Apache Flink(从小白到熟练掌握)
Apache Flink
一、概述
https://flink.apache.org/
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-p1oVcYTE-1582679088382)(https://flink.apache.org/img/flink-header-logo.svg)]
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
大数据处理方案演变过程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RMhFwbAQ-1582679088383)(assets/1.png)]
Flink框架的体系结构
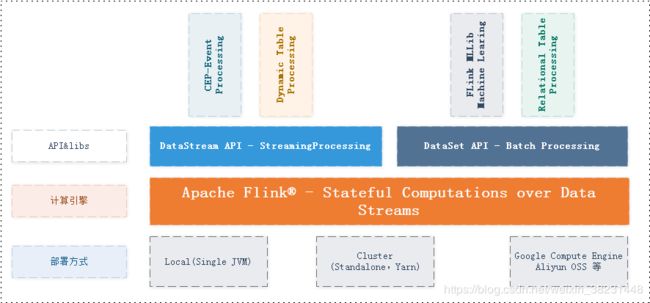
- 部署方式支持多种环境:Local模式(测试)、Standalone&Yarn、云计算
- 底层计算引擎:数据流的基础之上实现了有状态计算
- 目前Flink提供两套基础API:DataSet API(批处理)和DataStream API(流处理)
- 高级抽象API:CEP、Dynamic Table、MLLib、Relationnal Table等;
特点
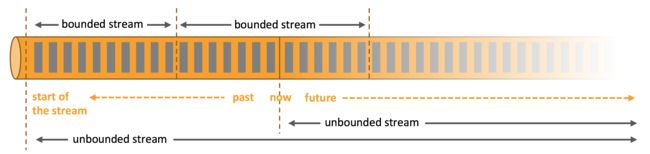
处理无界和有界数据
任何类型的数据都可以形成一种事件流。信用卡交易、传感器测量、机器日志、网站或移动应用程序上的用户交互记录,所有这些数据都形成一种流。
数据可以被作为 无界 或者 有界 流来处理。
- 无界流 有定义流的开始,但没有定义流的结束。
- 有界流 有定义流的开始,也有定义流的结束。
部署应用到任意地方
Apache Flink 是一个分布式系统,它需要计算资源来执行应用程序。Flink 集成了所有常见的集群资源管理器,例如 Hadoop YARN、 Apache Mesos 和 Kubernetes,但同时也可以作为Standalone集群运行。
运行任意规模应用
Flink 旨在任意规模上运行有状态流式应用。因此,应用程序被并行化为可能数千个任务,这些任务分布在集群中并发执行。所以应用程序能够充分利用无尽的 CPU、内存、磁盘和网络 IO。而且 Flink 很容易维护非常大的应用程序状态。其异步和增量的检查点算法对处理延迟产生最小的影响,同时保证精确一次状态的一致性。
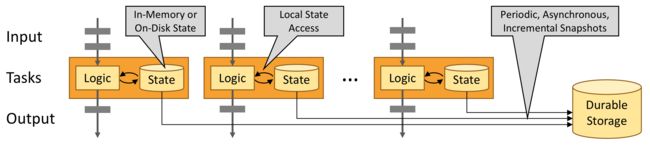
利用内存性能
有状态的 Flink 程序针对本地状态访问进行了优化。任务的状态始终保留在内存中,如果状态大小超过可用内存,则会保存在能高效访问的磁盘数据结构中。任务通过访问本地(通常在内存中)状态来进行所有的计算,从而产生非常低的处理延迟。Flink 通过定期和异步地对本地状态进行持久化存储来保证故障场景下精确一次的状态一致性。
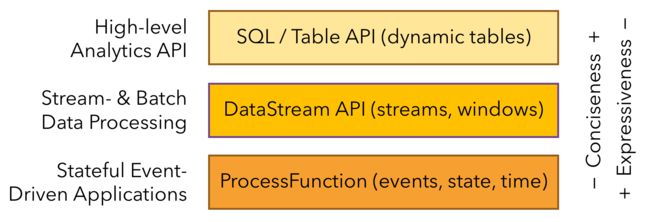
分层API
Flink 根据抽象程度分层,提供了三种不同的 API。每一种 API 在简洁性和表达力上有着不同的侧重,并且针对不同的应用场景。
二、环境搭建
Flink集群是Standalone伪分布式集群
准备工作
- JDK1.8 +
- Hadoop环境(HDFS、环境变量、SSH免密登录等)
- Flink版本1.8.2
- Scala版本2.11.12
安装
-
解压缩安装
tar -zxvf flink-1.8.2-bin-scala_2.11.tgz -C /usr
配置
-
flink-conf.yaml# jobmanager flink standalone集群master jobmanager.rpc.address: netzhuo # 每一个计算节点提供的任务槽数量 任务槽是一个资源单位 默认是1 taskmanager.numberOfTaskSlots: 2 -
slaves# 当前虚拟机的主机名 netzhuo
运行集群
-
启动
命令1:bin/start-cluster.sh 验证服务命令:jps 2885 TaskManagerRunner # 从机JVM进程 2462 StandaloneSessionClusterEntrypoint # 主机JVM进程 Flink Web UI页面:http://虚拟机主机名:8081 -
关闭
bin/stop-cluster.sh
三、Quick Example
Flink版本WordCount
导入依赖
<dependencies>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-coreartifactId>
<version>1.8.2version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-scala_2.11artifactId>
<version>1.8.2version>
dependency>
dependencies>
开发应用
package com.netzhuo
import org.apache.flink.streaming.api.scala._
// flink word count
object WordCountApplication {
def main(args: Array[String]): Unit = {
//1. flink程序运行的环境 自适应运行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2. 构建数据源对象
val dataStream = env.socketTextStream("localhost", 8888)
//3. 转换处理操作
dataStream
.flatMap(_.split("\\s"))
.map((_, 1L))
// 分组
// 0 --> tuple2 word
.keyBy(0)
.sum(1)
.print()
//4. 启动流式计算
env.execute("wordcount")
}
}
启动数据服务器
nc -lk 8888
Hello Spark
Hello Flink
本地运行
右键 运行 main方法即可,常用于测试开发
2> (Hello,1)
16> (Spark,1)
16> (Flink,1)
2> (Hello,2)
集群运行
准备工作
- flink集群服务正常
将应用打包
- 略
- 集群能够提供的依赖
provider
提交应用
bin/flink run -c com.netzhuo.WordCountApplication /tmp/flink-day1/target/flink-day1-1.0-SNAPSHOT.jar
查看结果
-
Web界面
-
查看计算节点的数据日志
四、DataStream API
DataSource(数据源)
通俗理解数据的来源地
基于Scala集合
package com.netzhuo.datasource
import org.apache.flink.streaming.api.scala._
// 基础的datasource的创建方法(集合)
object DataSourceWithScalaCollection {
def main(args: Array[String]): Unit = {
//1. flink程序运行的环境 自适应运行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2. 构建数据源对象
// scala list
// val dataStream = env.fromCollection(List("Hello Spark","Hello Flink"))
// scala seq
// val dataStream = env.fromCollection(Seq("Hello Spark","Hello Flink"))
/*
//3. 转换处理操作
dataStream
.flatMap(_.split("\\s"))
.map((_, 1L))
// 分组
// 0 --> tuple2 word
.keyBy(0)
.sum(1)
.print()
*/
// 并行集合
/*
val dataStream = env.fromParallelCollection(new LongValueSequenceIterator(1,10))
dataStream
.print()
*/
// 数值Range 1 to 20
/*
val dataStream = env.generateSequence(1,20)
dataStream.print()
*/
// pojo
val dataStream = env.fromElements(User(1, "zs"), User(2, "ls"))
dataStream
.print()
//4. 启动流式计算
env.execute("wordcount")
}
}
case class User(id: Int, name: String)
基于文件系统
readFile & readTextFile
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-shaded-hadoop-2artifactId>
<version>2.6.5-8.0version>
dependency>
package com.netzhuo.datasource
import org.apache.flink.api.java.io.TextInputFormat
import org.apache.flink.core.fs.Path
import org.apache.flink.streaming.api.functions.source.FileProcessingMode
import org.apache.flink.streaming.api.scala._
// 基础的datasource的创建方法(文件系统)
// Could not find a file system implementation for scheme 'hdfs'.
object DataSourceWithFileSystem {
def main(args: Array[String]): Unit = {
//1. flink程序运行的环境 自适应运行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//方法1:readFile 数据文件目录中内容只会读取一次
// val dataStream = env.readFile(new TextInputFormat(new Path("hdfs://netzhuo:9000/data")),"hdfs://netzhuo:9000/data")
//方法2:持续监控数据文件目录中新内容
// 参数3:watchType 监视类型 PROCESS_ONCE(默认) 和 PROCESS_CONTINUOUSLY
// 参数4:interval 时间间隔
// 参数5:filter 过滤器
/*
val dataStream = env.readFile(
new TextInputFormat(new Path("hdfs://netzhuo:9000/data")),
"hdfs://netzhuo:9000/data",
FileProcessingMode.PROCESS_CONTINUOUSLY,
2000
)
*/
// 方法3:直接读取指定目录的文本 (只读一次)
val dataStream = env.readTextFile("hdfs://netzhuo:9000/data")
dataStream
.print()
//4. 启动流式计算
env.execute("wordcount")
}
}
注意:
- 只读一次,选择方法1和方法3
- 持续读,选择方法2
基于网络套接字
val dataStream = env.socketTextStream("localhost", 8888)
基于Kafka【重点】
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-kafka_2.11artifactId>
<version>1.8.2version>
dependency>
整合代码
package com.netzhuo.datasource
import java.util.Properties
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaConsumer, KafkaDeserializationSchema}
import org.apache.flink.streaming.util.serialization.JSONKeyValueDeserializationSchema
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
// 基础的datasource的创建方法(Kafka)
// Could not find a file system implementation for scheme 'hdfs'.
object DataSourceWithKafka {
def main(args: Array[String]): Unit = {
//1. flink程序运行的环境 自适应运行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// bin/kafka-topics.sh --create --topic flink --zookeeper netzhuo:2181 --partitions 1 --replication-factor 1
// bin/kafka-console-producer.sh --topic flink --broker-list netzhuo:9092
// 方法1:只获取kafka record value
// console kafka producer
/*
val prop = new Properties()
prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"netzhuo:9092")
prop.put(ConsumerConfig.GROUP_ID_CONFIG,"g1")
val dataStream = env.addSource(new FlinkKafkaConsumer[String]("flink",new SimpleStringSchema(),prop))
*/
// --------------------------------------------------------------------------------
// 方法2:如果获取record其它信息怎么办呢? value key partition offset ...
// 假如:获取key value offset partition
/*
val prop = new Properties()
prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "netzhuo:9092")
prop.put(ConsumerConfig.GROUP_ID_CONFIG, "g1")
val dataStream = env.addSource(new FlinkKafkaConsumer[(String, String, Long, Int)]("flink", new KafkaDeserializationSchema[(String, String, Long, Int)] {
/**
* 判断流是否结束 永远不会结束
*
* @param nextElement
* @return
*/
override def isEndOfStream(nextElement: (String, String, Long, Int)): Boolean = false
/**
* 反序列化方法
*
* @param record 拉取到kafka记录
* @return
*/
override def deserialize(record: ConsumerRecord[Array[Byte], Array[Byte]]): (String, String, Long, Int) = {
var key = ""
if (record.key() != null) {
key = new String(record.key())
}
val value = new String(record.value())
val offset = record.offset()
val partition = record.partition()
(key, value, offset, partition)
}
/**
* 生成类型信息
*
* @return
*/
override def getProducedType: TypeInformation[(String, String, Long, Int)] = {
createTypeInformation[(String, String, Long, Int)]
}
}, prop))
*/
// --------------------------------------------------------------------------------
// 方法3:Kafka Record Value Json格式数据,支持简介操作
val prop = new Properties()
prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "netzhuo:9092")
prop.put(ConsumerConfig.GROUP_ID_CONFIG, "g1")
// true 表示包含offset topic partition信息
val dataStream = env.addSource(new FlinkKafkaConsumer("flink", new JSONKeyValueDeserializationSchema(true), prop))
// 注意:datastream中元素类型都为objectNode
dataStream
.map(objectNode => (
objectNode.get("key"),
objectNode.get("value").get("id"),
objectNode.get("value").get("name"),
objectNode.get("metadata").get("offset")))
.print()
//4. 启动流式计算
env.execute("wordcount")
}
}
更多的connector
请参阅:
https://ci.apache.org/projects/flink/flink-docs-release-1.10/zh/dev/connectors/
Data Sink(结果写出)
Flink计算结果输出支持多种类型,如:print(测试)、文件系统、redis、hbase、kafka等第三方存储系统
略
基于文件系统
package com.netzhuo.sink
import org.apache.flink.streaming.api.scala._
object WordCountWithFileSystemSink {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream = env.socketTextStream("localhost", 8888)
val resultDataStream = dataStream
.flatMap(_.split("\\s"))
.map((_, 1))
.keyBy(0)
.sum(1)
// 使用文件系统方式写出结果数据流
resultDataStream
// .writeAsText("hdfs://netzhuo:9000/data3")
// .writeAsText("/Users/netzhuo/data/170_result") // 默认 NO_OVERWRITE
// .writeAsText("/Users/netzhuo/data/170_result",WriteMode.OVERWRITE) // 清空结果文件 覆盖所有的内容
// .writeAsText("/Users/netzhuo/data/170_result",WriteMode.NO_OVERWRITE) // 结果文件存在 直接报错
// 注意:数据流一定得大,否则不容易看到输出结果
.writeAsCsv("/Users/netzhuo/data/170_result2")
env.execute("word count")
}
}
Bucketing File Sink
分桶输出(默认根据系统时间,格式yyyy-MM-dd-HH)
如:/basicpath/{datetime}/part-{任务序号}-xx
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-filesystem_2.11artifactId>
<version>1.8.2version>
dependency>
// -----------------------------------------------------------------
// 分桶形式存放结果流
// 注意:本地:file:/// hdfs://
val bucketingSink = new BucketingSink[(String, Int)]("file:///Users/netzhuo/data/170bucket")
// 自定义基于北京时间的分桶规则
bucketingSink.setBucketer(new DateTimeBucketer[(String, Int)]("yyyy-MM-dd-HHmm",ZoneId.of("Asia/Shanghai")))
//bucketingSink.setBatchSize(1024 * 1024 * 10) // 单位:字节 10MB
bucketingSink.setBatchSize(1) // 单位:字节 10MB
bucketingSink.setBatchRolloverInterval(5000) // 5s 两个条件满足其一即可
resultDataStream
.addSink(bucketingSink)
基于Redis Sink
https://bahir.apache.org/docs/flink/current/flink-streaming-redis/
<dependency>
<groupId>org.apache.bahirgroupId>
<artifactId>flink-connector-redis_2.11artifactId>
<version>1.0version>
dependency>
单机Redis
package com.netzhuo.sink
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.redis.RedisSink
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig
import org.apache.flink.streaming.connectors.redis.common.mapper.{RedisCommand, RedisCommandDescription, RedisMapper}
object WordCountWithRedisSink {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream = env.socketTextStream("localhost", 8888)
val resultDataStream = dataStream
.flatMap(_.split("\\s"))
.map((_, 1))
.keyBy(0)
.sum(1)
// redis sink
// 定义flink&redis集成的连接信息
val conf = new FlinkJedisPoolConfig.Builder().setHost("localhost").setPort(6379).build()
resultDataStream
.addSink(new RedisSink[(String, Int)](conf, new RedisMapper[(String, Int)] {
/**
* 获取命令的描述对象
* 主要定义结果写出redis使用类型(String,Set,Zset,Hash,List)
* Hash类型
* hset wordcount word,1
* hget wordcount word
* @return
*/
override def getCommandDescription: RedisCommandDescription = new RedisCommandDescription(RedisCommand.HSET,"wordcount")
/**
* 从数据中找key(word)
*
* @param t
* @return
*/
override def getKeyFromData(t: (String, Int)): String = t._1
override def getValueFromData(t: (String, Int)): String = t._2.toString
}))
env.execute("word count")
}
}
Redis Cluster
val conf = new FlinkJedisPoolConfig.Builder().setNodes(...).build()
stream.addSink(new RedisSink[(String, String)](conf, new RedisExampleMapper))
Redis 哨兵集群
val conf = new FlinkJedisSentinelConfig.Builder().setMasterName("master").setSentinels(...).build()
stream.addSink(new RedisSink[(String, String)](conf, new RedisExampleMapper))
| Data Type | Redis Command [Sink] |
|---|---|
| HASH | HSET |
| LIST | RPUSH, LPUSH |
| SET | SADD |
| PUBSUB | PUBLISH |
| STRING | SET |
| HYPER_LOG_LOG | PFADD |
| SORTED_SET | ZADD |
| SORTED_SET | ZREM |
基于Kafka Sink
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/connectors/kafka.html
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-kafka_2.11artifactId>
<version>1.8.2version>
dependency>
写出Key&Value
package com.netzhuo.sink
import java.util.Properties
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer
import org.apache.flink.streaming.util.serialization.KeyedSerializationSchema
import org.apache.kafka.clients.producer.ProducerConfig
object WordCountWithKafkaSink {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream = env.socketTextStream("localhost", 8888)
val resultDataStream = dataStream
.flatMap(_.split("\\s"))
.map((_, 1))
.keyBy(0)
.sum(1)
val prop = new Properties()
prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "netzhuo:9092")
prop.put(ProducerConfig.ACKS_CONFIG, "all")
prop.put(ProducerConfig.RETRIES_CONFIG, "3")
prop.put(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG, "2000")
resultDataStream
.addSink(new FlinkKafkaProducer[(String, Int)](
"170result",
new KeyedSerializationSchema[(String, Int)] {
/**
* 序列化record key方法
*
* @param element
* @return
*/
override def serializeKey(element: (String, Int)): Array[Byte] = element._1.getBytes()
override def serializeValue(element: (String, Int)): Array[Byte] = element._2.toString.getBytes()
override def getTargetTopic(element: (String, Int)): String = "170result"
}, prop))
env.execute("word count")
}
}
只写出Value
将计算结果作为一个整体,以Kafka Record Value的形式输出存储
// 方法二:写出value
resultDataStream
// 元素类型必须string
.map(t2 => t2._1 + "->" + t2._2)
.addSink(new FlinkKafkaProducer[String]("170result", new SimpleStringSchema(), prop))
env.execute("word count")
// null JDBC->1
// null Hello->1
// null Hello->2
// null Mysql->1
基于ElasticSearch 【拓展】
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-elasticsearch6_2.11artifactId>
<version>1.6.1version>
dependency>
package com.netzhuo.sink
import org.apache.flink.api.common.functions.RuntimeContext
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.elasticsearch.{ElasticsearchSinkFunction, RequestIndexer}
import org.apache.flink.streaming.connectors.elasticsearch6.ElasticsearchSink
import org.apache.http.HttpHost
import org.elasticsearch.action.index.IndexRequest
import org.elasticsearch.client.Requests
object WordCountWithESSink {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream = env.socketTextStream("localhost", 8888)
val resultDataStream = dataStream
.flatMap(_.split("\\s"))
.map((_, 1))
.keyBy(0)
.sum(1)
val httpHosts = new java.util.ArrayList[HttpHost]
httpHosts.add(new HttpHost("127.0.0.1", 9200, "http"))
val esSinkBuilder = new ElasticsearchSink.Builder[(String,Int)](
httpHosts,
new ElasticsearchSinkFunction[(String,Int)] {
def process(element: (String,Int), ctx: RuntimeContext, indexer: RequestIndexer) {
val json = new java.util.HashMap[String, Any]
json.put("word", element._1)
json.put("count", element._2)
val rqst: IndexRequest = Requests.indexRequest
// 索引名 database
.index("my-index")
// 类型名 table
.`type`("my-type")
.source(json)
indexer.add(rqst)
}
}
)
// configuration for the bulk requests; this instructs the sink to emit after every element, otherwise they would be buffered
esSinkBuilder.setBulkFlushMaxActions(1)
resultDataStream.addSink(esSinkBuilder.build())
env.execute("word count")
}
}
更多的Source&Sink
参阅:https://ci.apache.org/projects/flink/flink-docs-release-1.10/zh/dev/connectors/
自定义Sink
resultDataStream
.addSink(new RichSinkFunction[(String, Int)] {
/**
* 调用方法
*
* @param value
* @param context
*/
override def invoke(value: (String, Int), context: SinkFunction.Context[_]): Unit = {
println(value._1+"--->"+value._2)
}
/**
* 建立和第三方存储系统连接
*
* @param parameters
*/
override def open(parameters: Configuration): Unit = {
println("open method")
}
/**
* 释放资源
*/
override def close(): Unit = {
println("close method")
}
})
env.execute("word count")
转换函数
| Transformation | Description |
|---|---|
| Map DataStream → DataStream | Takes one element and produces one element. A map function that doubles the values of the input stream:dataStream.map { x => x * 2 } |
| FlatMap DataStream → DataStream | Takes one element and produces zero, one, or more elements. A flatmap function that splits sentences to words:dataStream.flatMap { str => str.split(" ") } |
| Filter DataStream → DataStream | Evaluates a boolean function for each element and retains those for which the function returns true. A filter that filters out zero values:dataStream.filter { _ != 0 } |
| KeyBy DataStream → KeyedStream | Logically partitions a stream into disjoint partitions, each partition containing elements of the same key. Internally, this is implemented with hash partitioning. See keys on how to specify keys. This transformation returns a KeyedStream.dataStream.keyBy("someKey") // Key by field "someKey" dataStream.keyBy(0) // Key by the first element of a Tuple |
| Reduce KeyedStream → DataStream | A “rolling” reduce on a keyed data stream. Combines the current element with the last reduced value and emits the new value. A reduce function that creates a stream of partial sums:keyedStream.reduce { _ + _ } |
| Fold KeyedStream → DataStream | A “rolling” fold on a keyed data stream with an initial value. Combines the current element with the last folded value and emits the new value. A fold function that, when applied on the sequence (1,2,3,4,5), emits the sequence “start-1”, “start-1-2”, “start-1-2-3”, …val result: DataStream[String] = keyedStream.fold("start")((str, i) => { str + "-" + i }) |
| Aggregations KeyedStream → DataStream | Rolling aggregations on a keyed data stream. The difference between min and minBy is that min returns the minimum value, whereas minBy returns the element that has the minimum value in this field (same for max and maxBy).keyedStream.sum(0) keyedStream.sum("key") keyedStream.min(0) keyedStream.min("key") keyedStream.max(0) keyedStream.max("key") keyedStream.minBy(0) keyedStream.minBy("key") keyedStream.maxBy(0) keyedStream.maxBy("key") |
| Window KeyedStream → WindowedStream | Windows can be defined on already partitioned KeyedStreams. Windows group the data in each key according to some characteristic (e.g., the data that arrived within the last 5 seconds). See windows for a description of windows.dataStream.keyBy(0).window(TumblingEventTimeWindows.of(Time.seconds(5))) // Last 5 seconds of data |
| WindowAll DataStream → AllWindowedStream | Windows can be defined on regular DataStreams. Windows group all the stream events according to some characteristic (e.g., the data that arrived within the last 5 seconds). See windows for a complete description of windows.WARNING: This is in many cases a non-parallel transformation. All records will be gathered in one task for the windowAll operator.dataStream.windowAll(TumblingEventTimeWindows.of(Time.seconds(5))) // Last 5 seconds of data |
| Window Apply WindowedStream → DataStream AllWindowedStream → DataStream | Applies a general function to the window as a whole. Below is a function that manually sums the elements of a window.Note: If you are using a windowAll transformation, you need to use an AllWindowFunction instead.windowedStream.apply { WindowFunction } // applying an AllWindowFunction on non-keyed window stream allWindowedStream.apply { AllWindowFunction } |
| Window Reduce WindowedStream → DataStream | Applies a functional reduce function to the window and returns the reduced value.windowedStream.reduce { _ + _ } |
| Window Fold WindowedStream → DataStream | Applies a functional fold function to the window and returns the folded value. The example function, when applied on the sequence (1,2,3,4,5), folds the sequence into the string “start-1-2-3-4-5”:val result: DataStream[String] = windowedStream.fold("start", (str, i) => { str + "-" + i }) |
| Aggregations on windows WindowedStream → DataStream | Aggregates the contents of a window. The difference between min and minBy is that min returns the minimum value, whereas minBy returns the element that has the minimum value in this field (same for max and maxBy).windowedStream.sum(0) windowedStream.sum("key") windowedStream.min(0) windowedStream.min("key") windowedStream.max(0) windowedStream.max("key") windowedStream.minBy(0) windowedStream.minBy("key") windowedStream.maxBy(0) windowedStream.maxBy("key") |
| Union DataStream* → DataStream | Union of two or more data streams creating a new stream containing all the elements from all the streams. Note: If you union a data stream with itself you will get each element twice in the resulting stream.dataStream.union(otherStream1, otherStream2, ...) |
| Window Join DataStream,DataStream → DataStream | Join two data streams on a given key and a common window.dataStream.join(otherStream) .where().equalTo() .window(TumblingEventTimeWindows.of(Time.seconds(3))) .apply { ... } |
| Window CoGroup DataStream,DataStream → DataStream | Cogroups two data streams on a given key and a common window.dataStream.coGroup(otherStream) .where(0).equalTo(1) .window(TumblingEventTimeWindows.of(Time.seconds(3))) .apply {} |
| Connect DataStream,DataStream → ConnectedStreams | “Connects” two data streams retaining their types, allowing for shared state between the two streams.someStream : DataStream[Int] = ... otherStream : DataStream[String] = ... val connectedStreams = someStream.connect(otherStream) |
| CoMap, CoFlatMap ConnectedStreams → DataStream | Similar to map and flatMap on a connected data streamconnectedStreams.map( (_ : Int) => true, (_ : String) => false ) connectedStreams.flatMap( (_ : Int) => true, (_ : String) => false ) |
| Split DataStream → SplitStream | Split the stream into two or more streams according to some criterion.val split = someDataStream.split( (num: Int) => (num % 2) match { case 0 => List("even") case 1 => List("odd") } ) |
| Select SplitStream → DataStream | Select one or more streams from a split stream.val even = split select "even" val odd = split select "odd" val all = split.select("even","odd") |
| Iterate DataStream → IterativeStream → DataStream | Creates a “feedback” loop in the flow, by redirecting the output of one operator to some previous operator. This is especially useful for defining algorithms that continuously update a model. The following code starts with a stream and applies the iteration body continuously. Elements that are greater than 0 are sent back to the feedback channel, and the rest of the elements are forwarded downstream. See iterations for a complete description.initialStream.iterate { iteration => { val iterationBody = iteration.map {/*do something*/} (iterationBody.filter(_ > 0), iterationBody.filter(_ <= 0)) } } |
| Extract Timestamps DataStream → DataStream | Extracts timestamps from records in order to work with windows that use event time semantics. See Event Time.stream.assignTimestamps { timestampExtractor } |
map
val datastream = env.fromCollection(List("Hello Spark", "Hello Flink"))
datastream
.flatMap(line => line.split("\\s"))
.map((_,1))
.print()
结果:
5> (Hello,1)
4> (Hello,1)
5> (Flink,1)
4> (Spark,1)
flatMap
val datastream = env.fromCollection(List("Hello Spark", "Hello Flink"))
datastream
.flatMap(line => line.split("\\s"))
.print()
结果:
7> Hello
8> Hello
7> Spark
8> Flink
filter
val datastream = env.fromCollection(List("Hello Spark", "Hello Flink"))
datastream
.flatMap(line => line.split("\\s"))
.map((_,1))
.filter(_._1.startsWith("H"))
.print()
结果:
4> (Hello,1)
5> (Hello,1)
keyBy
根据key进行逻辑分区,默认使用
hash partitioning
datastream
.flatMap(line => line.split("\\s"))
.map((_,1))
// 根据field下标分区
//.keyBy(0)
.keyBy(t2 => t2._1)
.print()
结果:
2> (Hello,1)
16> (Spark,1)
2> (Hello,1)
16> (Flink,1)
reduce
val datastream = env.fromCollection(List("Hello Spark", "Hello Flink"))
datastream
.flatMap(line => line.split("\\s"))
.map((_, 1))
.keyBy(t2 => t2._1)
.reduce((x, y) => (x._1, x._2 + y._2))
.print()
结果:
16> (Flink,1)
2> (Hello,1)
16> (Spark,1)
2> (Hello,2)
fold
使用一个初始值,滚动折叠一个KV DataStream
val datastream = env.fromCollection(List("Hello Spark", "Hello Flink"))
datastream
.flatMap(line => line.split("\\s"))
.map((_, 1))
.keyBy(t2 => t2._1)
.fold(("", 0))((t1, t2) => (t2._1, t1._2 + t2._2))
.print()
结果:
16> (Spark,1)
16> (Flink,1)
2> (Hello,1)
2> (Hello,2)
aggregations
滚动聚合一个KV DataStream
val dataStream = env.fromCollection(List("zs A 1800", "ls A 1500", "ww A 1600"))
dataStream
.map(str => {
val arr = str.split("\\s")
(arr(1), arr(2).toInt)
})
.keyBy(0)
//.sum(1) // 14> (A,4900)
//.min(1) // 14> (A,1500)
//.max(1) // 14> (A,1800)
//.minBy(1) // 14> (A,1500)
.maxBy(1) // 14> (A,1800)
.print()
union
将两个或者多个DataSream组合为一个
val datastream1 = env.fromCollection(List("Hello Spark", "Hello Flink"))
val datastream2 = env.fromCollection(List("Hello Spark", "Hello Flink"))
val datastream3 = env.fromCollection(List("Hello Spark", "Hello Flink"))
datastream1
.union(datastream2, datastream3)
.print()
结果:
13> Hello Flink
12> Hello Spark
4> Hello Spark
5> Hello Flink
3> Hello Spark
4> Hello Flink
connect
连接两个流,允许类型不一致,可以共享状态
val datastream1 = env.fromCollection(List("Hello Spark", "Hello Flink"))
val datastream2 = env.fromCollection(List(("aa", 1), ("bb", 1)))
datastream1
.connect(datastream2)
.flatMap((str: String) => str.split("\\s"), (t2: (String,Int)) => t2._1.split("\\s"))
.print()
结果:
6> Hello
3> aa
4> bb
5> Hello
6> Flink
5> Spark
split
分流
val datastream = env.generateSequence(1, 10)
datastream
.split(num => {
if (num % 2 == 0) {
List("even")
} else {
List("odd")
}
})
.print()
结果:
7> 7
3> 3
8> 8
10> 10
1> 1
5> 5
4> 4
9> 9
2> 2
6> 6
select
对一个split后的流进行选择操作
val datastream = env.generateSequence(1, 10)
datastream
.split(num => {
if (num % 2 == 0) {
List("even")
} else {
List("odd")
}
})
.select("even","odd") // 获取偶数和奇数
.print()
结果:
8> 8
1> 1
6> 6
5> 5
2> 2
3> 3
9> 9
7> 7
4> 4
10> 10
iterate
基本概念:在流中创建“反馈(feedback)”循环,通过将一个算子的输出重定向到某个先前的算子。这对于定义不断更新模型的算法特别有用。
迭代的数据流向:DataStream → IterativeStream → DataStream
以下代码以流开始并连续应用迭代体。性别为male的元素将被发送回反馈(feedback)通道,继续迭代,其余元素将向下游转发,离开迭代。
val dataStream = env.socketTextStream("localhost", 8888)
dataStream
.map(line => {
val arr = line.split("\\s")
(arr(0), arr(1), arr(2))
})
.iterate(
iteration => {
var count = 0
iteration.map(t3 => {
count += 1
println(t3 + "\t" + count)
t3
})
(iteration.filter(_._3.equals("male")), iteration.filter(_._3.equals("female")))
})
.print()
结果:
(1,zs,male) 149
(1,zs,male) 150
(1,zs,male) 151
(3,ww,female) 1
16> (3,ww,female)
(1,zs,male) 152
(1,zs,male) 153
(1,zs,male) 154
五、Flink整体的系统架构
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-s6gWKXKV-1582679088385)(assets/image-20200220094134313.png)]
https://ci.apache.org/projects/flink/flink-docs-release-1.10/zh/concepts/runtime.html
Task&Operator chain
分布式计算中,Flink 将算子(operator)的 subtask *链接(chain)*成 task【类似于Spark中的Stage阶段】。每个 task 由一个线程执行。把算子链接成 tasks 能够减少线程间切换和缓冲的开销,在降低延迟的同时提高了整体吞吐量。
当前的flink应用由3个Task,5个SubTask构成,每一个SubTask会由1个Thread处理
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1IOpt8u5-1582679088386)(assets/image-20200220100232568.png)]
注:
- Flink中的Task等价于Spark中的Stage
- Flink根据Operator Chain划分任务Task,两种依据:Forward和Hash | Rebalance
Task Slots 和资源
每个 worker(TaskManager)都是一个 JVM 进程,并且可以在不同的线程中执行一个或多个 subtasks。为了控制 worker 接收 task 的数量,worker 拥有所谓的 task slots (至少一个)。
每个 task slots 代表 TaskManager 的一份固定资源子集。例如,具有三个 slots 的 TaskManager 会将其管理的内存资源分成三等份给每个 slot。 划分资源意味着 subtask 之间不会竞争资源,但是也意味着它们只拥有固定的资源。注意这里并没有 CPU 隔离,当前 slots 之间只是划分任务的内存资源。
通过调整 slot 的数量,用户可以决定 subtasks 的隔离方式。每个 TaskManager 有一个 slot 意味着每组 task 在一个单独的 JVM 中运行(例如,在一个单独的容器中启动)。拥有多个 slots 意味着多个 subtasks 共享同一个 JVM。 Tasks 在同一个 JVM 中共享 TCP 连接(通过多路复用技术)和心跳信息(heartbeat messages)。它们还可能共享数据集和数据结构,从而降低每个 task 的开销。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9Lk0anuv-1582679088386)(https://ci.apache.org/projects/flink/flink-docs-release-1.10/fig/tasks_slots.svg)]
默认情况下,Flink 允许 subtasks 共享 slots,即使它们是不同 tasks 的 subtasks,只要它们来自同一个 job。因此,一个 slot 可能会负责这个 job 的整个管道(pipeline)。允许 slot sharing 有两个好处:
- Flink 集群需要与 job 中使用的最高并行度一样多的 slots。这样不需要计算作业总共包含多少个 tasks(具有不同并行度)。
- 更好的资源利用率。在没有 slot sharing 的情况下,简单的 subtasks(source/map())将会占用和复杂的 subtasks (window)一样多的资源。通过 slot sharing,将示例中的并行度从 2 增加到 6 可以充分利用 slot 的资源,同时确保繁重的 subtask 在 TaskManagers 之间公平地获取资源。
APIs 还包含了 resource group 机制,它可以用来防止不必要的 slot sharing。
根据经验,合理的 slots 数量应该和 CPU 核数相同。在使用超线程(hyper-threading)时,每个 slot 将会占用 2 个或更多的硬件线程上下文(hardware thread contexts)。
- slot 是指 taskmanager 的并发执行能力;
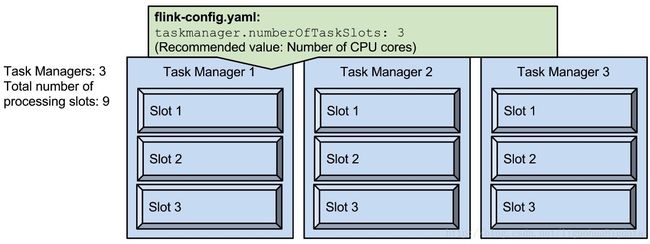
如上图所示:taskmanager.numberOfTaskSlots:3;即每一个 taskmanager 中的分配 3 个 TaskSlot, 3 个 taskmanager 一共有 9 个 TaskSlot。
- parallelism 是指 taskmanager 实际使用的并发能力
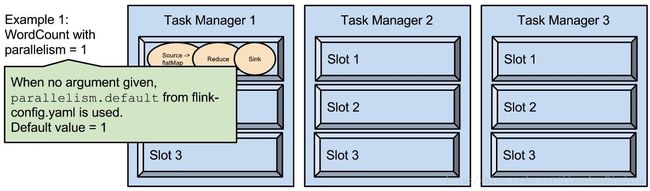
如上图所示:parallelism.default:1;即运行程序默认的并行度为 1,9 个 TaskSlot 只用了 1 个,有 8 个空闲。设置合适的并行度才能提高效率。
- parallelism 是可配置、可指定的;
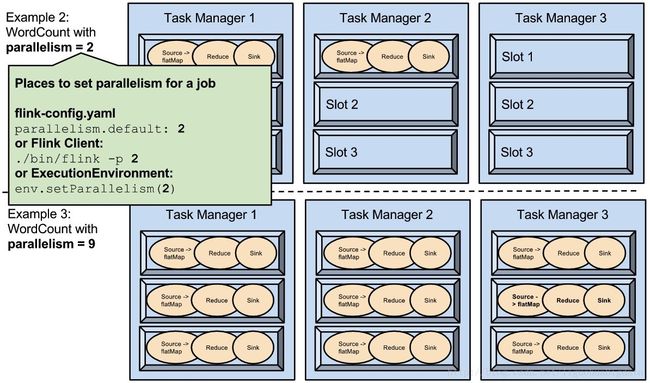
上图中 example2 每个算子设置的并行度是 2, example3 每个算子设置的并行度是 9。
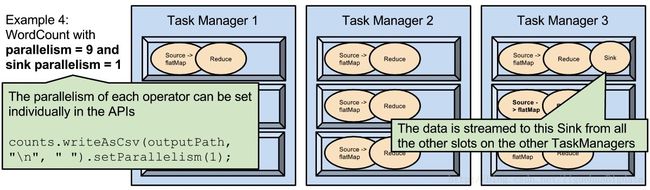
分析:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TjKaF6Qk-1582679088389)(assets/2.png)]
Job Managers、Task Managers、客户端(Clients)
Flink 运行时包含两类进程:
-
JobManagers (也称为 masters)协调分布式计算。它们负责调度任务、协调 checkpoints、协调故障恢复等。
每个 Job 至少会有一个 JobManager。高可用部署下会有多个 JobManagers,其中一个作为 leader,其余处于 standby 状态。
-
TaskManagers(也称为 workers)执行 dataflow 中的 tasks(准确来说是 subtasks ),并且缓存和交换数据 streams。
每个 Job 至少会有一个 TaskManager。
JobManagers 和 TaskManagers 有多种启动方式:直接在机器上启动(该集群称为 standalone cluster),在容器或资源管理框架,如 YARN 或 Mesos,中启动。TaskManagers 连接到 JobManagers,通知后者自己可用,然后开始接手被分配的工作。
客户端虽然不是运行时(runtime)和作业执行时的一部分,但它是被用作准备和提交 dataflow 到 JobManager 的。提交完成之后,客户端可以断开连接,也可以保持连接来接收进度报告。客户端既可以作为触发执行的 Java / Scala 程序的一部分,也可以在命令行进程中运行./bin/flink run ...。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oKc9kPNW-1582679088390)(https://ci.apache.org/projects/flink/flink-docs-release-1.10/fig/processes.svg?)]
详细剖析:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9X6QOLlz-1582679088390)(3.png)]
Flink On Yarn运行原理
https://ci.apache.org/projects/flink/flink-docs-release-1.10/zh/ops/deployment/yarn_setup.html
六、状态和容错
有状态操作或者操作算子在处理DataStream的元素或者事件的时候需要存储计算的中间状态,这就使得状态在整个Flink的精细化计算中有着非常重要的地位
如:
- 记录保存某个时间节点到当前时间节点的状态数据
- 在每分钟/小时/天汇总事件时,状态将保留待处理的汇总。
- 在数据点流上训练机器学习模型时,状态保持模型参数的当前版本。
- 当需要管理历史数据时,状态允许有效访问过去发生的事件。
在学习使用flink时,需要掌握了解状态,以便使用检查点状态容错并设置流应用保存点;flink同样支持多种状态备份,如:内存、文件系统、RocksDB等
Keyed State 与 Operator State
Flink 中有两种基本的状态:Keyed State 和 Operator State。
Keyed State
Keyed State 通常和 key 相关,仅可使用在 KeyedStream 的方法和算子中。
你可以把 Keyed State 看作分区或者共享的 Operator State, 而且每个 key 仅出现在一个分区内。 逻辑上每个 keyed-state 和唯一元组 <算子并发实例, key> 绑定,由于每个 key 仅”属于” 算子的一个并发,因此简化为 <算子, key>。
Keyed State 会按照 Key Group 进行管理。Key Group 是 Flink 分发 Keyed State 的最小单元; Key Group 的数目等于作业的最大并发数。在执行过程中,每个 keyed operator 会对应到一个或多个 Key Group
Operator State
对于 Operator State (或者 non-keyed state) 来说,每个 operator state 和一个并发实例进行绑定。 Kafka Connector 是 Flink 中使用 operator state 的一个很好的示例。 每个 Kafka 消费者的并发在 Operator State 中维护一个 topic partition 到 offset 的映射关系。
Operator State 在 Flink 作业的并发改变后,会重新分发状态,分发的策略和 Keyed State 不一样。
Raw State 与 Managed State
Keyed State 和 Operator State 分别有两种存在形式:managed and raw.
Managed State 由 Flink 运行时控制的数据结构表示,比如内部的 hash table 或者 RocksDB。 比如 “ValueState”, “ListState” 等。Flink runtime 会对这些状态进行编码并写入 checkpoint。
Raw State 则保存在算子自己的数据结构中。checkpoint 的时候,Flink 并不知晓具体的内容,仅仅写入一串字节序列到 checkpoint。
所有 datastream 的 function 都可以使用 managed state, 但是 raw state 则只能在实现算子的时候使用。 由于 Flink 可以在修改并发时更好的分发状态数据,并且能够更好的管理内存,因此建议使用 managed state(而不是 raw state)。
注意 如果你的 managed state 需要定制化的序列化逻辑, 为了后续的兼容性请参考 相应指南,Flink 的默认序列化器不需要用户做特殊的处理。
使用 Managed Keyed State
managed keyed state 接口提供不同类型状态的访问接口,这些状态都作用于当前输入数据的 key 下。换句话说,这些状态仅可在 KeyedStream 上使用,可以通过 stream.keyBy(...) 得到 KeyedStream.
不同类型的状态,如下所示:
-
ValueState: 保存一个可以更新和检索的值(如上所述,每个值都对应到当前的输入数据的 key,因此算子接收到的每个 key 都可能对应一个值)。 这个值可以通过update(T)进行更新,通过T value()进行检索。 -
ListState: 保存一个元素的列表。可以往这个列表中追加数据,并在当前的列表上进行检索。可以通过add(T)或者addAll(List)进行添加元素,通过Iterable get()获得整个列表。还可以通过update(List)覆盖当前的列表。 -
ReducingState: 保存一个单值,表示添加到状态的所有值的聚合。接口与ListState类似,但使用add(T)增加元素,会使用提供的ReduceFunction进行聚合。 -
AggregatingState: 保留一个单值,表示添加到状态的所有值的聚合。和ReducingState相反的是, 聚合类型可能与 添加到状态的元素的类型不同。接口与
ListState类似,但使用add(IN)添加的元素会用指定的AggregateFunction进行聚合。 -
FoldingState:ReducingState相反,聚合类型可能与添加到状态的元素类型不同。 接口与ListState类似,但使用add(T)添加的元素会用指定的FoldFunction折叠成聚合值。 -
MapState: 维护了一个映射列表。 你可以添加键值对到状态中,也可以获得反映当前所有映射的迭代器。使用put(UK,UV)或者putAll(Map)添加映射。 使用
get(UK)检索特定 key。 使用entries(),keys()和values()分别检索映射、键和值的可迭代视图。
注意:
- 所有类型的状态还有一个
clear()方法,清除当前 key 下的状态数据,也就是当前输入元素的 key。- 这些状态对象仅用于与状态交互。状态本身不一定存储在内存中,还可能在磁盘或其他位置。 另外需要牢记的是从状态中获取的值取决于输入元素所代表的 key。 因此,在不同 key 上调用同一个接口,可能得到不同的值。
- 必须创建一个
StateDescriptor,才能得到对应的状态句柄。 根据不同的状态类型,可以创建ValueStateDescriptor,ListStateDescriptor,ReducingStateDescriptor,FoldingStateDescriptor或MapStateDescriptor。- 状态通过
RuntimeContext进行访问,因此只能在 rich functions 中使用。
ValueState
ds
.flatMap(_.split("\\s"))
.map((_, 1L))
.keyBy(0)
// *************************************ValueState**************************************
.map(new RichMapFunction[(String, Long), (String, Long)] {
var state: ValueState[Long] = _
override def open(parameters: Configuration): Unit = {
val vsd = new ValueStateDescriptor[Long]("valueCount", createTypeInformation[Long], 0L)
state = getRuntimeContext.getState[Long](vsd)
}
override def map(value: (String, Long)): (String, Long) = {
state.update(state.value() + value._2)
(value._1, state.value())
}
})
// ***************************************************************************
.print()
ListState
ds
.flatMap(_.split("\\s"))
.map((_, 1L))
.keyBy(0)
// *************************************ListState**************************************
.map(new RichMapFunction[(String, Long), (String, Long)] {
var state: ListState[Long] = _
override def open(parameters: Configuration): Unit = {
val lsd = new ListStateDescriptor[Long]("wordcount", createTypeInformation[Long])
state = getRuntimeContext.getListState(lsd)
}
override def map(value: (String, Long)): (String, Long) = {
val word = value._1
val currentCount = value._2
state.add(currentCount)
var sum = 0L
state.get().forEach(n => {
sum += n
})
(word, sum)
}
})
// ***************************************************************************
.print()
ReducingState
// ************************************ReducingState***************************************
.map(new RichMapFunction[(String, Long), (String, Long)] {
var state: ReducingState[Long] = _
override def open(parameters: Configuration): Unit = {
val rsd = new ReducingStateDescriptor[Long](
"wordcount",
new ReduceFunction[Long] {
override def reduce(value1: Long, value2: Long): Long = value1 + value2
},
createTypeInformation[Long]
)
state = getRuntimeContext.getReducingState(rsd)
}
override def map(value: (String, Long)): (String, Long) = {
val word = value._1
val currentCount = value._2
state.add(currentCount)
(word, state.get())
}
})
// ***************************************************************************
.print()
FoldingState 已废弃
已废弃AggregatingState
// ************************************AggregatingState***************************************
.map(new RichMapFunction[(String, Long), (String, Long)] {
var state: AggregatingState[Long, Int] = _
override def open(parameters: Configuration): Unit = {
// 泛型1:In 泛型2: 累加器 泛型3:Out
val asd = new AggregatingStateDescriptor[Long, Long, Int](
"wordcount",
new AggregateFunction[Long, Long, Int] {
override def createAccumulator(): Long = 0L
override def add(value: Long, accumulator: Long): Long = value + accumulator
override def getResult(accumulator: Long): Int = accumulator.toInt
override def merge(a: Long, b: Long): Long = a + b
},
createTypeInformation[Long]
)
state = getRuntimeContext.getAggregatingState[Long, Long, Int](asd)
}
override def map(value: (String, Long)): (String, Long) = {
val word = value._1
val currentCount = value._2
state.add(currentCount)
(word, state.get())
}
})
// ***************************************************************************
.print()
MapState
// ************************************MapState***************************************
.map(new RichMapFunction[(String, Long), (String, Long)] {
var state: MapState[String, Long] = _
override def open(parameters: Configuration): Unit = {
val msd = new MapStateDescriptor[String, Long](
"wordcount",
createTypeInformation[String],
createTypeInformation[Long],
)
state = getRuntimeContext.getMapState(msd)
}
override def map(value: (String, Long)): (String, Long) = {
val word = value._1
val currentCount = value._2
if (state.get(word) != null) {
state.put(word, state.get(word) + value._2)
} else {
state.put(word, currentCount)
}
(word, state.get(word))
}
})
// ***************************************************************************
.print()
总结
-
Managed Keyed State使用语法
new Rich[Map|FlatMap]Function { // 状态类型 var state: 状态类型 = _ override def open(parameters: Configuration): Unit = { val desc = new 状态类型的描述对象 state = getRuntimeContext.获取对应的状态类型(desc) } override def map|flatMap(x):XXX = { // 状态数据更新 } } -
获取状态句柄的方法
ValueStategetState(ValueStateDescriptor ) ReducingState getReducingState(ReducingStateDescriptor ) ListState getListState(ListStateDescriptor ) AggregatingState
状态有效期 (TTL)
任何类型的 keyed state 都可以有 有效期 (TTL)。如果配置了 TTL 且状态值已过期,则会尽最大可能清除对应的值;在使用状态 TTL 前,需要先构建一个StateTtlConfig 配置对象。 然后把配置传递到 state descriptor 中启用 TTL 功能:
import org.apache.flink.api.common.state.StateTtlConfig
import org.apache.flink.api.common.state.ValueStateDescriptor
import org.apache.flink.api.common.time.Time
val ttlConfig = StateTtlConfig
// 状态数据的有效时长
.newBuilder(Time.seconds(1))
// 过期状态数据的更新策略:OnCreateAndWrite - 仅在创建和写入时更新 OnReadAndWrite - 读取时也更新
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
// 过期状态数据的可见性 NeverReturnExpired ReturnExpiredIfNotCleanedUp
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build
val stateDescriptor = new ValueStateDescriptor[String]("text state", classOf[String])
stateDescriptor.enableTimeToLive(ttlConfig)
基本案列
package com.netzhuo.state.ttl
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.common.state.{StateTtlConfig, ValueState, ValueStateDescriptor}
import org.apache.flink.api.common.time.Time
import org.apache.flink.configuration.Configuration
import org.apache.flink.runtime.state.filesystem.FsStateBackend
import org.apache.flink.streaming.api.CheckpointingMode
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment, createTypeInformation}
object QuickExample {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val ds: DataStream[String] = env.socketTextStream("localhost", 9999)
ds
.flatMap(_.split("\\s"))
.map((_, 1L))
.keyBy(0)
// *************************************ValueState**************************************
.map(new RichMapFunction[(String, Long), (String, Long)] {
var state: ValueState[Long] = _
override def open(parameters: Configuration): Unit = {
val vsd = new ValueStateDescriptor[Long]("valueCount", createTypeInformation[Long], 0L)
// 状态ttl
val ttlConfig = StateTtlConfig
// 状态数据有效期5s
.newBuilder(Time.seconds(5))
// 可选:在创建和写入时更新状态数据
// .OnCreateAndWrite - 仅在创建和写入时更新
// .OnReadAndWrite - 读取时也更新
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
// 可选:数据过期但未清除时的可见性配置
// .NeverReturnExpired - 不返回过期数据: 过期数据就像不存在一样,不管是否被物理删除。
// .ReturnExpiredIfNotCleanedUp - 会返回过期但未清理的数据: 在数据被物理删除前都会返回。
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build()
vsd.enableTimeToLive(ttlConfig)
state = getRuntimeContext.getState[Long](vsd)
}
override def map(value: (String, Long)): (String, Long) = {
state.update(state.value() + value._2)
(value._1, state.value())
}
})
.print()
env.execute("word count")
}
}
注意:
- 状态上次的修改时间会和数据一起保存在 state backend 中,因此开启该特性会增加状态数据的存储。
- 暂时只支持基于 processing time 的 TTL
- 如果用户以前没有开启TTL配置,在启动之前修改代码开启了TTL,在做状态恢复的时候系统启动不起来,会抛出兼容性失败以及StateMigrationException的异常。
- TTL 的配置并不会保存在 checkpoint/savepoint 中,仅对当前 Job 有效
- 当前开启 TTL 的 map state 仅在用户值序列化器支持 null 的情况下,才支持用户值为 null。如果用户值序列化器不支持 null, 可以用
NullableSerializer包装一层。
过期数据的清理
默认情况下,过期数据会在读取的时候被删除,例如 ValueState#value,同时会有后台线程定期清理(如果 StateBackend 支持的话)。可以通过 StateTtlConfig 配置关闭后台清理:
import org.apache.flink.api.common.state.StateTtlConfig
val ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.disableCleanupInBackground
.build
可以按照如下所示配置更细粒度的后台清理策略
全量快照时进行清理(Cleanup in full snapshot)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-l54nfVKB-1582679088392)(assets/3.png)]
另外,你可以启用全量快照时进行清理的策略,这可以减少整个快照的大小。当前实现中不会清理本地的状态,但从上次快照恢复时,不会恢复那些已经删除的过期数据。
import org.apache.flink.api.common.state.StateTtlConfig
import org.apache.flink.api.common.time.Time
val ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupFullSnapshot
.build
注意:这种策略在
RocksDBStateBackend的增量 checkpoint 模式下无效。
增量数据清理(Incremental cleanup)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5I0MWuy7-1582679088392)(assets/4.png)]
增量式清理状态数据,在状态访问或/和处理时进行。如果某个状态开启了该清理策略,则会在存储后端保留一个所有状态的惰性全局迭代器。 每次触发增量清理时,从迭代器中选择已经过期的数进行清理。该特性可以通过 StateTtlConfig 进行配置:
import org.apache.flink.api.common.state.StateTtlConfig
val ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupIncrementally(10, true) // 默认值5,false
.build
该策略有两个参数。 第一个是每次清理时检查状态的条目数,在每个状态访问时触发。第二个参数表示是否在处理每条记录时触发清理。 Heap backend 默认会检查 5 条状态,并且关闭在每条记录时触发清理。
注意:这种策略在
RocksDBStateBackend上启用无效。
在 RocksDB 压缩时清理
RocksDB是一个嵌入式的key-value存储,其中key和value是任意的字节流,底层进行异步压缩,会将key相同的数据进行compact(压缩; 但是并不对过期的state进行清理,因此可以通过配置compactFilter,让RocksDB在compact的时候对过期的state进行排除,这样的话RocksDB就会周期性的对数据进行合并压缩从而减少存储空间
import org.apache.flink.api.common.state.StateTtlConfig
val ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
//默认后台清理策略会每处理 1000 条数据进行一次
.cleanupInRocksdbCompactFilter(1000)
.build
使用Managed Operator State
用户可以通过实现 CheckpointedFunction 或 ListCheckpointed 接口来使用 managed operator state。
CheckpointedFunction
CheckpointedFunction 接口提供了访问 non-keyed state 的方法,需要实现如下两个方法:
// 在checkpoint时调用方法
void snapshotState(FunctionSnapshotContext context) throws Exception;
// 初始化或者恢复历史状态
void initializeState(FunctionInitializationContext context) throws Exception;
案例:自定义状态操作的SinkFunction,当满足阈值时将数据发送到下游
package com.netzhuo.state.managed.operator
import org.apache.flink.api.common.state.{ListState, ListStateDescriptor}
import org.apache.flink.runtime.state.{FunctionInitializationContext, FunctionSnapshotContext}
import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction
import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}
import org.apache.flink.streaming.api.scala._
import scala.collection.mutable.ListBuffer
// flink word count
object WordCountApplication {
def main(args: Array[String]): Unit = {
//1. flink程序运行的环境 自适应运行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2. 构建数据源对象
val dataStream = env.socketTextStream("localhost", 8888)
//3. 转换处理操作
dataStream
.flatMap(_.split("\\s"))
.map((_, 1))
// 分组
// 0 --> tuple2 word
.keyBy(0)
.sum(1)
// datastream 应用operator state
.addSink(new BufferingSink(3))
.setParallelism(1)
//4. 启动流式计算
env.execute("wordcount")
}
}
// 自定义状态操作的SinkFunction,当满足阈值时将数据发送到下游
class BufferingSink(threshold: Int) extends RichSinkFunction[(String, Int)] with CheckpointedFunction {
// 状态数据
var state: ListState[(String, Int)] = _
// 已缓存的写出元素
var bufferedElements: ListBuffer[(String, Int)] = ListBuffer[(String, Int)]()
/**
* 写出时调用处理方法
*
* @param value
* @param context
*/
override def invoke(value: (String, Int), context: SinkFunction.Context[_]): Unit = {
bufferedElements += value
if (bufferedElements.size == threshold) {
bufferedElements.foreach(t2 => {
println(t2)
})
bufferedElements.clear()
}
}
/**
* 在checkpoint时调用方法
*
* bufferedElements ---> State
*
* @param context
*/
override def snapshotState(context: FunctionSnapshotContext): Unit = {
state.clear()
bufferedElements.foreach(t2 => {
state.add(t2)
})
}
/**
* 初始化状态和恢复状态时
*
* @param context
*/
override def initializeState(context: FunctionInitializationContext): Unit = {
// 状态类型ListState
val lsd = new ListStateDescriptor[(String, Int)]("buffered-elements", classOf[(String, Int)])
// 获取历史的状态数据
// getListState Even-split 状态数据平均分配
// getUnionListState Union 每一个算子中包含所有的状态数据
state = context.getOperatorStateStore.getListState(lsd)
// 如果需要恢复状态 true
if (context.isRestored) {
val historyWordCount = state.get()
val iter = historyWordCount.iterator()
while (iter.hasNext) {
bufferedElements += iter.next()
}
}
}
}
状态恢复
向Flink集群提交Job
bin/flink run -c com.netzhuo.state.managed.operator.WordCountApplication /Users/netzhuo/工作/代码仓库/训练营备课代码/BigData/flink-day4/target/flink-day4-1.0-SNAPSHOT.jar
手动建立保存点Savepoint
JobID可以在Flink的WebUI获取
bin/flink cancel -m netzhuo:8081 -s /Users/netzhuo/data/flink/savepoint 2d27fda1e92592e769f8efad37d6ca6f
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/Users/netzhuo/app/flink-1.8.2/lib/slf4j-log4j12-1.7.15.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/Users/netzhuo/app/hadoop-2.6.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Cancelling job 2d27fda1e92592e769f8efad37d6ca6f with savepoint to /Users/netzhuo/data/flink/savepoint.
Cancelled job 2d27fda1e92592e769f8efad37d6ca6f. Savepoint stored in file:/Users/netzhuo/data/flink/savepoint/savepoint-2d27fd-a278a2bece1f.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2YT8z3uW-1582679088392)(assets/image-20200221113702959.png)]
重新运行Job,通过保存点恢复状态
bin/flink run -c com.netzhuo.state.managed.operator.WordCountApplication -s /Users/netzhuo/data/flink/savepoint/savepoint-2d27fd-a278a2bece1f /Users/netzhuo/工作/代码仓库/训练营备课代码/BigData/flink-day4/target/flink-day4-1.0-SNAPSHOT.jar
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OReH9wza-1582679088393)(assets/image-20200221114148192.png)]
ListCheckpointed
ListCheckpointed 接口是 CheckpointedFunction 的精简版,仅支持 even-split redistributuion 的 list state。同样需要实现两个方法:
// 需要返回一个将写入到 checkpoint 的对象列表,
List snapshotState(long checkpointId, long timestamp) throws Exception;
// 需要返回一个将写入到 checkpoint 的对象列表 若状态不可切分Collections.singletonList(MY_STATE)。
void restoreState(List state) throws Exception;
案列:CounterSource
class CounterSource extends RichParallelSourceFunction[scala.Long] with ListCheckpointed[java.lang.Long] {
@volatile
var isRunning: Boolean = true
var counter = 0L
override def snapshotState(l: Long, l1: Long): util.List[java.lang.Long] = Collections.singletonList(counter)
override def restoreState(list: util.List[java.lang.Long]): Unit = {
val state = list.iterator()
while (state.hasNext) {
counter = state.next()
}
}
override def run(ctx: SourceFunction.SourceContext[scala.Long]): Unit = {
val lock = ctx.getCheckpointLock
while (isRunning) {
Thread.sleep(1000)
lock.synchronized({
ctx.collect(counter)
counter += 1
})
}
}
override def cancel(): Unit = isRunning = false
}
State Backend(状态后端)
Flink 提供了多种 state backends,它用于指定状态的存储方式和位置。
状态可以位于 Java 的堆或堆外内存。取决于你的 state backend,Flink 也可以自己管理应用程序的状态。 为了让应用程序可以维护非常大的状态,Flink 可以自己管理内存(如果有必要可以溢写到磁盘)。 默认情况下,所有 Flink Job 会使用配置文件 flink-conf.yaml 中指定的 state backend。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ALkGnNnI-1582679088394)(https://ci.apache.org/projects/flink/flink-docs-release-1.10/fig/checkpoints.svg?)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GGxs3wmv-1582679088394)(assets/5.png)]
但是,配置文件中指定的默认 state backend 会被 Job 中指定的 state backend 覆盖
val env = StreamExecutionEnvironment.getExecutionEnvironment()
env.setStateBackend(...)
Flink目前支持三种state backend:
- MemoryStateBackend(默认):State数据保存在java堆内存中,执行checkpoint的时候,会把state的快照数据保存到jobmanager的内存中,基于内存的state backend在生产环境下不建议使用
- FsStateBackend:state数据保存在taskmanager的内存中,执行checkpoint的时候,会把state的快照数据保存到配置的文件系统中,可以使用hdfs等分布式文件系统
- RocksDBStateBackend(推荐):RocksDB跟上面的都略有不同,它会在本地文件系统中维护状态,state会直接写入本地rocksdb中。同时它需要配置一个远端的filesystem uri(一般是HDFS),在做checkpoint的时候,会把本地的数据直接复制到filesystem中。fail over的时候从filesystem中恢复到本地。RocksDB克服了state受内存限制的缺点,同时又能够持久化到远端文件系统中,比较适合在生产中使用
参阅资料:https://ci.apache.org/projects/flink/flink-docs-release-1.10/zh/ops/state/state_backends.html
使用方法
-
如果用户不配置,则系统使用默认实现(全局配置)
# The backend that will be used to store operator state checkpoints if # checkpointing is enabled. # # Supported backends are 'jobmanager', 'filesystem', 'rocksdb', or the #. # # state.backend: filesystem # Directory for checkpoints filesystem, when using any of the default bundled # state backends. # # state.checkpoints.dir: hdfs://namenode-host:port/flink-checkpoints # Default target directory for savepoints, optional. # # state.savepoints.dir: hdfs://namenode-host:port/flink-checkpoints # Flag to enable/disable incremental checkpoints for backends that # support incremental checkpoints (like the RocksDB state backend). # # state.backend.incremental: false -
如果用户设置了Job的状态后端,则使用Job指定实现
env.setStateBackend(new FsStateBackend("hdfs://xxx")) // 或 env.setStateBackend(new MemoryStateBackend()) // 或 env.setStateBackend(new RocksDBStateBackend("hdfs://xxx"))rocksdb需要导入额外依赖
<dependency> <groupId>org.apache.flinkgroupId> <artifactId>flink-statebackend-rocksdb_2.11artifactId> <version>1.8.2version> <scope>providedscope> dependency>
Checkpoint&Savapoint
CheckPoint是Flink实现故障容错的一种机制,系统会根据配置的检查点定期自动对程序计算状态进行备份。一旦程序在计算过程中出现故障,系统会选择一个最近的检查点进行故障恢复。
SavePoint是一种有效的运维手段,需要用户手动触发程序进行状态备份,本质也是在做CheckPoint。
实现故障恢复的先决条件:
- 持久的数据源,可以在一定时间内重播记录(例如,FlinkKafkaConsumer)
- 状态的永久性存储,通常是分布式文件系统(例如,HDFS)
CheckPoint使用方法
val env = StreamExecutionEnvironment.getExecutionEnvironment()
// 每 1000ms 开始一次 checkpoint
env.enableCheckpointing(1000)
// 高级选项:
// 设置模式为精确一次 (这是默认值)
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
// 确认 checkpoints 之间的时间会进行 500 ms
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500)
// Checkpoint 必须在一分钟内完成,否则就会被抛弃
env.getCheckpointConfig.setCheckpointTimeout(60000)
// 如果 task 的 checkpoint 发生错误,会阻止 task 失败,checkpoint 仅仅会被抛弃
env.getCheckpointConfig.setFailTasksOnCheckpointingErrors(false)
// 同一时间只允许一个 checkpoint 进行
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
状态后端 + 检查点 + 状态恢复
-
准备Flink应用
import java.util.Properties import org.apache.flink.api.common.functions.RichMapFunction import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor} import org.apache.flink.configuration.Configuration import org.apache.flink.contrib.streaming.state.RocksDBStateBackend import org.apache.flink.streaming.api.CheckpointingMode import org.apache.flink.streaming.api.environment.CheckpointConfig import org.apache.flink.streaming.api.scala._ import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer import org.apache.flink.streaming.util.serialization.SimpleStringSchema import org.apache.kafka.clients.consumer.ConsumerConfig object WordCountApplicationWithState { def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment // 状态后端 env.setStateBackend(new RocksDBStateBackend("hdfs://netzhuo:9000/170/flink")) // 检查点配置 env.enableCheckpointing(1000) env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE) env.getCheckpointConfig.setCheckpointTimeout(60000) env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500) env.getCheckpointConfig.setFailOnCheckpointingErrors(false) env.getCheckpointConfig.setMaxConcurrentCheckpoints(1) // 开启外部的检查点 env.getCheckpointConfig.enableExternalizedCheckpoints( CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION) // 在取消任务时,是否删除或者保留外部的检查点数据 // 构建数据源 val prop = new Properties() prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "netzhuo:9092") prop.put(ConsumerConfig.GROUP_ID_CONFIG, "g1") val dataStream = env.addSource(new FlinkKafkaConsumer[String]("flink", new SimpleStringSchema(), prop)) dataStream .flatMap(_.split("\\s")) .map((_, 1L)) .keyBy(0) .map(new RichMapFunction[(String, Long), (String, Long)] { var state: ValueState[Long] = _ override def open(parameters: Configuration): Unit = { val vsd = new ValueStateDescriptor[Long]("valueCount", createTypeInformation[Long], 0L) state = getRuntimeContext.getState[Long](vsd) } override def map(value: (String, Long)): (String, Long) = { state.update(state.value() + value._2) (value._1, state.value()) } }) .print() env.execute() } } -
将第三方依赖打成计算jar包
-
修改集群环境变量配置文件
vi ~/.bashrc export HADOOP_HOME=/usr/hadoop-2.6.0 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export HADOOP_CLASSPATH=`hadoop classpath` source .bashrc echo $HADOOP_CLASSPATH /Users/netzhuo/app/hadoop-2.6.0/etc/hadoop:/Users/netzhuo/app/hadoop-2.6.0/share/hadoop/common/lib/*:/Users/netzhuo/app/hadoop-2.6.0/share/hadoop/common/*:/Users/netzhuo/app/hadoop-2.6.0/share/hadoop/hdfs:/Users/netzhuo/app/hadoop-2.6.0/share/hadoop/hdfs/lib/*:/Users/netzhuo/app/hadoop-2.6.0/share/hadoop/hdfs/*:/Users/netzhuo/app/hadoop-2.6.0/share/hadoop/yarn/lib/*:/Users/netzhuo/app/hadoop-2.6.0/share/hadoop/yarn/*:/Users/netzhuo/app/hadoop-2.6.0/share/hadoop/mapreduce/lib/*:/Users/netzhuo/app/hadoop-2.6.0/share/hadoop/mapreduce/*:/Users/netzhuo/app/hadoop-2.6.0/etc/hadoop:/Users/netzhuo/app/hadoop-2.6.0/share/hadoop/common/lib/*:/Users/netzhuo/app/hadoop-2.6.0/share/hadoop/common/*:/Users/netzhuo/app/hadoop-2.6.0/share/hadoop/hdfs:/Users/netzhuo/app/hadoop-2.6.0/share/hadoop/hdfs/lib/*:/Users/netzhuo/app/hadoop-2.6.0/share/hadoop/hdfs/*:/Users/netzhuo/app/hadoop-2.6.0/share/hadoop/yarn/lib/*:/Users/netzhuo/app/hadoop-2.6.0/share/hadoop/yarn/*:/Users/netzhuo/app/hadoop-2.6.0/share/hadoop/mapreduce/lib/*:/Users/netzhuo/app/hadoop-2.6.0/share/hadoop/mapreduce/*:/Users/netzhuo/app/hadoop-2.6.0/contrib/capacity-scheduler/*.jar:/Users/netzhuo/app/hadoop-2.6.0/contrib/capacity-scheduler/*.jar -
向集群提交Flink应用
bin/flink run -c FlinkSourcesExample /Users/netzhuo/工作/代码仓库/训练营备课代码/BigData/flink-basic2/target/flink-basic2-1.0-SNAPSHOT-jar-with-dependencies.jar[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bEKqlciM-1582679088395)(assets/image-20200221160443725.png)]
-
获取最新的检查点
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0S3oNhsO-1582679088395)(assets/image-20200221160718780.png)]
-
通过最新检查点的状态数据恢复任务
bin/flink run -c WordCountApplicationWithState -s hdfs://netzhuo:9000/170/flink/3f3f1fc23ba9995613ee9c8a096acc77/chk-425 /Users/netzhuo/工作/代码仓库/训练营备课代码/BigData/flink-day4/target/flink-day4-1.0-SNAPSHOT.jar[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Gg8htvh1-1582679088396)(assets/image-20200221161441127.png)]
Savapoint使用方法
netzhuo@localhost ~/app/flink-1.8.2 bin/flink list -m netzhuo:8081
Waiting for response...
------------------ Running/Restarting Jobs -------------------
19.02.2020 22:34:25 : 6f710ea67f1d0f5ef28654298bbc9f9d : Flink Streaming Job (RUNNING)
--------------------------------------------------------------
No scheduled jobs.
netzhuo@localhost ~/app/flink-1.8.2 bin/flink cancel -m netzhuo:8081 -s /Users/netzhuo/data/sp 0f847576e5f3fcd568a8f2ae50cb0f9a
Cancelling job 0f847576e5f3fcd568a8f2ae50cb0f9a with savepoint to /Users/netzhuo/data/sp.
Cancelled job 0f847576e5f3fcd568a8f2ae50cb0f9a. Savepoint stored in file:/Users/netzhuo/data/sp/savepoint-0f8475-698da560de62.
常见问题
Flink计算发布之后是否还能够修改计算算子?
首先,这在Spark中是不允许的,因为Spark会持久化代码片段,一旦修改代码,必须删除Checkpoint,但是Flink仅仅存储各个算子的计算状态,如果用户修改代码,需要用户在有状态的操作算子上指定uid属性。
env.addSource(new FlinkKafkaConsumer[String]("topic01",new SimpleStringSchema(),props))
.uid("kakfa-consumer")
.flatMap(line => line.split("\\s+"))
.map((_,1))
.keyBy(0) //只可以写一个参数
.sum(1)
.uid("word-count") //唯一
.map(t=>t._1+"->"+t._2)
.print()
Flink Kafka如何保证精准一次的语义操作?
- https://www.cnblogs.com/ooffff/p/9482873.html
- https://www.jianshu.com/p/8cf344bb729a
- https://www.jianshu.com/p/de35bf649293
- https://blog.csdn.net/justlpf/article/details/80292375
- https://www.jianshu.com/p/c0af87078b9c (面试题)
六、窗口计算
Windows是流数据处理的核心。 Windows将流分成有限大小的“buckets”,我们可以在其上应用计算;
窗口计算应用的一般结构
Keyed Windows
stream
.keyBy(...)
.window(...) <- 必须指定: 窗口类型
[.trigger(...)] <- 可选: "trigger" (都有默认 触发器),决定窗口什么时候触发
[.evictor(...)] <- 可选: "evictor" (默认 没有剔出),剔出窗口中的元素
[.allowedLateness(...)] <- 可选: "lateness" (默认 0),不允许有迟到的数据
[.sideOutputLateData(...)] <- 可选: "output tag" 将迟到的数据输出到指定流中
.reduce/aggregate/fold/apply() <- 必须指定: "function",实现对窗口数据的聚合计算
[.getSideOutput(...)] <- 可选: "output tag" 获取Sideout的数据,一般处理迟到数据
Non-Keyed Windows
stream
.windowAll(...) <- 必须指定: 窗口类型
[.trigger(...)] <- 可选: "trigger" (都有默认 触发器),决定窗口什么时候触发
[.evictor(...)] <- 可选: "evictor" (默认 没有剔出),剔出窗口中的元素
[.allowedLateness(...)] <- 可选: "lateness" (默认 0),不允许有迟到的数据
[.sideOutputLateData(...)] <- 可选: "output tag" 将迟到的数据输出到指定流中
.reduce/aggregate/fold/apply() <- 必须指定: "function",实现对窗口数据的聚合计算
[.getSideOutput(...)] <- 可选: "output tag" 获取Sideout的数据,一般处理迟到数据
窗口的生命周期
简而言之,一旦应属于该窗口的第一个元素到达,就会创建一个窗口,并且当时间(事件或处理时间)超过其结束时间戳加上用户指定的允许延迟时,该窗口将被完全删除(请参见允许的延迟)。 Flink保证只删除基于时间的窗口,而不能删除其他类型的窗口,例如global windows
此外,每个窗口都将具有一个Trigger(请参见触发器)和一个Function(ProcessWindowFunction,ReduceFunction,AggregateFunction或FoldFunction)(请参见窗口函数)。该函数将包含要应用于窗口内容的计算,而触发器指定条件,在该条件下,可以认为该窗口已准备就绪,可以应用该函数。
除上述内容外,您还可以指定一个Evictor(请参阅Evictors),该触发器将在触发触发器后以及应用此功能之前和/或之后从窗口中删除元素。
Window Assigners
WindowAssigner负责将每个传入元素分配给一个或多个窗口。 Flink带有针对最常见用例的预定义窗口分配器,即滚动(翻滚)窗口,滑动窗口,会话窗口和全局窗口(tumbling windows, sliding windows, session windows and global windows)。您还可以通过扩展WindowAssigner类来实现自定义窗口分配器。
Tumbling Windows(翻滚窗口)
窗口大小固定,数据无重叠
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-isyfKtdC-1582679088396)(https://ci.apache.org/projects/flink/flink-docs-release-1.10/fig/tumbling-windows.svg)]
val env = StreamExecutionEnvironment.getExecutionEnvironment
val ds: DataStream[String] = env.socketTextStream("localhost", 9999)
ds
.flatMap(_.split("\\s"))
.map((_, 1L))
.keyBy(0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(10)))
.reduce((v1, v2) => (v1._1, v1._2 + v2._2))
.print()
env.execute("word count")
Sliding Windows(滑动窗口)
窗口大小固定,数据有重合
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uEt2riLY-1582679088397)(https://ci.apache.org/projects/flink/flink-docs-release-1.10/fig/sliding-windows.svg)]
val env = StreamExecutionEnvironment.getExecutionEnvironment
val ds: DataStream[String] = env.socketTextStream("localhost", 9999)
ds
.flatMap(_.split("\\s"))
.map((_, 1L))
.keyBy(0)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10),Time.seconds(5)))
.reduce((v1, v2) => (v1._1, v1._2 + v2._2))
.print()
env.execute("word count")
Session Windows(会话窗口)
窗口大小不固定 数据无重合
GAP 间隙
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-D5egsh9L-1582679088397)(https://ci.apache.org/projects/flink/flink-docs-release-1.10/fig/session-windows.svg?)]
val env = StreamExecutionEnvironment.getExecutionEnvironment
val ds: DataStream[String] = env.socketTextStream("localhost", 9999)
ds
.flatMap(_.split("\\s"))
.map((_, 1L))
.keyBy(0)
// 静态活跃间隙
//.window(ProcessingTimeSessionWindows.withGap(Time.seconds(5)))
// 动态活跃间隙
.window(ProcessingTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor[(String, Long)] {
override def extract(element: (String, Long)): Long = {
if (element._1.equals("a")) {
5000
} else {
1000
}
}
}))
.reduce((v1, v2) => (v1._1, v1._2 + v2._2))
.print()
Global Windows(全局窗口)
所有key相同的数据放到同一个窗口,该窗口永远不会关闭,需用户设置Trigger(默认:NeverTrigger)
val env = StreamExecutionEnvironment.getExecutionEnvironment
val ds: DataStream[String] = env.socketTextStream("localhost", 9999)
ds
.flatMap(_.split("\\s"))
.map((_, 1L))
.keyBy(0)
.window(GlobalWindows.create())
.trigger(CountTrigger.of(3))
.reduce((v1, v2) => (v1._1, v1._2 + v2._2))
.print()
env.execute("word count")
窗口函数
窗口函数可以是ReduceFunction,AggregateFunction,FoldFunction或ProcessWindowFunction之一。前两个可以更有效地执行(请参阅“状态大小”部分),因为Flink可以在每个窗口到达时以递增方式聚合它们。 ProcessWindowFunction获取窗口中包含的所有元素的Iterable以及有关元素所属的窗口的其他元信息。(更灵活)
ReduceFunction
对窗口内的数据,应用增量式的聚合(效率高)
ds
.flatMap(_.split("\\s"))
.map((_, 1L))
.keyBy(0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(3)))
.reduce(new ReduceFunction[(String, Long)] {
override def reduce(value1: (String, Long), value2: (String, Long)): (String, Long) = {
(value1._1,value1._2+value2._2)
}
})
.print()
AggregateFunction
AggregateFunction是ReduceFunction的通用版本,具有三种泛型:输入类型(IN),累加器类型(ACC)和输出类型(OUT)。
val env = StreamExecutionEnvironment.getExecutionEnvironment
val ds: DataStream[String] = env.socketTextStream("localhost", 9999)
ds
// a,10
// a,33
.map(line => {
val arr = line.split(",")
(arr(0), arr(1).toLong)
})
.keyBy(0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(10)))
.aggregate(new AggregateFunction[(String, Long), (Long, Long), Double] {
// (sum,count)
override def createAccumulator(): (Long, Long) = (0L, 0L)
override def add(value: (String, Long), accumulator: (Long, Long)): (Long, Long) = {
(accumulator._1 + value._2, accumulator._2 + 1L)
}
override def getResult(accumulator: (Long, Long)): Double = accumulator._1 / accumulator._2.toDouble
override def merge(a: (Long, Long), b: (Long, Long)): (Long, Long) = (a._1 + b._1, a._2 + b._2)
})
// a 21,5
.print()
env.execute("word count")
FoldFunction(已废弃)
val env = StreamExecutionEnvironment.getExecutionEnvironment
val ds: DataStream[String] = env.socketTextStream("localhost", 9999)
ds
.flatMap(_.split("\\s"))
.map((_, 1L))
.keyBy(0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.fold(("", 0l))((acc, t2) => (t2._1, acc._2 + t2._2))
.print()
ProcessWindowFunction
ProcessWindowFunction获取一个Iterable,该Iterable包含窗口的所有元素,以及一个Context对象,该对象可以访问时间和状态信息,从而使其比其他窗口函数更具灵活性。
val env = StreamExecutionEnvironment.getExecutionEnvironment
val ds: DataStream[String] = env.socketTextStream("localhost", 9999)
ds
.flatMap(_.split("\\s"))
.map((_, 1L))
.keyBy(t2 => t2._1)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.process(new ProcessWindowFunction[(String, Long), (String, Long), String, TimeWindow] {
/**
*
* @param key
* @param context
* @param elements
* @param out
*/
override def process(key: String, context: Context, elements: Iterable[(String, Long)], out: Collector[(String, Long)]): Unit = {
val window = context.window
val sdf = new SimpleDateFormat("HH:mm:ss")
println(sdf.format(window.getStart) + "<--->" + sdf.format(window.getEnd))
val result = elements.reduce((t1, t2) => (t1._1, t1._2 + t2._2))
out.collect(result)
}
})
.print()
ProcessWindowFunction + ReduceFunction
可以将ProcessWindowFunction与ReduceFunction,AggregateFunction或FoldFunction组合以在元素到达窗口时对其进行增量聚合。关闭窗口时,将向ProcessWindowFunction提供聚合结果。
val env = StreamExecutionEnvironment.getExecutionEnvironment
val ds: DataStream[String] = env.socketTextStream("localhost", 9999)
ds
.map(line => {
val arr = line.split(",")
(arr(0), arr(1).toLong)
})
.keyBy(t2 => t2._1)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
// 获取窗口最大的值
.reduce(
new ReduceFunction[(String, Long)] {
override def reduce(value1: (String, Long), value2: (String, Long)): (String, Long) = {
if (value1._2 > value2._2) {
value1
} else {
value2
}
}
},
new ProcessWindowFunction[(String, Long), String, String, TimeWindow] {
override def process(key: String, context: Context, elements: Iterable[(String, Long)], out: Collector[String]): Unit = {
val tuple = elements.iterator.next()
out.collect(context.window + " " + tuple)
}
}
)
.print()
在ProcessWindowFunction中使用窗口状态
globalState(), which allows access to keyed state that is not scoped to a windowwindowState(), which allows access to keyed state that is also scoped to the window
package window
import org.apache.flink.api.common.state.ValueStateDescriptor
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
object FlinkWindowDemo3 {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val ds: DataStream[String] = env.socketTextStream("localhost", 9999)
val globalTag = new OutputTag[(String, Long)]("global")
val resultDS = ds
.map(line => {
val arr = line.split(",")
(arr(0), arr(1).toLong)
})
.keyBy(t2 => t2._1)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.process(new ProcessWindowFunction[(String, Long), (String, Long), String, TimeWindow] {
var wvsd: ValueStateDescriptor[Long] = _
var gvsd: ValueStateDescriptor[Long] = _
override def open(parameters: Configuration): Unit = {
wvsd = new ValueStateDescriptor[Long]("windowState", classOf[Long])
gvsd = new ValueStateDescriptor[Long]("globalState", classOf[Long])
}
override def process(key: String, context: Context, elements: Iterable[(String, Long)], out: Collector[(String, Long)]): Unit = {
val windowState = context.windowState.getState[Long](wvsd)
val globalState = context.globalState.getState[Long](gvsd)
val result = elements.reduce((v1, v2) => (v1._1, v1._2 + v2._2))
windowState.update(windowState.value() + result._2)
globalState.update(globalState.value() + result._2)
// 窗口状态
out.collect((result._1, windowState.value()))
context.output(globalTag, (result._1, globalState.value()))
}
})
resultDS
.print("窗口输出")
resultDS.getSideOutput(globalTag).print("全局输出")
env.execute()
}
}
窗口触发器
触发器(Trigger)决定了窗口什么时候准备好被窗口函数处理。每个窗口分配器都带有一个默认的 Trigger。如果默认触发器不能满足你的要求,可以使用 trigger(...) 指定自定义的触发器。
触发器接口有五个方法来对不同的事件做出响应:
// 当每个元素被添加窗口时调用
public abstract TriggerResult onElement(T element, long timestamp, W window, TriggerContext ctx) throws Exception;
// 当注册的事件时间计时器被触发时调用。
public abstract TriggerResult onProcessingTime(long time, W window, TriggerContext ctx) throws Exception;
// 当注册的处理时间计时器被触发时调用。
public abstract TriggerResult onEventTime(long time, W window, TriggerContext ctx) throws Exception;
// 与状态 触发器相关,并且在相应的窗口合并时合并两个触发器的状态。例如,使用会话窗口时。
public void onMerge(W window, OnMergeContext ctx) throws Exception {
throw new UnsupportedOperationException("This trigger does not support merging.");
}
// 在删除相应窗口时执行所需的任何操作。
public abstract void clear(W window, TriggerContext ctx) throws Exception;
前三个函数决定了如何通过返回一个
TriggerResult来对其调用事件采取什么操作。TriggerResult可以是以下之一:
- CONTINUE 什么都不做
- FIRE_AND_PURGE 触发计算,然后清除窗口中的元素
- FIRE 触发计算
- PURGE 清除窗口中的元素
窗口分配器的默认触发器
- GlobalWindow的默认触发器是永不会被触发的 NeverTrigger
- Event-time Window是EventTimeTrigger
- Processing-time Window是ProcessingTimeTrigger
如:DeltaTrigger
val env = StreamExecutionEnvironment.getExecutionEnvironment
val ds: DataStream[String] = env.socketTextStream("localhost", 9999)
val trigger = DeltaTrigger.of[(String, Long), GlobalWindow](
1.0,
new DeltaFunction[(String, Long)] {
// 获取两个数据点得增量
// 如:a,1 & a,3
// 3 - 1 > 1 (threshold 1.0)
override def getDelta(oldDataPoint: (String, Long), newDataPoint: (String, Long)): Double = newDataPoint._2 - oldDataPoint._2
},
createTypeInformation[(String, Long)].createSerializer(env.getConfig)
)
val resultDS = ds
.map(line => {
val arr = line.split(",")
(arr(0), arr(1).toLong)
})
.keyBy(t2 => t2._1)
.window(GlobalWindows.create())
.trigger(trigger)
.reduce((v1, v2) => (v1._1, v1._2 + v2._2))
.print()
env.execute()
Evictors(驱逐器)
可以使用evictor(…)方法完成操作。驱逐者可以在触发器触发后,应用窗口功能之前和/或之后从窗口中删除元素
Flink附带了三个预先实施的驱逐程序。这些是:
- CountEvictor:从窗口中保留用户指定数量的元素,并从窗口缓冲区的开头丢弃其余的元素。
- DeltaEvictor:采用DeltaFunction和阈值,计算窗口缓冲区中最后一个元素与其余每个元素之间的增量,并删除增量大于或等于阈值的元素。
- TimeEvictor:以毫秒为单位的间隔作为参数,对于给定的窗口,它将在其元素中找到最大时间戳max_ts,并删除所有时间戳小于max_ts-interval的元素。
val env = StreamExecutionEnvironment.getExecutionEnvironment
val ds: DataStream[String] = env.socketTextStream("localhost", 9999)
ds
.windowAll(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.evictor(new Evictor[String, TimeWindow] {
// 在计算前驱逐不符合要求的数据
override def evictBefore(elements: lang.Iterable[TimestampedValue[String]], size: Int, window: TimeWindow, evictorContext: Evictor.EvictorContext): Unit = {
evict(elements, size, evictorContext)
}
override def evictAfter(elements: lang.Iterable[TimestampedValue[String]], size: Int, window: TimeWindow, evictorContext: Evictor.EvictorContext): Unit = {
}
def evict(elements: lang.Iterable[TimestampedValue[String]], size: Int, ctx: Evictor.EvictorContext): Unit = {
val iter = elements.iterator()
while (iter.hasNext) {
val line = iter.next().getValue
if (line.startsWith("ERROR") || line.startsWith("error")) {
iter.remove()
}
}
}
})
.apply((window, iter, out: Collector[String]) => {
iter.foreach(line => out.collect(window + " " + line))
})
.print()
env.execute()
基于事件时间的延迟数据处理
一旦设置基于EventTime处理,用户必须声明水位线的计算策略,系统需要给每一个流计算出水位线时间T,只有窗口的end time T' < = watermarker(T)的时候,窗口才会被触发。在Flink当中需要用户实现水位线计算的方式,系统并不提供实现。
触发水位线的计算方式
有两种:
①一种是基于定时Interval(推荐)
②通过记录触发,每来一条记录系统会立即更新水位线。
定时Interval
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// 时间特征
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// 水位线计算周期
env.getConfig.setAutoWatermarkInterval(1000)
val ds: DataStream[String] = env.socketTextStream("localhost", 9999)
ds
.map(line => {
val arr = line.split(",")
(arr(0), arr(1).toLong)
})
.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks[(String, Long)] {
// 延迟阈值
val lateness = 2000L
// max eventTime
var maxEventTime = 0L
override def getCurrentWatermark: Watermark = {
// wm = eventTime - lateness
println(s"wm $maxEventTime-$lateness")
new Watermark(maxEventTime - lateness)
}
override def extractTimestamp(element: (String, Long), previousElementTimestamp: Long): Long = {
maxEventTime = Math.max(element._2, maxEventTime)
element._2
}
})
.keyBy(t2 => t2._1)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.allowedLateness(Time.seconds(2))
.process(new ProcessWindowFunction[(String, Long), String, String, TimeWindow] {
override def process(key: String, context: Context, elements: Iterable[(String, Long)], out: Collector[String]): Unit = {
elements.foreach(t2 => out.collect(context.window + " " + t2))
}
})
.print()
env.execute()
// -----------------------------
nc -lk 9999
a,1000
a,6000
a,2000
a,7000
// ==============================
TimeWindow{start=0, end=5000} (a,1000)
TimeWindow{start=0, end=5000} (a,2000)
数据驱动水位线计算
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// 时间特征
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// 水位线计算周期
env.getConfig.setAutoWatermarkInterval(1000)
val ds: DataStream[String] = env.socketTextStream("localhost", 9999)
ds
.map(line => {
val arr = line.split(",")
(arr(0), arr(1).toLong)
})
.assignTimestampsAndWatermarks(new AssignerWithPunctuatedWatermarks[(String, Long)] {
// 延迟阈值
val lateness = 2000L
// max eventTime
var maxEventTime = 0L
override def checkAndGetNextWatermark(lastElement: (String, Long), extractedTimestamp: Long): Watermark = {
println(s"wm $maxEventTime-$lateness")
new Watermark(maxEventTime - lateness)
}
override def extractTimestamp(element: (String, Long), previousElementTimestamp: Long): Long = {
maxEventTime = Math.max(element._2, maxEventTime)
element._2
}
})
.keyBy(t2 => t2._1)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.allowedLateness(Time.seconds(2))
.process(new ProcessWindowFunction[(String, Long), String, String, TimeWindow] {
override def process(key: String, context: Context, elements: Iterable[(String, Long)], out: Collector[String]): Unit = {
elements.foreach(t2 => out.collect(context.window + " " + t2))
}
})
.print()
env.execute()
延迟数据处理方法
有两种:
默认丢弃
旁路输出
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// 时间特征
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// 水位线计算周期
env.getConfig.setAutoWatermarkInterval(1000)
val ds: DataStream[String] = env.socketTextStream("localhost", 9999)
val resultDataStream = ds
.map(line => {
val arr = line.split(",")
(arr(0), arr(1).toLong)
})
.assignTimestampsAndWatermarks(new AssignerWithPunctuatedWatermarks[(String, Long)] {
// 延迟阈值
val lateness = 2000L
// max eventTime
var maxEventTime = 0L
override def checkAndGetNextWatermark(lastElement: (String, Long), extractedTimestamp: Long): Watermark = {
println(s"wm $maxEventTime-$lateness")
new Watermark(maxEventTime - lateness)
}
override def extractTimestamp(element: (String, Long), previousElementTimestamp: Long): Long = {
maxEventTime = Math.max(element._2, maxEventTime)
element._2
}
})
.keyBy(t2 => t2._1)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.allowedLateness(Time.seconds(2))
.sideOutputLateData(new OutputTag[(String, Long)]("lateData"))
.process(new ProcessWindowFunction[(String, Long), String, String, TimeWindow] {
override def process(key: String, context: Context, elements: Iterable[(String, Long)], out: Collector[String]): Unit = {
elements.foreach(t2 => out.collect(context.window + " " + t2))
}
})
resultDataStream
.print("窗口计算:")
resultDataStream
.getSideOutput(new OutputTag[(String, Long)]("lateData"))
.print("延迟数据:")
env.execute()
窗口Join
一般用法可以总结如下:
stream.join(otherStream)
.where()
.equalTo()
.window()
.apply()
Tumbling Window Join
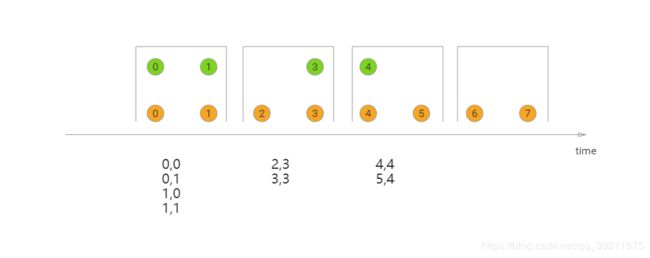
package window
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.watermark.Watermark
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
object FlinkWindowDemo7 {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.getConfig.setAutoWatermarkInterval(1000)
env.setParallelism(1)
/**
* 101,1,1000
* 104,1,6000
* 102,1,2000
* 105,1,7000
*/
val orderInfo: DataStream[String] = env.socketTextStream("localhost", 9999)
/**
* 1,zs,1000
* 4,zl,7000
*/
val userInfo: DataStream[String] = env.socketTextStream("localhost", 8888)
val userInfoWithWM = userInfo.map(
line => {
val arr = line.split(",")
// userId,name,ts
(arr(0), arr(1), arr(2).toLong)
})
.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks[(String, String, Long)] {
// 延迟阈值
val lateness = 2000L
// max eventTime
var maxEventTime = 0L
override def getCurrentWatermark: Watermark = {
// wm = eventTime - lateness
// println(s"wm $maxEventTime-$lateness")
new Watermark(maxEventTime - lateness)
}
override def extractTimestamp(element: (String, String, Long), previousElementTimestamp: Long): Long = {
maxEventTime = Math.max(element._3, maxEventTime)
element._3
}
})
orderInfo
.map(line => {
val arr = line.split(",")
// orderId,userId,ts
(arr(0), arr(1), arr(2).toLong)
})
.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks[(String, String, Long)] {
// 延迟阈值
val lateness = 2000L
// max eventTime
var maxEventTime = 0L
override def getCurrentWatermark: Watermark = {
// wm = eventTime - lateness
// println(s"wm $maxEventTime-$lateness")
new Watermark(maxEventTime - lateness)
}
override def extractTimestamp(element: (String, String, Long), previousElementTimestamp: Long): Long = {
maxEventTime = Math.max(element._3, maxEventTime)
element._3
}
})
.join(userInfoWithWM)
// left userId
.where(t3 => t3._2)
// right userId
.equalTo(_._1)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.allowedLateness(Time.seconds(2))
.apply((left, right) => {
(left._1, left._2, right._2, left._3)
})
/**
* (101,1,zs,1000)
* (102,1,zs,2000)
*/
.print()
env.execute()
}
}
Sliding Window Join
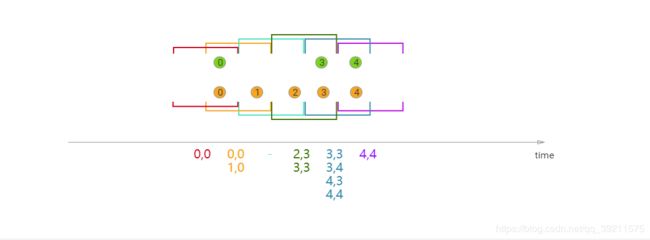
package window
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.watermark.Watermark
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
/**
* 基于滑动窗口 两个流的Join
*/
object FlinkWindowDemo8 {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.getConfig.setAutoWatermarkInterval(1000)
env.setParallelism(1)
/**
* a,1,1000
* b,2,6000
*/
val leftStream: DataStream[String] = env.socketTextStream("localhost", 9999)
/**
* a,bj,1000
* c,tj,7000
*/
val rightStream: DataStream[String] = env.socketTextStream("localhost", 8888)
val leftFinalStream = leftStream.map(
line => {
val arr = line.split(",")
// tag,id,ts
(arr(0), arr(1), arr(2).toLong)
})
.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks[(String, String, Long)] {
// 延迟阈值
val lateness = 2000L
// max eventTime
var maxEventTime = 0L
override def getCurrentWatermark: Watermark = {
new Watermark(maxEventTime - lateness)
}
override def extractTimestamp(element: (String, String, Long), previousElementTimestamp: Long): Long = {
maxEventTime = Math.max(element._3, maxEventTime)
element._3
}
})
.setParallelism(1)
rightStream
.map(line => {
val arr = line.split(",")
// tag,city,ts
(arr(0), arr(1), arr(2).toLong)
})
.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks[(String, String, Long)] {
// 延迟阈值
val lateness = 2000L
// max eventTime
var maxEventTime = 0L
override def getCurrentWatermark: Watermark = {
new Watermark(maxEventTime - lateness)
}
override def extractTimestamp(element: (String, String, Long), previousElementTimestamp: Long): Long = {
maxEventTime = Math.max(element._3, maxEventTime)
element._3
}
})
.setParallelism(1)
.join(leftFinalStream)
.where(_._1)
.equalTo(_._1)
.window(SlidingEventTimeWindows.of(Time.seconds(5), Time.seconds(2)))
.allowedLateness(Time.seconds(2))
.apply((left, right) => {
(left._1, left._2, right._2, left._3)
})
/**
* (a,bj,1,1000)
*/
.print()
env.execute()
}
}
Session Window Join
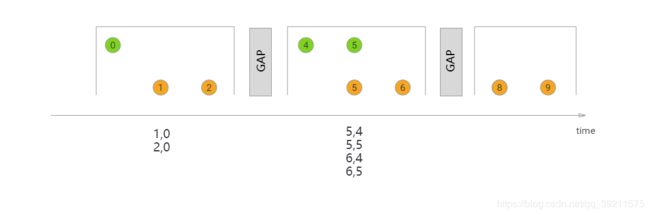
import org.apache.flink.streaming.api.windowing.assigners.EventTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
...
val orangeStream: DataStream[Integer] = ...
val greenStream: DataStream[Integer] = ...
orangeStream.join(greenStream)
.where(elem => /* select key */)
.equalTo(elem => /* select key */)
.window(EventTimeSessionWindows.withGap(Time.milliseconds(1)))
.apply { (e1, e2) => e1 + "," + e2 }
Interval Join
The interval join joins elements of two streams (we’ll call them A & B for now) with a common key and where elements of stream B have timestamps that lie in a relative time interval to timestamps of elements in stream A.
This can also be expressed more formally as b.timestamp ∈ [a.timestamp + lowerBound; a.timestamp + upperBound] or a.timestamp + lowerBound <= b.timestamp <= a.timestamp + upperBound
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xrr9xUpy-1582679088399)(https://ci.apache.org/projects/flink/flink-docs-release-1.10/fig/interval-join.svg?v)]
orangeElem.ts + lowerBound <= greenElem.ts <= orangeElem.ts + upperBound
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
...
val orangeStream: DataStream[Integer] = ...
val greenStream: DataStream[Integer] = ...
orangeStream
.keyBy(elem => /* select key */)
.intervalJoin(greenStream.keyBy(elem => /* select key */))
.between(Time.milliseconds(-2), Time.milliseconds(1))
.process(new ProcessJoinFunction[Integer, Integer, String] {
override def processElement(left: Integer, right: Integer, ctx: ProcessJoinFunction[Integer, Integer, String]#Context, out: Collector[String]): Unit = {
out.collect(left + "," + right);
}
});
});
七、Standalone Cluster High Availability
https://ci.apache.org/projects/flink/flink-docs-release-1.10/zh/ops/jobmanager_high_availability.html
The general idea of JobManager high availability for standalone clusters is that there is a single leading JobManager at any time and multiple standby JobManagers to take over leadership in case the leader fails. This guarantees that there is no single point of failureand programs can make progress as soon as a standby JobManager has taken leadership. There is no explicit distinction between standby and master JobManager instances. Each JobManager can take the role of master or standby.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oGZUhAO7-1582679088400)(https://ci.apache.org/projects/flink/flink-docs-release-1.10/fig/jobmanager_ha_overview.png)]
搭建过程
先决条件(略)
- 安装JDK
- 安装HADOOP HDFS-HA
- 安装Zookeeper
Flink环境构建
- 配置HADOOP_CLASSPATH
[root@CentOSX ~]# vi .bashrc
HADOOP_HOME=/usr/hadoop-2.9.2
JAVA_HOME=/usr/java/latest
PATH=$PATH:$/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
CLASSPATH=.
export JAVA_HOME
export PATH
export CLASSPATH
export HADOOP_HOME
HADOOP_CLASSPATH=`hadoop classpath`
export HADOOP_CLASSPATH
[root@CentOSX ~]# source .bashrc
[root@CentOSX ~]# echo $HADOOP_CLASSPATH
/usr/hadoop-2.9.2/etc/hadoop:/usr/hadoop-2.9.2/share/hadoop/common/lib/*:/usr/hadoop-2.9.2/share/hadoop/common/*:/usr/hadoop-2.9.2/share/hadoop/hdfs:/usr/hadoop-2.9.2/share/hadoop/hdfs/lib/*:/usr/hadoop-2.9.2/share/hadoop/hdfs/*:/usr/hadoop-2.9.2/share/hadoop/yarn/lib/*:/usr/hadoop-2.9.2/share/hadoop/yarn/*:/usr/hadoop-2.9.2/share/hadoop/mapreduce/lib/*:/usr/hadoop-2.9.2/share/hadoop/mapreduce/*:/usr/hadoop-2.9.2/contrib/capacity-scheduler/*.jar
- 上传Flink,配置Flink
[root@CentOSX ~]# tar -zxf flink-1.8.1-bin-scala_2.11.tgz -C /usr/
[root@CentOSA ~]# cd /usr/flink-1.8.1
[root@CentOSA flink-1.8.1]# vi conf/flink-conf.yaml
#==============================================================================
# Common
#==============================================================================
taskmanager.numberOfTaskSlots: 4
parallelism.default: 3
#==============================================================================
# High Availability
#==============================================================================
high-availability: zookeeper
high-availability.storageDir: hdfs:///flink/ha/
high-availability.zookeeper.quorum: CentOSA:2181,CentOSB:2181,CentOSC:2181
high-availability.zookeeper.path.root: /flink
high-availability.cluster-id: /default_ns
#==============================================================================
# Fault tolerance and checkpointing
#==============================================================================
state.backend: rocksdb
state.checkpoints.dir: hdfs:///flink-checkpoints
state.savepoints.dir: hdfs:///flink-savepoints
state.backend.incremental: true
[root@CentOSX flink-1.8.1]# vi conf/masters
CentOSA:8081
CentOSB:8081
CentOSC:8081
[root@CentOSA flink-1.8.1]# vi conf/slaves
CentOSA
CentOSB
CentOSC
启动Flink集群
[root@CentOSA flink-1.8.1]# ./bin/start-cluster.sh
Starting HA cluster with 3 masters.
Starting standalonesession daemon on host CentOSA.
Starting standalonesession daemon on host CentOSB.
Starting standalonesession daemon on host CentOSC.
Starting taskexecutor daemon on host CentOSA.
Starting taskexecutor daemon on host CentOSB.
Starting taskexecutor daemon on host CentOSC.
等集群启动完成后,查看JobManager任务的日志,在lead主机中可以看到:
http://xxx:8081 was granted leadership with leaderSessionID=f5338c3f-c3e5-4600-a07c-566e38bc0ff4
测试HA
登陆获取leadership的节点,然后执行以下指令
[root@CentOSB flink-1.8.1]# ./bin/jobmanager.sh stop
查看其它节点,按照上诉的测试方式,可以查找leadership日志输出的节点,该节点就是master节点。