C++ Concurrency Notes
C++ Concurrency
1.Thread management
process
- A process is an instance of a computer program that is being executed.
- thread is component of a process. every process have at least one thread called main thread which is the entry point for the program.
context
- collection of data about process which allows processor to suspend or hold the execution of a process and restart the execution later.
thread
- thread of execution is the smallest sequence of programmed instructions that can be managed independently by a scheduler.
- has its own registers
threads(of the same process) run in a shared memory space, while processes run in separate memory spaces.
task level and data level parallelism
lauch a thread
#include
#include
// 1. normal function
void foo(){
printf("Hello from foo \n");
}
class callable_class {
public:
// 2. function call operator
void operator()(){
printf("Hello from class with function call operator \n");
}
}
/*The main function act as the entry point for our program. Every program or
process in C++ is going to have this main function and the thread which runs
the main function we refer to as the main thread.*/
void run(){
std::thread thread1(foo);
callable_class obj;
std::thread thread2(obj);
// 3.lambda function
std::thread thread3([]()->void{
printf("Hellp from lambda \n");
});
/*Join function will force main thread to wait until
the thread that it call upon finish its execution.*/
thread1.join();
thread2.join();
thread3.join();
printf("Hello from main \n");
}
int main(){
run();
return 0;
}
To launch a thread, we have to provide a callable object to thread class constructor. Callable objects are normal function, lambda expressions and class with function call operator.
Joinability of threads
- properly constructed thread object represent an active thread of execution in hardware level. Such a thread object is joinable.
- for any joinable thread, we must call either join or detach function.
- after we made such a call that thread object vecome non joinable.
- if you forgot to join or detach on joinable thread, then at the time of destructor call to that thread object, std::terminate function will be called.
- if any program have std::terminate call we refer such program as unsafe program.
// check if the thread is joinable
std::thread thread1(func);
thread1.joinable();
thread1.join();To construct a thread properly we have to pass callable object as the argument to the thread class constructor and if that callable object takes parameters you have to pass those parameters properly as well.
Join and detach
join
- join() introduce a synchronize point between launched thread and thread that it launched from.
- it blocks the execution of the thread that calls join function, until the launched thread's execution finished.
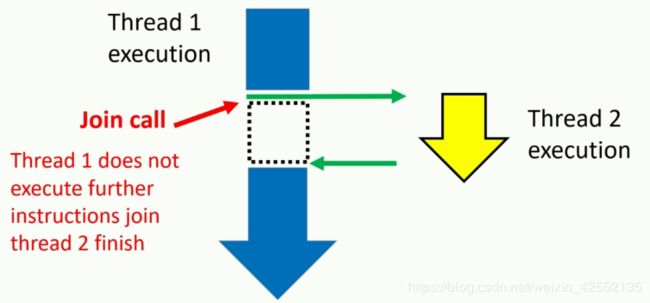
launch thread2 from thread 1 in the middle of thread1's execution.
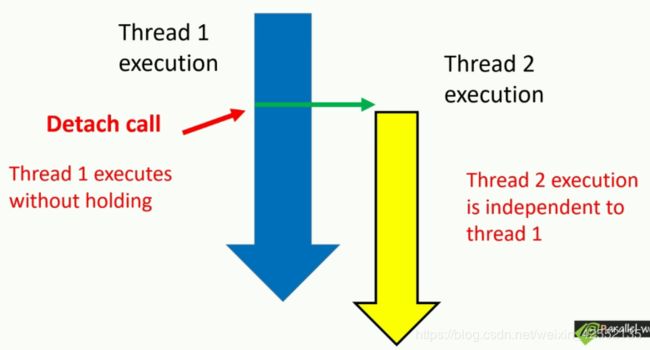
detach
- separates the launched thread from the thread object which it launched from, allowing exevution to continue independently.
- any allocated resources will be freed once the thread exits.
Better Join mechanism
class thread_guard{
private:
std::thread & t;
public:
explicit thread_guard(std::thread & _t): t(_t){}
// avoid unsafe program
~thread_guard(){
if(t.joinable()){
t.join();
}
}
// we don't mean to copy thread_guard type object from one to another.
// deleted the copy constructor and copy assignment operator
thread_guard(thread_guard & const) = delete;
thread_guard & operator= (thread_guard & const) = delete;
};
void foo(){
}
void other_operations(){
std::cout << "This is other operation /n";
// throw an exception and main thread will go out of scope.
// objects which are created inside this function will be destructed.
throw std::runtime_error("this is a runtime error");
}
void run(){
std::thread foo_thread(foo);
thread_guard tg(foo_thread);
try{
other_operations();
} catch (){
}
}RAII
resource acquisition is initialization (Constructor acquire resources, destructor releases resources).
Pass parameters to a thread
thread class has 4 constructors
- default
- initialization
- copy(deleted)
- move
use initialization constructor. can pass arguments after the function name to this constructor.
template
explicit thread (Fn&& fn, Args&&... args); to pass the variable by reference, use std::ref(var). this is because thread object itself take its argument by value;
problem may occur when detaching threads after pass reference to a variable to that thread as detach thread can outlive the lifetime of the objects in the thread that it detach from.
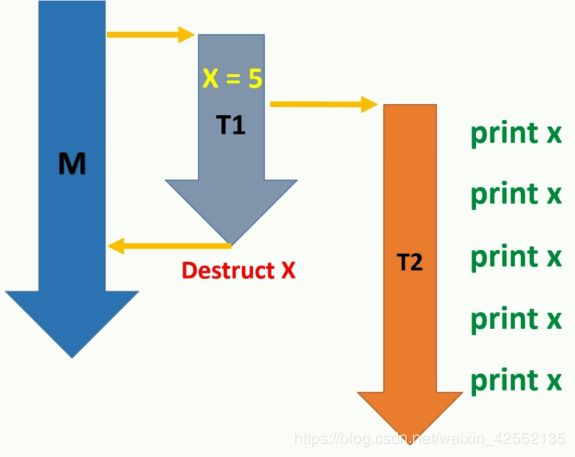
Transfer ownership of a thread
use move constructor, this is because thread object are not copy constructable nor copy assignable.
std::thread thread_1(foo);
std::thread thread_2 = std::move(thread_1);
// implicit move call, RHS is a temp object
thread_1 = std::thread(bar);But, cannot transfer ownership when left side variable of this operation owning a thread.
Useful functions
get_id()
- return unique thread id for each active thread of execution
- return 0 for all non active threads
sleep_for()
- blocks the execution of the current thread for at least the specified sleep_duration
- this function may block for longer than sleep_duration due to scheduling or resource contention delays
std::this_thread::yield()
- yield will give up the current time slice and re-insert the thread into the scheduling queue. the amount of time that expires until the thread is executed again is usually entirely dependent upon the scheduler.
std::thread::hardware_concurrency()
- return the number of concurrent threads supported by the implementation. the value should be considered only a hint.
- if use more threads than avaliable number of cores, then cores have to perform task switching which takes some overhead. which may lead the parallel implementation of particular algorithm to lag behind its sequential counterpart.
Accumulate
T accumulate(InputIt first, InputIt last, T init);
T accumulate(InputIt first, InputIt last, T init, BinaryOperation op)Parallel accumulate

#include
#define MIN_BLOCK_SIZE 1000
template
void accumulate(iterator start, iterator end, T &ref){
ref = std::accumulate(start,end,0);
}
template
T parallel_accumulate(iterator start, iterator end, T &ref){
int input_size = std::distance(start,end);
int allowed_threads_by_elements = (input_size) / MIN_BLOCK_SIZE;
int allowed_threads_by_hardware = std::thread::hardware_concurrency();
int num_threads = std::min(allowed_threads_by_elements, allowed_threads_by_hardware);
int block_size = (input_size + 1)/num_threads;
std::vector results(num_threads);
std::vector threads(num_threads-1);
iterator last;
for(int i = 0; i < num_threads-1;i++){
last = start;
std::advance(last, block_size);
threads[i] = std::thread(accumulate,start,last, std::ref(results[i]));
start = last;
}
results[num_threads-1] = std::accumulate(start,end,0);
std::for_each(threads.begin(),threads.end(),std::mem_fn(&std::thread::join));
return std::accumulate(results.begin(),results.end(),ref);
} 2.Thread safe access to shared data and locking mechanisms
Invariants
- statements that are always true for particular data structure
- For a list data structure, size variable contains number of elements in the list
- In the doubly linked list data structure, if you follow a next pointer from node A to node B, previous pointer in B should point to node A
- most common problem of the multithreaded applications is, broken invariants while updating.
Race condition
- in concurrency race condition is anything where outcome is depend on the relative ordering of execution of operations on two or more threads.
- many of the times this ordering does not matter.
- but if this race condition result in broken data structures, then we refer such race conditions as problematic race conditions.
Mutex
the mutex class is a synchronization primitive that can be used to protect shared data from being simultaneous access by my mutiple thread. simply, the mutex provide mutually exclusive access of shared data for multiple threads.
Note about list
- list is not built in thread safe data structure. in fact most, if not all data structures in the STL are not thread safe at all.
- pushing a element to list is not a atomic operation.
- creation of new node.
- setting that nodes next to current head node.
- changing head pointer to points to new node.
3 functions
- lock
- try_lock
- unlock
#include
#include
#include
#include
std::list my_list;
std::mutex m;
// use same mutex for both of the functions, the access to both of these functions are mutually exclusive.
void add_to_list(int const &x){
m.lock();
my_list.push_front(x);
m.unlock();
}
void size(){
m.lock();
int size = my_list.size();
m.unlock();
std::cout << "size of the list is :" << size << std::endl;
}
void run_code(){
std::thread thread_1(add_to_list, 4);
std::thread thread_2(add_to_list, 11);
thread_1.join();
thread_2.join();
}
Lock_guard
- the class lock_guard is a mutex wrapper that provides a convenient RAII-style mechanism for owning a mutex for the duration of a scoped block.
- when a lock_guard object is created, it attempts to take ownership of the mutex it is given. when control leaves the scope in which the lock_guard object was created, the lock_guard is destructed and the mutex is released.
std::mutex m;
std::lock_guard lg(m); When using mutex, it can be unsafe when
- returning pointer or reference to the data protected.
- passing code to the protected data structure which you don't have control with.
Dead locks
neither of the threads allowed to proceed because they're waiting for others to finish.
the cause of the deadlock is
- the order that we aquire the mutexes
- while joining
Unique locks
- is a general-purpose mutex ownership wrapper
- it can be used to manage mutexes like lock_guard objects.
- unlike lock_guard object it does not have to acquire the lock for the associated mutex in the construction
- unique_locks are neither copy constructible nor copy assignable
- but they are move constructible and move assignable
The difference unique_locks and lock_guard is that
- you can lock and unlock a
std::unique_lock. std::lock_guardwill be locked only once on construction and unlocked on destruction.
3. Communication between thread using condition variables and futures
condition variables
- condition variable is basic mechanism for waiting for an event to be triggered by another thread.
- condition variable is associated with some event, and one or more threads can wait for that event to be happen. If some thread has determined that the event is satisfied it can then notify one or more of the threads waiting for that condition variable, and wake them up and allow them to continue processing.
#include
#include
#include
#include
#include
#include
bool have_i_arrived = false;
int total_distance = 10;
int distance_covered = 0;
std::condition_variable cv;
std::mutex m;
void keep_moving(){
while(true){
std::this_thread::sleep_for(std::chrono::milliseconds(1000));
distance_covered++;
//notify the waiting threads if the event occurs
if(distance_covered == total_distance)
//wake up the condition variable
cv.notify_one();
}
}
void ask_driver_to_wake_u_up_at_right_time(){
std::unique_lock ul(m);
// conditional check after wake up
// reach the wait statement in the first time, it will get ownership of the mutex associate with the unique lock
// check if the condition in lambda function is true
// if not true, unlock the mutex and make passenger sleep
cv.wait(ul, []{return distance_covered == total_distance;});
}
void run_code(){
std::thread driver_thread(keep_moving);
std::thread passenger_thread(ask_driver_to_wake_u_up_at_right_time);
passenger_thread.join();
driver_thread.join();
} futures and async tasks
- A synchronous operation blocks a process till the operation completes. An asynchronous operation is non-blocking and only initiates the operation. The caller could discover completion by some other mechanism.
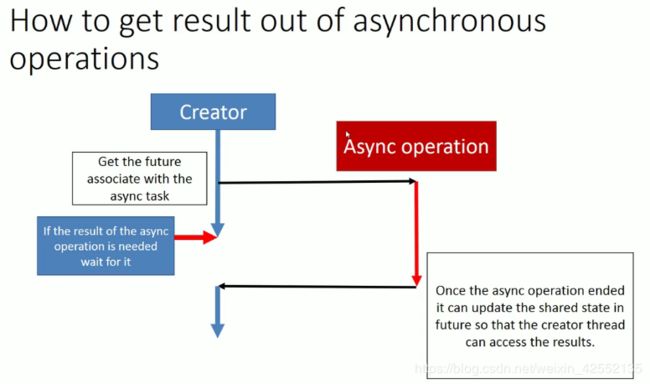
- First, creator of the asynchronous task have to obtain the future associate with asynchronous task.
- When creator of async task need the result of that async task it called get() method on future.
- get() method may block if the asynchronous operation has not yet complete its execution.
- when the asynchronous operation is ready to send a result to the creator, it can do so by modifying shared state that is linked to the creator's std::future.
asynchronous operation in c++
In c++ asynchronous operation can be created via
std::async
async(std::launch policy, Function&& f, Args&&... args);
// launch policy has
std::launch::async // run function in a separate thread
std::launch::deferred // task run in creator thread in the future get called
// can do, let compiler decide
std::launch::async | std::launch::deferred
#include
int func(){
}
std::future the_answer_future = std::async(func);
the_answer_future.get(); parallel accumulate with async task
template
int parallel_accumulate(iterator begin, iterator end){
long length = std::distance(begin,end);
if(length <= MIN_ELEMENT_COUNT){
std::cout << std::this_thread::get_id() << std::endl;
return std::accumulate(begin, end, 0);
}
iterator mid = begin;
std::advance(mid, (length+1)/2);
//recursive all to parallel_accumulate
std::future f1 = std::async(std::launch::deferred | std::launch::async, parallel_accumulate, mid,end);
auto sum = parallel_accumulate(begin,mid);
return sum + f1.get();
} package_task
- the class template std::packaged_task wraps any Callable target so that it can be invoked asynchronously.
- it's return value or exception thrown, is stored in a shared state which can be accessed through std::future objects.
std::packaged_task task(callable object)
void task_thread(){
std::packaged_task task_1(add);
std::future future_1 = task_1.get_future();
std::thread thread_1(std::move(task_1),5,6);
thread_1.detach();
std::cout << "task thread - " << future_1.get() << "\n";
}
int add(int x,int y); Promises
- each std::promise object is paired with a std::future object
- A thread with access to the std::future object can wait for the result to be set, while another thread that has access to the corresponding std::promise object can call set_value() to store the value and make the future ready.
void print_int(std::future &fut){
std::cout << "waiting for value from print thread \n";
std::cout << "value: " << fut.get() << "\n";
}
void run_code(){
std::promise prom;
std::future fut = prom.get_future();
std::thread print_thread(print_int, std::ref(fut));
std::this_thread::sleep_for(std::chrono::milliseconds(5000));
std::cout << "setting the value in main thread \n";
prom.set_value(10);
print_thread.join();
}
// future has to wait for promise to set the value.
exception handling with promises
Now think of a scenario where one thread is waiting for a future and the other thread sets its value. So if the exception thrown in the other thread the ideal scenario would be to propagate that exception to the waiting thread so it can read through the exception.
use promise.set_exception()
Shared_futures
more than one thread wait for the same future object.
future will go invalid after the future.get().
3. Design for concurrency
- invariants were upheld at all times
- avoid race conditions inherit from interface
- handling exception scenarios
- avoiding deadlocks at all cost
4. C++ memory model and atomic operations
atomic operation
- Atomic operation: an individible operation. We cannot observe such an operation half-done from any thread in the system.
- if all the opeartion on particular type is atomic then we refer such types as atomic types.
#include
std::atomic_int x;
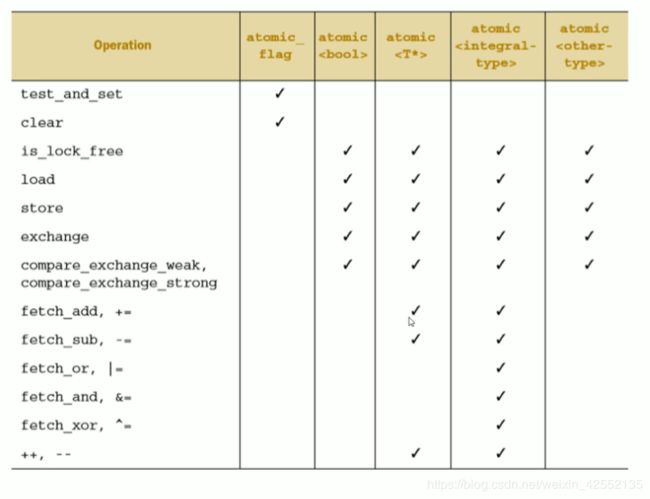
std::atomic y; Atomic_flag
- basic and intended as basic building blocks only.
- atomic flag should initialized with ATOMIC_FLAG_INIT
- only two functions clear() and test_and_set()
- no is_lock_free function: atomic_flag should be implemented without internal locks
atomic
atomic<*> (all atomic type)
- neither copy assignable nor copy constructible
- but can assign non atomic booleans and can be construct using non atomic booleans.
functions on atomic bool
- is_lock_free
- store
- load
- exchange
- replace the stored value with new one and atomically retrieve the original one
- compare_exchange_weak
- bool = X.compare_exchange_weak(T& expected, T desired)
- Compares the value of the atomic variable with supplied expected value and stores the supplied desired value if they are equal. if they are not equal the expected value is updated with the actual value of the atomic variable. this will return true if store is performed false otherwise.
- compare_exchange_strong
Atomic pointers
- atomic
- does not mean object pointed to is atomic
- but pointer itself is atomic
- neither copy constructible nor copy assignable
- but can be construct and assign using non atomic value
functions addition to the above 6
- fetch_add, +=
- fetch_sub, -=
- ++
- --
Important relationships related to atomic operations between threads
- happen-before
- inter-thread-happen-before
- synchronized-with
- carries-a-dependency-to
- apply within a thread
- if result of an operation A is used as operand for operation B, then A carries-a-dependency-to B.
- dependency-ordered-before
Memory ordering
- memory_order_deq_cst
- implies that the behavior of the program is consistent with a simple sequential view of the world.
- memory_order_relaxed
- opposite to the memory_order_seq_cst
- view of the threads does not need to consistent to each other
- no restriction on instruction re-ordering
- memory_order_aquire
- memory_order_release
- atomic store operation tagged with memory_order_release will have synchronized with relationship with atomic load operation tagged with memory_order_acquire
- memory_order_acq_rel
- memory_order_consume
- introduce synchronization(release-consume pair), but limited to direct data dependency (not the thread operation before the memory_order_release line)
By using this memory ordering options with the atomic operator, we can create synchronization point in the code.
Category of operations
- store
- memory_order_relaxed, memory_order_release, memory_order_seq_cst
- load
- memory_order_relaxed, memory_order_consume, memory_order_acquire, memory_order_seq_cst
- Read-modify-write
- memory_order_relaxed, memory_order_consume, memory_order_acquire, memory_order_release, memory_order_rel_acq, memory_order_seq_cst
transitice synchronization
with this property we can synchronize two threads without having any direct release and aquire mechanism between them.
Release sequence
after a release operation A is performed on an atomic object M, the longest continuous subsequence of the modification on M that consists of
- writes performed by the same thread that performed A
- Atomic read-modify-write operations made to M by any thread
is known as release sequence headed by A.
Provide rules to logically deducted synchronization.
- If the release sequence is properly tagged with memory ordering options
- and if each operation reads the values written from the previous operation
then the initial store operation and final load operation will be synchronized.
6. Lock free data structures and algorithms
blocking vs non-blocking
algorithms and data structures that use mutexes, condition variables and futures to synchronize the data are called blocking data structures and algorithms.
lock free vs wait free
- with lock free data structures some thread makes progress with every step.
- with wait free data structures every thread can make progess regardless of what other threads are doing.
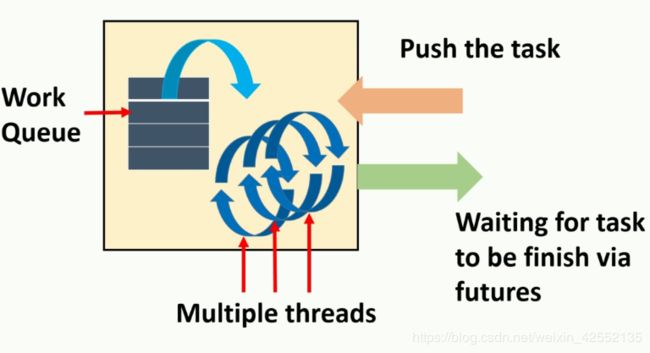
7. Thread Pools
On most systems, it is impractical to have separate thread for every task that can potentially be done with other tasks, but you would still like to take advantage of the available concurrency where possible. A thread pool allows you to accomplish this.