编译技术,从BNF范式到文法识别简介
今日漫谈的是编译技术,作为计算机科学中的皇后,一只是编程中最为关键的技术之一,但由于太过繁杂,往往不被一般开发者重视。但其实,它是计算机代码优美结构的基石,了解编译技术,往往能让你成为更加优秀的程序员。
我作为编译原理的初学者,仅仅是谈一些个人的心得和体会,对一些部分难免也有疏漏,还请谅解和指正。
语言和计算机编程语言
编程语言的诞生,源于对计算机控制的难题。人和人交谈用自然语言即可,但计算机只认识指令,例如,我们个人电脑上用的intel的CPU,常用的指令集就有x86,x86-64,MMX,SSE,SSE2,SSE3等。
指令就是按照规则编排的数字信号,由CPU硬件电路直接识别,那么我们如何希望直接控制,就要用机器码对其进行操作,但我们希望简单的方式来描述,计算机发明的最初,人们便使用助记符也就是常说的汇编指令来帮助人们编写这些指令。
如下,是dos下的汇编helloworld:
;;;;;;;;;;;;;;;;;;;;;hello.asm;;;;;;;;;;;;;;;;;;;;;;;;;;;;
assume cs:code,ds:data
data segment
db "hello world"
data ends
code segment
start:
mov ax,data
mov ds,ax
mov bx,0b800h
mov es,bx
mov cx,11
mov si,0
mov bx,0
mov ah,01000010b
s:mov al,ds:[si]
mov es:[bx],ax
mov es:[bx+1],ah
inc si
add bx,2
loop s
mov ax,4c00h
int 21h
code ends
end start
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; 这种方法,可以将程序代码保存在电脑中,修改和编辑都很简便。但要人理解还很困难,编译器就在帮助我们,将高级语言转换成为这种低级的机器码或汇编指令,说白了,编译器就是一个字符串处理程序,将一种格式编写的字符串数据转换成另一种。输入是源代码的文本文件,输出是低级语言或机器码。
那么,我们为了让计算机识别我们定义的一种编程语言,都要做哪些工作呢?
语言的描述——BNF范式
首先我们需要定义我语言的规范,为什么不用自然语言?因为太难了,现在自然语言处理,仍然是世界性的难题,目前还没有哪种程序能够将自然语言处理的很好,所以我们不得已,只能放弃。
乔姆斯基(Chomsky)于1956年建立形式语言的描述以来,形式语言的理论发展很快。他将文法分成四种类型,即0型、1型、2型和3型,0型即自然语言文法,1型称为上下文相关文法,2型称为上下文无关文法,3型称为正则文法。
2型文法和3型文法在计算机中应用较为广泛,主要是因为其限制较多,处理较为容易。
为了描述一个文法,我们常常使用巴斯克范式(BNF范式)来描述一个文法的结构:
<句子> ::= <主语> <谓语> <宾语>
<谓语> ::= <动词> | <动词短语>
<主语> ::= 你 | 我 | 他这里的BNF范式实际上应该叫做扩展巴斯克范式(EBNF),而且并没有定义完整,只是一个演示,每一行范式的左边的部分,称为非终结符,而主语那一行,右边的每个词,都称为终结符,如果定义完整时,应该每一个非终结符都有定义,都要能从终结符和非终结符推倒而来。这个BNF范式表示了每一个语法成分是应该由怎样的结构组成的。
抽象语法树(AST)
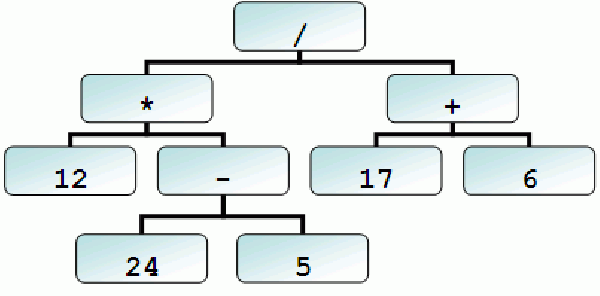
有了BNF范式定义我们的文法规则,那么我们在识别一个文法的时候,就能对其构建一棵抽象语法树(AST),这个语法树就是帮助我们进行代码编译工作的核心数据结构。
例如,12*(24-5)/(17+6)的抽象语法树:
文法的识别
如果我们定义了一个文法,那么我们用什么样的方法识别它呢?
这里我们介绍两种最常见的方法,自顶向下分析法和自底向上分析法。
这是两种解决问题的思路,一种是从整体上看,不断的推倒当前语法树下面应该构建的部分是什么,一种是从局部入手,不断归约可能的语法树,然后将它们组合起来。