MySql数据库(三):数据的增删改查,排序,聚合函数,分组查询,外键约束,多表查询,子查询
数据的增删改查(CRUD)
插入数据(insert)
向表中指定的字段中添加值:
insert into 表 (字段1,字段2,字段3) values (值1,值2,值3);
向表中所有的字段添加值:
insert into 表 values (值1,值2,值3...);
注意:1.插入的数据与字段数据的类型相同
2.数据的大小应在规定的范围内
3.字符串和日期类型的数据,必须使用单引号括起来
修改数据(update)
修改/更改数据:
update 表名 set 字段=值 where 条件;
注意:若没有where条件子句,默认修改所有该字段的数据
若有where条件子句,修改符合条件的数据
删除数据(delete)
删除数据:
delete from 表 where 条件;
注意:若不加where,默认删除所有数据
若加where条件,删除符合条件的数据
delete 删除支持事务的操作
关于删除的命令
drop truncate delete
drop table 表名; --删除整个表,包括数据和结构
truncate table 表名; --先把整个表删除掉,再创建一个与原来一摸一样的表,不支持事务
delete from 表 where 条件; --支持事务操作,回滚
关于事务
开启事务:
start transaction;
使用delete删除:
delete from 表 where 条件;
数据回滚:
rollback;
查询数据(select)
查询语句:
select * from 表; --默认查询所有字段的数据
select * from 表 where 条件; --查询符合条件的数据
select 字段1,字段2,字段3 from 表; --查询指定字段的数据
select distinct from 表; --使用distinct剔除掉查询结果中重复的数据
查询语句中可以使用as起别名,as可以省略不写,中间使用空格代替
where子句后可以使用的符号
1.>, =, <, >=, <=, !=
2.in 查询字段的值是否在指定的集合中
select * from 表名 where 字段 in (元素1,元素2...);
--嵌套查询,括号里也可以写查询语句
3.like 模糊查询
select * from 表名 where 字段 like '张_';
select * from 表名 where 字段 like '张%';
后面配合通配符使用:'%','_'
'_'下划线,表示查询所占一个字符
'%'百分号,表示查询所占多个字符
条件需要使用单引号''
4.and与 or或 not非 between...and 在...范围,包含两个端点
select * from stu where english>60 and english <90;
select * from stu where english>80 or chinese>90;
select * from stu where english between 60 and 90;
使用 order by 对结果排序
order by 字段 asc | desc;
asc --默认升序
desc --降序
order by放在select语句的末尾
select * from 表 (where 字段) order by 字段 asc/desc;
对结果多次排序时,order by写一次即可,多次不同排序之间使用逗号隔开
聚合函数
聚合函数操作的都是某一列的数据
count() --求数量
select count(*) | count(列名) from 表; --某一列数据的总和
sum() --求某一列数据的和
注意:没有sum(*),求某一列,只对数值类型起作用
select sum(列名) from 表;
avg() --求平均分
select avg(字段) from 表;
min() --求最小值
select min(字段) from 表;
max() --求最大值
select max(字段) from 表;
分组查询
group by --分组查询,在对表中的数据进行一定的类别统计
select 字段 from 表 group by 字段名;
分组查询一般和聚合函数联合一起使用
注意:使用where的条件,如果有分组,where的条件是分组之前的条件
having关键字是进行分组的条件过滤,用在group by后面
where关键字后不能使用聚合函数,
having关键字后可以使用聚合函数
外键约束
外键约束:
foregin key (外键字段名) references 外表表名 (主键字段名)
用于建立和加强两个表数据之间的联系
多表的设计
多表设计存在多种方式:
一对多 多对多 一对一(了解)
一对多:
部门表(一方) 员工表(多方)
用户表(一方) 订单表(多方)
一对多表结构设计,两张表,主表(一方),从表(多方)
建表原则:在多方表中添加字段,把该字段作为外键,指向一方表的主键。
多对多表结构:
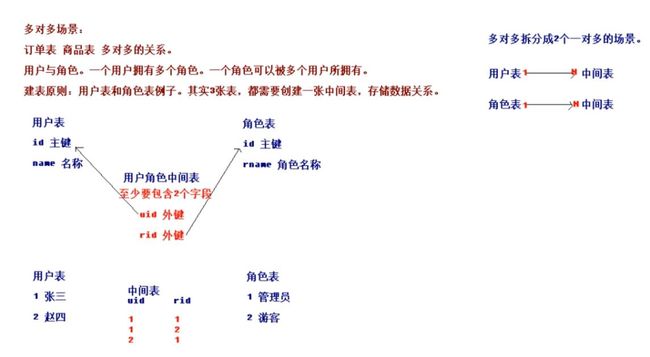
多表查询
笛卡儿积是两个结果的乘积,假如说有两张表,A表和B表
select * from A,B; --查询产生的结果就是笛卡儿积
应该解决这个问题,去掉其中重复的查询结果
内连接
1.普通内连接
语法:...inner join ... on 条件;
注意:在inner join关键字之前写表1,在inner join关键字之后写表2
on后面写条件:表1:dept 表2:emp (dept.did = emp.dno)
select * from dept inner join emp on dept.did = emp.dno;
2.隐式内连接(常用)
语法:select * from 表1,表2 where 表1.字段 = 表2.字段;
例句:select * from dept,emp where dept.did = emp.dno;
外连接
1.左外连接(left)
select * from 表1 left (outer) join 表2 on 条件;
outer可以省略不写
例句:
select * from dept left outer join emp on dept.did = emp.dno;
2.右外连接(right)
select * from 表1 right (outer) join 表2 on 条件;
例句:
select * from dept right outer join emp on dept.did = emp.dno;
内连接 与 外连接的区别
- 内连接查询的是2张表交集的数据,主外键关联的数据
- 左外连接查询的是左表中所有的数据和2张表主外键关联的数据 (以左表为基准,取交集,与右表不匹配的以 null 填充)
- 右外连接查询的是右表中所有的数据和2张表主外键关联的数据 (以右表为基准,取交集,与左表不匹配的以 null 填充)
子查询
子查询,嵌套查询,一个 select 语句不能查询出结果的,可以通过多个 select 语句来查询结果。一个查询语句的结果,作为另一条查询语句的条件。
例句:查询出语文成绩大于语文平均分的同学?
先计算出语文成绩的平均分:select avg(chinese) from stu
语文成绩大于语文平均分的同学:
select username,chinese from stu where chinese > (select avg(chinese) from stu);
MySql事务
事务的4个特性:“ACID”
- 原子性 2. 一致性 3. 持久性 4. 隔离性
- 原子性 :一个事务是一个整体,不可拆分的,事务的 sql 语句,要么都执行,要么都不执行
- 一致性 :通过事务操作的数据要保持一致
- 持久性 :通过事务提交的数据,若没有问题的情况下,将永久生效
- 隔离性 :事务与事务之间相互隔离,就是说一个事务是一个单独的个体,隔离性在多线程操作数据的过程中发挥很大作用,避免了数据的脏读,幻读等