ClusterNet: Detecting Small Objects in Large Scenes by Exploiting Spatio-Temporal Information
ClusterNet: Detecting Small Objects in Large Scenes by Exploiting Spatio-Temporal Information 阅读笔记
- 摘要
- 摘要
- 1.Introduction
- 1.1WAMI中的目标检测
- 1.2空间与时间信息
- 2.相关工作
- 2.1帧间差分法和背景减除法
- 2.2. Region Proposal Networks
- 2.3. Spatio-Temporal CNNs
- 3. ClusterNet & FoveaNet: Two-Stage CNN
- 3.1. Region Proposal: Exploiting Motion
- 3.2. FoveaNet: Predicting Object Locations
- 4. Experimental Setup
- 5. Results
- 5.1. Single-Frame & Background Subtraction(单帧和背景减除法)
- 5.2. ClusterNet & FoveaNet
- 6. Conclusion
阅读笔记)
Object detection in wide area motion imagery (WAMI)
摘要
Object detection in wide area motion imagery (WAMI) has drawn the attention of the computer vision research community for a number of years. WAMI proposes a number of unique challenges including extremely small object sizes, both sparse and densely-packed objects, and extremely large search spaces (large video frames). Nearly all state-of-the-art methods in WAMI object detection report that appearance-based classifiers fail in this challenging data and instead rely almost entirely on motion information in the form of background subtraction or frame-differencing. In this work, we experimentally verify the
failure of appearance-based classifiers in WAMI, such as Faster R-CNN and a heatmap-based fully convolutional neural network (CNN), and propose a novel two-stage spatio-temporal CNN which effectively and efficiently combines both appearance and motion information to significantly surpass the state-of-the-art in WAMI object detection. To reduce the large search space, the first stage (ClusterNet) takes in a set of extremely large video frames, combines the motion and appearance information within the convolutional architecture, and proposes regions of objects of interest (ROOBI). These ROOBI can contain from one to clusters of several hundred objects due to the large video frame size and varying object density in WAMI. The second stage (FoveaNet) then estimates the centroid location of all objects in that given ROOBI simultaneously via heatmap estimation. The proposed method exceeds state-of-the-art results on the WPAFB 2009 dataset by 5-16% for moving objects and nearly 50% for stopped objects, as well as being the first proposed method in wide area motion imagery to detect completely stationary objects.
摘要
广域运动图像(WAMI)中的物体检测已经引起了计算机视觉研究界的关注多年。 WAMI提出了许多独特的挑战,包括极小的对象大小,稀疏和密集的对象,以及极大的搜索空间(大视频帧)。在WAMI对象检测中几乎所有最先进的基于外观的分类器方法都在这个具有挑战性的数据中失败,基本上都是依赖于背景减法或帧间差分法来获得运动信息。在这项工作中,我们通过实验验证WAMI中基于外观的分类器的失败,例如Faster R-CNN和基于热图的完全卷积神经网络(CNN),并提出了一种新颖的两阶段时空CNN,有效地将外观和运动信息结合起来,显着超越了WAMI物体检测的最新技术水平。为了减少大的搜索空间,第一阶段(Clusternet)接收一组极大的视频帧,在卷积体系结构中组合运动和外观信息,并提出感兴趣对象的区域(ROOBI)。由于WAMI中的大视频帧大小和不同的对象密度,这些ROOBI可以包含一个到几百个对象的簇。然后,第二阶段(FoveaNet)通过热力图估计给定ROOBI中所有对象的质心位置。对于移动物体,所提出的方法超过WPAFB 2009数据集的最新结果5-16%,停止物体接近50%,同时也是广域运动图像中首次提出的检测完全静止物体的方法。
1.Introduction
Object detection is a large and active area of research in computer vision. In wide area motion imagery (WAMI),performing object detection has drawn the attention of the computer vision community for a number of years the computer vision community for a number of years [14, 19, 23, 28, 31]. Numerous applications exist in both the civilian and military domains. In urban planning, applications include automatic traffic monitoring, driver behavior analysis, and road verification for assisting both scene understanding and land use classification. Civilian and military security is another area to benefit with applications including military reconnaissance, detection of abnormal or dangerous behavior, border protection, and surveillance of restricted areas. With increases in the use and affordability of drones and other unmanned aerial platforms, the desire for building a robust system to detect objects in wide-area and low-resolution aerial videos has developed considerably in recent years.[14, 19, 23, 28, 31].
物体检测是计算机视觉研究的一个重要且活跃的领域。在广域运动图像(WAMI)中,执行物体检测已经引起了计算机视觉社区多年来计算机视觉社区的注意[14,19,23,28,31]。民用和军用领域都有许多应用。在城市规划中,应用包括自动交通监控,驾驶员行为分析和道路验证,以协助场景理解和土地利用分类。民用和军事安全是受益于军事侦察,异常或危险行为检测,边境保护和限制区域监视等应用的另一个领域。随着无人机和其他无人机平台的使用和可承受性的增加,近年来建立一个强大的系统来检测广域和低分辨率航拍视频中的物体的愿望已经大大增加。[14,19,23,28]。
1.1WAMI中的目标检测
The goal of object detection in images or videos is to place a bounding box (i.e. the tightest fitting rectangle which contains all elements of an object while containing as few extraneous elements as possible) around all objects in the scene. Object detection in WAMI differs from the typical object detection problem in three major ways: 1)Ground-truth (i.e. human-generated) annotations are single (x, y) coordinates placed at the objects’ centers, rather than a bounding box. Therefore, scale and orientation invariance must be learned in order to locate objects’ centers, but this information cannot be provided during supervised training. 2) In typical object detection datasets, images or video frames most often contain only one to three objects, with no more than 15 objects, while these objects take up a large percentage of the image or video frame [13]. In WAMI,video frames can contain thousands of small objects, each object accounting for less than 0.000007% of the total pixels in a given frame. Quantitative analysis of this is shown in Fig. 2. 3) Majority of object detection frameworks deal with images at 256 x 256 up to 500 x 500 pixel resolutions.Video frames in WAMI are significantly larger, typically on the order of several, to hundreds of, megapixels. This creates an extremely large search space, especially given the extremely small typical object size in WAMI being on the order of 9×18 pixels. An example WAMI video frame with ground-truth annotations is shown in Fig. 1.
图像或视频中的对象检测的目标是在场景中的所有对象周围放置边界框(即,包含对象的所有元素的最紧密拟合矩形,同时包含尽可能少的外来元素)。WAMI中的对象检测与典型的对象检测问题在三个主要方面不同:1)ground-truth(即人类生成的)注释是放置在对象中心的单个(x,y)坐标,而不是边界框。因此,必须学习尺度和方向不变性以便定位物体的中心,但是在监督训练期间不能提供这种信息。2)在典型的物体检测数据集中,图像或视频帧通常只包含一到三个物体,不超过15个物体,而这些物体占据了图像或视频帧的很大一部分[13]。 在WAMI中,视频帧可以包含数千个小对象,每个对象占给定帧中总像素的0.000007%。 对此的定量分析如图2所示。3)大多数对象检测框架处理256 x 256到500 x 500像素分辨率的图像。WAMI中的视频帧明显更大,通常在几百到几万像素的数量级。这创建了一个非常大的搜索空间,特别是考虑到WAMI中极小的典型对象大小大约为9×18像素。WAMI的ground-truth如图一所示。



1.2空间与时间信息
For the past several years, object detection has been dominated by detectors relying solely on spatial and appearance information (e.g. Faster R-CNN [20], ResNet [5],YOLO 9000 [18]). These methods extract low-to-high level spatial and appearance features from images to predict and classify objects. However, it has been stated in numerous recent works [21, 24, 28, 29] that these appearance and machine-learning-based methods fail in WAMI due to several unique challenges. 1) Extremely small objects averaging 9 × 18 pixels in size. 2) High intra-class variation,ranging from deep black to bright white and from semitrucks to small cars with the typical vehicle color (i.e. silver/gray) exactly matching the background, as well as dramatic changes in camera gain cause significant changes in objects’ appearance between consecutive frames. 3) Lacking color and with low resolution, videos are single-channel gray-scale with often blurred/unclear object boundaries. 4)Low frame rates of roughly 1.25 Hz make exploiting temporal information a challenge. Moving objects travel a significant distance between consecutive frames, most often with no overlap to the previous frame. Also, since the aerial recording platform is moving, background objects have significant motion causing strong parallax effects and frame-registration errors, leading to false-positive detections. Moving mosaic seams, where multiple cameras are stitched together to form a single sensor, sweep across the video, leading to even more false positives. Several of these challenges are shown in Fig. 3.
在过去的几年中,物体检测一直由仅依赖于空间和外观信息的探测器主导(例如,更快的R-CNN [20],ResNet [5],YOLO 9000 [18])。这些方法从图像中提取低到高级别的空间和外观特征,以预测和分类对象。然而,在最近的许多着作[21,24,28,29]中已经说明,由于几个独特的挑战,这些外观和基于机器学习的方法在WAMI中失败。1)极小的物体,平均尺寸为9×18像素。 2)高级的类内变化,从深黑色到亮白色和从半卡车到小型汽车,典型的车辆颜色(即银色/灰色)与背景完全匹配,以及相机增益的显着变化导致连续帧之间物体外观的显着变化。3)缺乏颜色和低分辨率,视频是单通道灰度级,通常模糊/不清楚对象边界。4)大约1.25Hz的低帧速率使得利用时间信息成为挑战。 移动物体在连续帧之间行进相当大的距离,最常见的是与前一帧没有重叠。 此外,由于空中记录平台正在移动,背景物体具有显着的运动,导致强烈的视差效应和帧配准误差,从而导致误报检测。移动马赛克接缝,将多个相机拼接在一起形成单个传感器,扫过视频,导致更多的误检。 其中一些挑战如图3所示。
Due to the aforementioned reasons, all state-of-the-art object detection methods in WAMI are motion-based[17, 28, 29], which use background subtraction or frame differencing to find the objects in the videos. However, as with the appearance-based methods, motion-based approaches suffer from their own costly drawbacks. Frame differencing and background subtraction at their core, rely heavily on the video frame registration. Small errors in frame registration can induce large failures in the final results and attempting to remove false positives is often a big part of these methods. In addition to frame registration, background subtraction requires computing median background images over a large number of frames for the entire video. This combined with the ignorance of appearance information leads to an inefficient use of information across multiple video frames. Yet, the biggest drawback is the complete inability to detect stopped vehicles. All state-of-the-art methods, due to their sole reliance on temporal information, cannot detect vehicles which are not moving relative to the background.
由于上述原因,WAMI中所有现有的对象检测方法都是基于运动的[17,28,29],它们使用背景减法或帧差分来找到视频中的对象。然而,与基于外观的方法一样,基于运动的方法遭受其自身的昂贵缺点。帧间差分法和背景减除法很大程度上依赖于视频帧配准(??)配准帧中的小错误可能导致最终结果中的大失败,并且尝试去除误报通常是这些方法的重要部分。除了帧注册之外,背景减法还需要在整个视频的大量帧上计算中值背景图像。这同对外观信息的不敏感相结合导致跨多个视频帧的信息的低效使用。然而,最大的缺点是完全无法检测到停止的车辆。 由于其仅依赖于时间信息,所有最先进的方法都无法检测到相对于背景不移动的车辆。
Some recent works [3, 6, 8, 22, 27] have attempted to begin combining spatial and temporal information in various ways for object detection and action recognition. These methods include connecting detections across frames using tracking methods or optical flow, using a sliding window or out-of-the-box detector to perform detection then simply classify this result using some temporal information, as well as combining the outputs of a single frame CNN and optical flow input to a CNN. However, all of these methods rely either on a single-frame detector, which uses no temporal information, or uses a sliding window to check all possible locations in a video frame for object proposals, and thus do not fully exploit temporal information for the task of object detection in video. This is discussed further in Section 2.3.
最近的一些工作[3,6,8,22,27]已经尝试以各种方式开始组合空间和时间信息以用于对象检测和动作识别。这些方法包括使用跟踪方法或光流连接帧间检测,使用滑动窗口或开箱即用的检测器执行检测,然后使用一些时间信息简单地对此结果进行分类,以及将单帧CNN的输出和光流输入组合到CNN。然而,所有这些方法都依赖于单帧检测器,其不使用时间信息,或者使用滑动窗口来检查视频帧中的所有可能位置以用于对象提议,因此不完全利用该任务的时间信息。 视频中的物体检测。 这将在2.3节中进一步讨论。
3.贡献
The proposed two-stage, spatio-temporal convolutional neural network (CNN) predicts the location of multiple objects simultaneously, without using single-frame detectors or sliding-window classifiers. We show that, consistent with findings in several other works, single-frame detectors fail in this challenging WAMI data, and it is known that sliding window classifiers are terribly inefficient. The novelty of this paper is as follows: 1) Our method effectively utilizes both spatial and temporal information from a set of video frames to locate multiple objects simultaneously in WAMI. 2) This approach removes the need for computing background subtracted images, thus reducing the computational burden and the effect of errors in frame registration.3) The two-stage network shows the potential to reduce the extremely large search space present in WAMI data with a minimal effect on accuracy. 4) The proposed method is capable of detecting completely stationary vehicles in WAMI,where no other work yet published can do so. 5) The proposed method significantly outperforms the state-of-the-art in WAMI with a 5-16% relative improvement in F 1 score on moving object detection and a nearly 50% relative improvement for stopping vehicles, while reducing the average error distance of true positive detections from the previous state-of-the-art 5.5 pixels to roughly 2 pixels.
所提出的两阶段时空卷积神经网络(CNN)同时预测多个对象的位置,而不使用单帧检测器或滑动窗口分类器。我们表明,与其他几项工作的发现一致,单帧探测器在这个具有挑战性的WAMI数据中失败,并且已知滑动窗口分类器非常低效。本文的新颖性如下:1)我们的方法有效地利用来自一组视频帧的空间和时间信息在WAMI中同时定位多个对象。2)该方法消除了计算背景减影图像的需要,从而减少了计算负担和帧匹配中的错误的影响。3)两阶段网络显示了减少WAMI数据中存在的极大搜索空间的可能性,而对准确性的影响最小。 4)所提出的方法能够在WAMI中检测完全静止的车辆,其中尚未公布的其他工作可以这样做。5)所提出的方法明显优于WAMI的最新技术,运动物体检测的F 1得分相对改善5-16%,静止物体相对改善近50%,同时减少平均误差距离 从先前最先进的5.5像素到大约2个像素。
2.相关工作
2.1帧间差分法和背景减除法
As stated in Section 1.2, due to the difficulties in WAMI and the reported failures of appearance and machine-learning-based-methods, all state-of-the-art methods in WAMI are based on either frame-differencing or back-ground subtraction. Both methods require video frames to be registered to a single coordinate system. Reilly et al. [19] detects Haris corners in two frames, computes the SIFT features around those corners, and matches the points using descriptors. A frame-to-frame homography is then fit, using RANSAC or a similar method, and used to warp images to a common reference frame. Frame differencing is the process of computing pixel-wise differences in intensities between consecutive frames. Both two-frame and three-frame differencing methods have been proposed in literature with a number of variations [9, 16, 24, 28, 30]. Background subtraction methods focus on obtaining a background model for each frame, then subtract each video frame from its corresponding background model. These methods suffer heavily from false positives introduced by the issues discussed in Section 1.2 and cannot detect stationary vehicles. Slowing vehicles also cause a major problem as they are prone to cause split detections in frame differencing [29] while registration errors and parallax effects are increased in background subtraction models, which use more frames than frame differencing. Sudden and dramatic changes in camera gain cause illumination changes which in-turn cause problems for background modeling and frame differencing methods that require consistent global illumination [24].
如第1.2节所述,由于WAMI的困难以及基于外观和基于机器学习的方法的失败,WAMI中所有最先进的方法都基于帧间差分法或背景减除法。两种方法都要求将视频帧映射到单个坐标系。Reilly et al. [19]在两个帧中检测Haris角,计算这些角周围的SIFT特征,并使用描述符匹配点。然后使用RANSAC或类似方法拟合帧到帧的单应性,并用于将图像扭曲到公共参考帧。帧间差分法是计算连续帧之间的像素强度的差异的过程。在具有许多变化的文献中已经提出了两帧和三帧差分方法[9,16,24,28,30]。 背景减法方法着重于获得每个帧的背景模型,然后从其对应的背景模型中减去每个视频帧。 这些方法严重受到第1.2节讨论的问题引入的误报的影响,无法检测静止车辆。 减速车辆也会引起一个主要问题,因为它们容易在帧差分中引起分裂检测[29],而配准误差和视差效应在背景减法模型中增加,后者使用比帧差分更多的帧。 相机增益的突然和剧烈变化导致照明变化,这反过来又导致背景建模和帧差分方法的问题,这些方法需要一致的全局照明[24]。
2.2. Region Proposal Networks
Region proposal networks (RPN), such as Faster R-CNN[20], which has in some ways become the standard in object detection, have shown the ability to generate object proposals with high accuracy and efficiency. Unfortunately, Faster R-CNN fails in WAMI due to four main reasons. 1) Faster R-CNN acts only on single frames, thus does not exploit the available temporal information, which proves to be extremely important. 2) WAMI video frames are extremely large, thus cannot be sent in their entirety to a Faster R-CNN network on any reasonable number of GPUs. This requires spatially-chipping videos into smaller sections and checking these sections individually, dramatically hurting the computational efficiency benefit supposed to be provided by a RPN. 3) If one changed the RPN stage of Faster R-CNN to extremely downsample the images in the earliest layers in order to fit the large WAMI video frames within GPU memory, object proposals would become impossible.
Due to the extremely small object size combined with the areas of high object density means any significant amount of downsampling in the network immediately makes object locations indistinguishable, as they are often separated by only a few pixels or even less. 4) WAMI data is ill-suited for Faster R-CNN as the ground-truth locations are single points, not bounding boxes. We experimentally verify that Faster R-CNN fails in WAMI, even when given the benefit of spatially-chipping the video frames to manageable sizes.
区域提议网络(RPN),例如Faster R-CNN [20],在某些方面已成为对象检测的标准,已经显示出以高准确度和高效率生成对象提议的能力。不幸的是,由于四个主要原因,更快的R-CNN在WAMI中失败。 1)更快的R-CNN仅作用于单帧,因此不能利用可用的时间信息,这被证明是非常重要的。2)WAMI视频帧非常大,因此把整幅图像完整的送入Fast Rcnn中,在合理数目的GPU上。这需要将视频帧切片到较小的部分并单独检查这些部分,这极大地损害了RPN应该提供的计算效率优势。3)如果将Faster R-CNN中,在前几层的图像进行下采样以便将大WAMI视频帧送人到GPU存储器内,但是这样在RPN阶段,但是对象提议将变得不可能。由于极小的物体尺寸与高物体密度区域相结合意味着网络中任何大量的下采样都会立即使物体位置难以区分,因为它们通常仅相隔几个像素或甚至更少。4)WAMI数据不适合Faster R-CNN,因为ground-truth 位置是单点,而不是边界框。 我们通过实验验证了更快的R-CNN在WAMI中失败,即使在将视频帧空间削减到可管理的大小的情况下也是如此。
2.3. Spatio-Temporal CNNs
In the past few years, partially due to the enormous success of deep learning methods in a vast array of problems,several works have been proposed for combining spatial and temporal information in various ways within deep learning frameworks. Baccouche et al. [3] and Ji et al. [6] both propose using 3D CNNs for action recognition. Simonyan and Zisserman [27] propose a ”two-stream” CNN, one branch receiving individual video frames as input and the other receiving optical flow image stacks where the output of the two streams are combined at the end of the network. Kang et al. [8] proposes several methods to connect object detections in individual frames across time, including using tracking algorithms, optical-flow-guided propagation, and a long short-term memory (LSTM) sub-network. Rozantsev et al. [22] detects flying drones using sliding-window proposals, input to two CNNs multiple times to align each frame, then performs binary classification of the object or non-object in the sliding window.
在过去几年中,部分由于深度学习方法在大量问题中取得了巨大成功,已经提出了一些在深度学习框架内以各种方式组合空间和时间信息的工作。Baccouche et al. [3] and Ji et al. [6]都提出使用3D卷积进行动作识别。Simonyan和Zisserman [27]提出了“双流”CNN,一个分支接收单独的视频帧作为输入,另一个接收光流图像,其中两个流的输出在网络的末端组合。Kang et al. [8]提出了几种方法来连接各个帧中的对象检测,包括使用跟踪算法,光流引导传播和长期短期记忆(LSTM)子网络。Rozantsev et al. [22] 使用滑动窗口提议检测飞行无人机,多次输入两个CNN以对齐每个帧,然后在滑动窗口中执行对象或非对象的二分类。
Our proposed work differs from all of the above in several key ways. Baccouche et al. and Ji et al. both use stacks of frames as input to a 3D CNN. However, these works do not perform object detection. Both first assume an object of interest is already detected and perfectly centered in each input video frame. To accomplish this, these works use out-of-the-box single-frame human detector algorithms to find the objects of interest in their videos. Our method proposes to solve this object detection problem where singleframe detectors fail, in the challenging WAMI domain. Simonyan and Zisserman keep spatial and temporal information separate during feature extraction, simply combin-
ing the extracted features at the end of the network. As stated, single-frame detectors fail in WAMI. Also, due to the extremely large object displacements between consecutive frames, the optical flow stream would likely struggle significantly. The work by Kang et al. also relies on first acquiring single-frame object detections before applying their tracking or LSTM methods. The work by Rozant-sev et al. is the only one of these methods which does not rely on single-frame detections, instead opting for a sliding window to first generate its object proposals before using a 3D CNN for classification. However, sliding-window-based methods are extremely inefficient. Our work proposes to generate all object proposals simultaneously using a multi-frame, two-stage CNN for videos in WAMI in a more computationally efficient manner than background subtraction or sliding windows, effectively combining both spatial and temporal information in a deep-learning-based algorithm.
我们提出的工作在几个关键方面与上述所有工作不同。 Baccouche等人和Ji等人,两者都使用帧堆栈作为3D CNN的输入。 但是,这些工作不执行对象检测。 两者都首先假设已经检测到感兴趣的对象并且在每个输入视频帧中完美地居中。为了实现这一目标,这些工作使用开箱即用的单帧人体探测器算法来查找其视频中感兴趣的对象。我们的方法提出在具有挑战性的WAMI域中解决物体检测中单帧检测器失效的问题。Simonyan和Zisserman在特征提取期间将空间和时间信息分开,在网络的末端简单地组合,并提取特征。如上所述,单帧检测器在WAMI中失败。 而且,由于连续帧之间的极大的物体位移,光流特征也比较差。Kang等人的工作还依赖于在应用其跟踪或LSTM方法之前首先获取单帧对象检测。 Rozant-sev等人的工作是这些方法中唯一不依赖于单帧检测的方法,而是选择滑动窗口在使用3D CNN进行分类之前首先生成其对象提议。但是,基于滑动窗口的方法效率极低。 我们的工作建议使用多帧同时生成所有对象提议,在WAMI中的视频中使用两阶段CNN,比背景减法计算效率更高比滑动窗口更有效,在基于深度学习的算法中有效地结合了空间和时间信息
3. ClusterNet & FoveaNet: Two-Stage CNN
We propose a new region proposal network which combines spatial and temporal information within a deep CNN to propose object locations. Where in Faster R-CNN, each 3 × 3 region of the output map of the RPN proposes nine possible objects, our network generalizes this to propose regions of objects of interest (ROOBI) containing varying amounts of objects, from a single object to potentially over 300 objects, for each 4 × 4 region of the output map of the RPN. We then focus the second stage of the network on each proposed ROOBI to predict the location of all object(s) simultaneously for the ROOBI, again combining spatial and temporal information in this network. This two-stage approach is loosely inspired by biological vision where a large field of vision takes in information, then cues, one of the strongest being motion-detection, determine where to focus the much smaller fovea centralis.
我们提出了一种新的区域提议网络,该网络在深度CNN内组合空间和时间信息以提出对象位置。在Faster R-CNN中,RPN的输出图的每个3×3区域提出九个可能的对象,我们的网络概括了这一点,以提出包含不同数量对象的感兴趣对象区域(ROOBI),对于每个RPN的输出映射的每个4×4区域,从单个对象到可能超过300个对象。然后,我们将网络的第二阶段集中在每个提议的ROOBI上,以同时为ROOBI预测所有对象的位置,再次组合该网络中的空间和时间信息。这种两阶段方法的灵感来自于生物视觉,最强大的运动检测之一,其中大视野接收信息,然后提示,确定聚焦较小的中央凹中心的位置。
3.1. Region Proposal: Exploiting Motion
To reduce the extremely large search space in WAMI,several works proposed using road-overlay maps. This dramatically reduces the search area but severely limits to applicability of the method. Road maps must be known in advance and must be fit perfectly to each video frame, in addition to removing the possibility for detecting objects which do not fall on the road. Instead, we proposed a method to learn this search space reduction, without any prior knowledge of road maps. We created a fully-convolutional neural network shown in Fig. 4 which dramatically downsamples the very large WAMI video frames using convolutional strides and max pooling. To exploit temporal information,rather than sending an individual frame to the CNN, we input consecutive adjoining frames with the frame we want to generate proposals for. These adjoining and central frames are input to a 2D convolutional network. The advantage of using a 2D CNN over a 3D CNN as in [3, 6] is the preservation of the temporal relationship between frames. Each frame learns its own convolutional filter set, then these are combined to produce feature maps which maximize information related to the frame we care most about (in our case we chose to train the network to maximize the central frame). Instead of a sliding temporal convolution, our method uses the following equation,
为了减少WAMI中极大的搜索空间,提出了一些使用道路覆盖图的工作。为了减少WAMI中极大的搜索空间,提出了一些使用道路覆盖图的工作。这大大减少了搜索范围,但严重限制了该方法的适用性。道路地图必须事先知道,并且必须完美地适合每个视频帧,此外还不能检测到不会落在路面上的物体。相反,我们提出了一种方法来学习这种搜索空间缩减的方法,而不需要任何先前的路线图知识。我们创建了一个完全卷积的神经网络,如图4所示,它使用卷积步幅和最大池来显着地对非常大的WAMI视频帧进行采样。

为了利用时间信息,而不是将单个帧发送到CNN,我们输入我们想要为其生成提议的帧以及连续的相邻帧。这些相邻和中央帧被输入到2D卷积网络。如[3,6]中那样在3D CNN上使用2D CNN的优点是保持帧之间的时间关系。每个帧都学习自己的卷积滤波器集,然后将它们组合起来,通过最大化与我们最关心的帧相关的信息(在我们的例子中,我们选择训练网络以最大化中心帧)产生特征图。我们的方法使用以下等式代替滑动时间卷积:

其中 V n 是 第 存 储 在 堆 栈 中 的 第 n t h 视 频 帧 , K n 是 对 用 第 n 帧 的 , 大 小 为 V_{n}是第存储在堆栈中的第n^{th}视频帧,K_{n}是对用第n帧的,大小为 Vn是第存储在堆栈中的第nth视频帧,Kn是对用第n帧的,大小为{ k h , k w k_{h},k_{w} kh,kw}的卷积核,来生成我们要的特征图 f m ∈ R m f_{m}∈R^{m} fm∈Rm,M是特征图的集合, n ∈ N n∈N n∈N是是输入到网络的时间帧集合中的帧,并且 b m b_{m} bm是特征图m的学习偏差。这个公式不同于标准2D单帧CNN和3D CNN,允许我们通过欧几里德的反向传播或输出得分图与ground-truth热力图之间的交叉熵损失来选择我们想要最大化的帧。
All further layers in the network beyond the first perform the task of refining this information to the desired output.As shown by Schwartz-Ziv and Tishby [26], the amazing success of deep neural networks lie in their ”information bottleneck” ability to refine information through the layers guided by backpropagation, reducing the high-entropy input to a low-entropy output. Therefore we chose to provide our temporal information to the network in the earliest layer,providing the maximum possible information at the earliest stage, allowing the remainder of the layers to refine this information to the desired output proposals.
网络中除第一层之外的所有其他层执行将该信息细化到期望输出的任务。如Schwartz-Ziv和Tishby [26]所示,深度神经网络的惊人成功在于它们的“信息瓶颈”能力,即通过反向传播引导的层来细化信息,将高熵输入减少到低熵输出。 因此,我们选择在最早的层中向网络提供我们的时间信息,在最早阶段提供最大可能的信息,允许其余层将该信息细化为期望的输出提议。
We formulated the problem in two different ways. In one, we estimate ROOBIs, or object locations in the second stage, via a heatmap-based formulation using the Euclidean loss between the network output and a heatmap created in the following manner,
我们以两种不同的方式考虑了这个问题。一方面我们使用热力图和网络输出的欧几里得损失获得基于热力图的损失公式,通过基于热图的公式估算第二阶段的ROOBI或对象位置。
其中n ∈ N是(x,y)的ground-truth坐标,d是下采样的量倍数,σ是高斯模糊适合每个变换对象位置的方差。这使得损失具有平滑的梯度,以便估计对象/区域位置而不是空间中的单个点。然后将H剪裁为1,以便用单个对象和数百个对象的簇来均等地加权区域。通过对我们的两个类的高斯热图进行阈值处理来创建分割图。分割公式,使用softmax-交叉熵损失,当对象位置互斥时。因此,如果对象位置不重叠,则可以使用单个输出预测大量对象类的位置。如果位置不相互排斥,则可以使用高斯热图公式,其中每类对象具有相应的热图,并且网络产生该数量的输出。这些实验的结果显示出非常相似的结果,证明在给定特定问题的情况下可以使用任一种公式,因此允许我们的方法具有更大的灵活性和更广泛的可能应用。
3.2. FoveaNet: Predicting Object Locations
The FoveaNet stage of our two-stage CNN works on the principle of the effective receptive field of neurons in ClusterNet. Each output neuron in the final 1 × 1 convolutional layer essentially gives a vote, whether there is a vehicle or cluster of vehicles within that given region or whether there are none. These neurons vote based on the information of the neurons they are connected to in the previous layer which in turn are connected back to the layer before them and so on until the initial input. FoveaNet calculates the region of input information each neuron in the final layer is using to make its final vote. For any Cluster-Net output values above a set threshold, this input region, across all input frames, is sent through FoveaNet for high-resolution analysis, as FoveaNet has only a single down-sample in the network. The effect is ClusterNet allows us to ignore large regions of the search space while focusing a small high-resolution fovea centralis over regions which contain at least one to several hundred vehicles, illustrated in Fig. 5. FoveaNet then predicts the location all of vehicles within that region to a high degree of accuracy for the given temporal frame of interest.
我们的两阶段CNN的FoveaNet阶段基于ClusterNet中神经元的有效感受域原理。最终的1×1卷积层中的每个输出神经元给出投票,无论在该给定区域内是否存在车辆或车辆群或者是否存在。这些神经元基于它们在前一层中连接的神经元的信息进行投票,而前一层又连接回它们之前的层,依此类推,直到初始输入。FoveaNet计算最终层中每个神经元用于进行最终投票的输入信息区域。 对于高于设定阈值的任何Cluster-Net输出值,跨所有输入帧的此输入区域将通过FoveaNet发送以进行高分辨率分析,因为FoveaNet在网络中只有一个下采样。效果是ClusterNet允许我们忽略搜索那些空间大的区域,同时聚焦在一个小的高分辨率中央凹集中,至少包含一到几百辆车的区域上,如图5所示,然后,FoveaNet预测该区域内所有车辆的位置,以达到给定时间范围内的高精度。

Since our FoveaNet input can be much smaller thanks to ClusterNet reducing the search space, we opted to use large kernels within the convolutional layers of FoveaNet, decreasing in size to the final 1 × 1 convolutional layer, see Fig 4. This was inspired by the recent work by Peng et al. [15] as well as a large amount of experimentation. For the options of large kernels ascending in size, descending in size, or fixed in size, as well as small kernels, we found the proposed network to consistently perform the best.
由于ClusterNet减少了搜索空间,我们的FoveaNet输入可以小得多,我们选择在FoveaNet的卷积层内使用大的卷积核,将大小减小到最终的1×1卷积层,见图4。对于卷积核的打小,我们发现我们提出的网络始终如一地表现最佳。
4. Experimental Setup
Experiments were performed on the WPAFB 2009 dataset [1]. This dataset is the benchmark by which all methods in WAMI compare as it is one of the most varied and challenging, as well as one of the only publicly available with human-annotated vehicle locations. The video is taken from a single sensor, comprised of six slightly-overlapping cameras, covering an area of over 19 sq. km.,at a frame rate of roughly 1.25 Hz. The average vehicle in these single-channel images make up only approximately 9×18 out of the over 315 million pixels per frame, with each pixel corresponding to roughly 1/4 meter. With almost 2.4 million vehicle detections spread across only 1, 025 frames of video, there averages out to be well over two thousand vehicles to detect in every frame.
实验在WPAFB 2009数据集[1]上进行。 该数据集是WAMI中所有方法进行比较的基准,因为它是最具变化性和挑战性的数据集之一,也是唯一一个公开提供人类注释的车辆位置的数据集。该视频来自一个传感器,由六个略微重叠的摄像机组成,覆盖面积超过19平方公里,帧速率约为1.25赫兹。这些单通道图像中的每个车辆平均仅占大约9×18,每个像素对应于大约1/4米,每帧超过3.15亿像素,检测到240万个车辆在1,025帧的视频中,平均每帧都有超过两千辆车被检测。
Frames are registered to compensate for camera motion following the method by Reilly et al. [19] as discussed in Section 2.1. After registration, eight areas of interest (AOI) were cropped out in accordance to those used is testing other state-of-the-art methods [4, 17, 28, 29], allowing for a proper comparison of results. AOIs 01−04 are 2278×2278 pixels, covering different types of surroundings and varying levels of traffic. AOI 34 is 4260 × 2604. AOI 40 is 3265 × 2542. AOI 41 is 3207 × 2892. AOI 42 is simply a sub-region of AOI 41 but was included to test our method against the one proposed by Prokaj et al. [17] on persistent detections where slowing and stopped vehicles were not removed from the ground truth, even though Prokaj et al. uses tracking methods to maintain detections. All other AOIs have any vehicle which moved fewer than 15 pixels (2/3 a car length) over the course of 5 frames removed as to be consistent in testing against other methods for moving object detection. All cropped AOIs are shown with their ground-truth and our results in the supplemental materials.
根据Reilly等人的方法,对帧进行配准以补偿相机运动。 [19]如2.1节所述。匹配后,根据使用的方法裁剪出八个感兴趣的区域(AOI),测试其他最先进的方法[4,17,28,29],以便对结果进行适当的比较。 AOI 01-04是2278×2278像素,覆盖不同类型的环境和不同的交通水平。 AOI 34是4260×2604.AO 40是3265×2542.AO 41是3207×2892.AO 42仅仅是AOI 41的子区域,但是包括在内以测试我们的方法与Prokaj等人提出的方法。 [17]关于持续性检测,其中减速和停止的车辆没有从基本事实中移除,即使Prokaj等人。使用跟踪方法来维护检测。所有其他AOI都有任何车辆在移除5帧的过程中移动少于15个像素(车辆长度为2/3),以便与其他移动物体检测方法的测试保持一致。所有裁剪的AOI都显示其真实性在我们在补充材料中的结果。
Data was split into training and testing splits in the following way. For training, only tiles which contain vehicles were included. The splits were as follows: AOIs 02, 03, and 34 were trained on AOIs 40, 41, and 42; AOIs 01 and 40 were trained on AOIs 34, 41, and 42; and AOIs 04, 41, and 42 were trained on 34 and 40. Both ClusterNet and FoveaNet were trained separately from scratch using Caffe [7]. ClusterNet used stochastic gradient descent with Nesterov momentum, a base learning rate of 0.01, a batch size of 8, and decreased the learning rate by a factor of 0.1 upon validation loss plateaus. FoveaNet used Adam [11] with a base learning rate of 0.00001 and a batch size of 32. Training and testing was performed on a single Titan X GPU.
数据按以下方式分为训练和测试分组。对于训练,仅包括包含车辆的分组。分组如下:AOI 02,03和34在AOI 40,41和42上训练; AOI 01和40在AOI 34,41和42上接受过培训; 并且AOI 04,41和42在34和40训练。ClusterNet和FoveaNet都是使用Caffe分开训练的[7]。 ClusterNet使用随机梯度下降与Nesterov动量,基本学习率为0.01,批量大小为8,在验证loss plateaus时,将学习率降低0.1倍。FoveaNet使用Adam [11],基本学习率为0.00001,批量大小为32.训练和测试是在单个Titan X GPU上进行的。
To turn the final network output back to single (x, y)coordinates for comparison against the ground-truth, the output is thresholded (either by set levels for creating precision-recall curves, or by Otsu thresholding to find the best threshold level during deployment). Connected components are obtained, weak responses (i.e. < 100 pixels) are removed, and large responses (i.e. > 900 pixels; assumed to be merged detections) are split into multiple detections by finding circular centers in a bounding box surrounding that connected component. The centroid of each connected component is considered as a positive detection. It should be noted merged detections are quite rare; completely removing this component saw a F 1 score decrease of less than 0.01 across all AOIs. Completely removing small detection removal saw a decrease in F 1 score of 0.01 to 0.05 depending on the AOI tested; however, this parameter is quite robust. Values in the range of 60 to 180 pixels show a change of less than 0.01 in F1 score across all AOIs.
要将最终网络输出变成单个(x,y)坐标以与ground-thruth实况进行比较,输出将被阈值化(通过设置级别创建精确调用曲线,或通过Otsu阈值处理以找到最佳阈值水平部署)。获得连通分量,去除弱响应(即<100像素),并且通过在围绕该连通分量的边界框中找到圆形中心,将大响应(即> 900像素;假设为合并检测)分成多个检测。每个连通分量的质心被认为是正样本。值得注意的是,合并检测很少见; 完全去除该组分后,所有AOI的F 1评分降低均小于0.01。根据所测试的AOI,完全去除小的检测去除,F 1得分降低0.01至0.05; 但是,这个参数非常强大。 在所有AOI中,在60到180像素范围内的值显示F1得分中的变化小于0.01。定量结果在精确度,召回率和F 1度量方面进行了比较。
为了与文献[28]保持一致,如果它们落在地面实况坐标的20像素(5米)范围内,则被认为是正样本。如果多个检测在此半径范围内,则采用最接近的检测,如果它们没有任何其他具有20个像素的地面实况坐标,则其余的被标记为误报。任何不在ground-truth的20个像素范围内的检测坐标也标记为误报。在20像素内没有检测的地面实况坐标被标记为副样本。
5. Results
5.1. Single-Frame & Background Subtraction(单帧和背景减除法)
为了证明时间信息的影响,我们进行了三组实验:显式,隐式和无时间信息。对于显示,我们计算了Reilly[19]等人的方法之后所有帧的中值和背景减除图像。我们训练和测试FoveaNet,输入是中间视频帧的两个副本与该帧的计算背景减除图像相结合。每个部分分成128*128个像素。这表明,我们的深层网络通过同时提供外观和时间信息,可以比单纯的背景减法表现得更好。对于隐式方法,我们使用三到五帧作为网络的输入来训练和测试我们提出的方法,以证明网络能够直接从输入图像中学习时间信息,而不需要计算中值图像和背景减法图像。我们使用单一帧作为输入对FoveaNet进行训练和测试,并使用Faster的R-CNN进行实验。我们尝试了许多配置Faster的R-CNN与VGG-16和ResNet-50,预训练和从头开始开始训练,proposal尺寸调整成WAMI数据分成256×256像素,ground-truth的边界框设置为20×20像素集,以目标对象为中心。所有这些实验在AOI 41上测试的最高精确召回曲线如图6所示。

5.2. ClusterNet & FoveaNet
我们提出的两阶段方法的结果,与13种不同的最先进的方法相比,在图9和表2中显示了7种不同的AOIs。在AOI 42上,不去除静止物体,结果如图8、图7所示。我们的最终结果衡量了ClusterNet提供的计算效率改进和对检测得分的影响。如果FoveaNet必须检查给定输入的每个区域,那么获得预测对象(x, y)位置的时间大约为每帧3秒。表1显示了来自ClusterNet的平均加速以及所有AOIs中F1值的平均变化。

表1:不同阈值水平下使用ClusterNet的加速百分比和F1-measure减少。较高的阈值排除了较大部分的输入空间,但如果提高得太高,则会对F1分数产生负面影响。

表2:F1当前最先进的方法得分。如果原始作品中没有报告F1值,则使用[28]和/或[29]中报告的值。注意,AOI 42是持久检测的结果(没有车辆从地面真值中移除),并与目前文献中仅有的另一种持久检测WAMI方法进行了比较。
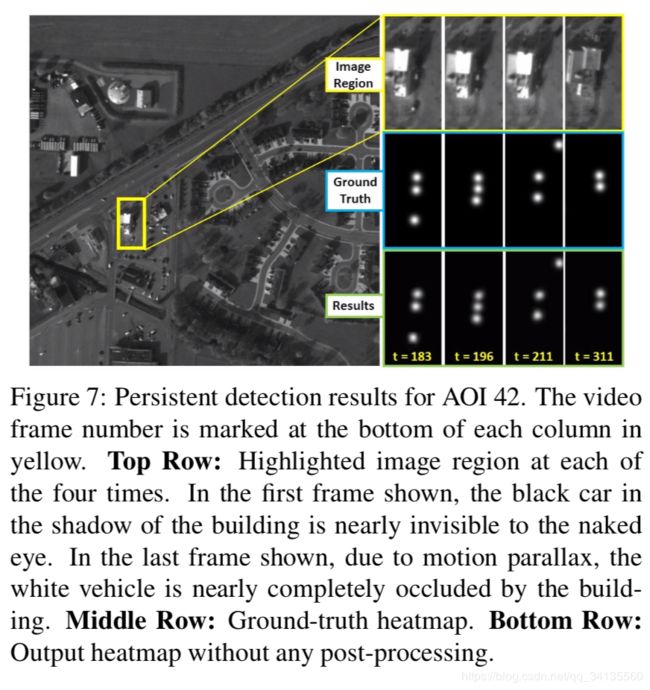
图7:AOI 42的持久检测结果。视频帧号用黄色标记在每一列的底部。顶行:四次高亮显示图像区域。在第一幅图中,建筑阴影下的黑色汽车几乎是肉眼看不见的。在最后一帧显示,由于运动视差,白色车辆几乎完全被建筑遮挡。中间一行:ground truth真实热图。底部行:输出热图没有任何后处理。

图8:持续检测AOI 42的准确率召回曲线(即不去掉ground truth真值坐标)。
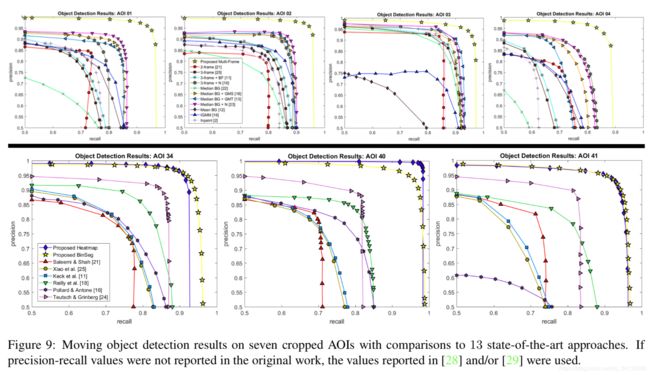
图9:7个裁剪过的AOIs上的移动对象检测结果与13种最先进的方法进行比较。如果原始工作中没有报告值,则使用[28]和/或[29]中报告的值。
6. Conclusion
提出了一种用于大场景小目标检测的两级卷积神经网络,并在大区域运动图像上进行了验证。我们的方法成功地利用了外观和运动线索来同时检测数百个物体的位置。我们已经将其与13种最先进的方法进行了比较,F1评分显示,运动物体的性能改善相对为5-16%,持久检测的性能改善接近50%。去除计算中值图像和背景图像的计算盲点,以及聚类网络减少搜索空间,都是接近在线方法的关键贡献。对于未来的工作,最后的障碍之一是去除帧对齐计算删除相机的运动。