从Java8发布到现在有好几年了,而Java9也提上发布日程了(没记错的话好像就是这个月2017年7月,也许会再度跳票吧,不过没关系,稳定大于一切,稳定了再发布也行),现在才开始去真正学习,说来也是惭愧。虽然目前工作环境仍然以Java6为主,不过Java8目前已是大势所趋了。Java8带来了许多令人激动的新特性,如lambda表达式,StreamsAPI与并行集合计算,新的时间日期API(借鉴joda-time),字节码支持保存方法参数名(对于框架开发真的是非常赞的一个特性),Optional类解决空指针问题(虽然Guava中早就有这个了)等。
lambda表达式
语法:
v->System.out.println(v)
(v)->System.out.println(v)
(String v)->System.out.println(v)
(v)->{System.out.println(v);return v+1;}
List numbers = Arrays.asList(1, 2, 3, 4, 5, 6);
numbers.forEach((Integer value) -> System.out.println(value)); 注意:lambda表达式内如果引用了外部的局部变量,那么这个局部变量必须是final的,如果不是,编译器会自动给加上final。比如下面这段是错误的
//这是错误的
int num = 2;
Function stringConverter = (from) -> from * num;
num++;//会报错,因为此时num已经是final声明的了
System.out.println(stringConverter.apply(3)); 函数式接口:
仅有一个抽象方法的接口(注:Java8之后接口也可以有非抽象方法,所以此处强调只有一个抽象方法的接口)
可选注解:@FunctionalInterface , 作用:编译器会检查,javadoc文档中会特别说明。
这里需要强调的是,函数式接口只能有一个抽象方法,而不是指只能有一个方法。这分两点来说明。首先,在Java 8中,接口运行存在实例方法(见默认方法一节),其次任何被java.lang.Object实现的方法,都不能视为抽象方法,因此,下面的NonFunc接口不是函数式接口,因为equals()方法在java.lang.Object中已经实现。
标准函数式接口
新的 java.util.function 包定义旨在使用 lambdas 的广泛函数式接口。这些接口分为几大类:
Function:接受一个参数,基于参数值返回结果
Predicate:接受一个参数,基于参数值返回一个布尔值
BiFunction:接受两个参数,基于参数值返回结果
Supplier:不接受参数,返回一个结果
Consumer:接受一个参数,无结果 (void)
interface NonFunc {
boolean equals(Object obj);
}同理,下面实现的IntHandler接口符合函数式接口要求,虽然看起来它不像,但实际上它是一个完全符合规范的函数式接口。
@FunctionalInterface
public static interface IntHandler{
void handle(int i);
boolean equals(Object obj);
}接口默认方法
在Java 8之前的版本,接口只能包含抽象方法,Java 8 对接口做了进一步的增强。在接口中可以添加使用 default 关键字修饰的非抽象方法。还可以在接口中定义静态方法。如今,接口看上去与抽象类的功能越来越类似了。这一改进使得Java 8拥有了类似于多继承的能力。一个对象实例,将拥有来自于多个不同接口的实例方法。
比如,对于接口IHorse,实现如下:
public interface IHorse{
void eat();
default void run(){
System.out.println(“hourse run”);
}
}在Java 8中,使用default关键字,可以在接口内定义实例方法。注意,这个方法是并非抽象方法,而是拥有特定逻辑的具体实例方法。
所有的动物都能自由呼吸,所以,这里可以再定义一个IAnimal接口,它也包含一个默认方法breath()。
public interface IAnimal {
default void breath(){
System.out.println(“breath”);
}
}骡是马和驴的杂交物种,因此骡(Mule)可以实现为IHorse,同时骡也是动物,因此有:
public class Mule implements IHorse,IAnimal{
@Override
public void eat() {
System.out.println(“Mule eat”);
}
public static void main(String[] args) {
Mule m=new Mule();
m.run();
m.breath();
}
}注意上述代码中Mule实例同时拥有来自不同接口的实现方法。在这Java 8之前是做不到的。从某种程度上说,这种模式可以弥补Java单一继承的一些不便。但同时也要知道,它也将遇到和多继承相同的问题,如果IDonkey也存在一个默认的run()方法,那么同时实现它们的Mule,就会不知所措,因为它不知道应该以哪个方法为准。此时,由于IHorse和IDonkey拥有相同的默认实例方法,故编译器会抛出一个错误:Duplicate default methods named run with the parameters () and () are inherited from the types IDonkey and IHorse
接口默认实现对于整个函数式编程的流式表达式非常重要。比如,大家熟悉的java.util.Comparator接口,它在JDK 1.2时就已经被引入。在Java 8中,Comparator接口新增了若干个默认方法,用于多个比较器的整合。其中一个常用的默认如下:
default Comparator thenComparing(Comparator other) {
Objects.requireNonNull(other);
return (Comparator & Serializable) (c1, c2) -> {
int res = compare(c1, c2);
return (res != 0) ? res : other.compare(c1, c2);
};
} 有个这个默认方法,在进行排序时,我们就可以非常方便得进行元素的多条件排序,比如,如下代码构造一个比较器,它先按照字符串长度排序,继而按照大小写不敏感的字母顺序排序。
Comparator cmp = Comparator.comparingInt(String::length)
.thenComparing(String.CASE_INSENSITIVE_ORDER); 接口静态方法:
在接口中,还允许定义静态的方法。接口中的静态方法可以直接用接口来调用。
例如,下面接口中定义了一个静态方法 find,该方法可以直接用 StaticFunInterface .find() 来调用。
public interface StaticFunInterface {
public static int find(){
return 1;
}
}
public class TestStaticFun {
public static void main(String[] args){
//接口中定义了静态方法 find 直接被调用
StaticFunInterface.fine();
}
}说明:虽然我知道了default方法是为了便于集合接口(新的StreamsAPI)向后兼容而设计的,但是这个接口静态方法暂时还没体会其作用,可能得接触多了才会明白吧。
方法引用
静态方法引用:ClassName::methodName
实例上的实例方法引用:instanceReference::methodName (这里还可以使用this)
超类上的实例方法引用:super::methodName
类型上的实例方法引用:ClassName::methodName
构造方法引用:Class::new
数组构造方法引用:TypeName[]::new
public class InstanceMethodRef {
public static void main(String[] args) {
List users=new ArrayList();
for(int i=1;i<10;i++){
users.add(new User(i,”billy”+Integer.toString(i)));
}
users.stream().map(User::getName).forEach(System.out::println);
}
} 注意几点:
对于第一个方法引用User::getName,表示User类的实例方法。在执行时,Java会自动识别流中的元素(这里指User实例)是作为调用目标还是调用方法的参数。
一般来说,如果使用的是静态方法,或者调用目标明确,那么流内的元素会自动作为参数使用。如果函数引用表示实例方法,并且不存在调用目标,那么流内元素就会自动作为调用目标。
因此,如果一个类中存在同名的实例方法和静态函数,那么编译器就会感到很困惑,因为此时,它不知道应该使用哪个方法进行调用。
Stream API
打开 Collection Api可以看到多了一个 stream() default 方法:
default Stream stream() {
return StreamSupport.stream(spliterator(), false);
} Stream 允许以声明方式处理集合等可以转换为 Stream
内部迭代 :与原有的 Iterator 不同, Stream 将迭代操作(类似 for / for-each )全部固化到了Api内部实现, 用户只需传入表达计算逻辑的 lambda 表达式(可以理解为 Supplier 、 Function 这些的 @FunctionalInterface 的实现), Stream 便会自动迭代- 数据触发计算逻辑并生成结果. 内部迭代主要解决了两方面的问题: 避免集合处理时的套路和晦涩 ; 便于库内部实现的多核并行优化 .
流水线 :很多 Stream 操作会再返回一个 Stream , 这样多个操作就可以链接起来, 形成一个大的流水线, 使其看起来像是 对数据源进行数据库式查询 , 这也就让自动优化成为可能, 如 隐式并行 .
隐式并行 :如将 .stream() 替换为 .parallelStream() , Stream 则会自动启用Fork/Join框架, 并行执行各条流水线, 并最终自动将结果进行合并.
延迟计算 :由于 Stream 大部分的操作(如 filter() 、 generate() 、 map() …)都是接受一段 lambda 表达式, 逻辑类似接口实现(可以看成是 回调 ), 因此代码并不是立即执行的, 除非流水线上触发一个终端操作, 否则中间操作不会执行任何处理.
短路求值 :有些操作不需要处理整个流就能够拿到结果, 很多像 anyMatch() 、 allMatch() 、 limit() , 只要找到一个元素他们的工作就可以结束, 也就没有必要执行后面的操作, 因此如果后面有大量耗时的操作, 此举可大大节省性能.
Stream 构成
一个流管道(Stream pipeline)通常由3部分构成: 数据源(Source) -> 中间操作/转换(Transforming) -> 终端操作/执行(Operations) : Stream 由数据源生成, 经由中间操作串联起来的一条流水线的转换, 最后由终端操作触发执行拿到结果.
1、数据源-Stream生成
除了前面介绍过的 collection.stream() , 流的生成方式多种多样, 可简单概括为3类: 通用流 、 数值流 、 其他 , 其中以 通用流最为常用, 数值流是Java为 int 、 long 、 double 三种数值类型防 拆装箱 成本所做的优化:
A、通用流
Arrays.stream(T[] array)
Stream.empty()
Stream.generate(Supplier
s) 返回无限无序流,其中每个元素由Supplier 生成. Stream.iterate(T seed, UnaryOperator
f) 返回无限有序流。 Stream.of(T... values)
Stream.concat(Stream a, Stream b) 创建一个懒惰连接的流,其元素是第一个流的所有元素,后跟第二个流的所有元素.
StreamSupport.stream(Spliterator
spliterator, boolean parallel) 从Spliterator创建一个新的顺序流或并行流。.
B、数值流
Arrays.stream(Xxx[] array) Returns a sequential Int/Long/DoubleStream with the specified array as its source.
XxxStream.empty() Returns an empty sequential Int/Long/DoubleStream .
XxxStream.generate(XxxSupplier s) Returns an infinite sequential unordered stream where each element is generated by the provided Int/Long/DoubleSupplier .
XxxStream.iterate(Xxx seed, XxxUnaryOperator f) Returns an infinite sequential ordered Int/Long/DoubleStream like as Stream.iterate(T seed, UnaryOperator
f) XxxStream.of(Xxx... values) Returns a sequential ordered stream whose elements are the specified values.
XxxStream.concat(XxxStream a, XxxStream b) Creates a lazily concatenated stream whose elements are all the elements of the first stream followed by all the elements of the second stream.
Int/LongStream.range(startInclusive, endExclusive) Returns a sequential ordered Int/LongStream from startInclusive (inclusive) to endExclusive (exclusive) by an incremental step of 1.
Int/LongStream.rangeClosed(startInclusive, endInclusive) Returns a sequential ordered Int/LongStream from startInclusive (inclusive) to endInclusive (inclusive) by an incremental step of 1.
C、其他
C.1、I/O Stream
BufferedReader.lines()
C.2、File Stream
Files.lines(Path path)
Files.find(Path start, int maxDepth, BiPredicate
DirectoryStream
newDirectoryStream(Path dir) Files.walk(Path start, FileVisitOption... options)
C.3、Jar
JarFile.stream()
C.4、Random
Random.ints()
Random.longs()
Random.doubles()
C.5、Pattern
splitAsStream(CharSequence input) …
另外, 三种数值流之间, 以及数值流与通用流之间都可以相互转换:
数值流转换: doubleStream.mapToInt(DoubleToIntFunction mapper) 、 intStream.asLongStream() …
数值流转通用流: longStream.boxed() 、 intStream.mapToObj(IntFunction mapper) …
通用流转数值流: stream.flatMapToInt(Function mapper) 、 stream.mapToDouble(ToDoubleFunction mapper) …
中间操作-Stream转换
所有的中间操作都会返回另一个 Stream , 这让多个操作可以链接起来组成中间操作链, 从而形成一条流水线, 因此它的特点就是前面提到的 延迟执行 : 触发流水线上触发一个终端操作, 否则中间操作不执行任何处理.
filter(Predicate predicate)
distinct() Returns a stream consisting of the distinct elements (according to
Object.equals(Object)) of this stream.limit(long maxSize)
skip(long n)
sorted(Comparator comparator)
map(Function mapper) Returns a stream consisting of the results of applying the given function to the elements of this stream.
flatMap(Function> mapper) Returns a stream consisting of the results of replacing each element of this stream with the contents of a mapped stream produced by applying the - provided mapping function to each element.
peek(Consumer action) Returns a stream consisting of the elements of this stream, additionally performing the provided action on each element as elements are consumed from the resulting stream.
这里着重讲解下 flatMap()
假设我们有这样一个字符串list: List
Stream> streamStream = strs.stream()
.map(str -> Arrays.stream(str.split(""))); 我们将 String 分解成 String[] 后再由 Arrays.stream() 将 String[] 映射成 Stream
Stream stringStream = strs.stream()
.flatMap(str -> Arrays.stream(str.split(""))); flatMap() 把 Stream 中的层级结构扁平化了, 将内层 Stream 内的元素抽取出来, 最终新的 Stream 就没有内层 Stream 了.
可以简单概括为: flatMap() 方法让你把一个流中的每个值都换成另一个 Stream , 然后把所有的 Stream 连接起来成为一个 Stream .
终端操作-Stream执行
终端操作不仅担负着触发流水线执行的任务, 他还需要拿到流水线执行的结果, 其结果为任何不是流的值.
count()
max(Comparator comparator)
min(Comparator comparator)
allMatch(Predicate predicate)
anyMatch(Predicate predicate)
noneMatch(Predicate predicate)
findAny()
findFirst()
reduce(BinaryOperator
accumulator) Performs a reduction on the elements of this stream, using an associative accumulation function, and returns an Optional describing the reduced value, if any. toArray()
forEach(Consumer action)
forEachOrdered(Consumer action) Performs an action for each element of this stream, in the encounter order of the stream if the stream has a defined encounter order.
collect(Collector collector) Performs a mutable reduction operation on the elements of this stream using a Collector .
像 IntStream / LongStream / DoubleStream 还提供了 average() 、 sum() 、 summaryStatistics() 这样的操作, 拿到一个对 Stream 进行汇总了的结果.
java.util.stream.Stream 接口继承自 java.util.stream.BaseStream 接口, 而 BaseStream 接口也提供了很多工具方法(如将串行流转换为并行流的 parallel() 方法)供我们使用:
S onClose(Runnable closeHandler) Returns an equivalent stream with an additional close handler .
void close()
S unordered()
Iterator
iterator() Spliterator
spliterator() Returns a spliterator for the elements of this stream. S sequential()
S parallel()
boolean isParallel()
demo
简单点的:
static int [] arr={1,4,3,6,5,7,2,9};
public static void main(String[]args){
//Array.stream()方法返回了一个流对象。类似于集合或者数组,流对象也是一个对象的集合,它将给予我们遍历处理流内元素的功能
Arrays.stream(arr).forEach((x)->System.out.println(x));
}复杂点的:
public void joiningList() {
// 生成一段[0,20)序列
List list = IntStream.range(0, 20)
.boxed()
.collect(Collectors.toList());
// 将list内的偶数提取反向排序后聚合为一个String
String string = list.stream()
.filter(n -> n % 2 == 0)
.sorted(Comparator.comparing((Integer i) -> i).reversed())
.limit(3)
.peek((i) -> System.out.println("remained: " + i))
.map(String::valueOf)
.collect(Collectors.joining());
System.out.println(string);
} public class StreamLambda {
private List transactions;
@Before
public void setUp() {
Trader raoul = new Trader("Raoul", "Cambridge");
Trader mario = new Trader("Mario", "Milan");
Trader alan = new Trader("Alan", "Cambridge");
Trader brian = new Trader("Brian", "Cambridge");
transactions = Arrays.asList(
new Transaction(brian, 2011, 300),
new Transaction(raoul, 2012, 1000),
new Transaction(raoul, 2011, 400),
new Transaction(mario, 2012, 710),
new Transaction(mario, 2012, 700),
new Transaction(alan, 2012, 950)
);
}
@Test
public void action() {
// 1. 打印2011年发生的所有交易, 并按交易额排序(从低到高)
transactions.stream()
.filter(transaction -> transaction.getYear() == 2011)
.sorted(Comparator.comparing(Transaction::getValue))
.forEachOrdered(System.out::println);
// 2. 找出交易员都在哪些不同的城市工作过
Set distinctCities = transactions.stream()
.map(transaction -> transaction.getTrader().getCity())
.collect(Collectors.toSet()); // or .distinct().collect(Collectors.toList())
System.out.println(distinctCities);
// 3. 找出所有来自于剑桥的交易员, 并按姓名排序
Trader[] traders = transactions.stream()
.map(Transaction::getTrader)
.filter(trader -> trader.getCity().equals("Cambridge"))
.distinct()
.sorted(Comparator.comparing(Trader::getName))
.toArray(Trader[]::new);
System.out.println(Arrays.toString(traders));
// 4. 返回所有交易员的姓名字符串, 并按字母顺序排序
String names = transactions.stream()
.map(transaction -> transaction.getTrader().getName())
.distinct()
.sorted(Comparator.naturalOrder())
.reduce("", (str1, str2) -> str1 + " " + str2);
System.out.println(names);
// 5. 返回所有交易员的姓名字母串, 并按字母顺序排序
String letters = transactions.stream()
.map(transaction -> transaction.getTrader().getName())
.distinct()
.map(name -> name.split(""))
.flatMap(Arrays::stream)
.sorted()
.collect(Collectors.joining());
System.out.println(letters);
// 6. 有没有交易员是在米兰工作
boolean workMilan = transactions.stream()
.anyMatch(transaction -> transaction.getTrader().getCity().equals("Milan"));
System.out.println(workMilan);
// 7. 打印生活在剑桥的交易员的所有交易额总和
long sum = transactions.stream()
.filter(transaction -> transaction.getTrader().getCity().equals("Cambridge"))
.mapToLong(Transaction::getValue)
.sum();
System.out.println(sum);
// 8. 所有交易中,最高的交易额是多少
OptionalInt max = transactions.stream()
.mapToInt(Transaction::getValue)
.max();
// or transactions.stream().map(Transaction::getValue).max(Comparator.naturalOrder());
System.out.println(max.orElse(0));
// 9. 找到交易额最小的交易
Optional min = transactions.stream()
.min(Comparator.comparingInt(Transaction::getValue));
System.out.println(min.orElseThrow(IllegalArgumentException::new));
}
} 在Java8中,可以在接口不变的情况下,将流改为并行流。这样,就可以很自然地使用多线程进行集合中的数据处理。
并行流与并行排序
demo:我们希望可以统计一个1~1000000内所有的质数的数量。
IntStream.range(1,1000000).parallel().filter(PrimeUtil::isPrime).count();从集合得到并行流
List ss =new ArrayList();
...
double ave = ss.parallelStream().mapToInt(s->s.score).average().getAsDouble();
int[]arr = new int [10000000];
Arrarys.parallelSort(arr); 进阶:自己生成流
1、Stream.generate
通过实现 Supplier 接口,你可以自己来控制流的生成。这种情形通常用于随机数、常量的 Stream,或者需要前后元素间维持着某种状态信息的 Stream。把 Supplier 实例传递给 Stream.generate() 生成的 Stream,默认是串行(相对 parallel 而言)但无序的(相对 ordered 而言)。由于它是无限的,在管道中,必须利用 limit 之类的操作限制 Stream 大小。
//生成 10 个随机整数
Random seed = new Random();
Supplier random = seed::nextInt;
Stream.generate(random).limit(10).forEach(System.out::println);
//Another way
IntStream.generate(() -> (int) (System.nanoTime() % 100)).
limit(10).forEach(System.out::println); 注意几个关键词:默认串行、无序、无限(需要进行短路求值操作如limit)。
2、Stream.iterate
iterate 跟 reduce 操作很像,接受一个种子值,和一个 UnaryOperator(例如 f)。然后种子值成为 Stream 的第一个元素,f(seed) 为第二个,f(f(seed)) 第三个,以此类推。
//生成一个等差数列 0 3 6 9 12 15 18 21 24 27
Stream.iterate(0, n -> n + 3).limit(10). forEach(x -> System.out.print(x + " "));.与 Stream.generate 相仿,在 iterate 时候管道必须有 limit 这样的操作来限制 Stream 大小。
进阶:用 Collectors 来进行 reduction 操作
java.util.stream.Collectors 类的主要作用就是辅助进行各类有用的 reduction 操作,例如转变输出为 Collection,把 Stream 元素进行归组。
1、groupingBy/partitioningBy
//按照年龄归组
Map> personGroups = Stream.generate(new PersonSupplier()).
limit(100).
collect(Collectors.groupingBy(Person::getAge));
Iterator it = personGroups.entrySet().iterator();
while (it.hasNext()) {
Map.Entry> persons = (Map.Entry) it.next();
System.out.println("Age " + persons.getKey() + " = " + persons.getValue().size());
}
//按照未成年人和成年人归组
Map> children = Stream.generate(new PersonSupplier()).
limit(100).
collect(Collectors.partitioningBy(p -> p.getAge() < 18));
System.out.println("Children number: " + children.get(true).size());
System.out.println("Adult number: " + children.get(false).size());
//在使用条件“年龄小于 18”进行分组后可以看到,不到 18 岁的未成年人是一组,成年人是另外一组。partitioningBy 其实是一种特殊的 groupingBy,它依照条件测试的是否两种结果来构造返回的数据结构,get(true) 和 get(false) 能即为全部的元素对象。 Stream总结
其实这里很多观念和Spark的RDD操作很相似。
总之,Stream 的特性可以归纳为:
不是数据结构,它没有内部存储,它只是用操作管道从 source(数据结构、数组、generator function、IO channel)抓取数据。
它也绝不修改自己所封装的底层数据结构的数据。例如 Stream 的 filter 操作会产生一个不包含被过滤元素的新 Stream,而不是从 source 删除那些元素。
所有 Stream 的操作必须以 lambda 表达式为参数
不支持索引访问,你可以请求第一个元素,但无法请求第二个,第三个,或最后一个。
很容易生成数组或者 List
惰性化,Intermediate 操作永远是惰性化的。
很多 Stream 操作是向后延迟的,一直到它弄清楚了最后需要多少数据才会开始。
并行能力,当一个 Stream 是并行化的,就不需要再写多线程代码,所有对它的操作会自动并行进行的。
可以是无限的,集合有固定大小,Stream 则不必。limit(n) 和 findFirst() 这类的 short-circuiting 操作可以对无限的 Stream 进行运算并很快完成。
注解的更新
对于注解,Java 8 主要有两点改进:类型注解和重复注解。
Java 8 的类型注解扩展了注解使用的范围。在该版本之前,注解只能是在声明的地方使用。现在几乎可以为任何东西添加注解:局部变量、类与接口,就连方法的异常也能添加注解。新增的两个注释的程序元素类型 ElementType.TYPE_USE 和 ElementType.TYPE_PARAMETER 用来描述注解的新场合。
ElementType.TYPE_PARAMETER 表示该注解能写在类型变量的声明语句中。而 ElementType.TYPE_USE 表示该注解能写在使用类型的任何语句中(例如声明语句、泛型和强制转换语句中的类型)。
对类型注解的支持,增强了通过静态分析工具发现错误的能力。原先只能在运行时发现的问题可以提前在编译的时候被排查出来。Java 8 本身虽然没有自带类型检测的框架,但可以通过使用 Checker Framework 这样的第三方工具,自动检查和确认软件的缺陷,提高生产效率。
在Java8之前使用注解的一个限制是相同的注解在同一位置只能声明一次,不能声明多次。Java 8 引入了重复注解机制,这样相同的注解可以在同一地方声明多次。重复注解机制本身必须用 @Repeatable 注解。
IO/NIO 的改进
增加了一些新的 IO/NIO 方法,使用这些方法可以从文件或者输入流中获取流(java.util.stream.Stream),通过对流的操作,可以简化文本行处理、目录遍历和文件查找。
新增的 API 如下:
BufferedReader.line(): 返回文本行的流 Stream
File.lines(Path, Charset):返回文本行的流 Stream
File.list(Path): 遍历当前目录下的文件和目录
File.walk(Path, int, FileVisitOption): 遍历某一个目录下的所有文件和指定深度的子目录
File.find(Path, int, BiPredicate, FileVisitOption... ): 查找相应的文件
下面就是用流式操作列出当前目录下的所有文件和目录:
Files.list(new File(".").toPath())
.forEach(System.out::println);新的Date/Time API
Java 的日期与时间 API 问题由来已久,Java 8 之前的版本中关于时间、日期及其他时间日期格式化类由于线程安全、重量级、序列化成本高等问题而饱受批评。Java 8 吸收了 Joda-Time 的精华,以一个新的开始为 Java 创建优秀的 API。新的 java.time 中包含了所有关于时钟(Clock),本地日期(LocalDate)、本地时间(LocalTime)、本地日期时间(LocalDateTime)、时区(ZonedDateTime)和持续时间(Duration)的类。历史悠久的 Date 类新增了 toInstant() 方法,用于把 Date 转换成新的表示形式。这些新增的本地化时间日期 API 大大简化了了日期时间和本地化的管理。
Java日期/时间API包含以下相应的包。
java.time包:这是新的Java日期/时间API的基础包,所有的主要基础类都是这个包的一部分,如:LocalDate, LocalTime, LocalDateTime, Instant, Period, Duration等等。所有这些类都是不可变的和线程安全的,在绝大多数情况下,这些类能够有效地处理一些公共的需求。
java.time.chrono包:这个包为非ISO的日历系统定义了一些泛化的API,我们可以扩展AbstractChronology类来创建自己的日历系统。
java.time.format包:这个包包含能够格式化和解析日期时间对象的类,在绝大多数情况下,我们不应该直接使用它们,因为
java.time包中相应的类已经提供了格式化和解析的方法。java.time.temporal包:这个包包含一些时态对象,我们可以用其找出关于日期/时间对象的
某个特定日期或时间,比如说,可以找到某月的第一天或最后一天。你可以非常容易地认出这些方法,因为它们都具有“withXXX”的格式。java.time.zone包:这个包包含支持不同时区以及相关规则的类。
例如,下面是对 LocalDate,LocalTime 的简单应用:
//LocalDate只保存日期系统的日期部分,有时区信息,LocalTime只保存时间部分,没有时区信息。LocalDate和LocalTime都可以从Clock对象创建。
//LocalDate
LocalDate localDate = LocalDate.now(); //获取本地日期
localDate = LocalDate.ofYearDay(2014, 200); // 获得 2014 年的第 200 天
System.out.println(localDate.toString());//输出:2014-07-19
localDate = LocalDate.of(2014, Month.SEPTEMBER, 10); //2014 年 9 月 10 日
System.out.println(localDate.toString());//输出:2014-09-10
//LocalTime
LocalTime localTime = LocalTime.now(); //获取当前时间
System.out.println(localTime.toString());//输出当前时间
localTime = LocalTime.of(10, 20, 50);//获得 10:20:50 的时间点
System.out.println(localTime.toString());//输出: 10:20:50
//Clock 时钟,Clock类可以替换 System.currentTimeMillis() 和 TimeZone.getDefault(). 如:Clock.systemDefaultZone().millis()
Clock clock = Clock.systemDefaultZone();//获取系统默认时区 (当前瞬时时间 )
long millis = clock.millis();//
//LocalDateTime类合并了LocalDate和LocalTime,它保存有ISO-8601日期系统的日期和时间,但是没有时区信息。
final LocalDateTime datetime = LocalDateTime.now();
final LocalDateTime datetimeFromClock = LocalDateTime.now( clock );
System.out.println( datetime );
System.out.println( datetimeFromClock );
//如果您需要一个类持有日期时间和时区信息,可以使用ZonedDateTime,它保存有ISO-8601日期系统的日期和时间,而且有时区信息。
final ZonedDateTime zonedDatetime = ZonedDateTime.now();
final ZonedDateTime zonedDatetimeFromClock = ZonedDateTime.now( clock );
final ZonedDateTime zonedDatetimeFromZone = ZonedDateTime.now( ZoneId.of( "America/Los_Angeles" ) );
System.out.println( zonedDatetime );
System.out.println( zonedDatetimeFromClock );
System.out.println( zonedDatetimeFromZone );Duration类,Duration持有的时间精确到纳秒。它让我们很容易计算两个日期中间的差异。让我们来看一下:
// Get duration between two dates
final LocalDateTime from = LocalDateTime.of( 2014, Month.APRIL, 16, 0, 0, 0 );
final LocalDateTime to = LocalDateTime.of( 2015, Month.APRIL, 16, 23, 59, 59 );
final Duration duration = Duration.between( from, to );
System.out.println( "Duration in days: " + duration.toDays() );
System.out.println( "Duration in hours: " + duration.toHours() );上面的例子计算了两个日期(2014年4月16日和2014年5月16日)之间的持续时间(基于天数和小时)
日期API操作
//日期算术操作,多数日期/时间API类都实现了一系列工具方法,如:加/减天数、周数、月份数,等等。还有其他的工具方法能够使用TemporalAdjuster调整日期,并计算两个日期间的周期。
LocalDate today = LocalDate.now();
//Get the Year, check if it's leap year
System.out.println("Year "+today.getYear()+" is Leap Year? "+today.isLeapYear());
//Compare two LocalDate for before and after
System.out.println("Today is before 01/01/2015? "+today.isBefore(LocalDate.of(2015,1,1)));
//Create LocalDateTime from LocalDate
System.out.println("Current Time="+today.atTime(LocalTime.now()));
//plus and minus operations
System.out.println("10 days after today will be "+today.plusDays(10));
System.out.println("3 weeks after today will be "+today.plusWeeks(3));
System.out.println("20 months after today will be "+today.plusMonths(20));
System.out.println("10 days before today will be "+today.minusDays(10));
System.out.println("3 weeks before today will be "+today.minusWeeks(3));
System.out.println("20 months before today will be "+today.minusMonths(20));
//Temporal adjusters for adjusting the dates
System.out.println("First date of this month= "+today.with(TemporalAdjusters.firstDayOfMonth()));
LocalDate lastDayOfYear = today.with(TemporalAdjusters.lastDayOfYear());
System.out.println("Last date of this year= "+lastDayOfYear);
Period period = today.until(lastDayOfYear);
System.out.println("Period Format= "+period);
System.out.println("Months remaining in the year= "+period.getMonths()); 解析和格式化:将一个日期格式转换为不同的格式,之后再解析一个字符串,得到日期时间对象
//Format examples
LocalDate date = LocalDate.now();
//default format
System.out.println("Default format of LocalDate="+date);
//specific format
System.out.println(date.format(DateTimeFormatter.ofPattern("d::MMM::uuuu")));
System.out.println(date.format(DateTimeFormatter.BASIC_ISO_DATE));
LocalDateTime dateTime = LocalDateTime.now();
//default format
System.out.println("Default format of LocalDateTime="+dateTime);
//specific format
System.out.println(dateTime.format(DateTimeFormatter.ofPattern("d::MMM::uuuu HH::mm::ss")));
System.out.println(dateTime.format(DateTimeFormatter.BASIC_ISO_DATE));
Instant timestamp = Instant.now();
//default format
System.out.println("Default format of Instant="+timestamp);
//Parse examples
LocalDateTime dt = LocalDateTime.parse("27::Apr::2014 21::39::48",
DateTimeFormatter.ofPattern("d::MMM::uuuu HH::mm::ss"));
System.out.println("Default format after parsing = "+dt);旧的日期时间支持转换:
//Date to Instant
Instant timestamp = new Date().toInstant();
//Now we can convert Instant to LocalDateTime or other similar classes
LocalDateTime date = LocalDateTime.ofInstant(timestamp,
ZoneId.of(ZoneId.SHORT_IDS.get("PST")));
System.out.println("Date = "+date);
//Calendar to Instant
Instant time = Calendar.getInstance().toInstant();
System.out.println(time);
//TimeZone to ZoneId
ZoneId defaultZone = TimeZone.getDefault().toZoneId();
System.out.println(defaultZone);
//ZonedDateTime from specific Calendar
ZonedDateTime gregorianCalendarDateTime = new GregorianCalendar().toZonedDateTime();
System.out.println(gregorianCalendarDateTime);
//Date API to Legacy classes
Date dt = Date.from(Instant.now());
System.out.println(dt);
TimeZone tz = TimeZone.getTimeZone(defaultZone);
System.out.println(tz);
GregorianCalendar gc = GregorianCalendar.from(gregorianCalendarDateTime);
System.out.println(gc);Java8 CompletableFuture强大的函数式异步编程辅助类
Future是Java 5添加的类,用来描述一个异步计算的结果。你可以使用isDone方法检查计算是否完成,或者使用get阻塞住调用线程,直到计算完成返回结果,你也可以使用cancel方法停止任务的执行。
虽然Future以及相关使用方法提供了异步执行任务的能力,但是对于结果的获取却是很不方便,只能通过阻塞或者轮询的方式得到任务的结果。阻塞的方式显然和我们的异步编程的初衷相违背,轮询的方式又会耗费无谓的CPU资源,而且也不能及时地得到计算结果,为什么不能用观察者设计模式当计算结果完成及时通知监听者呢?
其实Google guava早就提供了通用的扩展Future:ListenableFuture、SettableFuture 以及辅助类Futures等,方便异步编程。
final String name = ...;
inFlight.add(name);
ListenableFuture future = service.query(name);
future.addListener(new Runnable() {
public void run() {
processedCount.incrementAndGet();
inFlight.remove(name);
lastProcessed.set(name);
logger.info("Done with {0}", name);
}
}, executor); 在Java 8中, 新增加了一个包含50个方法左右的类: CompletableFuture,提供了非常强大的Future的扩展功能,可以帮助我们简化异步编程的复杂性,提供了函数式编程的能力,可以通过回调的方式处理计算结果,并且提供了转换和组合CompletableFuture的方法。
CompletableFuture类实现了CompletionStage和Future接口,所以你还是可以像以前一样通过阻塞或者轮询的方式获得结果,尽管这种方式不推荐使用。
尽管Future可以代表在另外的线程中执行的一段异步代码,但是你还是可以在本身线程中执行:
public class BasicMain {
public static CompletableFuture compute() {
final CompletableFuture future = new CompletableFuture<>();
return future;
}
public static void main(String[] args) throws Exception {
final CompletableFuture f = compute();
class Client extends Thread {
CompletableFuture f;
Client(String threadName, CompletableFuture f) {
super(threadName);
this.f = f;
}
@Override
public void run() {
try {
System.out.println(this.getName() + ": " + f.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
new Client("Client1", f).start();
new Client("Client2", f).start();
System.out.println("waiting");
//上面的代码中future没有关联任何的Callback、线程池、异步任务等,如果客户端调用future.get就会一致傻等下去。除非我们显式指定complete
f.complete(100);
//f.completeExceptionally(new Exception());
System.in.read();
}
} CompletableFuture.complete()、CompletableFuture.completeExceptionally只能被调用一次。但是我们有两个后门方法可以重设这个值:obtrudeValue、obtrudeException,但是使用的时候要小心,因为complete已经触发了客户端,有可能导致客户端会得到不期望的结果。
1、创建CompletableFuture对象。
public static CompletableFuture completedFuture(U value)
public static CompletableFuture
runAsync(Runnable runnable) public static CompletableFuture
runAsync(Runnable runnable, Executor executor) public static CompletableFuture supplyAsync(Supplier supplier)
public static CompletableFuture supplyAsync(Supplier supplier, Executor executor)
注意:以Async结尾并且没有指定Executor的方法会使用ForkJoinPool.commonPool()作为它的线程池执行异步代码。因为方法的参数类型都是函数式接口,所以可以使用lambda表达式实现异步任务
2、计算结果完成时的处理
当CompletableFuture的计算结果完成,或者抛出异常的时候,我们可以执行特定的Action。主要是下面的方法:
public CompletableFuture
whenComplete(BiConsumer action) public CompletableFuture
whenCompleteAsync(BiConsumer action) public CompletableFuture
whenCompleteAsync(BiConsumer action, Executor executor) public CompletableFuture
exceptionally(Function
注意:方法不以Async结尾,意味着Action使用相同的线程执行,而Async可能会使用其它的线程去执行(如果使用相同的线程池,也可能会被同一个线程选中执行)
public class Main {
private static Random rand = new Random();
private static long t = System.currentTimeMillis();
static int getMoreData() {
System.out.println("begin to start compute");
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("end to start compute. passed " + (System.currentTimeMillis() - t)/1000 + " seconds");
return rand.nextInt(1000);
}
public static void main(String[] args) throws Exception {
CompletableFuture future = CompletableFuture.supplyAsync(Main::getMoreData);
Future f = future.whenComplete((v, e) -> {
System.out.println(v);
System.out.println(e);
});
System.out.println(f.get());
System.in.read();
}
} 下面一组方法虽然也返回CompletableFuture对象,但是对象的值和原来的CompletableFuture计算的值不同。当原先的CompletableFuture的值计算完成或者抛出异常的时候,会触发这个CompletableFuture对象的计算,结果由BiFunction参数计算而得。
因此这组方法兼有whenComplete和转换的两个功能。
public CompletableFuture handle(BiFunction fn)
public CompletableFuture handleAsync(BiFunction fn)
public CompletableFuture handleAsync(BiFunction fn, Executor executor)
同样,不以Async结尾的方法由原来的线程计算,以Async结尾的方法由默认的线程池ForkJoinPool.commonPool()或者指定的线程池executor运行。
3、转换
CompletableFuture可以作为monad(单子)和functor。由于回调风格的实现,我们不必因为等待一个计算完成而阻塞着调用线程,而是告诉CompletableFuture当计算完成的时候请执行某个function。而且我们还可以将这些操作串联起来,或者将CompletableFuture组合起来。
public CompletableFuture thenApply(Function fn)
public CompletableFuture thenApplyAsync(Function fn)
public CompletableFuture thenApplyAsync(Function fn, Executor executor)
这一组函数的功能是当原来的CompletableFuture计算完后,将结果传递给函数fn,将fn的结果作为新的CompletableFuture计算结果。因此它的功能相当于将CompletableFuture转换成CompletableFuture
它们与handle方法的区别在于handle方法会处理正常计算值和异常,因此它可以屏蔽异常,避免异常继续抛出。而thenApply方法只是用来处理正常值,因此一旦有异常就会抛出。
CompletableFuture future = CompletableFuture.supplyAsync(() -> {
return 100;
});
CompletableFuture f = future.thenApplyAsync(i -> i * 10).thenApply(i -> i.toString());
System.out.println(f.get()); //"1000" 需要注意的是,这些转换并不是马上执行的,也不会阻塞,而是在前一个stage完成后继续执行。
4、纯消费(执行Action)
上面的方法是当计算完成的时候,会生成新的计算结果(thenApply, handle),或者返回同样的计算结果whenComplete,CompletableFuture还提供了一种处理结果的方法,只对结果执行Action,而不返回新的计算值,因此计算值为Void:
public CompletableFuture
thenAccept(Consumer action) public CompletableFuture
thenAcceptAsync(Consumer action) public CompletableFuture
thenAcceptAsync(Consumer action, Executor executor)
看它的参数类型也就明白了,它们是函数式接口Consumer,这个接口只有输入,没有返回值。
CompletableFuture future = CompletableFuture.supplyAsync(() -> {
return 100;
});
CompletableFuture f = future.thenAccept(System.out::println);
System.out.println(f.get()); thenAcceptBoth以及相关方法提供了类似的功能,当两个CompletionStage都正常完成计算的时候,就会执行提供的action,它用来组合另外一个异步的结果。 runAfterBoth是当两个CompletionStage都正常完成计算的时候,执行一个Runnable,这个Runnable并不使用计算的结果。
public CompletableFuture
thenAcceptBoth(CompletionStage other, BiConsumer action) public CompletableFuture
thenAcceptBothAsync(CompletionStage other, BiConsumer action) public CompletableFuture
thenAcceptBothAsync(CompletionStage other, BiConsumer action, Executor executor) public CompletableFuture
runAfterBoth(CompletionStage other, Runnable action)
例子如下:
CompletableFuture future = CompletableFuture.supplyAsync(() -> {
return 100;
});
CompletableFuture f = future.thenAcceptBoth(CompletableFuture.completedFuture(10), (x, y) -> System.out.println(x * y));
System.out.println(f.get()); 更彻底地,下面一组方法当计算完成的时候会执行一个Runnable,与thenAccept不同,Runnable并不使用CompletableFuture计算的结果。
public CompletableFuture
thenRun(Runnable action) public CompletableFuture
thenRunAsync(Runnable action) public CompletableFuture
thenRunAsync(Runnable action, Executor executor)
CompletableFuture future = CompletableFuture.supplyAsync(() -> {
return 100;
});
CompletableFuture f = future.thenRun(() -> System.out.println("finished"));
System.out.println(f.get()); 因此,你可以根据方法的参数的类型来加速你的记忆。Runnable类型的参数会忽略计算的结果,Consumer是纯消费计算结果,BiConsumer会组合另外一个CompletionStage纯消费,Function会对计算结果做转换,BiFunction会组合另外一个CompletionStage的计算结果做转换。
5、组合compose
public CompletableFuture thenCompose(Function> fn)
public CompletableFuture thenComposeAsync(Function> fn)
public CompletableFuture thenComposeAsync(Function> fn, Executor executor)
这一组方法接受一个Function作为参数,这个Function的输入是当前的CompletableFuture的计算值,返回结果将是一个新的CmpletableFuture,这个新的CompletableFuture会组合原来的CompletableFuture和函数返回的CompletableFuture。public
thenCombine(CompletionStage other, BiFunction fn) public
thenCombineAsync(CompletionStage other, BiFunction fn) public
thenCombineAsync(CompletionStage other, BiFunction fn, Executor executor)
两个CompletionStage是并行执行的,它们之间并没有先后依赖顺序,other并不会等待先前的CompletableFuture执行完毕后再执行。
6、Either
thenAcceptBoth和runAfterBoth是当两个CompletableFuture都计算完成,而我们下面要了解的方法是当任意一个CompletableFuture计算完成的时候就会执行。
public CompletableFuture
acceptEither(CompletionStage other, Consumer action) public CompletableFuture
acceptEitherAsync(CompletionStage other, Consumer action) public CompletableFuture
acceptEitherAsync(CompletionStage other, Consumer action, Executor executor) public CompletableFuture applyToEither(CompletionStage other, Function fn)
public CompletableFuture applyToEitherAsync(CompletionStage other, Function fn)
public CompletableFuture applyToEitherAsync(CompletionStage other, Function fn, Executor executor)
下面这个例子有时会输出100,有时候会输出200,哪个Future先完成就会根据它的结果计算。
Random rand = new Random();
CompletableFuture future = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(10000 + rand.nextInt(1000));
} catch (InterruptedException e) {
e.printStackTrace();
}
return 100;
});
CompletableFuture future2 = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(10000 + rand.nextInt(1000));
} catch (InterruptedException e) {
e.printStackTrace();
}
return 200;
});
CompletableFuture f = future.applyToEither(future2,i -> i.toString());
7、辅助方法 allOf 和 anyOf
用来组合多个CompletableFuture。
public static CompletableFuture
allOf(CompletableFuture... cfs) public static CompletableFuture
anyOf方法是当任意一个CompletableFuture执行完后就会执行计算,计算的结果相同。
8、更进一步
如果你用过Guava的Future类,你就会知道它的Futures辅助类提供了很多便利方法,用来处理多个Future,而不像Java的CompletableFuture,只提供了allOf、anyOf两个方法。
比如有这样一个需求,将多个CompletableFuture组合成一个CompletableFuture,这个组合后的CompletableFuture的计算结果是个List,它包含前面所有的CompletableFuture的计算结果,guava的Futures.allAsList可以实现这样的功能.
但是对于java CompletableFuture,我们需要一些辅助方法:
public static CompletableFuture> sequence(List> futures) {
CompletableFuture allDoneFuture = CompletableFuture.allOf(futures.toArray(new CompletableFuture[futures.size()]));
return allDoneFuture.thenApply(v -> futures.stream().map(CompletableFuture::join).collect(Collectors.toList()));
}
public static CompletableFuture> sequence(Stream> futures) {
List> futureList = futures.filter(f -> f != null).collect(Collectors.toList());
return sequence(futureList);
} Java Future转CompletableFuture:
public static CompletableFuture toCompletable(Future future, Executor executor) {
return CompletableFuture.supplyAsync(() -> {
try {
return future.get();
} catch (InterruptedException | ExecutionException e) {
throw new RuntimeException(e);
}
}, executor);
} github有多个项目可以实现Java CompletableFuture与其它Future (如Guava ListenableFuture)之间的转换,如spotify/futures-extra、future-converter、scala/scala-java8-compat 等。
其他
Java 8 Optional类
大家可能都有这样的经历:调用一个方法得到了返回值却不能直接将返回值作为参数去调用别的方法。我们首先要判断这个返回值是否为null,只有在非空的前提下才能将其作为其他方法的参数。
Java 8引入了一个新的Optional类。Optional类的Javadoc描述如下:这是一个可以为null的容器对象。如果值存在则isPresent()方法会返回true,调用get()方法会返回该对象。
1、of:为非null的值创建一个Optional。需要注意的是,创建对象时传入的参数不能为null。如果传入参数为null,则抛出NullPointerException
//调用工厂方法创建Optional实例
Optional name = Optional.of("Sanaulla");
//错误写法,传入参数为null,抛出NullPointerException.
Optional someNull = Optional.of(null); 2、ofNullable:为指定的值创建一个Optional,如果指定的值为null,则返回一个空的Optional。
ofNullable与of方法相似,唯一的区别是可以接受参数为null的情况
3、isPresent:如果值存在返回true,否则返回false。
4、get:如果Optional有值则将其返回,否则抛出NoSuchElementException。
5、ifPresent:如果Optional实例有值则为其调用consumer,否则不做处理
要理解ifPresent方法,首先需要了解Consumer类。简答地说,Consumer类包含一个抽象方法。该抽象方法对传入的值进行处理,但没有返回值。Java8支持不用接口直接通过lambda表达式传入参数。
//ifPresent方法接受lambda表达式作为参数。
//lambda表达式对Optional的值调用consumer进行处理。
name.ifPresent((value) -> {
System.out.println("The length of the value is: " + value.length());
});6、orElse:如果有值则将其返回,否则返回orElse方法传入的参数。
7、orElseGet:orElseGet与orElse方法类似,区别在于得到的默认值。orElse方法将传入的字符串作为默认值,orElseGet方法可以接受Supplier接口的实现用来生成默认值。示例如下:
//orElseGet与orElse方法类似,区别在于orElse传入的是默认值,
//orElseGet可以接受一个lambda表达式生成默认值。
//输出:Default Value
System.out.println(empty.orElseGet(() -> "Default Value"));
//输出:Sanaulla
System.out.println(name.orElseGet(() -> "Default Value"));8、orElseThrow:如果有值则将其返回,否则抛出supplier接口创建的异常。
在orElseGet方法中,我们传入一个Supplier接口。然而,在orElseThrow中我们可以传入一个lambda表达式或方法,如果值不存在来抛出异常。示例如下:
try {
//orElseThrow与orElse方法类似。与返回默认值不同,
//orElseThrow会抛出lambda表达式或方法生成的异常
empty.orElseThrow(ValueAbsentException::new);
} catch (Throwable ex) {
//输出: No value present in the Optional instance
System.out.println(ex.getMessage());
}9、map:如果有值,则对其执行调用mapping函数得到返回值。如果返回值不为null,则创建包含mapping返回值的Optional作为map方法返回值,否则返回空Optional。
map方法用来对Optional实例的值执行一系列操作。
//map方法执行传入的lambda表达式参数对Optional实例的值进行修改。
//为lambda表达式的返回值创建新的Optional实例作为map方法的返回值。
Optional upperName = name.map((value) -> value.toUpperCase());
System.out.println(upperName.orElse("No value found")); 10、flatMap:如果有值,为其执行mapping函数返回Optional类型返回值,否则返回空Optional。flatMap与map(Funtion)方法类似,区别在于flatMap中的mapper返回值必须是Optional。调用结束时,flatMap不会对结果用Optional封装。
//flatMap与map(Function)非常类似,区别在于传入方法的lambda表达式的返回类型。
//map方法中的lambda表达式返回值可以是任意类型,在map函数返回之前会包装为Optional。
//但flatMap方法中的lambda表达式返回值必须是Optionl实例。
upperName = name.flatMap((value) -> Optional.of(value.toUpperCase()));
System.out.println(upperName.orElse("No value found"));//输出SANAULLA11、filter:如果有值并且满足断言条件返回包含该值的Optional,否则返回空Optional。
//filter方法检查给定的Option值是否满足某些条件。
//如果满足则返回同一个Option实例,否则返回空Optional。
Optional longName = name.filter((value) -> value.length() > 6);
System.out.println(longName.orElse("The name is less than 6 characters"));//输出Sanaulla
//另一个例子是Optional值不满足filter指定的条件。
Optional anotherName = Optional.of("Sana");
Optional shortName = anotherName.filter((value) -> value.length() > 6);
//输出:name长度不足6字符
System.out.println(shortName.orElse("The name is less than 6 characters")); Java8编译器的新特性
1、参数名字
很长时间以来,Java程序员想尽办法把参数名字保存在java字节码里,并且让这些参数名字在运行时可用。Java 8 终于把这个需求加入到了Java语言(使用反射API和Parameter.getName() 方法)和字节码里(使用java编译命令javac的–parameters参数)。
import java.lang.reflect.Method;
import java.lang.reflect.Parameter;
public class ParameterNames {
public static void main(String[] args) throws Exception {
Method method = ParameterNames.class.getMethod( "main", String[].class );
for( final Parameter parameter: method.getParameters() ) {
System.out.println( "Parameter: " + parameter.getName() );
}
}
}额外的,有一个方便的方法Parameter.isNamePresent() 来验证参数名是不是可用。
如果你编译这个class的时候没有添加参数–parameters,运行的时候你会得到这个结果:
Parameter: arg0
编译的时候添加了–parameters参数的话,运行结果会不一样:
Parameter: args
对于有经验的Maven使用者,–parameters参数可以添加到maven-compiler-plugin的配置部分:
org.apache.maven.plugins
maven-compiler-plugin
3.1
-parameters
1.8
1.8
eclipse中也可以进行相关配置: 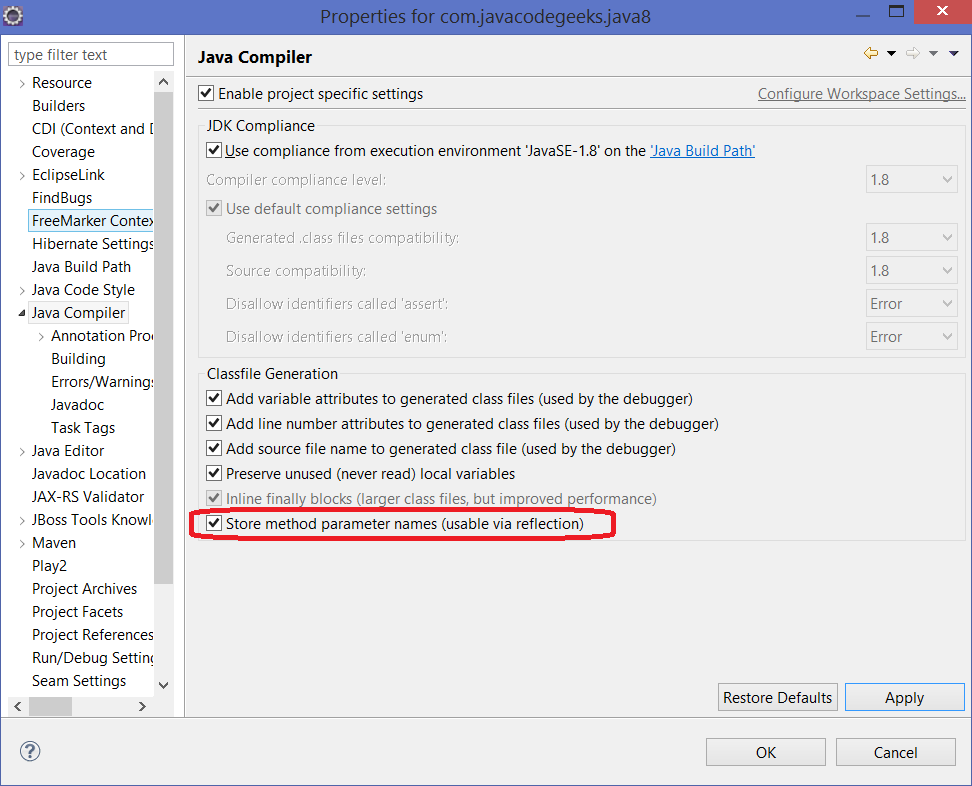
Nashorn javascript引擎
Java 8提供了一个新的Nashorn javascript引擎,它允许我们在JVM上运行特定的javascript应用。Nashorn javascript引擎只是javax.script.ScriptEngine另一个实现,而且规则也一样,允许Java和JavaScript互相操作。这里有个小例子:
ScriptEngineManager manager = new ScriptEngineManager();
ScriptEngine engine = manager.getEngineByName( "JavaScript" );
System.out.println( engine.getClass().getName() );
System.out.println( "Result:" + engine.eval( "function f() { return 1; }; f() + 1;");推荐参考:http://www.importnew.com/2266...
Base64
对Base64的支持最终成了Java 8标准库的一部分,非常简单易用:
import java.nio.charset.StandardCharsets;
import java.util.Base64;
public class Base64s {
public static void main(String[] args) {
final String text = "Base64 finally in Java 8!";
final String encoded = Base64
.getEncoder()
.encodeToString( text.getBytes( StandardCharsets.UTF_8 ) );
System.out.println( encoded );
final String decoded = new String(
Base64.getDecoder().decode( encoded ),
StandardCharsets.UTF_8 );
System.out.println( decoded );
}
}新的Base64API也支持URL和MINE的编码解码。 (Base64.getUrlEncoder() / Base64.getUrlDecoder(), Base64.getMimeEncoder() / Base64.getMimeDecoder()).
并行数组
Java 8新增加了很多方法支持并行的数组处理。最重要的大概是parallelSort()这个方法显著地使排序在多核计算机上速度加快。下面的小例子演示了这个新的方法(parallelXXX)的行为。
import java.util.Arrays;
import java.util.concurrent.ThreadLocalRandom;
public class ParallelArrays {
public static void main( String[] args ) {
long[] arrayOfLong = new long [ 20000 ];
Arrays.parallelSetAll( arrayOfLong,
index -> ThreadLocalRandom.current().nextInt( 1000000 ) );
Arrays.stream( arrayOfLong ).limit( 10 ).forEach(
i -> System.out.print( i + " " ) );
System.out.println();
Arrays.parallelSort( arrayOfLong );
Arrays.stream( arrayOfLong ).limit( 10 ).forEach(
i -> System.out.print( i + " " ) );
System.out.println();
}
}这一小段代码使用parallelSetAll() t方法填充这个长度是2000的数组,然后使用parallelSort() 排序。这个程序输出了排序前和排序后的10个数字来验证数组真的已经被排序了。
并发工具
在新增Stream机制与lambda的基础之上,在java.util.concurrent.ConcurrentHashMap中加入了一些新方法来支持聚集操作。同时也在java.util.concurrent.ForkJoinPool类中加入了一些新方法来支持共有资源池(common pool)
新增的java.util.concurrent.locks.StampedLock类提供一直基于容量的锁,这种锁有三个模型来控制读写操作(它被认为是不太有名的java.util.concurrent.locks.ReadWriteLock类的替代者)。
在java.util.concurrent.atomic包中还增加了下面这些类:
DoubleAccumulator
DoubleAdder
LongAccumulator
LongAdder
类依赖分析工具:jdeps
Jdeps是一个功能强大的命令行工具,它可以帮我们显示出包层级或者类层级java类文件的依赖关系。它接受class文件、目录、jar文件作为输入,默认情况下,jdeps会输出到控制台。
JVM的新特性
JVM内存永久区(Perm)已经被metaspace替换(JEP 122)。JVM参数 -XX:PermSize 和 –XX:MaxPermSize被XX:MetaSpaceSize 和 -XX:MaxMetaspaceSize代替。
参考:
写给大忙人的JavaSE8
https://www.ibm.com/developer...
https://segmentfault.com/a/11...
http://www.tuicool.com/articl...
https://www.ibm.com/developer...
https://www.ibm.com/developer...
http://www.importnew.com/6675...
http://www.importnew.com/1934...
http://www.importnew.com/1414...
http://docs.oracle.com/javase...
http://colobu.com/2016/02/29/...