一文读懂深度学习分割网络发展史(重点介绍pspnet)
FCN,Unet , Segnet,RefineNet,PSPNet,Deeplab v1&v2&v3、ERFNET
图像分割问题可以理解为聚类问题。
图像分割任务的本质是像素级别的分类。
深度学习来做图像分割需要考虑的因素(实际上所有算法都应该考虑):
(1)资源,就是达到某种分割效果所需要的算法复杂度。
(2)效果,算法最终的分割效果达到了什么程度。
(3)效率,即分割一帧图片需要的时间。
从算法本质来看,追求的是利用算法达成某个目标的性价比,即性能和资源(代价)的一个平衡。脱离某一方面,去谈另一方面都是没有任何意义的。
进一步而言,产品迭代的过程也是如此,先要满足性能,然后开始考虑成本。
例如:手机的发展历史,一开始是BB机,然后是大哥大,接着是小灵通,最后是智能手机,以及后来的触屏手机。
这些分割网络的基础是CNN。
注:分割网络的预测是基于像素点的预测。
如何才能使像素预测更加准确?
方法一: 得到图像多尺度的特征信息。
方法二: 得到图像中相邻物体像素之间的逻辑关系。
理论依据:像素点的预测需要综合全局的场景类别信息,以及局部的类别信息来判断,这样的预测更加可靠。
实现方法:通过金字塔场景解析网络(pspnet)可以得到输入图像不同尺度下的特征,这样就可以综合不同尺度的特征,得到全局和局部的信息,从而对像素进行准确预测。
分割问题很难使用CNN的原因:
原因1:全连接层结构
分割需要综合局部和全局的信息来作出分割,如果只考虑全局信息,没有局部信息,无法完成分割
原因2:存在池化层。池化层不仅能增大上层卷积核的感受野,而且能聚合背景同时丢弃部分位置信息。然而,语义分割方法需对类别图谱进行精确调整,因此需保留池化层中所舍弃的位置信息。
CRF方法是一种基于底层图像像素强度进行“平滑”分割的图模型,在运行时会将像素强度相似的点标记为同一类别。加入条件随机场方法可以提高1~2%的最终评分值。
FCN网络
论文:Fully Convolutional Networks for Semantic Segmentation 于2014年11月14日提交到arvix:https://arxiv.org/abs/1411.4038
主要贡献:
深度学习分割网络的鼻祖。
将端到端的卷积网络推广到语义分割中;
重新将预训练好的Imagenet网络用于分割问题中;
(1)使用反卷积层进行上采样/反卷积;
采用上采样和反卷积得到了和原图同等比例的图像进行分割
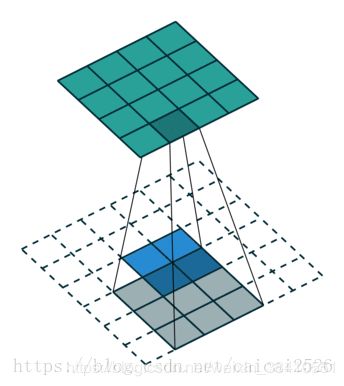
(2)提出了跳跃连接来改善上采样的粗糙程度。
因为如果将全卷积之后的结果直接上采样得到的结果是很粗糙的,所以作者将不同池化层的结果进行上采样之后来优化输出。
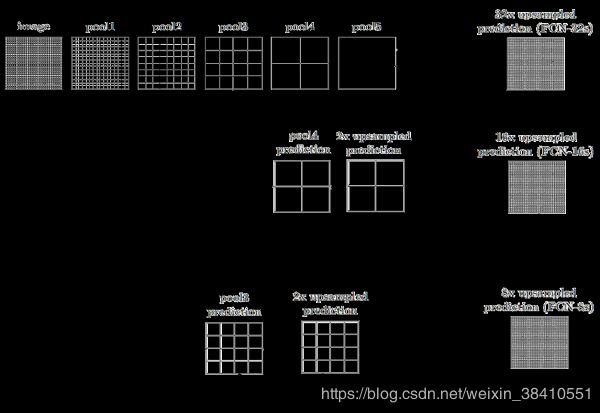
缺点:
FCN不能有效的处理场景之间的关系和全局信息
Segnet网络
论文翻译:https://blog.csdn.net/u014451076/article/details/70741629
https://blog.csdn.net/fate_fjh/article/details/53467948
主要贡献有两点:
(1)**segnet采用的是编码-解码的结构,这样的对称结构有种自编码器的感觉在里面,先编码再解码。**这样的结构主要使用了反卷积和上池化。即:
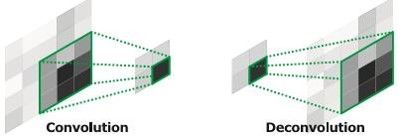
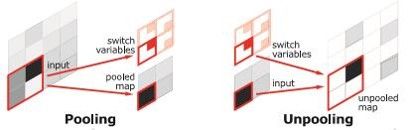
反卷积如上。而上池化的实现主要在于池化时记住输出值的位置,在上池化时再将这个值填回原来的位置,其他位置填0。这样的上采样结构,可以保证对图像边缘信息的正确翻译,而且上采样没有参数,不需要训练,节约了训练时间,减少了内存消耗,速度很快。
(2)空洞卷积
RefineNet网络
RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation 于2016年11月20日提交到Arxiv
https://arxiv.org/abs/1611.06612
带有精心设计解码器模块的编码器-解码器结构(编码器和解码器结构);
所有组件遵循残差连接的设计方式。
使用空洞卷积的方法也存在一定的缺点,它的计算成本比较高,同时由于需处理大量高分辨率特征图谱,会占用大量内存,这个问题阻碍了高分辨率预测的计算研究。
Deeplab v1&v2网络
https://blog.csdn.net/c_row/article/details/52161394
CNN的一个特性是invariance(不变性),这个特性使得它在high-level的计算机视觉任务比如classification中,取得很好的效果。但是在semantic segmentation任务中,这个特性反而是个障碍。毕竟语义分割是像素级别的分类,高度抽象的空间特征对如此low-level并不适用。 所以,要用CNN来做分割,就需要考虑两个问题,一个是feature map的尺寸,以及空间不变性。
金字塔场景解析网络(PSPNet)*
背景:
原有的FCN网络,无法利用全局的场景类别信息,来进行复杂场景每个像素的标签判断,不能有效的处理场景之间的关系和全局信息,导致会出现很多误判。而通过全局的场景类别信息,结合局部的标签信息,可以对像素做出正确的判断,这样的预测更加可靠。
贡献:
1)通过多尺度 Pooling 的方式得到不同 Scale 的 Feature,Concat (全连接)得到判别的多尺度特征;
2)加入额外的深度监督 Loss,我们开发了一种有效的深网优化策略,在基于深度监督损失ResNet上制定有效的优化策略。
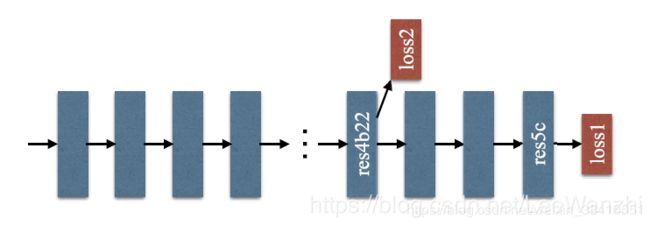
这是专门针对ResNet的。虽然ResNet已经通过残差块来解决梯度消失的问题,但作者认为加一个loss层会使优化问题更简单。于是在如图位置加了一个loss。最后乘以一个权重alpha 与最后一层连接的loss相加,形成最终的loss。
3)提出了一个金字塔场景解析网络,能够将难解析的场景信息特征嵌入基于FCN****预测框架中。
4)构建了一个实用的系统,用于场景解析和语义分割,其中包含了所有关键的实现细节。
5)能够获取全局场景。
特点:
其一是多尺度特征组合。因为在深层网络中,更高层次的特性包含更多的语义含义和较少的位置信息。低层次对应位置信息。结合多尺度特性可以提高性能。
其二是基于结构预测。提倡工作[3]使用条件随机字段(CRF)作为后处理来细化分割结果。通过端到端的建模方法改进的网络。(利用的是相邻像素之间的逻辑关系)
PSPnet网络结构:
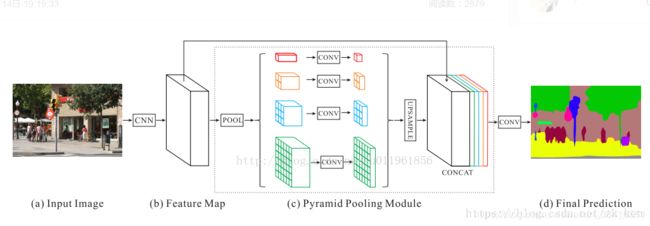
给定一个输入图像(a),我们首先使用CNN获得特征图来得到最后卷积层(b),然后一个金字塔解析模块应用于收获不同次区域表示,其次上采样和连接层以形成最终的特征表示,有局部和全局上下文信息©。最后,将该表示输入到卷积层中,以获得最终的每个像素预测(d)
主体网络由ResNet101构成,使用了残差网络、空洞卷积和降维卷积的方法(先使用11降低维度,然后使用33卷积,再用1*1恢复维度)。网络中一共出现三次特征图缩小,一次使用maxpool,两次使用conv,每次减少二分之一大小,最终得到的特征图是原尺寸的1/8,最后使用双线性插值恢复原尺寸。
**金字塔池模块融合了四个不同金字塔规模的特征。**红色突出显示的最粗级别是全局池,以生成单个bin输出。下面的金字塔级别将feature map分割为不同的子区域,并形成不同位置的集合表示。金字塔池模块中不同级别的输出包含不同大小的feature map。为了保持全局特征的权重,我们用1*1卷积后每个金字塔级别降低维度的上下文表示为1 \ N如果原来级别大小的金字塔是N .然后我们直接upsample低维特征图得到相同的大小特征与原始特征映射通过双线性插值。最后,将不同层次的特性连接成最终的金字塔汇聚全局特性。
采用一个pre-trained网络ResNet [13],并加入dilated network来提取feature map,得到的feature map的尺寸是原始图的1/8(这在Deeplab在解释过)。
采用4层金字塔模型,最后通过卷积后连接起来。
缺点:
主流的场景解析算法基于FCN(全卷积网络),存在的问题是没有利用整体的场景信息。
与其它网络的关系:
基于FCN和Resnet网络优化的。
应用:
(1)图像的输入是固定尺寸,例如:对于cityspace的数据,它的输入尺寸为3 * 713 * 713
(2)cityspace数据的类别为19。
(3)模型中的某些参数是与图像尺寸,图像的类别标签数目一致。
总结:
能够融合合适的全局特征,将局部和全局信息融合到一起。并提出了一个适度监督损失的优化策略,在多个数据集上表现优异。
Deeplab v3网络
Rethinking Atrous Convolution for Semantic Image Segmentation 于2017年6月17日提交到Arxiv:https://arxiv.org/abs/1706.05587
https://blog.csdn.net/zziahgf/article/details/75314719
改进了空间维度上的金字塔空洞池化方法(ASPP),采用全局平均池化;该模块级联了多个空洞卷积结构。与在DeepLab v2网络、空洞卷积中一样,这项研究也用空洞卷积/多空卷积来改善ResNet模型。
这篇论文还提出了三种改善ASPP的方法,涉及了像素级特征的连接、加入1×1的卷积层和三个不同比率下3×3的空洞卷积,还在每个并行卷积层之后加入了批量归一化操作。
级联模块实际上是一个残差网络模块,但其中的空洞卷积层是以不同比率构建的。这个模块与空洞卷积论文中提到的背景模块相似,但直接应用到中间特征图谱中,而不是置信图谱。置信图谱是指其通道数与类别数相同的CNN网络顶层特征图谱。
该论文独立评估了这两个所提出的模型,尝试结合将两者结合起来并没有提高实际性能。两者在验证集上的实际性能相近,带有ASPP结构的模型表现略好一些,且没有加入CRF结构。
这两种模型的性能优于DeepLabv2模型的最优值,文章中还提到性能的提高是由于加入了批量归一化层和使用了更优的方法来编码多尺度背景。
转载链接:
(1)https://blog.csdn.net/caicai2526/article/details/79984950
(2)https://blog.csdn.net/zk_ken/article/details/80481764
(3)https://blog.csdn.net/yxq5997/article/details/53695779
(9)https://blog.csdn.net/qq_20084101/article/details/80432960
(10)https://blog.csdn.net/fendouaini/article/details/82853696
(4)https://blog.csdn.net/py184473894/article/details/84205779
(5)https://blog.csdn.net/linolzhang/article/details/78536191
(6)https://blog.csdn.net/u011974639/article/details/78985130
(7)https://blog.csdn.net/sinat_28731575/article/details/82828021
(8)https://blog.csdn.net/ziyouyi111/article/details/80416935