【三维深度学习】点云上采样网络PU-Net 代码分析
PU-Net的代码是基于Tensorflow code,并从PointNet++和PointSetGeneration中进行了诸多借鉴。PU-Net是一个点云上采样模型,可以将非规则的点云输入通过点云片抽取、特征嵌入学习和特征拓展将点云密度提升r倍。具体可以参看 ? 论文分析
1.代码基本结构
要使用这一代码,首先需要从github上拉取作者分享的源码:
git clone https://github.com/yulequan/PU-Net.git
cd PU-Net
其中code是本项目的源码;evaluation_code是针对NUC指标的测评代码,需要安装CGAL库;h5_data是训练数据文件夹;MC_5K是测试数据集文件夹;prepare_data是一些数据集处理函数,包含了mesh分割和泊松采样;model可以下载预训练模型进行测试;
随后在code文件夹下可以看到详细的代码结构:
tf_ops/ #包含各类tf操作子,CD,EMD,grouping,interpolation,sampling等
utils/ #各种点云处理使用的功能函数
data_provider.py #点云载入,操作处理的函数
main.py
model_generator*.py #构建训练的模型计算图
model_utilis,py #载入ckpt,定义损失

其中main函数是总入口,可以设置过个参数来控制代码的训练、测试状态以及超参数
# copy from: https://github.com/yulequan/PU-Net/blob/master/code/main.py
# 省略各种相关功能和函数的引用
import model_generator2_2new6 as MODEL_GEN # 模型生成
import model_utils #预训练模型载入与损失
import data_provider #数据
from utils import pc_util #点云处理
###----------------------各种参数设置接口,包括模态、操作、上采样数量、点云分辨率、训练周期、学习率等等-------------------####
parser = argparse.ArgumentParser()
parser.add_argument('--phase', default='test', help='train or test [default: train]')
parser.add_argument('--gpu', default='0', help='GPU to use [default: GPU 0]')
parser.add_argument('--log_dir', default='../model/generator2_new6', help='Log dir [default: log]')
parser.add_argument('--num_point', type=int, default=1024,help='Point Number [1024/2048] [default: 1024]')
parser.add_argument('--up_ratio', type=int, default=4, help='Upsampling Ratio [default: 2]')
parser.add_argument('--max_epoch', type=int, default=120, help='Epoch to run [default: 500]')
parser.add_argument('--batch_size', type=int, default=28, help='Batch Size during training [default: 32]')
parser.add_argument('--learning_rate', type=float, default=0.001)
ASSIGN_MODEL_PATH=None
USE_DATA_NORM = True
USE_RANDOM_INPUT = True
USE_REPULSION_LOSS = True
FLAGS = parser.parse_args()
PHASE = FLAGS.phase
GPU_INDEX = FLAGS.gpu
BATCH_SIZE = FLAGS.batch_size
NUM_POINT = FLAGS.num_point
UP_RATIO = FLAGS.up_ratio
MAX_EPOCH = FLAGS.max_epoch
BASE_LEARNING_RATE = FLAGS.learning_rate
MODEL_DIR = FLAGS.log_dir
print socket.gethostname()
print FLAGS
os.environ['CUDA_VISIBLE_DEVICES'] = GPU_INDEX
###-----------------------------------------------------------------------------------------------###
#打印函数
def log_string(out_str):
global LOG_FOUT
LOG_FOUT.write(out_str)
LOG_FOUT.flush()

训练函数部分主要流程是传入学习率等超参数、载入计算图、创建训练模型、计算损失、tensorboard记录以及开启训练session等。
##训练函数
def train(assign_model_path=None):
is_training = True
bn_decay = 0.95
step = tf.Variable(0,trainable=False)
learning_rate = BASE_LEARNING_RATE
tf.summary.scalar('bn_decay', bn_decay)
tf.summary.scalar('learning_rate', learning_rate)
# get placeholder 输入位置的占位符
pointclouds_pl, pointclouds_gt, pointclouds_gt_normal, pointclouds_radius = MODEL_GEN.placeholder_inputs(BATCH_SIZE, NUM_POINT, UP_RATIO)
#create the generator model 载入计算图
pred,_ = MODEL_GEN.get_gen_model(pointclouds_pl, is_training, scope='generator',bradius=pointclouds_radius,
reuse=None,use_normal=False, use_bn=False,use_ibn=False,
bn_decay=bn_decay,up_ratio=UP_RATIO)
#计算损失,包含两部分,重建损失和排斥损失
#get emd loss
gen_loss_emd,matchl_out = model_utils.get_emd_loss(pred, pointclouds_gt, pointclouds_radius)
#get repulsion loss
if USE_REPULSION_LOSS:
gen_repulsion_loss = model_utils.get_repulsion_loss4(pred)
tf.summary.scalar('loss/gen_repulsion_loss', gen_repulsion_loss)
else:
gen_repulsion_loss =0.0
#get total loss function
pre_gen_loss = 100 * gen_loss_emd + gen_repulsion_loss + tf.losses.get_regularization_loss()
#-----------------------------------------------------------------------------------------------------#
# create pre-generator ops
gen_update_ops = [op for op in tf.get_collection(tf.GraphKeys.UPDATE_OPS) if op.name.startswith("generator")]
gen_tvars = [var for var in tf.trainable_variables() if var.name.startswith("generator")]
# 定义优化器
with tf.control_dependencies(gen_update_ops):
pre_gen_train = tf.train.AdamOptimizer(learning_rate,beta1=0.9).minimize(pre_gen_loss,var_list=gen_tvars,
colocate_gradients_with_ops=True,
global_step=step)
# 将损失加入到tensorboard中显示
# merge summary and add pointclouds summary
tf.summary.scalar('loss/gen_emd', gen_loss_emd)
tf.summary.scalar('loss/regularation', tf.losses.get_regularization_loss())
tf.summary.scalar('loss/pre_gen_total', pre_gen_loss)
pretrain_merged = tf.summary.merge_all()
# 输入输入并到tensorboard中显示
pointclouds_image_input = tf.placeholder(tf.float32, shape=[None, 500, 1500, 1])
pointclouds_input_summary = tf.summary.image('pointcloud_input', pointclouds_image_input, max_outputs=1)
pointclouds_image_pred = tf.placeholder(tf.float32, shape=[None, 500, 1500, 1])
pointclouds_pred_summary = tf.summary.image('pointcloud_pred', pointclouds_image_pred, max_outputs=1)
pointclouds_image_gt = tf.placeholder(tf.float32, shape=[None, 500, 1500, 1])
pointclouds_gt_summary = tf.summary.image('pointcloud_gt', pointclouds_image_gt, max_outputs=1)
image_merged = tf.summary.merge([pointclouds_input_summary,pointclouds_pred_summary,pointclouds_gt_summary])
#-----------------------------------------------------------------------------------------------------#
# Create a session
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
config.allow_soft_placement = True
config.log_device_placement = False
with tf.Session(config=config) as sess: #开启session
train_writer = tf.summary.FileWriter(os.path.join(MODEL_DIR, 'train'), sess.graph)
init = tf.global_variables_initializer()
sess.run(init)
# 初始化一大堆基于tf的点云操作子(变量,占位符),并以字典形式存在
ops = {'pointclouds_pl': pointclouds_pl,
'pointclouds_gt': pointclouds_gt,
'pointclouds_gt_normal':pointclouds_gt_normal,
'pointclouds_radius': pointclouds_radius,
'pointclouds_image_input':pointclouds_image_input,
'pointclouds_image_pred': pointclouds_image_pred,
'pointclouds_image_gt': pointclouds_image_gt,
'pretrain_merged':pretrain_merged,
'image_merged': image_merged,
'gen_loss_emd': gen_loss_emd,
'pre_gen_train':pre_gen_train,
'pred': pred,
'step': step,
}
#-----------------------------------------------------------------------------------------------------#
#restore the model
saver = tf.train.Saver(max_to_keep=6) #训练过程中保存模型
restore_epoch, checkpoint_path = model_utils.pre_load_checkpoint(MODEL_DIR)
global LOG_FOUT
if restore_epoch==0:
LOG_FOUT = open(os.path.join(MODEL_DIR, 'log_train.txt'), 'w')
LOG_FOUT.write(str(socket.gethostname()) + '\n')
LOG_FOUT.write(str(FLAGS) + '\n')
else:
LOG_FOUT = open(os.path.join(MODEL_DIR, 'log_train.txt'), 'a')
saver.restore(sess,checkpoint_path)
###assign the generator with another model file
if assign_model_path is not None:
print "Load pre-train model from %s"%(assign_model_path)
assign_saver = tf.train.Saver(var_list=[var for var in tf.trainable_variables() if var.name.startswith("generator")])
assign_saver.restore(sess, assign_model_path)
#-----------------------------------------------------------------------------------------------------#
##read data 读入数据
input_data, gt_data, data_radius, _ = data_provider.load_patch_data(skip_rate=1, num_point=NUM_POINT, norm=USE_DATA_NORM,
use_randominput = USE_RANDOM_INPUT)
# 多线程读入数据 from data_provider-->class Fetcher
fetchworker = data_provider.Fetcher(input_data,gt_data,data_radius,BATCH_SIZE,NUM_POINT,USE_RANDOM_INPUT,USE_DATA_NORM)
fetchworker.start()
for epoch in tqdm(range(restore_epoch,MAX_EPOCH+1),ncols=55):
log_string('**** EPOCH %03d ****\t' % (epoch))
train_one_epoch(sess, ops, fetchworker, train_writer) #训练循环的代码
if epoch % 20 == 0:
saver.save(sess, os.path.join(MODEL_DIR, "model"), global_step=epoch)
fetchworker.shutdown()

完整训练由多个单次训练构成,输入量为session操作、数据载入器和训练结果保存器等。单次训练的代码如下,
def train_one_epoch(sess, ops, fetchworker, train_writer):
loss_sum = []
fetch_time = 0
# 对每一个批进行操作
for batch_idx in range(fetchworker.num_batches):
start = time.time()
batch_input_data, batch_data_gt, radius =fetchworker.fetch()
end = time.time()
fetch_time+= end-start
# IODO(RJJ):feed sess.run的理解需要再做注释<<<<<------------------------
# 这里表述输入数据,分别是b输入数据、GT数据(xyz,nxnynz),半径
feed_dict = {ops['pointclouds_pl']: batch_input_data,
ops['pointclouds_gt']: batch_data_gt[:,:,0:3],
ops['pointclouds_gt_normal']:batch_data_gt[:,:,0:3],
ops['pointclouds_radius']: radius}
# 输入要计算的ops和对应数据dict
# 需要计算的结果包括当前步数、预测结果以及损失,被各个ops来作为字典的键值
summary,step, _, pred_val,gen_loss_emd = sess.run( [ops['pretrain_merged'],ops['step'],ops['pre_gen_train'],
ops['pred'], ops['gen_loss_emd']], feed_dict=feed_dict)
train_writer.add_summary(summary, step) #写入tensorboard显示
loss_sum.append(gen_loss_emd)
# 每30个batch输入一次
if step%30 == 0:
pointclouds_image_input = pc_util.point_cloud_three_views(batch_input_data[0,:,0:3])
pointclouds_image_input = np.expand_dims(np.expand_dims(pointclouds_image_input,axis=-1),axis=0)
pointclouds_image_pred = pc_util.point_cloud_three_views(pred_val[0, :, :])
pointclouds_image_pred = np.expand_dims(np.expand_dims(pointclouds_image_pred, axis=-1), axis=0)
pointclouds_image_gt = pc_util.point_cloud_three_views(batch_data_gt[0, :, 0:3])
pointclouds_image_gt = np.expand_dims(np.expand_dims(pointclouds_image_gt, axis=-1), axis=0)
feed_dict ={ops['pointclouds_image_input']:pointclouds_image_input,
ops['pointclouds_image_pred']: pointclouds_image_pred,
ops['pointclouds_image_gt']: pointclouds_image_gt,
}
summary = sess.run(ops['image_merged'],feed_dict)
train_writer.add_summary(summary,step)
loss_sum = np.asarray(loss_sum)
log_string('step: %d mean gen_loss_emd: %f\n' % (step, round(loss_sum.mean(),4)))
print 'read data time: %s mean gen_loss_emd: %f' % (round(fetch_time,4), round(loss_sum.mean(),4))

主函数里还包含了利用整个模型进行预测的代码,载入模型-读入数据-运行测试–可视化:
def prediction_whole_model(data_folder=None,show=False,use_normal=False):
data_folder = '../data/test_data/our_collected_data/MC_5k'
phase = data_folder.split('/')[-2]+data_folder.split('/')[-1]
save_path = os.path.join(MODEL_DIR, 'result/' + phase)
if not os.path.exists(save_path):
os.makedirs(save_path)
samples = glob(data_folder + "/*.xyz")
samples.sort(reverse=True)
input = np.loadtxt(samples[0])
if use_normal:
pointclouds_ipt = tf.placeholder(tf.float32, shape=(1, input.shape[0], 6))
else:
pointclouds_ipt = tf.placeholder(tf.float32, shape=(1, input.shape[0], 3))
pred, _ = MODEL_GEN.get_gen_model(pointclouds_ipt, is_training=False, scope='generator', bradius=1.0,
reuse=None, use_normal=use_normal, use_bn=False, use_ibn=False, bn_decay=0.95, up_ratio=UP_RATIO)
saver = tf.train.Saver()
_, restore_model_path = model_utils.pre_load_checkpoint(MODEL_DIR)
print restore_model_path
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
config.allow_soft_placement = True
with tf.Session(config=config) as sess:
saver.restore(sess, restore_model_path)
samples = glob(data_folder+"/*.xyz")
samples.sort()
total_time = 0
for i,item in enumerate(samples):
input = np.loadtxt(item)
gt = input
# input = data_provider.jitter_perturbation_point_cloud(np.expand_dims(input,axis=0),sigma=0.003,clip=0.006)
input = np.expand_dims(input, axis=0)
if not use_normal:
input = input[:,:,0:3]
gt = gt[:,0:3]
print item, input.shape
start_time = time.time()
pred_pl = sess.run(pred, feed_dict={pointclouds_ipt: input}) #<<<-----------预测
total_time +=time.time()-start_time
norm_pl = np.zeros_like(pred_pl)
##--------------visualize predicted point cloud----------------------
path = os.path.join(save_path,item.split('/')[-1])
if show:
f,axis = plt.subplots(3)
axis[0].imshow(pc_util.point_cloud_three_views(input[0, :,0:3],diameter=5))
axis[1].imshow(pc_util.point_cloud_three_views(pred_pl[0,:,:],diameter=5))
axis[2].imshow(pc_util.point_cloud_three_views(gt[:,0:3], diameter=5))
plt.show()
data_provider.save_pl(path, np.hstack((pred_pl[0, ...],norm_pl[0, ...])))
path = path[:-4]+'_input.xyz'
data_provider.save_pl(path, input[0])
print total_time/20
2. 网络构造
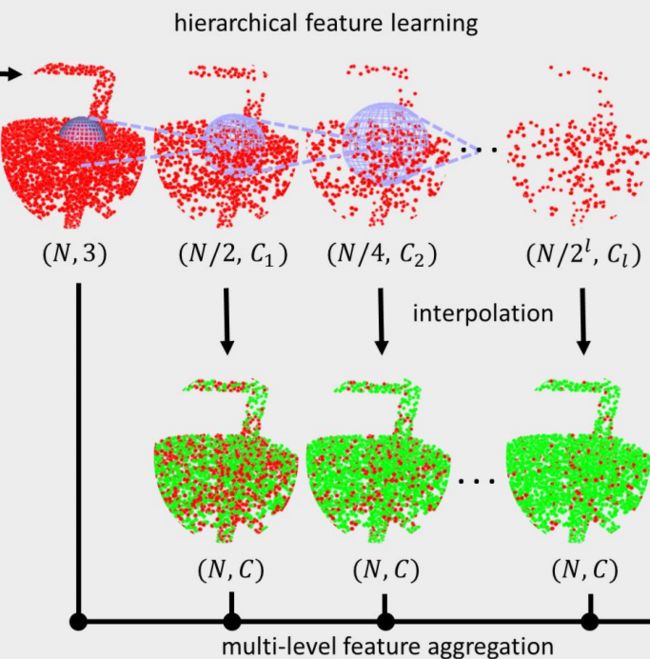
PU-Net的网络模型构造由model_generator*.py文件负责,其中定义了基本的网络结构,下面将参考模型的框架来深入理解网络的构成,下图先回顾了模型的基本结构,包含了抽取、嵌入学习、特征拓展、点云加密等操作,具体可以参考 ? 论文解读
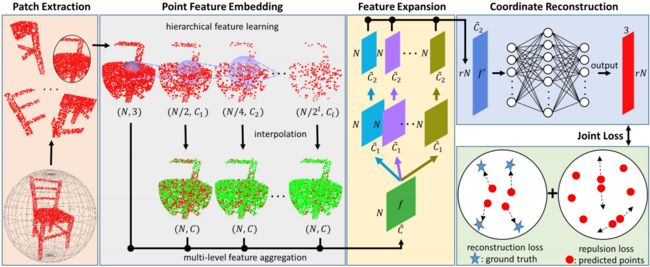
实现的代码如下,分析见注释:
# code copy from: https://github.com/yulequan/PU-Net/blob/master/code/model_generator2_2new6.py
# ref: https://yulequan.github.io/files/CVPR18_PUNet_supp.pdf --> C. Details of Network Architectures
import tensorflow as tf
from utils import tf_util2
from utils.pointnet_util import pointnet_sa_module,pointnet_fp_module
#首先定义输入占位符,包括了输入点云、基准、点云归一化、多尺度处理半径等
def placeholder_inputs(batch_size, num_point,up_ratio = 4):
pointclouds_pl = tf.placeholder(tf.float32, shape=(batch_size, num_point, 6))
pointclouds_gt = tf.placeholder(tf.float32, shape=(batch_size, num_point*up_ratio, 3))
pointclouds_normal = tf.placeholder(tf.float32, shape=(batch_size, num_point * up_ratio, 3))
pointclouds_radius = tf.placeholder(tf.float32, shape=(batch_size))
return pointclouds_pl, pointclouds_gt,pointclouds_normal, pointclouds_radius
# 这里开始定义模型,整体定义在sc这个scope下面,统一符号的命名空间范围
def get_gen_model(point_cloud, is_training, scope, bradius = 1.0, reuse=None, use_rv=False, use_bn = False,use_ibn = False,
use_normal=False,bn_decay=None, up_ratio = 4,idx=None):
with tf.variable_scope(scope,reuse=reuse) as sc:
batch_size = point_cloud.get_shape()[0].value #批大小
num_point = point_cloud.get_shape()[1].value #点的数目
l0_xyz = point_cloud[:,:,0:3] #0级的点云
if use_normal:
l0_points = point_cloud[:,:,3:] #0级normal值
else:
l0_points = None
# Layer 1 在四个级不同的尺度上进行下采样,如下图中红色部分
# 其中采样数量npoint在不断减小(变稀疏了)
# 采样半径radius从0.05,0.1,0.2,0.3扩大.
# 点特征输出维度mlp也在不断增加,因为扩大后包含更多语义信息了
l1_xyz, l1_points, l1_indices = pointnet_sa_module(l0_xyz, l0_points, npoint=num_point, radius=bradius*0.05,bn=use_bn,ibn = use_ibn,
nsample=32, mlp=[32, 32, 64], mlp2=None, group_all=False,
is_training=is_training, bn_decay=bn_decay, scope='layer1')
l2_xyz, l2_points, l2_indices = pointnet_sa_module(l1_xyz, l1_points, npoint=num_point/2, radius=bradius*0.1,bn=use_bn,ibn = use_ibn,
nsample=32, mlp=[64, 64, 128], mlp2=None, group_all=False,
is_training=is_training, bn_decay=bn_decay, scope='layer2')
l3_xyz, l3_points, l3_indices = pointnet_sa_module(l2_xyz, l2_points, npoint=num_point/4, radius=bradius*0.2,bn=use_bn,ibn = use_ibn,
nsample=32, mlp=[128, 128, 256], mlp2=None, group_all=False,
is_training=is_training, bn_decay=bn_decay, scope='layer3')
l4_xyz, l4_points, l4_indices = pointnet_sa_module(l3_xyz, l3_points, npoint=num_point/8, radius=bradius*0.3,bn=use_bn,ibn = use_ibn,
nsample=32, mlp=[256, 256, 512], mlp2=None, group_all=False,
is_training=is_training, bn_decay=bn_decay, scope='layer4')
其中稀疏化采样函数point_sa_module包含在utils/pointnet_util.py中,包含了采样半径
def pointnet_sa_module(xyz, points, npoint, radius, nsample, mlp, mlp2, group_all, is_training,
bn_decay, scope, bn=True, ibn=False, pooling='max', tnet_spec=None, knn=False, use_xyz=True):
''' PointNet Set Abstraction (SA) Module
Input:
xyz: (batch_size, ndataset, 3) TF tensor
points: (batch_size, ndataset, channel) TF tensor
npoint: int32 -- #points sampled in farthest point sampling
radius: float32 -- search radius in local region
batch_radius: the size of each object
nsample: int32 -- how many points in each local region
mlp: list of int32 -- output size for MLP on each point
mlp2: list of int32 -- output size for MLP on each region
group_all: bool -- group all points into one PC if set true, OVERRIDE
npoint, radius and nsample settings
use_xyz: bool, if True concat XYZ with local point features, otherwise just use point features
Return:
new_xyz: (batch_size, npoint, 3) TF tensor
new_points: (batch_size, npoint, mlp[-1] or mlp2[-1]) TF tensor
idx: (batch_size, npoint, nsample) int32 -- indices for local regions
'''
with tf.variable_scope(scope) as sc:
if group_all:
nsample = xyz.get_shape()[1].value
new_xyz, new_points, idx, grouped_xyz = sample_and_group_all(xyz, points, use_xyz)
else:
new_xyz, new_points, idx, grouped_xyz = sample_and_group(npoint, radius, nsample, xyz, points, tnet_spec, knn, use_xyz)
if mlp2 is None: mlp2 = []
for i, num_out_channel in enumerate(mlp):
new_points = tf_util2.conv2d(new_points, num_out_channel, [1,1],
padding='VALID', stride=[1,1],
bn=bn, ibn=ibn, is_training=is_training,
scope='conv%d'%(i), bn_decay=bn_decay)
#----------------------------池化方法-------------------------------------#
if pooling=='avg':
new_points = tf.layers.average_pooling2d(new_points, [1,nsample], [1,1], padding='VALID', name='avgpool1')
elif pooling=='weighted_avg':
with tf.variable_scope('weighted_avg1'):
dists = tf.norm(grouped_xyz,axis=-1,ord=2,keep_dims=True)
exp_dists = tf.exp(-dists * 5)
weights = exp_dists/tf.reduce_sum(exp_dists,axis=2,keep_dims=True) # (batch_size, npoint, nsample, 1)
new_points *= weights # (batch_size, npoint, nsample, mlp[-1])
new_points = tf.reduce_sum(new_points, axis=2, keep_dims=True)
elif pooling=='max':
new_points = tf.reduce_max(new_points, axis=[2], keep_dims=True)
elif pooling=='min':
new_points = tf.layers.max_pooling2d(-1 * new_points, [1, nsample], [1, 1], padding='VALID',name='minpool1')
elif pooling=='max_and_avg':
avg_points = tf.layers.max_pooling2d(new_points, [1,nsample], [1,1], padding='VALID', name='maxpool1')
max_points = tf.layers.average_pooling2d(new_points, [1,nsample],[1,1], padding='VALID', name='avgpool1')
new_points = tf.concat([avg_points, max_points], axis=-1)
#对点云进行卷积和特征抽取
if mlp2 is None: mlp2 = []
for i, num_out_channel in enumerate(mlp2):
new_points = tf_util2.conv2d(new_points, num_out_channel, [1,1],
padding='VALID', stride=[1,1],
bn=bn, ibn=ibn,is_training=is_training,
scope='conv_post_%d'%(i), bn_decay=bn_decay)
new_points = tf.squeeze(new_points, [2]) # (batch_size, npoints, mlp2[-1])
return new_xyz, new_points, idx
二、模型学习嵌入特征,上半段中从四个不同的层级上进行了特征抽取,下面部分则要对特征进行特征上采样,统一到相同维度上去绿色部分,l0xyz进行处理后得到l1piont,l2point-l4point都插值到l1point的维度并与l0xyz一起concate
# 将特征上采样到C.相同的维度64,以便随后进行特征拓展
# Feature Propagation layers
up_l4_points = pointnet_fp_module(l0_xyz, l4_xyz, None, l4_points, [64], is_training, bn_decay,
scope='fa_layer1',bn=use_bn,ibn = use_ibn)
up_l3_points = pointnet_fp_module(l0_xyz, l3_xyz, None, l3_points, [64], is_training, bn_decay,
scope='fa_layer2',bn=use_bn,ibn = use_ibn)
up_l2_points = pointnet_fp_module(l0_xyz, l2_xyz, None, l2_points, [64], is_training, bn_decay,
scope='fa_layer3',bn=use_bn,ibn = use_ibn)
这里的pointnet_fp_module具体实现在utils/pointnet_util.py里,先使用卷积处理xyz1, xyz2坐标,随后再利用稀疏的point2特征进行插值,将特征进行上采样插值:
def pointnet_fp_module(xyz1, xyz2, points1, points2, mlp, is_training, bn_decay, scope, bn=True,ibn=False):
''' PointNet Feature Propogation (FP) Module
Input:
xyz1: (batch_size, ndataset1, 3) TF tensor
xyz2: (batch_size, ndataset2, 3) TF tensor, sparser than xyz1,下采样后稀疏点向稠密点插值
points1: (batch_size, ndataset1, nchannel1) TF tensor
points2: (batch_size, ndataset2, nchannel2) TF tensor
mlp: list of int32 -- output size for MLP on each point
Return:
new_points: (batch_size, ndataset1, mlp[-1]) TF tensor
'''
with tf.variable_scope(scope) as sc:
dist, idx = three_nn(xyz1, xyz2)
dist = tf.maximum(dist, 1e-10)
norm = tf.reduce_sum((1.0/dist),axis=2,keep_dims=True) #归一化
norm = tf.tile(norm,[1,1,3])
weight = (1.0/dist) / norm
interpolated_points = three_interpolate(points2, idx, weight) #特征插值函数from tf_ops/interpolation/tf_interpolate.py, 利用cpp实现的tf_ops
if points1 is not None:
new_points1 = tf.concat(axis=2, values=[interpolated_points, points1]) # B,ndataset1,nchannel1+nchannel2
else:
new_points1 = interpolated_points
new_points1 = tf.expand_dims(new_points1, 2)
for i, num_out_channel in enumerate(mlp):
new_points1 = tf_util2.conv2d(new_points1, num_out_channel, [1,1],
padding='VALID', stride=[1,1],
bn=bn, ibn=ibn,is_training=is_training,
scope='conv_%d'%(i), bn_decay=bn_decay) # 用1*1卷积进行维度缩减
new_points1 = tf.squeeze(new_points1, [2]) # B,ndataset1,mlp[-1]
return new_points1
三、特征衔接并在特征空间内进行维度扩展,随后利用利用全连接得到最终的三维加密点输入:
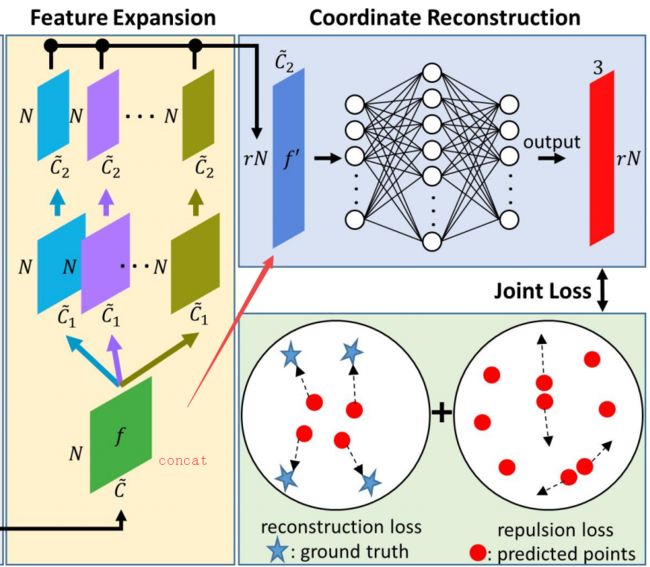
# 衔接特征随后进行特征拓展
###concat feature
with tf.variable_scope('up_layer',reuse=reuse):
new_points_list = []
#上采样率,上采样几倍就来几次拓展,将特征先衔接再拓展维度上进行两次卷积C1C2,最后在新维度上concate得到net输入
for i in range(up_ratio):
concat_feat = tf.concat([up_l4_points, up_l3_points, up_l2_points, l1_points, l0_xyz], axis=-1) #64*4+1 = 259 维度
concat_feat = tf.expand_dims(concat_feat, axis=2)
concat_feat = tf_util2.conv2d(concat_feat, 256, [1, 1],
padding='VALID', stride=[1, 1],
bn=False, is_training=is_training,
scope='fc_layer0_%d'%(i), bn_decay=bn_decay)
new_points = tf_util2.conv2d(concat_feat, 128, [1, 1],
padding='VALID', stride=[1, 1],
bn=use_bn, is_training=is_training,
scope='conv_%d' % (i),
bn_decay=bn_decay)
new_points_list.append(new_points)
net = tf.concat(new_points_list,axis=1)
# 全连接层,利用1*1卷积来代替得到最终的三维点云输入r*N*3
#get the xyz
coord = tf_util2.conv2d(net, 64, [1, 1],
padding='VALID', stride=[1, 1],
bn=False, is_training=is_training,
scope='fc_layer1', bn_decay=bn_decay)
coord = tf_util2.conv2d(coord, 3, [1, 1],
padding='VALID', stride=[1, 1],
bn=False, is_training=is_training,
scope='fc_layer2', bn_decay=bn_decay,
activation_fn=None, weight_decay=0.0) # B*(2N)*1*3
coord = tf.squeeze(coord, [2]) # B*(2N)*3 #去掉维度为1的维度,将张量变为三维输入B*(rN)*3
return coord,None

3.损失函数的定义
模型中包含了两个损失函数,分别是重建损失和使得点云均匀分布的排斥损失,其定义包含在model_utils.py中:
重建损失可以有两种定义方式,分别是描述分布差异的earth movers distance EMD和Chamfer distance CD:

def get_emd_loss(pred, gt, radius):
""" pred: BxNxC,
label: BxN, """
batch_size = pred.get_shape()[0].value
matchl_out, matchr_out = tf_auctionmatch.auction_match(pred, gt) # 匹配值,逐点计算,from: tf_ops/emd/tf_auctionmatch_g.cu,目的是从gt中计算出与预测点对应的gt点matched_out
# TODO(rjj):这里需要加强理解
matched_out = tf_sampling.gather_point(gt, matchl_out) # phi的值,预测点的bijection mapping
dist = tf.reshape((pred - matched_out) ** 2, shape=(batch_size, -1)) #l2 error
dist = tf.reduce_mean(dist, axis=1, keep_dims=True) # 两个预测点云间距离均值,相似性
dist_norm = dist / radius
emd_loss = tf.reduce_mean(dist_norm)
return emd_loss,matchl_out
def get_cd_loss(pred, gt, radius):
""" pred: BxNxC,
label: BxN, """
dists_forward, _, dists_backward, _ = tf_nndistance.nn_distance(gt, pred)
#dists_forward is for each element in gt, the cloest distance to this element
CD_dist = 0.8*dists_forward + 0.2*dists_backward
CD_dist = tf.reduce_mean(CD_dist, axis=1)
CD_dist_norm = CD_dist/radius
cd_loss = tf.reduce_mean(CD_dist_norm)
return cd_loss,None
排斥损失则定义为:
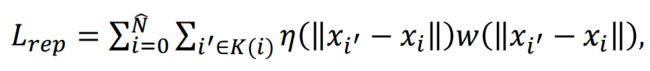
def get_repulsion_loss4(pred, nsample=20, radius=0.07):
# pred: (batch_size, npoint,3)
idx, pts_cnt = query_ball_point(radius, nsample, pred, pred)
tf.summary.histogram('smooth/unque_index', pts_cnt) #tensorboard
grouped_pred = group_point(pred, idx) # (batch_size, npoint, nsample, 3)
grouped_pred -= tf.expand_dims(pred, 2)
##get the uniform loss
h = 0.03
dist_square = tf.reduce_sum(grouped_pred ** 2, axis=-1)
dist_square, idx = tf.nn.top_k(-dist_square, 5) # k最邻近点 取5
dist_square = -dist_square[:, :, 1:] # remove the first one eta=-r
dist_square = tf.maximum(1e-12,dist_square)
dist = tf.sqrt(dist_square) # 距离x-x'
weight = tf.exp(-dist_square/h**2) # w = exp(-r2/h2)
uniform_loss = tf.reduce_mean(radius-dist*weight) # TODO(hitrjj):radius means?最小距离半径?
return uniform_loss


