神经网络简介 & 利用minist数据集实现手写数字识别和识别精度计算
文章目录
- 一.引子
- 二. 神经网络(三层简单实现)
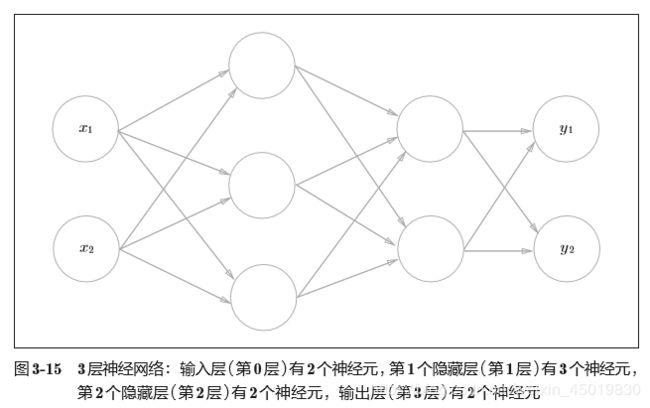
- 2.1 总图
- 2.2输入层到第一层信号传递:
- 2.3第一层到第二层的信号传递:
- 2.4 第二层到输出的信号传递:
- 2.5 总结(代码整理 最终实现)
- 2.6 输出层设计:恒等函数&softmax函数
- 三. 手写数字识别
- 3.1 基本思想:
- 3.2 MNIST数据集:
- 3.3 神经网络的推理处理
- 3.4 批处理
本博客借鉴了《深度学习入门:基于python的理论与实现》的第三章:神经网络
一.引子
博客主要介绍神经网络的前向传播。本章介绍的神经网络和上一章的感知 机在信号的按层传递这一点上是相同的,但是,向下一个神经元发送信号时, 改变信号的激活函数有很大差异。神经网络中使用的是平滑变化的sigmoid 函数,而感知机中使用的是信号急剧变化的阶跃函数。这个差异对于神经网 络的学习非常重要
。同时注意神经网络中激活函数必须非线性,否则多层网络无意义了。
二. 神经网络(三层简单实现)
2.1 总图
2.2输入层到第一层信号传递:
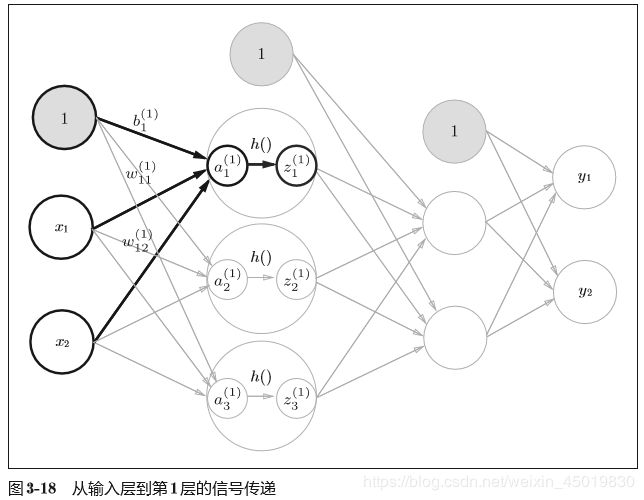
X = np.array([1.0, 0.5]) #输入
W1 = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]]) #权重
B1 = np.array([0.1, 0.2, 0.3])#偏置
print(W1.shape) # (2, 3)
print(X.shape) # (2,)
print(B1.shape) # (3,)
A1 = np.dot(X, W1) + B1 #这个A1的结果还没有经过激活函数的运算
Z1 = sigmoid(A1) #激活后 上图中h()表示激活函数
2.3第一层到第二层的信号传递:
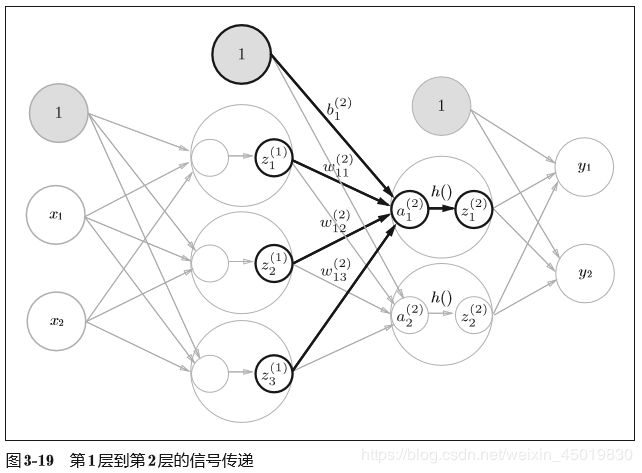
W2 = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]]) #权重
B2 = np.array([0.1, 0.2])#偏置
print(Z1.shape) # (3,)
print(W2.shape) # (3, 2)
print(B2.shape) # (2,)
A2 = np.dot(Z1, W2) + B2 #z1是当前的输入,是0~1层传递的输出
Z2 = sigmoid(A2)#激活后
2.4 第二层到输出的信号传递:
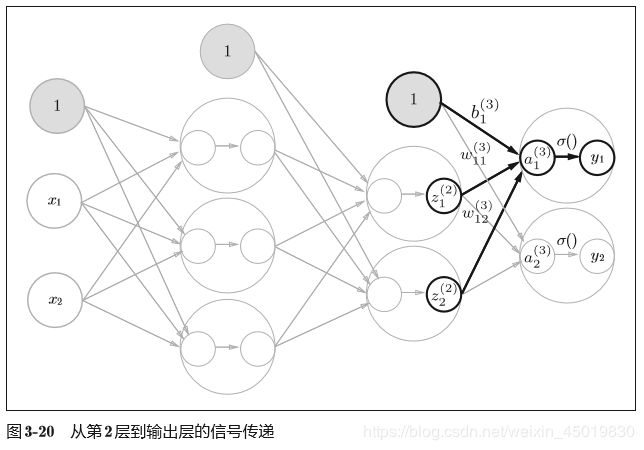
这里我们定义了identity_function()函数(也称为“恒等函数”),并将 其作为输出层的激活函数。恒等函数会将输入按原样输出,因此,这个例子 中没有必要特意定义identity_function()。这里这样实现只是为了和之前的 流程保持统一。另外,图3-20中,输出层的激活函数用σ()表示,不同于隐 藏层的激活函数h()(σ读作sigma)。另外,图3-20中,输出层的激活函数用σ()表示,不同于隐 藏层的激活函数h()
def identity_function(x):
return x
W3 = np.array([[0.1, 0.3], [0.2, 0.4]])
B3 = np.array([0.1, 0.2])
A3 = np.dot(Z2, W3) + B3
Y = identity_function(A3) # 或者Y = A3
2.5 总结(代码整理 最终实现)
这里输出层激活函数设置成了恒等函数,中间层激活函数为sigmoid函数
def init_network(): #数据初始化 使用字典来实现
network = {} #字典初始化用{}
network['W1'] = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]])
network['b1'] = np.array([0.1, 0.2, 0.3])
network['W2'] = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]])
network['b2'] = np.array([0.1, 0.2])
network['W3'] = np.array([[0.1, 0.3], [0.2, 0.4]])
network['b3'] = np.array([0.1, 0.2])
return network
def forward(network, x): #计算过程
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = identity_function(a3)
return y
network = init_network() #该函数返回值为一个字典
x = np.array([1.0, 0.5])
y = forward(network, x)
print(y) # [ 0.31682708 0.69627909]
2.6 输出层设计:恒等函数&softmax函数
1)神经网络可以用在分类问题和回归问题上
2)一般而言,回归问题用恒等函数(。比如,根据一个人的图像预测这个人的体重的问题就 是回归问题),分类问题用softmax函数
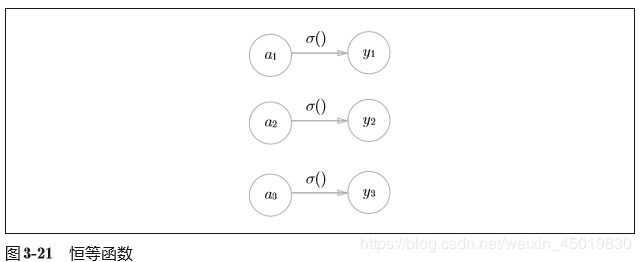
恒等函数:
恒等函数会将输入按原样输出,对于输入的信息,不加以任何改动地直 接输出。。和前面介绍的隐藏层的激活函数一样,恒等函数进行的转换处理可以 用一根箭头来表示。
softmax函数:
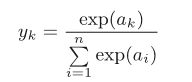
softmax函数 的输出通过箭头与所有的输入信号相连。这是因为,从式(3.10)可以看出, 输出层的各个神经元都受到所有输入信号的影响。
代码:
def softmax(a): #a可以时数组
exp_a = np.exp(a)
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
防止溢出:
def softmax(a):
c = np.max(a)
exp_a = np.exp(a - c) # 溢出对策
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
softmax函数特征:
(1)softmax函数的输出是0.0到1.0之间的实数。并且,softmax 函数的输出值的总和是1。
(2)即便使用了softmax函数,各个元素之间的大小关 系也不会改变。这是因为指数函数(y = exp(x))是单调递增函数。
(3)一般而言,神经网络只把输出值最大的神经元所对应的类别作为识别结果。 并且,即便使用softmax函数,输出值最大的神经元的位置也不会变。因此, 神经网络在进行分类时,输出层的softmax函数可以省略。在实际的问题中, 由于指数函数的运算需要一定的计算机运算量,因此输出层的softmax函数 一般会被省略。
三. 手写数字识别
3.1 基本思想:
首先使用训练数据(学习数据)进 行权重参数的学习;进行推理时,使用刚才学习到的参数,对输入 数据进行分类。
3.2 MNIST数据集:
MNIST数据集是由0到9的数字图像构成的(图3-24)。训练图像有6万张, 测试图像有1万张,这些图像可以用于学习和推理。MNIST数据集的一般 使用方法是,先用训练图像进行学习,再用学习到的模型度量能在多大程度 上对测试图像进行正确的分类。
MNIST的图像数据是28像素 ×28像素的灰度图像(1通道),各个像素 的取值在0到255之间。每个图像数据都相应地标有“7”“ 2”“ 1”等标签。

导入数据集:
import sys, os sys.path.append(os.pardir) # 为了导入父目录中的文件而进行的设定
from dataset.mnist import load_mnist
#导入 dataset/mnist.py中的load_mnist函数。
# 第一次调用会花费几分钟……
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False)
# 输出各个数据的形状
print(x_train.shape) # (60000, 784)
print(t_train.shape) # (60000,)
print(x_test.shape) # (10000, 784)
print(t_test.shape) # (10000,)
解释:
(1)load_mnist函数以“(训练图像,训练标签),(测试图像,测试标签)”的 形式返回读入的MNIST数据
(2)load_mnist(normalize=True, flatten=True, one_hot_label=False) 有3 个 参 数
- normalize:设置是否将输入图像正规化为0.0~1.0的值。如果将该参数设置 为False,则输入图像的像素会保持原来的0~255
- flatten:设置 是否展开输入图像(变成一维数组)。如果将该参数设置为False,则输入图 像为1×28×28的三维数组;若设置为True,则输入图像会保存为由784个 元素构成的一维数组
- one_hot_label:设置是否将标签保存为onehot表示(one-hot representation)。 one-hot表示是仅正确解标签为1,其余 皆为0的数组,就像[0,0,1,0,0,0,0,0,0,0]这样。当one_hot_label为False时, 只是像7、2这样简单保存正确解标签;当one_hot_label为True时,标签则 保存为one-hot表示。
如何显示训练图片集中的图片?(以第一张为例子)
import sys, os sys.path.append(os.pardir)
import numpy as np from dataset.mnist
import load_mnist
from PIL import Image
#图像的显示 使用PIL(Python Image Library)模块
def img_show(img):
pil_img = Image.fromarray(np.uint8(img))
#fromarray:实现array到image的转换
pil_img.show()#显示图片
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False)
#输入图像会保存为由784个 元素构成的一维数组
img = x_train[0]
label = t_train[0]
print(label) # 5
print(img.shape) # (784,)
img = img.reshape(28, 28) # 把图像的形状变成原来的尺寸
print(img.shape) # (28, 28)
img_show(img)
显示结果:
3.3 神经网络的推理处理
- 输入层784个神经元(flatten=true 每张图片展开成一位数组)
- 输出层10个神经元(10个类别,0~9)
- 两个隐藏层,第一个隐藏层有50个神经元,第二个隐藏层有100个神经元,50 100可以设置成任意值
- 注意以下代码是在
已知权重参数的情况下(init_network()会读入保存在pickle文件sample_weight.pkl中的学习到的 权重参数),输入测试数据,来测试识别精度。
def get_data(): #获取测试图像和测试标签
(x_train, t_train), (x_test, t_test) =load_mnist(normalize=True, flatten=True, one_hot_label=False)
return x_test, t_test
def init_network(): #获取权重参数 network是字典
with open("sample_weight.pkl", 'rb') as f:
network = pickle.load(f)
return network
def predict(network, x): #x也可以是多维数组
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = softmax(a3)
return y
x, t = get_data()
#>>> x.shape (10000, 784)
#>>> x[0].shape (784,)
network = init_network()
accuracy_cnt = 0
for i in range(len(x)): #每个循环值串一张照片
y = predict(network, x[i])
p = np.argmax(y) # 获取概率最高的元素的索引
if p == t[i]:
accuracy_cnt += 1
print("Accuracy:" + str(float(accuracy_cnt) / len(x)))
3.4 批处理
上述方式是:测试图像共10000张,一张一张地处理,这里使用批处理,实现高效的运算。
单张处理:
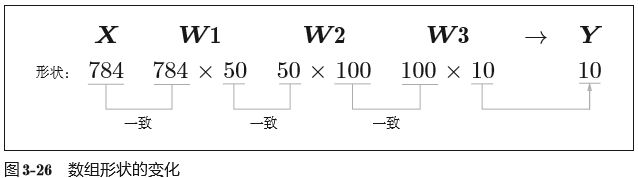
批处理(100张一批):
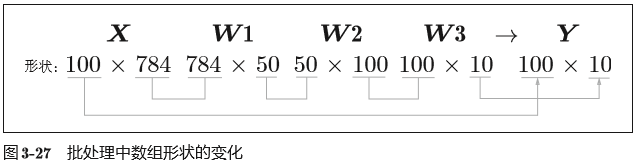
关键代码:
x, t = get_data()
network = init_network()
batch_size = 100 # 批数量
accuracy_cnt = 0
for i in range(0, len(x), batch_size):
#x[0:100]、x[100:200]……这样,从头开始以100为单位将数据提 取为批数据。
x_batch = x[i:i+batch_size]
y_batch = predict(network, x_batch)
p = np.argmax(y_batch, axis=1)
#axis=1 ,沿着第1维方向(以 第1维为轴)找到值最大的元素的索引(第0维对应第1个维度)
accuracy_cnt += np.sum(p == t[i:i+batch_size])
print("Accuracy:" + str(float(accuracy_cnt) / len(x)))