Spark(二)-- SparkCore扩展 (三) -- RDD 的 Shuffle 和分区
目录
3.RDD 的 Shuffle 和分区
3.1 RDD 的分区操作
查看分区数
创建 RDD 时指定分区数
3.2 RDD 的 Shuffle 是什么
3.3 RDD 的 Shuffle 原理
Hash base shuffle
Sort base shuffle
3.RDD 的 Shuffle 和分区
目标
RDD 的分区操作
Shuffle 的原理
分区的作用
RDD 使用分区来分布式并行处理数据, 并且要做到尽量少的在不同的 Executor 之间使用网络交换数据, 所以当使用 RDD 读取数据的时候, 会尽量的在物理上靠近数据源, 比如说在读取 Cassandra 或者 HDFS 中数据的时候, 会尽量的保持 RDD 的分区和数据源的分区数, 分区模式等一一对应
(笔记:1.RDD经常需要通过读取外部系统的数据来创建,外部存储系统往往是支持分辨的,RDD需要支持分区,来和外部系统的分片一一对应 2.RDD的分区是一个并行计算的实现手段)
分区和 Shuffle 的关系
分区的主要作用是用来实现并行计算, 本质上和 Shuffle 没什么关系, 但是往往在进行数据处理的时候, 例如
reduceByKey,groupByKey等聚合操作, 需要把 Key 相同的 Value 拉取到一起进行计算, 这个时候因为这些 Key 相同的 Value 可能会坐落于不同的分区, 于是理解分区才能理解 Shuffle 的根本原理
Spark 中的 Shuffle 操作的特点
只有
Key-Value型的 RDD 才会有 Shuffle 操作, 例如RDD[(K, V)], 但是有一个特例, 就是repartition算子可以对任何数据类型 Shuffle早期版本 Spark 的 Shuffle 算法是
Hash base shuffle, 后来改为Sort base shuffle, 更适合大吞吐量的场景
3.1 RDD 的分区操作
查看分区数
可以通过 webUI 或 命令rdd.partitions.size 来查看分区
scala> sc.parallelize(1 to 100).count res0: Long = 100
之所以会有 8 个 Tasks, 是因为在启动的时候指定的命令是
spark-shell --master local[8], 这样会生成 1 个 Executors, 这个 Executors 有 8 个 Cores, 所以默认会有 8 个 Tasks, 每个 Cores 对应一个分区, 每个分区对应一个 Tasks, 可以通过rdd.partitions.size来查看分区数量
同时也可以通过 spark-shell 的 WebUI 来查看 Executors 的情况


默认的分区数量是和 Cores 的数量有关的, 也可以通过如下三种方式修改或者重新指定分区数量
创建 RDD 时指定分区数
可以通过本地集合创建时指定分区数,或通过读取HDFS文件来创建(会比指定的大1个)
scala> val rdd1 = sc.parallelize(1 to 100, 6) rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at parallelize at:24 scala> rdd1.partitions.size res1: Int = 6 scala> val rdd2 = sc.textFile("hdfs:///dataset/wordcount.txt", 6) rdd2: org.apache.spark.rdd.RDD[String] = hdfs:///dataset/wordcount.txt MapPartitionsRDD[3] at textFile at :24 scala> rdd2.partitions.size res2: Int = 7 rdd1 是通过本地集合创建的, 创建的时候通过第二个参数指定了分区数量. rdd2 是通过读取 HDFS 中文件创建的, 同样通过第二个参数指定了分区数, 因为是从 HDFS 中读取文件, 所以最终的分区数是由 Hadoop 的 InputFormat 来指定的, 所以比指定的分区数大了一个.
通过 coalesce 算子指定
coalesce(numPartitions: Int, shuffle: Boolean = false)(implicit ord: Ordering[T] = null): RDD[T]numPartitions
新生成的 RDD 的分区数
shuffle
是否 Shuffle
scala> val source = sc.parallelize(1 to 100, 6) source: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at:24 scala> source.partitions.size res0: Int = 6 scala> val noShuffleRdd = source.coalesce(numPartitions=8, shuffle=false) noShuffleRdd: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[1] at coalesce at :26 scala> noShuffleRdd.toDebugString res1: String = (6) CoalescedRDD[1] at coalesce at :26 [] | ParallelCollectionRDD[0] at parallelize at :24 [] scala> val noShuffleRdd = source.coalesce(numPartitions=8, shuffle=false) noShuffleRdd: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[1] at coalesce at :26 scala> shuffleRdd.toDebugString res3: String = (8) MapPartitionsRDD[5] at coalesce at :26 [] | CoalescedRDD[4] at coalesce at :26 [] | ShuffledRDD[3] at coalesce at :26 [] +-(6) MapPartitionsRDD[2] at coalesce at :26 [] | ParallelCollectionRDD[0] at parallelize at :24 [] scala> noShuffleRdd.partitions.size res4: Int = 6 scala> shuffleRdd.partitions.size res5: Int = 8
- 如果 shuffle 参数指定为 false, 运行计划中确实没有 ShuffledRDD, 没有 shuffled 这个过程
- 如果 shuffle 参数指定为 true, 运行计划中有一个 ShuffledRDD, 有一个明确的显式的 shuffled 过程
- 如果 shuffle 参数指定为 false 却增加了分区数, 分区数并不会发生改变, 这是因为增加分区是一个宽依赖, 没有 shuffled 过程无法做到, 后续会详细解释宽依赖的概念
通过 repartition 算子指定
repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
repartition算子本质上就是coalesce(numPartitions, shuffle = true)
(1)增加分区有效scala> val source = sc.parallelize(1 to 100, 6) source: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[7] at parallelize at:24 scala> source.partitions.size res7: Int = 6 scala> source.repartition(100).partitions.size res8: Int = 100 scala> source.repartition(1).partitions.size res9: Int = 1
(2)减少分区有效

repartition算子无论是增加还是减少分区都是有效的, 因为本质上repartition会通过shuffle操作把数据分发给新的 RDD 的不同的分区, 只有shuffle操作才可能做到增大分区数, 默认情况下, 分区函数是RoundRobin, 如果希望改变分区函数, 也就是数据分布的方式, 可以通过自定义分区函数来实现

3.2 RDD 的 Shuffle 是什么
val sourceRdd = sc.textFile("hdfs://node01:9020/dataset/wordcount.txt")
val flattenCountRdd = sourceRdd.flatMap(_.split(" ")).map((_, 1))
val aggCountRdd = flattenCountRdd.reduceByKey(_ + _)
val result = aggCountRdd.collect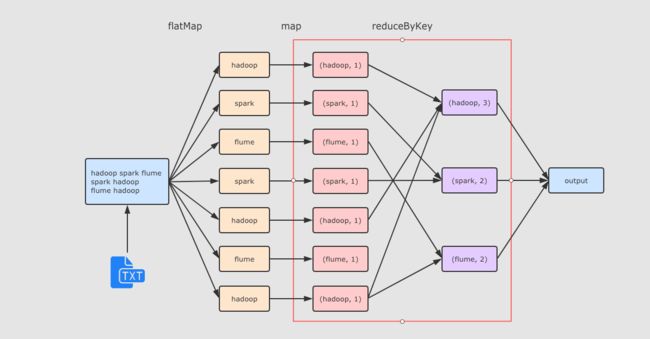

reduceByKey 这个算子本质上就是先按照 Key 分组, 后对每一组数据进行 reduce, 所面临的挑战就是 Key 相同的所有数据可能分布在不同的 Partition 分区中, 甚至可能在不同的节点中, 但是它们必须被共同计算.
为了让来自相同 Key 的所有数据都在 reduceByKey 的同一个 reduce 中处理, 需要执行一个 all-to-all 的操作, 需要在不同的节点(不同的分区)之间拷贝数据, 必须跨分区聚集相同 Key 的所有数据, 这个过程叫做 Shuffle.
3.3 RDD 的 Shuffle 原理
Spark 的 Shuffle 发展大致有两个阶段: Hash base shuffle 和 Sort base shuffle
(笔记:partitioner用于计算一个数据应该发往那个机器上,hash base和sort base用于描述中间过程如何存放文件)
Hash base shuffle
大致的原理是分桶, 假设 Reducer 的个数为 R, 那么每个 Mapper 有 R 个桶, 按照 Key 的 Hash 将数据映射到不同的桶中, Reduce 找到每一个 Mapper 中对应自己的桶拉取数据.
假设 Mapper 的个数为 M, 整个集群的文件数量是
M * R, 如果有 1,000 个 Mapper 和 Reducer, 则会生成 1,000,000 个文件, 这个量非常大了.过多的文件会导致文件系统打开过多的文件描述符, 占用系统资源. 所以这种方式并不适合大规模数据的处理, 只适合中等规模和小规模的数据处理, 在 Spark 1.2 版本中废弃了这种方式.
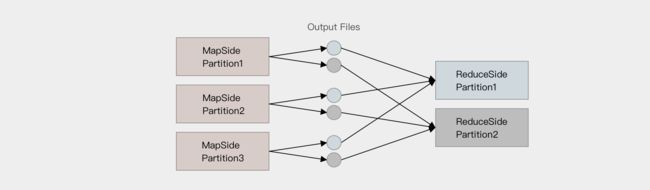
Sort base shuffle
对于 Sort base shuffle 来说, 每个 Map 侧的分区只有一个输出文件, Reduce 侧的 Task 来拉取, 大致流程如下
Map 侧将数据全部放入一个叫做 AppendOnlyMap 的组件中, 同时可以在这个特殊的数据结构中做聚合操作
然后通过一个类似于 MergeSort 的排序算法 TimSort 对 AppendOnlyMap 底层的 Array 排序
- 先按照 Partition ID 排序, 后按照 Key 的 HashCode 排序(例如:发往reduce1的数据叫做r1,然后排序形成类似 m1r1、m1r2、m1r3 然后分别发往对应的partition中)
最终每个 Map Task 生成一个 输出文件, Reduce Task 来拉取自己对应的数据
从上面可以得到结论, Sort base shuffle 确实可以大幅度减少所产生的中间文件, 从而能够更好的应对大吞吐量的场景, 在 Spark 1.2 以后, 已经默认采用这种方式.
但是需要大家知道的是, Spark 的 Shuffle 算法并不只是这一种, 即使是在最新版本, 也有三种 Shuffle 算法, 这三种算法对每个 Map 都只产生一个临时文件, 但是产生文件的方式不同, 一种是类似 Hash 的方式, 一种是刚才所说的 Sort, 一种是对 Sort 的一种优化(使用 Unsafe API 直接申请堆外内存)
