一致性哈希算法-应用
一致性Hash负载均衡算法实现
1. Hash函数
要将对象和服务器映射到Hash环中,需要计算出来哈希码,这就需要有Hash函数来完成,也就是关系到使用的哈希算法。使用一个好的哈希算法是很重要的,为什么这么说呢,拿我们上面提到的缓存服务来说,一个完美的解决方案是需要数据分配的平衡,假如Hash环的映射是这样的:

哈希码聚集.jpg
Hash码数值落在一个小区间内,出现Hash码聚集情况,那么从上图可以看到缓存数据全部由c3节点的服务器存储,出现数据分配不平衡。那么就需要一个好的哈希处理使得哈希码在环中的分配尽可能得分散,类似这样:

哈希码分散.jpg
上面说到过,环中数值点的取值范围为[0,2^32-1],也就是说我们通过Hash函数计算出来的这些哈希码数值应该避免集中在某一小区间范围内。
Hash算法对于一致性Hash负载均衡的作用可见一斑,而写出好的适用于一致性Hash负载均衡的Hash算法是需要些技术能力的,这里不研究如何写,而是查阅已有的实现方式。
xmemcached:哈希函数
xmemcached是memcached的java版本的客户端。它其中包含了一致性Hash算法的实现。
网上内容摘抄:Memcached在实现分布集群部署时,Memcached服务端的之间是没有通讯的,服务端是伪分布式,实现分布式是由客户端实现的,客户端实现了分布式算法把数据保存到不同的Memcached服务端。
HashAlgorithm.java
package net.rubyeye.xmemcached;
import java.io.UnsupportedEncodingException;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import java.util.zip.CRC32;
import net.rubyeye.xmemcached.exception.MemcachedClientException;
import net.rubyeye.xmemcached.utils.ByteUtils;
/**
* Known hashing algorithms for locating a server for a key. Note that all hash algorithms return
* 64-bits of hash, but only the lower 32-bits are significant. This allows a positive 32-bit number
* to be returned for all cases.
*/
public enum HashAlgorithm {
/**
* Native hash (String.hashCode()).
*/
NATIVE_HASH,
/**
* CRC32_HASH as used by the perl API. This will be more consistent both across multiple API users
* as well as java versions, but is mostly likely significantly slower.
*/
CRC32_HASH,
/**
* FNV hashes are designed to be fast while maintaining a low collision rate. The FNV speed allows
* one to quickly hash lots of data while maintaining a reasonable collision rate.
*
* @see http://www.isthe.com/chongo/tech/comp/fnv/
* @see http://en.wikipedia.org/wiki/Fowler_Noll_Vo_hash
*/
FNV1_64_HASH,
/**
* Variation of FNV.
*/
FNV1A_64_HASH,
/**
* 32-bit FNV1.
*/
FNV1_32_HASH,
/**
* 32-bit FNV1a.
*/
FNV1A_32_HASH,
/**
* MD5-based hash algorithm used by ketama.
*/
KETAMA_HASH,
/**
* From mysql source
*/
MYSQL_HASH,
ELF_HASH,
RS_HASH,
/**
* From lua source,it is used for long key
*/
LUA_HASH,
ELECTION_HASH,
/**
* The Jenkins One-at-a-time hash ,please see http://www.burtleburtle.net/bob/hash/doobs.html
*/
ONE_AT_A_TIME;
private static final long FNV_64_INIT = 0xcbf29ce484222325L;
private static final long FNV_64_PRIME = 0x100000001b3L;
private static final long FNV_32_INIT = 2166136261L;
private static final long FNV_32_PRIME = 16777619;
/**
* Compute the hash for the given key.
*
* @return a positive integer hash
*/
public long hash(final String k) {
long rv = 0;
switch (this) {
case NATIVE_HASH:
rv = k.hashCode();
break;
case CRC32_HASH:
// return (crc32(shift) >> 16) & 0x7fff;
CRC32 crc32 = new CRC32();
crc32.update(ByteUtils.getBytes(k));
rv = crc32.getValue() >> 16 & 0x7fff;
break;
case FNV1_64_HASH: {
// Thanks to [email protected] for the pointer
rv = FNV_64_INIT;
int len = k.length();
for (int i = 0; i < len; i++) {
rv *= FNV_64_PRIME;
rv ^= k.charAt(i);
}
}
break;
case FNV1A_64_HASH: {
rv = FNV_64_INIT;
int len = k.length();
for (int i = 0; i < len; i++) {
rv ^= k.charAt(i);
rv *= FNV_64_PRIME;
}
}
break;
case FNV1_32_HASH: {
rv = FNV_32_INIT;
int len = k.length();
for (int i = 0; i < len; i++) {
rv *= FNV_32_PRIME;
rv ^= k.charAt(i);
}
}
break;
case FNV1A_32_HASH: {
rv = FNV_32_INIT;
int len = k.length();
for (int i = 0; i < len; i++) {
rv ^= k.charAt(i);
rv *= FNV_32_PRIME;
}
}
break;
case ELECTION_HASH:
case KETAMA_HASH:
byte[] bKey = computeMd5(k);
rv = (long) (bKey[3] & 0xFF) << 24 | (long) (bKey[2] & 0xFF) << 16
| (long) (bKey[1] & 0xFF) << 8 | bKey[0] & 0xFF;
break;
case MYSQL_HASH:
int nr2 = 4;
for (int i = 0; i < k.length(); i++) {
rv ^= ((rv & 63) + nr2) * k.charAt(i) + (rv << 8);
nr2 += 3;
}
break;
case ELF_HASH:
long x = 0;
for (int i = 0; i < k.length(); i++) {
rv = (rv << 4) + k.charAt(i);
if ((x = rv & 0xF0000000L) != 0) {
rv ^= x >> 24;
rv &= ~x;
}
}
rv = rv & 0x7FFFFFFF;
break;
case RS_HASH:
long b = 378551;
long a = 63689;
for (int i = 0; i < k.length(); i++) {
rv = rv * a + k.charAt(i);
a *= b;
}
rv = rv & 0x7FFFFFFF;
break;
case LUA_HASH:
int step = (k.length() >> 5) + 1;
rv = k.length();
for (int len = k.length(); len >= step; len -= step) {
rv = rv ^ (rv << 5) + (rv >> 2) + k.charAt(len - 1);
}
break;
case ONE_AT_A_TIME:
try {
int hash = 0;
for (byte bt : k.getBytes("utf-8")) {
hash += (bt & 0xFF);
hash += (hash << 10);
hash ^= (hash >>> 6);
}
hash += (hash << 3);
hash ^= (hash >>> 11);
hash += (hash << 15);
rv = hash;
} catch (UnsupportedEncodingException e) {
throw new IllegalStateException("Hash function error", e);
}
break;
default:
assert false;
}
return rv & 0xffffffffL; /* Convert to unsigned 32-bits */
}
private static ThreadLocal md5Local = new ThreadLocal();
/**
* Get the md5 of the given key.
*/
public static byte[] computeMd5(String k) {
MessageDigest md5 = md5Local.get();
if (md5 == null) {
try {
md5 = MessageDigest.getInstance("MD5");
md5Local.set(md5);
} catch (NoSuchAlgorithmException e) {
throw new RuntimeException("MD5 not supported", e);
}
}
md5.reset();
md5.update(ByteUtils.getBytes(k));
return md5.digest();
}
// public static void main(String[] args) {
// HashAlgorithm alg=HashAlgorithm.CRC32_HASH;
// long h=0;
// long start=System.currentTimeMillis();
// for(int i=0;i<100000;i++)
// h=alg.hash("MYSQL_HASH");
// System.out.println(System.currentTimeMillis()-start);
// }
}
Dubbo:哈希函数
/**
* ConsistentHashLoadBalance
*/
public class ConsistentHashLoadBalance extends AbstractLoadBalance {
// 代码省略
......
private static final class ConsistentHashSelector {
// 代码省略
......
private long hash(byte[] digest, int number) {
return (((long) (digest[3 + number * 4] & 0xFF) << 24)
| ((long) (digest[2 + number * 4] & 0xFF) << 16)
| ((long) (digest[1 + number * 4] & 0xFF) << 8)
| (digest[number * 4] & 0xFF))
& 0xFFFFFFFFL;
}
private byte[] md5(String value) {
MessageDigest md5;
try {
md5 = MessageDigest.getInstance("MD5");
} catch (NoSuchAlgorithmException e) {
throw new IllegalStateException(e.getMessage(), e);
}
md5.reset();
byte[] bytes = value.getBytes(StandardCharsets.UTF_8);
md5.update(bytes);
return md5.digest();
}
}
}
2. 环存储数据结构
环由[0, 2^32-1]这个区间内的整数值组成。体现在程序中就是用一种数据结构存储这些值。
比如说用列表来存储,将服务器标识通过Hash函数计算后得到的哈希码存入到列表中,类似这样:
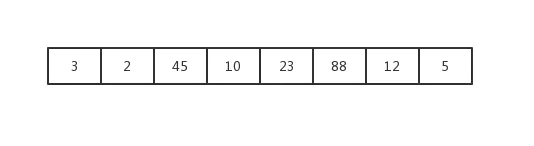
列表表示环.jpg
现在这个列表就表示了哈希码环。现在假设对象标识经过Hash函数计算后得到的哈希码值87。那么现在h=87,从环中找c点。如何确定c点呢?观察一下哈希码环,我们可以发现顺时针行走,哈希码值越来越小;逆时针行走哈希码值越来越大,而上面我们说到确定了h点后,逆时针行走查找c点,既然是逆时针行走那么就是找第一个大于h点的c,也就是说从列表中查找第一个大于h的元素。
满足这个需求的实现方法当然有很多了,这里有一种方式,就是先对列表进行从小到大排序,排序后列表结构如下:

排序后的列表.jpg
循环列表进行查找,第一个大于h的点就是88。查找涉及到时间复杂度,这种方式需要遍历列表,在查找性能上并不是最好的。
数据有序并且查找的时间复杂度小。使用Java容器类中的TreeMap比较合适。
更详细说明参考:https://www.cnblogs.com/xrq730/p/5186728.html
3. 代码实现
参考Dubbo的ConsistentHashLoadBalance类
ConsistentHashLoadBalancer.java
import java.nio.charset.StandardCharsets;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import java.util.List;
import java.util.Map;
import java.util.TreeMap;
/**
* @Author rocky.hu
* @Date 2019-04-20 20:34
*/
public class ConsistentHashLoadBalancer implements LoadBalancerStrategy {
private CandidateSelector candidateSelector;
@Override
public Server choose(List candidates) {
return null;
}
public Server choose(List candidates, String key) {
int identityHashCode = System.identityHashCode(candidates);
if (candidateSelector == null || candidateSelector.identityHashCode != identityHashCode) {
candidateSelector = new CandidateSelector(candidates, identityHashCode);
}
return candidateSelector.select(key);
}
private static final class CandidateSelector {
// 引入虚拟节点概念,此属性表示Hash环中总的虚拟节点数
private final TreeMap virtualCandidates;
// 每台真实服务器节点的虚拟节点数,这个值可做成可配置化的
private final int replicaNumber = 160;
// 服务器列表的Hash码,做缓存作用,用来判断服务器列表长度的变化
private final int identityHashCode;
CandidateSelector(List candidates, int identityHashCode) {
this.virtualCandidates = new TreeMap();
this.identityHashCode = identityHashCode;
// 将服务器节点映射到Hash环中
for (Server server : candidates) {
String address = server.getAddress();
for (int i = 0; i < replicaNumber / 4; i++) {
byte[] digest = md5(address + i);
for (int h = 0; h < 4; h++) {
long m = hash(digest, h);
virtualCandidates.put(m, server);
}
}
}
}
public Server select(String key) {
byte[] digest = md5(key);
return selectForKey(hash(digest, 0));
}
private Server selectForKey(long hash) {
// 使用TreeMap的ceilingEntry方法返回键值大于或等于的指定键的Entry(相当于Hash环逆时针行走查找服务器节点)
Map.Entry entry = virtualCandidates.ceilingEntry(hash);
if (entry == null) {
entry = virtualCandidates.firstEntry();
}
return entry.getValue();
}
private long hash(byte[] digest, int number) {
return (((long) (digest[3 + number * 4] & 0xFF) << 24)
| ((long) (digest[2 + number * 4] & 0xFF) << 16)
| ((long) (digest[1 + number * 4] & 0xFF) << 8)
| (digest[number * 4] & 0xFF))
& 0xFFFFFFFFL;
}
private byte[] md5(String value) {
MessageDigest md5;
try {
md5 = MessageDigest.getInstance("MD5");
} catch (NoSuchAlgorithmException e) {
throw new IllegalStateException(e.getMessage(), e);
}
md5.reset();
byte[] bytes = value.getBytes(StandardCharsets.UTF_8);
md5.update(bytes);
return md5.digest();
}
}
}
Server.java
/**
* @Author rocky.hu
* @Date 2019-04-21 00:47
*/
public class Server {
private String address;
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
}
一致性哈希算法及其在分布式存储中的应用
“外行看热闹,内行看门道”,一位做分布式存储的同仁看到了说:接近93%的存储利用率,还在不停写数据进去,说明OStorage-EOS数据分布的均匀性很好,否则,如果数据分布不够均匀,就有可能出现其他的节点或盘还有很多空间,但某一个盘或者某一个节点写满了,这时还继续写数据进去就会出问题。
OStorage的老大李明宇随手发了一个朋友圈,是该公司企业级对象存储产品OStorage-EOS的监控界面截图,感慨一个200多TB的集群很快被用户用到了92%以上。
“外行看热闹,内行看门道”,一位做分布式存储的同仁看到了说:接近93%的存储利用率,还在不停写数据进去,说明OStorage-EOS数据分布的均匀性很好,否则,如果数据分布不够均匀,就有可能出现其他的节点或盘还有很多空间,但某一个盘或者某一个节点写满了,这时还继续写数据进去就会出问题。
那么OStorage-EOS分布式对象存储是如何让数据均匀分布到各个盘上的呢?原来是使用了一个算法叫做“一致性哈希(Consistent Hashing)”,并且在一致性哈希基础上做了改进,增加了权重、副本、机柜感知、地域感知等机制。
一致性哈希算法也是分布式系统领域的经典算法,在很多地方都有应用,下面,我们就一起来了解一下它:
哈希函数
仔细研究一致性哈希之前,我们先来了解一下基本的哈希,举个例子说明了我们如何使用哈希函数来确定对象存储在哪里。
先看一个定位数据相对简单的方法,使用MD5算法来得到对象的逻辑位置的哈希值,然后除以可用的磁盘数量,得到余数。***将余数值映射到驱动器ID。
例如,对象的存储位置为 /accountA/container1/objectX ,并且使用四个磁盘来存储数据,我们称之为磁盘0到磁盘3。这里我们先计算MD5值:
- md5 -s /accountA/container1/objectX
- MD5 ("/account/container/object") =
- f9db0f833f1545be2e40f387d6c271de
然后我们用哈希值(十六进制数值)除以磁盘数,取余数(取模)。以上十六进制数值转化为十进制为:
332115198597019796159838990710599741918
取模函数在大多数编程语言中用%运算符表示:
332115198597019796159838990710599741918 % 4 = 2
因为余数是2,所以对象将被存储在磁盘2。
这种算法***的缺点是计算结果取决于除数也就是磁盘数量。任何时候添加或移除某个磁盘(除数变化了),同一个对象可能得到不同的余数,从而映射到不同的磁盘。为了说明这一点,下面的表显示了当添加磁盘时,哪一个磁盘将成为对象新的存储位置。
注意,几乎每次添加新磁盘,对象都必须移动到新的磁盘上,这仅仅一个对象的情况,将这种行为推广开来,在增加或者移除节点、磁盘时,几乎集群中的所有数据都需要进行移动。集群将不得不花费大量资源来进行这些迁移,还将产生繁重的网络负载,以及数据不可读取的情况。
一致性哈希算法
当从集群中的增加或者移除磁盘、节点时,一致性哈希(Consistent Hashing)可以减少移动的对象数量。一致性哈希不是将每个值直接映射到一个磁盘,而是通过将所有可能的哈希值建模为一个环。一致性哈希算法除了计算对象的哈希以外,还计算设备的哈希,根据磁盘的IP地址、盘符等计算哈希值,每个磁盘被映射到哈希环的某个点上,如图所示。
当一个对象需要被存储时,先计算对象的哈希值,然后定位到环上,如图所示“hash of object”的位置。系统按顺时针搜索环上面下一个磁盘的哈希然后定位该磁盘,用这个磁盘存储数据。上图中可以看到,对象将被存储在磁盘4。按照这种算法,哈希环上某个区间的哈希值会被映射到一个磁盘上,如图所示,我们用不同颜色表示不同区间和它们对应的磁盘,若某个对象的哈希值落在蓝色的区间内,则它会被存储在磁盘1上。
有了这样的哈希环,当我们添加一块新的磁盘时,比如磁盘5,那么图中粉色部分将不再属于磁盘4,因为这部分数据目前全部属于新的磁盘5。所以这部分位于磁盘4上的对象将会被移动到磁盘5,而其他数据均不受影响。
使用这种方案,添加一个盘或者一个节点,只需要移动少量数据,比前面那种最基本的依靠计算哈希值并模除来确定数据存放位置的方案要好很多,在前面那种方案中需要移动很多数据。
在实际应用的一致性哈希算法中,每个实际的磁盘或节点会对在环上对应到多个标记,这些标记在一些文献中也被成为“虚节点(Virtual Node)”,实际应用中,一个磁盘会对应很多标记/虚节点,甚至每个磁盘对应数百个标记。多个标记意味着每块磁盘对应环的哈希值范围从一个大区域切分成了数个小区域。这样做有两个效果,一个效果是一个新添加的磁盘可能从多个磁盘那里迁移对象数据,进一步降低了数据迁移的压力,另一个效果是总体的数据分布更加的平均。
以上就是一致性哈希的基本原理,OStorage-EOS基于一致性哈希算法实现了数据的均匀分布,并加以改进,引入副本、权重、机柜感知、地域感知等机制,以满足企业级用户的需求。
mycat一致性hash配置:
1、 mycat一致性hash算法分片测试结果
配置el_user_user_info表使用一致性hash算法进行分片。
schema.xml
rule.xml
使用一致性hash算法(murmur),在MyCat中插入49911条数据,分为2个分片,数据量基本平衡。
2、 mycat一致性hash算法扩容测试结果
先看扩容后的结果:
有两种扩容方案:
方案一、
a) 停止数据服务,导出全部分片表数据,进行备份;
b) 清空分片表;
c) 在mycat中重新导入分片表,完成迁移。
这种方案缺点很明显,需要导出导入的数据量大时,操作很费时,且容易出错。
方案二、
a) 修改MyCAT配置,使用扩容后的配置启动;
b) 自己编写脚本,利用MyCAT的explain语法,分析出各个MySQL节点中分片表需要重新hash的数据,并记录ID(或数据)到文件中;
b) 导出各节点中的需要重新hash的数据进行备份,
c) 确认备份无误,清除原节点中的数据记录;
c) 在mycat中重新导入备份的数据,完成迁移。