工作刷题积累-专业知识点1
1、CPU讀取內存的方式:
- 程序直接访问方式跟循环检测IO方式,应该是一个意思吧,是最古老的方式。CPU和IO串行,每读一个字节(或字),CPU都需要不断检测状态寄存器的busy标志,当busy=1时,表示IO还没完成;当busy=0时,表示IO完成。此时读取一个字的过程才结束,接着读取下一个字
- 中断控制方式:循环检测先进些,IO设备和CPU可以并行工作,只有在开始IO和结束IO时,才需要CPU。但每次只能读取一个字
- DMA方式:Direct Memory Access,直接存储器访问,比中断先进的地方是每次可以读取一个块,而不是一个字
- 通道方式:比DMA先进的地方是,每次可以处理多个块,而不只是一个块
2、Linux進程間通信方式:
管道( pipe ):管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
信号量( semophore ) : 信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
消息队列( message queue ) : 消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
共享内存( shared memory ) :共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量,配合使用,来实现进程间的同步和通信。
套接字( socket ) : 套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同機器间的进程通信。
回调: 是一种编程机制。
3、Linux系统中的线程间通信方式主要以下几种:
- 锁机制:包括互斥锁、条件变量、读写锁和自旋锁。
互斥锁确保同一时间只能有一个线程访问共享资源。当锁被占用时试图对其加锁的线程都进入阻塞状态(释放CPU资源使其由运行状态进入等待状态)。当锁释放时哪个等待线程能获得该锁取决于内核的调度 - 读写锁当以写模式加锁而处于写状态时任何试图加锁的线程(不论是读或写)都阻塞,当以读状态模式加锁而处于读状态时“读”线程不阻塞,“写”线程阻塞。读模式共享,写模式互斥。
- 条件变量可以以原子的方式阻塞进程,直到某个特定条件为真为止。对条件的测试是在互斥锁的保护下进行的。条件变量始终与互斥锁一起使用。
自旋锁上锁受阻时线程不阻塞而是在循环中轮询查看能否获得该锁,没有线程的切换因而没有切换开销,不过对CPU的霸占会导致CPU资源的浪费。 所以自旋锁适用于并行结构(多个处理器)或者适用于锁被持有时间短而不希望在线程切换产生开销的情况。 - 信号量机制(Semaphore):包括无名线程信号量和命名线程信号量
- 信号机制(Signal):类似进程间的信号处理
线程间的通信目的主要是用于线程同步,所以线程没有像进程通信中的用于数据交换的通信机制(線程間的通信可以直接調用進程的變量區,全局變量)
4、大小端存儲模式:
大端模式是高地址存储数据的低字节,小端模式是高地址存储数据的高字节
高——0x0102030405——低
5、TCP建立連接的三次握手和四次揮手断开连接
tcp/Ip有3次握手,第一次握手:客户端向服务器端发送SYN包(syn=j),进入SYN_SEND状态,等待服务器确认。
第二次握手:服务器收到SYN包,确认SYN,此时syn=k,同时发送一个ack包(ack=j+1)即SYN+ACK包,此时服务器进入SYN_RECV状态。
第三次握手:客户端收到SYN+ACK包,向服务器发送ACK确认包ack=k+1,syn=j+1,此时客户端和服务器端均进入ESTABLISHED状态。
其中有一个半连接状态:服务器维护一个半连接队列,该队列卫每个客户端SYN包开设一个条目,标明服务器已经接到SYN包,并向客户端发出确认,这些条目表示的连接处于SYN_RECV状态,得到客户端的确认后进入ESTABLISHED状态。
TIME_WAIT是断开连接时的状态
詳細描述
6、內存分配
struct
字节对齐:變量在內存中的儲存方式,爲了方便CPU讀取和運算,以經典的空間換區時間的做法來實現快速的數據讀取和計算
結構體的內存分配和對齊模式有很大的關係,定義的變量的長度>對齊字節長度,按照該變量的長度,且是對齊字節的倍數,定義的變量的長度<對齊字節的長度,可能出現兩個變量的共存在一個地址上,爲了減少內存的消耗,因此需要關注變量的類型和定義的位置關係
union(共用體)
union sample
{
short int n;//长度2
char c[10];//长度10
float f;//长度4
}s;
本来sample的空间应该是sizeof(char)*10=10;但是如果只是10个单元的话,那可以存几个float型(4位)呢?两个半?当然不可以,所以sample的空间延伸为既要大于10,又要满足其他成员所需空间的整数倍,即12
7、linux中進程運行的狀態:
调用在用户态,运行在内核态 ,進程的狀態
8、內存回收機制:
A:错误,因为回收主存时,要根据相邻分区空闲情况决定空闲分区个数,如果不考虑合并的话,空闲分区个数增加一个,因为可能发生合并情况,所以可能- ,可能不变;
B:由上知,错误;
C:无上邻空闲区,也无下邻空闲区,不需要合并空闲分区,空闲分区个数加1;
D:有上邻空闲区,但无下邻空闲区,需要将刚刚的空闲分区表的起始地址修改为上邻空闲区的起始地址和空闲分区大小,但是空闲分区个数不变;
E:有下邻空闲区,但无上邻空闲区,刚刚的空闲分区表起始位置不用改变,空闲分区大小改变,空闲分区个数不变;
F:有上邻空闲区,也有下邻空闲区,假设原来是2个空闲分区,新回收一个,发现前后都是空闲的,将三个合并为1个,最后结果为1个空闲分区,空闲分数个数减1
(原來是有2個空閒區,現在要回收一個,導致三個合成1個,因此減少了一個)
9、不同的0代表的含義:
① ‘0’ 代表字符0 ,对应ASCII码值为 0x30 (也就是十进制 48)
② ‘\0’ 代表空字符(转义字符)【输出为空】, 对应ASCII码值为 0x00(也就是十进制 0), 用作字符串结束符
③ 0 代表数字0,若把 数字0 赋值给 某个字符,对应ASCII码值为 0x00(也就是十进制0)
④ “0” 代表 一个字符串, 字符串中含有 2个字符,分别是 ‘0’ 和 ‘\0’
10、C++ malloc和new的区别:
1、malloc开辟的内存永远是通过free来释放的;而new单个元素内存,用的是delete,如果new[]数组,用的是delete[]来释放内存的
2、malloc开辟内存失败返回NULL,new开辟内存失败抛出bad_alloc类型的异常,需要捕获异常才能判断内存开辟成功或失败,new运算符其实是operator new函数的调用,它底层调用的也是malloc来开辟内存的,new它比malloc多的就是初始化功能,对于类类型来说,所谓初始化,就是调用相应的构造函数
11、內存分配
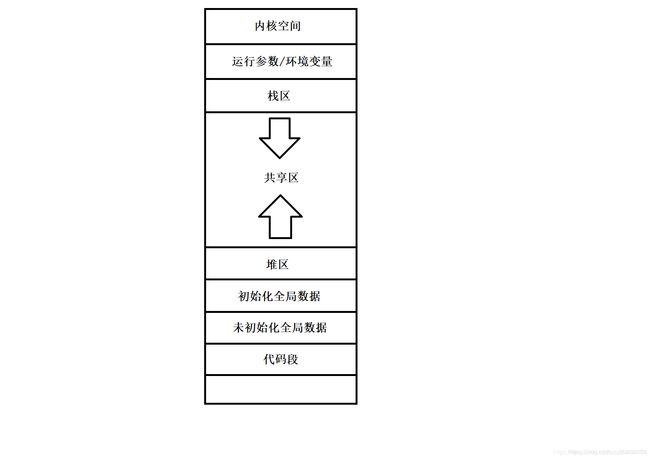
堆和栈的分配区别在以下几个方面
1、管理方式不同
2、空间大小不同
3、能否产生碎片不同
4、生长方向不同
5、分配方式不同
6、分配效率不同
- 管理方式: 栈是在函数运行时,由系统自动分配;而堆是通过程序员自己调用malloc函数或者new运算符去申请一个需要的大小空间
- 空间大小: 栈的空间大小并不大,一般最多为2M,超过之后会报Overflow错误。堆的空间非常大,最大可到达4G,可操作的空间非常大
- 能否产生碎片: 栈的操作与数据结构中的栈用法是类似的。‘后进先出’的原则,以至于不可能有一个空的内存块从栈被弹出。因为在它弹出之前,在它上面的后进栈的数据已经被弹出。它是严格按照栈的规则来执行。但是堆是通过new/malloc随机申请的空间,频繁的调用它们,则会产生大量的内存碎片。这是不可避免地
- 生长方向: 栈的生长方向是由高地址向低地址增长,是自上而下的。堆的生长方向是由低地址向高地址增长,是自下而上的
- 分配方式: 堆都是动态分配的,没有静态分配。但是栈有两种分配方式:静态分配和动态分配。静态分配是编译器完成的,比如局部变量的分配。动态分配由malloc函数实现,但是栈的动态分配和堆是不同的,它的动态分配是由编译器进行和释放,无需程序员进行操作
静态分配和动态分配的区别详解 - 分配效率: 栈是机器系统提供的数据结构,计算机底层对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行。这就决定了栈有着很高的效率。堆需要通过C/C++的库函数进行一个复杂的算法,在对内存中搜寻一个足够大小的空间,如果没有足够的空间(内存碎片空间太多),就有可能调用系统功能去增加程序数据段的内存空间,这样就有机会分到足够大小的内存,然后进行返回。显然,堆的效率比栈要低的多
12、IP与Mac地址的关系
- IP4的地址为32位,ip6为128位;MAC地址为48位
- 分配依据,IP的作用在于网络拓扑分层结构的建立,方便网络发送信息包,确定源地址和目标地址,MAC分配时基于制造商,前3字节为生厂商标志,后3字节按需分配
- 寻址协议,网络层和数据链路层,根据ARP协议进行目的IP地址到MAC地址的转换
- IP会根据网络环境变换,但是在局域网内是唯一确定的,MAC是唯一确定的,一般无法改变
13、循环冗余检测算法CRC和TCP协议中的FCS
- 先把需要发送的数据划分为组,假定每组k个比特。现假定待传送的数据M为101001(k=6)
- 在M后面添加供差错检测的n为冗余码,构成一帧(k+n位)发送
- 冗余码求法:
1、在原来的数据后面加n个0,这样原来的数据就相当于左移了3位,也就是M*8
2、将加0之后得到的(k+n)位的数除以双方事先商定好的长度为(n+1)位的除数P,得出的商是Q而余数为R(n位)
3、用模2除法来运算,相当于是在做亦或^运算
4、余数R即为FCS
- 接收方在利用双方约定的除数P,进行解码和检测运算,计算所得到的的余数为0,即代表接收正确
14、Linux内核的装载过程
内核文件是存放在硬盘中,但是和文件系统是分开存储的,没有启动内核之前,文件系统的初始化无法完成。
- uboot读取kernel到内存中,根据环境变量决定读取的地址和读取大小,以及读取完成后的执行地址
- uboot引导linux内核镜像(uImage)启动时,会有2个地址,加载地址(LoadAddress)即内核镜像整体要放置的内存空间位置,入口地址(Entry Point)即从内核镜像中开始执行的地址
15、SSH的加密通信过程
- 用户发送登录请求给远程主机,主机接收请求返回响应是自己的公钥
- 第一次登录的时候,会被要求询问是否相信该公钥
询问的原因:中间人攻击,伪造中间的主机,返回伪造的公钥(未被CA认证过的),窃取用户的登录密码,登录远程主机
- 用户根据公钥加密自己的用户名和密码,发送给远程主机
- 远程主机用自己的私钥解密,验证密码,即可同意登录
【口令登录】
1、发送公钥指纹,因为公钥采用RSA算法,其长度为1024,对其进行了MDK5的摘要算法计算,变为128位的指纹
2、接受指纹后,输入密码即可登录
【公钥登录】
1、用户将自己的公钥存储在远程主机上,登录时,远程主机发送随机字符串给用户
2、用户用自己的私钥加密后发送回远程主机
3、远程主机用事先储存的公钥进行解密,成功则直接进入shell