快速了解Flink——数据架构、执行流程等
一、什么是Flink
Apache Flink官网的描述:
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
翻译成中文就是说:Apache Flink是一个对有界或无界数据流进行有状态计算的分布式处理引擎框架。 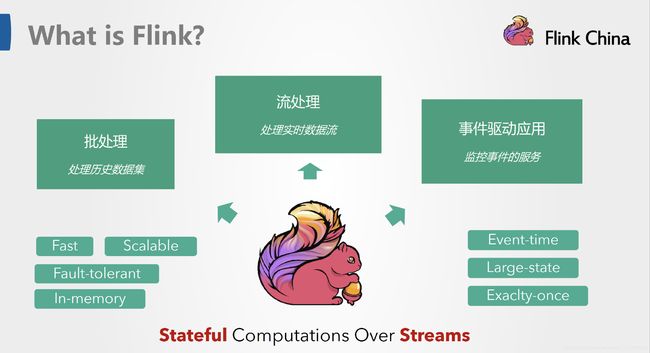

二、Flink架构
1、基本组件栈

从下至上:
- 1>、部署:Flink 支持本地运行、能在独立集群或者在被 YARN 或 Mesos 管理的集群上运行, 也能部署在云上;
- 2>、运行:Flink 的核心是分布式流式数据引擎,意味着数据以一次一个事件的形式被处理;
- 3>、API:DataStream、DataSet、Table、SQL API;
- 4>、扩展库:Flink 还包括用于复杂事件处理,机器学习,图形处理的专用代码库。
2、基本架构
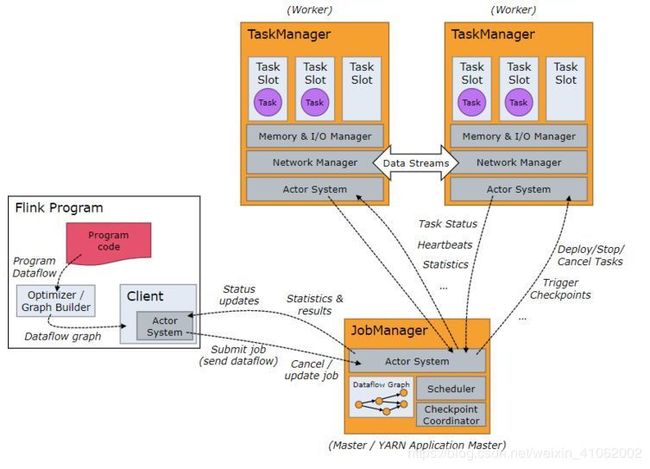
Flink架构也遵循了Master-Slave架构设计原则,主要由两个组件构成:JobManager和TaskManager。JobManager为Master节点,TaskManager为Worker节点(slave).。所有组件之间的通信都是借助于Akka Framework。
- Client:与JobManager构建Akka连接,然后将任务提交到JobManager。通过和JobManager之间进行交互获取任务执行状态。提交方式:客户端提交任务可以采用CLI方式或者通过使用Flink WebUI提交,也可以在应用程序中指定JobManager的RPC网络端口构建ExecutionEnvironment提交Flink应用。
- JobManager:JobManager负责申请资源、协调以及控制整个job的执行过程,具体包括调度任务、处理checkpoint、容错等等。从客户端中接收提交的JobGraph,进行包装转换成ExecutionGraph(physical dataflow graph,并行化),然后根据集群中TaskManager上TaskSlot的使用情况(注册到Master节点上的TaskManager的slot使用情况),资源准备就绪之后就调度任务到TaskManager启动并运行任务。JobManager相当于整个集群的Master节点,且整个集群中有且只有一个活跃的JobManager。JobManager和TaskManager之间通过Actor System进行通信,获取任务执行的情况、维持心跳等工作。同时在任务执行过程中,JobManager会协调TaskManager进行CheckPoints 操作,所有的Checkpoint协调过程都是在FLink JobManager中完成,当任务完成后Flink会将任务执行的信息反馈给客户端,并且释放掉TaskManager中的资源以提供下一次提交任务使用。
- TaskManager:负责具体的任务执行和相应任务在每个节点上的资源申请与管理。TM从JM接收到分配的任务,使用Slot资源启动Task,建立数据接入的网络连接(TM间底层使用Netty进行数据交换),接收数据并开始处理数据。一个TM中Slot之间内存隔离,slots间均分内存,但是共享CPU,所以提高了CPU的使用效率。
三、Flink编程模型
1、Flink根据数据集类型的不同将核心数据处理接口分为两大类:DataStream API与DataSet API。同时Flink将数据处理接口抽象成四层(如下图),用户可以根据需要选择任意一层抽象接口来开发Flink应用。

- SQL API:SQL API是Flink提供给用户完成流处理或批处理的高层抽象接口,通过SQL API可以让数据分析人员与开发人员跟快速上手,帮助其更专注于业务本身而不是受限于复杂的编程接口。这一层抽象在语法与表达能力上与 Table API 类似,但是是以 SQL查询表达式的形式表现程序。SQL 抽象与 Table API 交互密切,同时 SQL 查询可以直接在 Table API 定义的表上执行;
- Table API:Table API将内存中的DataStream和DataSet数据集在原有基础之上增加了Schema(描述数据属性和类型的元数据),将数据类型统一抽象成表结构(可以理解为MySQL中使用DML语言将数据对象描述为表结构)。并提供相应的接口对数据集进行操作。 例如Select、Join、GroupByKey、Aggregate 等操作符,提供给用户一种更加友好的处理数据集的方式。同时Table API在转换为DataStream和DataSet数据集的过程中用到了大量的优化规则对处理逻辑进行优化。Table API 中的Table与 DataStream/DataSet 之间可以相互转化,也允许程序将 Table API 与 DataStream 以及 DataSet 混合使用;
- DataStream / DataSet API: 是 Flink 提供的核心 API ,主要面向具有开发经验的用户。DataSet 处理有界的数据集,DataStream 处理有界或者无界的数据。DataStream / DataSet API同时提供了各种数据处理接口,例如map / flatmap / window / keyby / sum / max / min / avg / join 等;
- Stateful Stream Process API:Flink处理Stateful Stream最底层的接口。它通过处理函数(Process Function)嵌入到 DataStream API 的算子当中。用户可以对来自一个或多个流数据的事件自定义处理过程,并可以操作时间、状态等底层数据。除此之外,用户可以注册事件时间和处理事件回调,从而使程序可以实现非常复杂的流式计算逻辑。一般企业使用Flink进行二次开发或者深度封装的时候会用到这层接口。
2、Flink应用程序结构与数据流结构

Flink 应用程序结构就是如上图所示:
- 1、Source: 数据源,Flink 在流处理和批处理上的 source 大概有 4 类:基于本地集合的 source、基于文件的 source、基于网络套接字的 source、自定义的 source。自定义的 source 常见的有 Apache kafka、Amazon Kinesis Streams、RabbitMQ、Twitter Streaming API、Apache NiFi 等,当然你也可以定义自己的 source;
- 2、Transformation:数据转换的各种操作,有 Map / FlatMap / Filter / KeyBy / Reduce / Fold / Aggregations / Window / WindowAll / Union / Window join / Split / Select / Project 等,操作很多,可以将数据转换计算成你想要的数据;
- 3、Sink:接收器,Flink 将转换计算后的数据发送的目的地 ,Flink 常见的 Sink 大概有如下几类:写入文件、打印出来(print())、写入 socket 、自定义的 sink 。自定义的 sink 常见的有 Apache kafka、RabbitMQ、MySQL、ElasticSearch、Apache Cassandra、Hadoop FileSystem 等,同理你也可以定义自己的 sink。
- 注意:一个Flink程序是以创建一个执行环境StreamExecutionEnvironment的对象开始的,它是Flink的上下文,负责flink的默认配置,当前运行环境,例如取cpu核数为默认并行度,flink的启动方法execute等。同时,运行环境负责保存我们对流处理的操作,Source->Operator->Sink整个阶段和每个阶段的返回值类型,上下游关系等。
四、Flink执行流程
1、编写Flink程序:当我们要实现一个Flink Job时,需要先把我们的业务抽象成分布式计算模型,然后使用Stream API按照上述的编程结构进行编程实现:
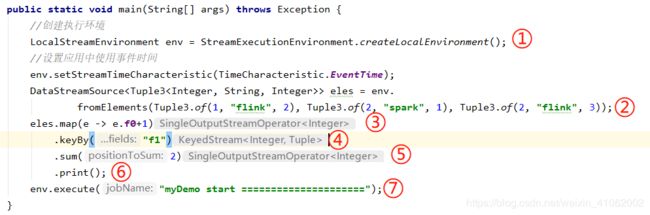
2、编写好的Flink程序打包提交到客户端执行,在客户端顺序执行我们编写的这段程序时:
- ①中会产生一个执行环境对象,这个对象非常重要,接下来的每个操作都是围绕它来进行的;
- ②中我们添加了一个本地数据源,它是Flink流计算的开始。内部执行过程是: 1>、使用TypeExtractor提取输入数据类型信息TypeInformation; 2>、然后根据typeInfo、输入数据来生成SourceFunction(用户定义的数据输入方法,比如Apache kafka、RabbitMQ 等); 3>、根据SourceFunction提取输出数据类型信息,并用它来初始化SourceOperator; 4>、最后根据function、inTypeInfo/outTypeInfo、并行度、SourceOperator、当前执行环境初始化DataStreamSource, 过程中会产生SourceTransformation(Transformation)对象,每个算子都会产生一个transformation对象,该对象就 是描述算子的,他描述了算子的输入、输出对象(类型、序列化反序列化方法)以及该算子的功能等信息,逻辑上来 说它代表了一个算子; 5>、最后返回初始化的DataStreamSource;
- ③的操作跟②的差不多,但不同的是③产生的transformation会被加入到StreamExecutionEnvironment的translations集合中,同时上游算子的tansformation会存入到③的transformation的input(一个transformation对象)中,这样只需要获得所有的Thransformation对象,就可以根据input知道算子之间的上下游关系了;


- ④~⑥的操作跟②③的是一样的。
- 当客户端执行到⑦时,会将job提交到JobManager;
-
结:从Source到Sink中间的处理阶段,所用到的这些算子或者说所有的算子可以分为两种类型:处理数据的算子、不处理数据的算子。这种分法不是官方的。为什么这么分,因为例如flatMap中间是有数据处理逻辑的,将一行数据扁平化为多行,但是像keyBy,equalTo,partition,rebanlance等方法,其实是没有对数据进行修改的,起的是一个按字段匹配,分发的作用,这些算子的transformation不会被放入到StreamExecutionEnvironment的transformations集合中,而是作为输入存入下游transformation的input对象中。所以为啥不处理数据的算子不存入transformations集合中,因为它的下一步一定是处理数据的算子,它可以通过input对象存在于transformation当中(如何判断一个算子是否是处理数据的算子,只要看该算子底层实现中是否执行DataStream的doTransform()方法即可)。
| 概念 | 说明 |
|---|---|
| TypeExtractor | DataStream应用所处理的事件会以数据对象的形式存在,在Flink内部出于网络传输、读写状态、检查点和保存点的目的,需要对这些输入输出对象进行序列化或反序列化。为了提高上述过程的效率,Flink对这些数据进行重新包装,使用TypeInformation类型信息来表示这些数据的类型。而TypeExtractor是flink提供的一个类型提取系统,它可以通过函数的输入输出类型自动获取他们的类型信息,继而得到他们相应的序列化器与反序列化器,但是Flink支持的Java相关的数据类型只有基本类型,数组类型,常用类型,POJO类,Tuple类等,用户自定义的类很多情况下Flink无法自动识别,即提取器失效。 |
| Function | 处理函数,流数据的基本处理单元,数据处理逻辑封装在function中,例如:SourceFunction封装Source中用来获取数据的代码,MapFunction封装了处理Map类型数据逻辑的代码。 |
| Operator | 算子,将一个Function封装为不同类型的Operator,例如:单输出Operator OneInputStreamOperator ,双输出Operator TwoInputStreamOperator等,是function的不同输出类型的处理逻辑封装。 |
| Transformation | 转换,将Operator封装为Transformation。用于形容一组类型的输入,经过Transformation以后,出来一组不同类型的输出。是Operator的更高级封装,也可以分为单输出,双输出,Source,Sink等多种Transformation。(transformation<-Operator<-function,装饰者模式) |
| DataStream | DataStream代表一个数据流,里面封装transformation,表示流的处理逻辑。还有若干基于该流往下游的方法。例如map,flatmap。 |
| SourceFunction | Function的一种封装,负责Source处理逻辑的Function,例如FromElementsFunction,看了一下,SourceFunction的实现,flink源码中就有22种 |
| SourceOperator | Operator的一种封装,封装SourceFunction的Operator,可以封装不同的SourceFunction |
| SourceTransformation | Transformation的一种实现,负责封装不同类别的SourceOperator |
| DataStreamSource | DataStream的一种实现,表示数据流计算的起点,里面封装了SourceTransformation |
d
3、DataFlowGraph转换(四层图结构)

-
转换过程说明:
1、转换过程: StreamExecutionEnvironment中存放的transformations->StreamGraph->JobGraph->ExecutionGraph->物理执行图;
2、transformations->StreamGraph->JobGraph在客户端完成,然后提交JobGraph到JobManager;
3、JobManager的主节点JobMaster,将JobGraph转化为ExecutionGraph,然后发送到不同的taskManager,在taskManager上实际的执行过程就是物理执行图。 - 从transformations集合到StreamGraph:
env.execute("myDemo start =====================");
该段代码执行时做了两件事:把Transformation集合转换成StreamGraph、把StreamGraph按照一定规则切分成JobGraph——逻辑上的DAG。
要介绍StreamGraph首先我们需要先了解两个概念:StreamNode——DAG图的顶点、StreamEdge——DAG图的边(带箭头的直线)。
public class StreamGraph implements Pipeline {
//记录jobName,ExecutionConfig、CheckpointConfig、SavepointRestoreSettings、scheduleMode、TimeCharacteristic 等配置
private boolean chaining;
private Collection> userArtifacts;
/**
* If there are some stream edges that can not be chained and the shuffle mode of edge is not
* specified, translate these edges into {@code BLOCKING} result partition type.
*/
private boolean blockingConnectionsBetweenChains;
/** Flag to indicate whether to put all vertices into the same slot sharing group by default. */
private boolean allVerticesInSameSlotSharingGroupByDefault = true;
//记录StreamNode节点,使用id作为key
private Map streamNodes;
//记录Source
private Set sources;
//记录Sink
private Set sinks;
//记录Select 节点,该节点是虚拟的,需要处理,但是不放入Streamgraph中。后面会被优化掉
private Map>> virtualSelectNodes;
//记录 side output 节点,该节点是虚拟的,需要处理,但是不放入Streamgraph中。后面会被优化掉
private Map> virtualSideOutputNodes;
//记录 partition 节点,该节点是虚拟的,需要处理,但是不放入Streamgraph中。后面会被优化掉
private Map, ShuffleMode>> virtualPartitionNodes;
protected Map vertexIDtoBrokerID;
protected Map vertexIDtoLoopTimeout;
private StateBackend stateBackend;
private Set> iterationSourceSinkPairs; Flink Client会遍历StreamExecutionEnvironment中的transformations集合,按照用户定义构建上面的DAG图。StreamGraph中,比较重要的是streamNode(transformation对应的节点),source(数据源),sinks(输出),然后几个虚拟的节点(sideout、select、partition分发等,都会作为虚拟节点生成,最后被优化掉)。StreamGraph没有记录边,只记录了节点,边存在于节点中。
StreamNode:里面存储了用户的udf(user-defined-function)对象、statePartitioner分区器、输入输出的序列化方法、所有输入和输出的StreamEdge对象、该StreamNode对应的transformationID等信息。
StreamEdge:存储了上游的节点id、下游节点id还有自身的一个edgeId、outputTag(SideOutputTransformation当中用户指定的OutputTag),outputPartitioner(默认ForwardPartitioner,可由PartitionTransformation指定)。
-
从StreamGraph到JobGraph
上文提到过,StreamGraph会被切分成JobGraph,这里来介绍一下:首先,StreamGraph和JobGraph有什么区别,StreamGraph是逻辑上的DAG图,不需要关心jobManager怎样去调度每个Operator的调度和执行;JobGraph是对StreamGraph进行切分,因为有些节点可以打包放在一起被JobManage安排调度(为何被打包放在一起点这里),因此JobGraph的DAG每一个顶点就是JobManger的一个调度单位(任务task,假如该Task并行度为3,则,该Task有3个SubTask)。假如StreamGraph切分如下图:

那么JobGraph的DAG如下图,绿色实心的两个顶点是上图打包在一起的StreamNode:

至此Flink客户端的工作基本完成,Flink客户端通过Akka把生成的JobGraph提交给JobManager,JobManager开始根据JobGraph部署工作,接下来详细介绍下该过程。
-
从JobGraph到ExecutionGraph
上文提到,在客户端完成JobGraph的构建之后,客户端通过akka把它提交给JobManager。JobManager收到客户端提交的JobGraph之后,会构建ExecutionGraph;JobGraph并行化之后就是ExecutionGraph,拓扑结构其实是一样的。其中按照JobVertex将顶点分装成ExecutionJobVertex,按照JobEdge将边封装成ExecutionEdge,还构建IntermediateResult(中间数据)用来描述节点之间的Data shuffle 。如下图:

上游节点会把产生的数据写到IntermediateReslut(下文称:中间数据集)中,是中间数据集的生产者;下游节点会处理中间数据集产生的数据,是中间数据集的消费者,具体的可能有下面两种情况:
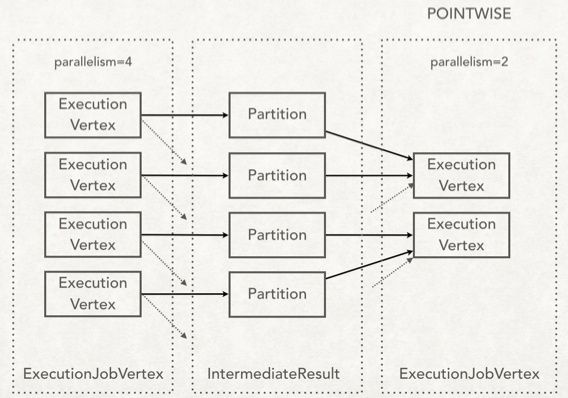

ExecutionJobGraph有下面几个特点:
- Partition的数量和上游节点的并行度保持一致。
- 下游节点在和上游节点建立连接时,只有POINTWISE和ALL_TO_ALL两种模式,事实上只有RescalePartitioner和ForwardPartitioner是POINTWISE模式,其他的都是ALL_TO_ALL。默认情况下如果不指定partitioner,如果上游节点和下游节点并行度一样为ForwardPartitioner,否则为RebalancePartioner ,前者POINTWISE,后者ALL_TO_ALL。
本内容是通读书籍和网上各个渠道总结再加上自己的理解而来,可能会有一些我没注意的纰漏,各位看官老爷如有疑问或指正,在下在此感激不尽。