- 【Java】已解决:java.util.concurrent.CompletionException
屿小夏
java开发语言
文章目录一、分析问题背景出现问题的场景代码片段二、可能出错的原因三、错误代码示例四、正确代码示例五、注意事项已解决:java.util.concurrent.CompletionException一、分析问题背景在Java并发编程中,java.util.concurrent.CompletionException是一种常见的运行时异常,通常在使用CompletableFuture进行异步计算时出现
- 谈谈你对AQS的理解
Mutig_s
jucjava开发语言面试后端
AQS概述AQS,全称为AbstractQueuedSynchronizer,是Java并发包(java.util.concurrent)中一个核心的框架,主要用于构建阻塞式锁和相关的同步器,也是构建锁或者其他同步组件的基础框架。AQS提供了一种基于FIFO(First-In-First-Out)的CLH(三个人名缩写)双向队列的机制,来实现各种同步器,如ReentrantLock、Semapho
- 【编程底层原理】HashMap Hashtable ConcurrentHashMap
Dylanioucn
开发语言后端java
在Java的不同版本中,集合的实现原理有所变化,尤其是在HashMap、Hashtable和ConcurrentHashMap这三种实现中。以下是它们的一些关键区别和实现原理:一、HashMapJDK1.7:HashMap使用数组和链表的组合来解决冲突。当一个桶(数组的每个位置)中的元素超过一定数量时,会使用链表来存储这些元素。HashMap在JDK1.7中不是线程安全的。JDK1.8:进行了优化
- Python 将parquet文件转换为csv文件
一个小坑货
#python常用功能方法python开发语言
Python将parquet文件转换为csv文件使用pyarrow插件将parquet文件转换为csv使用pyarrow插件将parquet文件转换为csv```pythonimportosimportpyarrow.parquetaspqfromconcurrent.futuresimportThreadPoolExecutorimportcsvimporttime#定义一个函数来处理单个Par
- java基础-线程间通信方式
问道飞鱼
Java开发技术java开发语言
文章目录1.wait()和notify()2.volatile关键字3.Java.util.concurrent包提供的工具类Semaphore(信号量)BlockingQueue(阻塞队列)4.Atomic类在Java中,线程间的通信是非常重要的,尤其是在多线程编程中,它有助于协调线程的行为,确保资源的正确访问和更新。Java提供了多种方式来实现线程间的通信,主要包括以下几种方法:1.wait(
- SingleFlight模式
你这个代码我看不懂
Springpython开发语言
SingleFlight在Java中实现SingleFlight模式,可以通过使用ConcurrentHashMap和CompletableFuture来管理并发请求。以下是一个示例代码,展示了如何在Java中实现SingleFlight模式:示例代码importjava.util.concurrent.CompletableFuture;importjava.util.concurrent.Co
- pdf转换jpg(Python版本3.10)
大头安
pythonpythonpdf数学建模
importosimportrefromPILimportImagefrompdf2imageimportconvert_from_path,exceptionsfromconcurrent.futuresimportProcessPoolExecutorimporttempfile#解除Pillow的像素限制Image.MAX_IMAGE_PIXELS=Nonechunk_size=10#每个块
- 本地内存和分布式缓存(面试)
rylzdz
缓存redis
本地缓存和分布式缓存本地缓存:缓存组件和应用在同一进程中。但各应用都需要维护单独的缓存,无法共享缓存。分布式缓存:缓存组件和应用分离,不在同一进程,多个应用可直接共享缓存。本地缓存的实现缓存一般是一种key-value的键值对数据结构与此同时,本地缓存由于需要被并发读写,需要保证线程安全。由于HashMap不是线程安全的,而ConcurrentHashMap是线程安全的,一般使用Concurren
- javaspringboot教程,5214页PDF的进阶架构师学习笔记
2401_84415534
程序员pdf学习笔记
一、电面:自我介绍项目情况:对你来说影响最大的一个项目(该面试中有关项目问题都针对该项目展开)?为什么会想做这个项目?这个项目的ideal是谁提出来的?项目中如何实现的大数据的传输和存储项目中哪一部分最难攻克?如何攻克?基础知识考察:模块化的好处Htttp协议hashmap和concurrenthashmap区别及两者的优缺点对MySQL的了解,和oracle的区别对设计模式的看法和认知有哪些设计
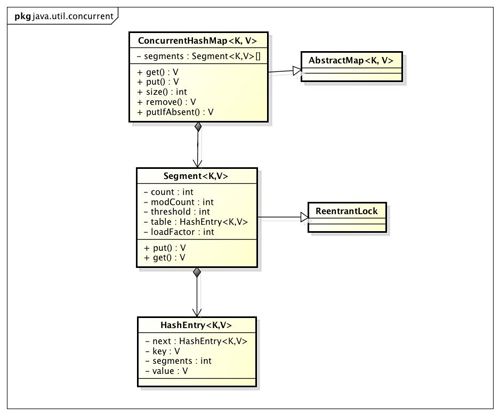
- ConcurrentHashMap实现原理
CodeMaster_37714848
线程安全的hashMap
ConcurrentHashMap是Java中的一个并发集合类,它用于在多线程环境下高效地存储和操作键值对。它的实现原理旨在提供高效的并发访问,确保线程安全,同时保持较高的性能。下面是ConcurrentHashMap的一些核心实现原理:1.分段锁(SegmentLocking)ConcurrentHashMap的早期实现使用了分段锁(SegmentLocking)。这个策略将整个哈希表划分为多个
- Java 入门指南:Java 并发编程 —— 同步工具类 Semephore(信号量)
ZachOn1y
Javajava开发语言intellij-idea个人开发团队开发java-ee
文章目录同步工具类Semephore核心功能限制并发访问量公平与非公平策略灵活性与适应性常用方法使用示例同步工具类JUC(Java.util.concurrent)是Java提供的用于并发编程的工具类库,其中包含了一些通信工具类,用于在多个线程之间进行协调和通信,特别是在多线程和网络通信方面。这些工具类提供了丰富的功能,帮助开发者高效地实现复杂的并发控制和网络通信需求。SemephoreSemap
- Java 入门指南:Java 并发编程 —— 同步工具类 CountDownLatch(倒计时门闩)
ZachOn1y
Javajava后端个人开发java-ee团队开发
文章目录同步工具类CountDownLatch常用方法使用步骤适用场景使用示例同步工具类JUC(Java.util.concurrent)是Java提供的用于并发编程的工具类库,其中包含了一些通信工具类,用于在多个线程之间进行协调和通信,特别是在多线程和网络通信方面。这些工具类提供了丰富的功能,帮助开发者高效地实现复杂的并发控制和网络通信需求。CountDownLatchCountDownLatc
- python如何加速计算密集型任务?
老歌老听老掉牙
python计算
问题描述:在python中,有一个函数,其功能是进行某种计算,需要传入一些参数,计算完成后传回结果,调用其一次大概要1s的时间,现在需要通过for循环调用其350次,保存每次调用结果(可能是合并成一个列表),这个过程大概需要半小时左右,如何加速该代码?方法:为了加速在Python中重复调用一个计算密集型函数的过程,可以采用以下策略:多线程或多进程:使用concurrent.futures模块中的T
- Java面试题--JVM大厂篇之高并发Java应用的秘密武器:深入剖析GC优化实战案例
青云交
Java大厂面试题Java虚拟机(JVM)专栏Javajavajvm不同场景中优化CMSGC高并发Java应用的秘密武器CMSGC电商实战优化案例CMSGC大数据优化案例CMSGC金融系统优化案例
引言:晚上好,Java开发者们!在高并发的现代应用中,垃圾回收器(GC)是Java性能优化的重要环节。尤其在CMS(ConcurrentMark-Sweep)GC曾经担任主角的日子里,适当的调优和优化措施至关重要。本篇文章将通过三个实际案例,探讨如何在不同场景中优化CMSGC,为你揭示Java性能调优的秘密。vQingYunJiao,无论你是新手还是资深工程师,希望这篇文章能为你提供实践中的宝贵经
- 使用CountDownLatch线程同步工具等待其它线程执行完毕之后再执行
CodeMaster_37714848
java
CountDownLatch是Java中的一个线程同步工具,它属于java.util.concurrent包。它用于在一个或多个线程等待其他线程完成一组操作的场景中。常见的使用场景包括:在主线程中等待多个工作线程完成某些初始化操作在多个线程之间协调某些操作的顺序CountDownLatch的工作原理如下:初始化:在创建CountDownLatch对象时,指定一个初始计数值。等待:一个或多个线程调用
- JedisUtils 对jedis的封装 and RedisCacheManager 管理多个连接池
潘多编程
Redisredis
RedisCacheManagerimportjava.util.concurrent.ConcurrentHashMap;importorg.springframework.beans.factory.annotation.Value;importorg.springframework.stereotype.Service;importredis.clients.jedis.Jedis;impo
- Android 面试题——如何徒手写一个非阻塞线程安全队列 ConcurrentLinkedQueue?_android concurrentlinkedqueue
2401_84265972
程序员android安全
队列容器设计若用数组作为队列的容器,就必须得加锁,因为数组是一块连续内存地址,多线程场景下,读写同一块内存地址不得不互斥地访问。链式结构链式结构就没有这个烦恼。链的每个结点都对应不同的内存地址,在多线程场景下,取头结点和插尾结点就不存在并发问题。(至少是降低了并发问题产生的概率)通用的队列应该可存放任何类型的元素。综上,就得声明一个带泛型的链结点://结点privatestaticclassNod
- Java集合中fail-fast和fail-safe机制详解
橡 皮 人
Java集合java集合的fail机制
在使用集合时候,大家应该都遇到过或听过并发修改异常(ConcurrentModificationException),这其实是Java集合中的一种fail-fast机制,为了避免触发fail-fast机制,Java中还提供了一些采用fail-safe机制设计的集合类,本篇文章就系统的介绍一下这两种机制。一、fail-fast机制1.1什么是fail-fast机制简单的说,这就是系统设计的一种理念,
- java高并发程序设计-锁的优化
fantasyYan2
java高并发程序设计javajvmjava多线程锁优化CAS
如何提高锁的性能减少锁持有时间即对类似如下的方法publicsynchronizedvoidsync(){a();//其实只有b需要同步处理b();c();}改进为publicvoidsync(){a();synchronized(this){b();}c();}从而减少锁的持有时间减少锁粒度如ConcurrentHashMap内部分成若干个小的HashMap,每个HashMap加不同的锁读写分离
- Guava Cache的使用
coderlong
javaCache
缓存在Guav中的应用GuavaCache与ConcurrentMap很相似,但也不完全一样。最基本的区别是ConcurrentMap会一直保存所有添加的元素,直到显式地移除。相对地,GuavaCache为了限制内存占用,通常都设定为自动回收元素。在某些场景下,尽管LoadingCache不回收元素,它也是很有用的,因为它会自动加载缓存。通常来说,GuavaCache适用于:你愿意消耗一些内存空间
- Java线程池
sparkle123
Callable和Runable都是启动一个线程,不过Callable可以有返回值importjava.util.concurrent.{Callable,Executor,Executors,Future}objectThreadDemo{defmain(args:Array[String]):Unit={valpool=Executors.newFixedThreadPool(5)//for(
- flink 问题记录
Jhon_yh
flinkflinkhadoop大数据
文章目录1.Causedby:java.lang.UnsatisfiedLinkError:org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSums(IILjava/nio/ByteBuffer;ILjava/nio/ByteBuffer;IILjava/lang/String;JZ)V原因java.util.concurrent.Ex
- inexpensive electronic digital
chouxiao4977
KualaLumpurgathersallkindsofmerchandise,fromtraditionaltolocalizedartsinadditiontocrafts,intheworldfamousmanufacturerfashionforyoutoinexpensiveelectronicdigitalproducts.Concurrently,ithasbothequallyla
- Java 中的并发工具类详解:Semaphore、CountDownLatch 和 CyclicBarrier
swadian2008
并发编程SemaphoreCountDownLatchCyclicBarrierJava并发工具类
目录1、信号量:Semaphore2、线程同步:CountDownLatch和CyclicBarrierJava并发包提供了哪些并发工具类?我们通常所说的并发包也就是java.util.concurrent及其子包,集中了Java并发的各种基础工具类,具体主要包括几个方面:提供了比synchronized更加高级的各种同步结构,包括CountDownLatch、CyclicBarrier、Sema
- 【编程底层思考】JUC中CAS的底层操作系统的实现原理及ABA问题
Dylanioucn
jvmjava开发语言
一、何为CAS操作Java中的CAS操作,即Compare-And-Swap,是一种用于实现无锁编程的原子操作。在Java的java.util.concurrent.atomic包中,许多原子类都利用了CAS操作来保证复合操作的原子性。在底层操作系统层面,CAS通常由特定的CPU指令实现,这些指令能够检测内存中的值是否为预期值,并在条件满足的情况下,将其更新为新值。二、操作系统层面的CAS实现原理
- 前端宝典之三:React源码解析之Fiber架构
桃子叔叔
大厂进阶前端深度解析系列react.js架构javascript
本文主要内容:1、ReactConcurrent2、React15架构3、React16架构4、Fiber架构5、任务调度循环和fiber构造循环区别一、ReactConcurrentReact在解决CPU卡顿是会用到ReactConcurrent的概念,它是React中的一个重要特性和模块,主要的特点和原理如下一、主要特点和优势1、时间切片(TimeSlicing)允许将长时间运行的任务分割成小
- Java 入门指南:Java 并发编程 —— 并发容器 TransferQueue、LinkedTransferQueue、SynchronousQueue
ZachOn1y
Javajava开发语言团队开发个人开发java-eeintellij-idea
BlockingQueueBlockingQueue是Java并发包(java.util.concurrent)中提供的一个阻塞队列接口,它继承自Queue接口。BlockingQueue中的元素采用FIFO的原则,支持多线程环境并发访问,提供了阻塞读取和写入的操作,当前线程在队列满或空的情况下会被阻塞,直到被唤醒或超时。常用的实现类有:ArrayBlockingQueue:并发容器ArrayBl
- Java 入门指南:Java 并发编程 —— 并发容器 LinkedBlockingQueue
ZachOn1y
Javajava开发语言intellij-idea个人开发团队开发后端
BlockingQueueBlockingQueue是Java并发包(java.util.concurrent)中提供的一个阻塞队列接口,它继承自Queue接口。BlockingQueue中的元素采用FIFO的原则,支持多线程环境并发访问,提供了阻塞读取和写入的操作,当前线程在队列满或空的情况下会被阻塞,直到被唤醒或超时。常用的实现类有:ArrayBlockingQueue:并发容器ArrayBl
- Java 入门指南:Java 并发编程 —— 并发容器 ArrayBlockingQueue
ZachOn1y
Javajava开发语言个人开发后端java-ee
BlockingQueueBlockingQueue是Java并发包(java.util.concurrent)中提供的一个阻塞队列接口,它继承自Queue接口。BlockingQueue中的元素采用FIFO的原则,支持多线程环境并发访问,提供了阻塞读取和写入的操作,当前线程在队列满或空的情况下会被阻塞,直到被唤醒或超时。常用的实现类有:ArrayBlockingQueueLinkedBlocki
- 多线程并发条件下创建一个缓存
苁蕶開始
多线程与高并发多线程缓存读写锁
importjava.util.Map;importjava.util.concurrent.ConcurrentHashMap;importjava.util.concurrent.locks.ReadWriteLock;importjava.util.concurrent.locks.ReentrantReadWriteLock;/***@authoryzhang*@date2018/5/25
- redis学习笔记——不仅仅是存取数据
Everyday都不同
returnSourceexpire/delincr/lpush数据库分区redis
最近项目中用到比较多redis,感觉之前对它一直局限于get/set数据的层面。其实作为一个强大的NoSql数据库产品,如果好好利用它,会带来很多意想不到的效果。(因为我搞java,所以就从jedis的角度来补充一点东西吧。PS:不一定全,只是个人理解,不喜勿喷)
1、关于JedisPool.returnSource(Jedis jeids)
这个方法是从red
- SQL性能优化-持续更新中。。。。。。
atongyeye
oraclesql
1 通过ROWID访问表--索引
你可以采用基于ROWID的访问方式情况,提高访问表的效率, , ROWID包含了表中记录的物理位置信息..ORACLE采用索引(INDEX)实现了数据和存放数据的物理位置(ROWID)之间的联系. 通常索引提供了快速访问ROWID的方法,因此那些基于索引列的查询就可以得到性能上的提高.
2 共享SQL语句--相同的sql放入缓存
3 选择最有效率的表
- [JAVA语言]JAVA虚拟机对底层硬件的操控还不完善
comsci
JAVA虚拟机
如果我们用汇编语言编写一个直接读写CPU寄存器的代码段,然后利用这个代码段去控制被操作系统屏蔽的硬件资源,这对于JVM虚拟机显然是不合法的,对操作系统来讲,这样也是不合法的,但是如果是一个工程项目的确需要这样做,合同已经签了,我们又不能够这样做,怎么办呢? 那么一个精通汇编语言的那种X客,是否在这个时候就会发生某种至关重要的作用呢?
&n
- lvs- real
男人50
LVS
#!/bin/bash
#
# Script to start LVS DR real server.
# description: LVS DR real server
#
#. /etc/rc.d/init.d/functions
VIP=10.10.6.252
host='/bin/hostname'
case "$1" in
sta
- 生成公钥和私钥
oloz
DSA安全加密
package com.msserver.core.util;
import java.security.KeyPair;
import java.security.PrivateKey;
import java.security.PublicKey;
import java.security.SecureRandom;
public class SecurityUtil {
- UIView 中加入的cocos2d,背景透明
374016526
cocos2dglClearColor
要点是首先pixelFormat:kEAGLColorFormatRGBA8,必须有alpha层才能透明。然后view设置为透明glView.opaque = NO;[director setOpenGLView:glView];[self.viewController.view setBackgroundColor:[UIColor clearColor]];[self.viewControll
- mysql常用命令
香水浓
mysql
连接数据库
mysql -u troy -ptroy
备份表
mysqldump -u troy -ptroy mm_database mm_user_tbl > user.sql
恢复表(与恢复数据库命令相同)
mysql -u troy -ptroy mm_database < user.sql
备份数据库
mysqldump -u troy -ptroy
- 我的架构经验系列文章 - 后端架构 - 系统层面
agevs
JavaScriptjquerycsshtml5
系统层面:
高可用性
所谓高可用性也就是通过避免单独故障加上快速故障转移实现一旦某台物理服务器出现故障能实现故障快速恢复。一般来说,可以采用两种方式,如果可以做业务可以做负载均衡则通过负载均衡实现集群,然后针对每一台服务器进行监控,一旦发生故障则从集群中移除;如果业务只能有单点入口那么可以通过实现Standby机加上虚拟IP机制,实现Active机在出现故障之后虚拟IP转移到Standby的快速
- 利用ant进行远程tomcat部署
aijuans
tomcat
在javaEE项目中,需要将工程部署到远程服务器上,如果部署的频率比较高,手动部署的方式就比较麻烦,可以利用Ant工具实现快捷的部署。这篇博文详细介绍了ant配置的步骤(http://www.cnblogs.com/GloriousOnion/archive/2012/12/18/2822817.html),但是在tomcat7以上不适用,需要修改配置,具体如下:
1.配置tomcat的用户角色
- 获取复利总收入
baalwolf
获取
public static void main(String args[]){
int money=200;
int year=1;
double rate=0.1;
&
- eclipse.ini解释
BigBird2012
eclipse
大多数java开发者使用的都是eclipse,今天感兴趣去eclipse官网搜了一下eclipse.ini的配置,供大家参考,我会把关键的部分给大家用中文解释一下。还是推荐有问题不会直接搜谷歌,看官方文档,这样我们会知道问题的真面目是什么,对问题也有一个全面清晰的认识。
Overview
1、Eclipse.ini的作用
Eclipse startup is controlled by th
- AngularJS实现分页功能
bijian1013
JavaScriptAngularJS分页
对于大多数web应用来说显示项目列表是一种很常见的任务。通常情况下,我们的数据会比较多,无法很好地显示在单个页面中。在这种情况下,我们需要把数据以页的方式来展示,同时带有转到上一页和下一页的功能。既然在整个应用中这是一种很常见的需求,那么把这一功能抽象成一个通用的、可复用的分页(Paginator)服务是很有意义的。
&nbs
- [Maven学习笔记三]Maven archetype
bit1129
ArcheType
archetype的英文意思是原型,Maven archetype表示创建Maven模块的模版,比如创建web项目,创建Spring项目等等.
mvn archetype提供了一种命令行交互式创建Maven项目或者模块的方式,
mvn archetype
1.在LearnMaven-ch03目录下,执行命令mvn archetype:gener
- 【Java命令三】jps
bit1129
Java命令
jps很简单,用于显示当前运行的Java进程,也可以连接到远程服务器去查看
[hadoop@hadoop bin]$ jps -help
usage: jps [-help]
jps [-q] [-mlvV] [<hostid>]
Definitions:
<hostid>: <hostname>[:
- ZABBIX2.2 2.4 等各版本之间的兼容性
ronin47
zabbix更新很快,从2009年到现在已经更新多个版本,为了使用更多zabbix的新特性,随之而来的便是升级版本,zabbix版本兼容性是必须优先考虑的一点 客户端AGENT兼容
zabbix1.x到zabbix2.x的所有agent都兼容zabbix server2.4:如果你升级zabbix server,客户端是可以不做任何改变,除非你想使用agent的一些新特性。 Zabbix代理(p
- unity 3d还是cocos2dx哪个适合游戏?
brotherlamp
unity自学unity教程unity视频unity资料unity
unity 3d还是cocos2dx哪个适合游戏?
问:unity 3d还是cocos2dx哪个适合游戏?
答:首先目前来看unity视频教程因为是3d引擎,目前对2d支持并不完善,unity 3d 目前做2d普遍两种思路,一种是正交相机,3d画面2d视角,另一种是通过一些插件,动态创建mesh来绘制图形单元目前用的较多的是2d toolkit,ex2d,smooth moves,sm2,
- 百度笔试题:一个已经排序好的很大的数组,现在给它划分成m段,每段长度不定,段长最长为k,然后段内打乱顺序,请设计一个算法对其进行重新排序
bylijinnan
java算法面试百度招聘
import java.util.Arrays;
/**
* 最早是在陈利人老师的微博看到这道题:
* #面试题#An array with n elements which is K most sorted,就是每个element的初始位置和它最终的排序后的位置的距离不超过常数K
* 设计一个排序算法。It should be faster than O(n*lgn)。
- 获取checkbox复选框的值
chiangfai
checkbox
<title>CheckBox</title>
<script type = "text/javascript">
doGetVal: function doGetVal()
{
//var fruitName = document.getElementById("apple").value;//根据
- MySQLdb用户指南
chenchao051
mysqldb
原网页被墙,放这里备用。 MySQLdb User's Guide
Contents
Introduction
Installation
_mysql
MySQL C API translation
MySQL C API function mapping
Some _mysql examples
MySQLdb
- HIVE 窗口及分析函数
daizj
hive窗口函数分析函数
窗口函数应用场景:
(1)用于分区排序
(2)动态Group By
(3)Top N
(4)累计计算
(5)层次查询
一、分析函数
用于等级、百分点、n分片等。
函数 说明
RANK() &nbs
- PHP ZipArchive 实现压缩解压Zip文件
dcj3sjt126com
PHPzip
PHP ZipArchive 是PHP自带的扩展类,可以轻松实现ZIP文件的压缩和解压,使用前首先要确保PHP ZIP 扩展已经开启,具体开启方法就不说了,不同的平台开启PHP扩增的方法网上都有,如有疑问欢迎交流。这里整理一下常用的示例供参考。
一、解压缩zip文件 01 02 03 04 05 06 07 08 09 10 11
- 精彩英语贺词
dcj3sjt126com
英语
I'm always here
我会一直在这里支持你
&nb
- 基于Java注解的Spring的IoC功能
e200702084
javaspringbeanIOCOffice
- java模拟post请求
geeksun
java
一般API接收客户端(比如网页、APP或其他应用服务)的请求,但在测试时需要模拟来自外界的请求,经探索,使用HttpComponentshttpClient可模拟Post提交请求。 此处用HttpComponents的httpclient来完成使命。
import org.apache.http.HttpEntity ;
import org.apache.http.HttpRespon
- Swift语法之 ---- ?和!区别
hongtoushizi
?swift!
转载自: http://blog.sina.com.cn/s/blog_71715bf80102ux3v.html
Swift语言使用var定义变量,但和别的语言不同,Swift里不会自动给变量赋初始值,也就是说变量不会有默认值,所以要求使用变量之前必须要对其初始化。如果在使用变量之前不进行初始化就会报错:
var stringValue : String
//
- centos7安装jdk1.7
jisonami
jdkcentos
安装JDK1.7
步骤1、解压tar包在当前目录
[root@localhost usr]#tar -xzvf jdk-7u75-linux-x64.tar.gz
步骤2:配置环境变量
在etc/profile文件下添加
export JAVA_HOME=/usr/java/jdk1.7.0_75
export CLASSPATH=/usr/java/jdk1.7.0_75/lib
- 数据源架构模式之数据映射器
home198979
PHP架构数据映射器datamapper
前面分别介绍了数据源架构模式之表数据入口、数据源架构模式之行和数据入口数据源架构模式之活动记录,相较于这三种数据源架构模式,数据映射器显得更加“高大上”。
一、概念
数据映射器(Data Mapper):在保持对象和数据库(以及映射器本身)彼此独立的情况下,在二者之间移动数据的一个映射器层。概念永远都是抽象的,简单的说,数据映射器就是一个负责将数据映射到对象的类数据。
&nb
- 在Python中使用MYSQL
pda158
mysqlpython
缘由 近期在折腾一个小东西须要抓取网上的页面。然后进行解析。将结果放到
数据库中。 了解到
Python在这方面有优势,便选用之。 由于我有台
server上面安装有
mysql,自然使用之。在进行数据库的这个操作过程中遇到了不少问题,这里
记录一下,大家共勉。
python中mysql的调用
百度之后能够通过MySQLdb进行数据库操作。
- 单例模式
hxl1988_0311
java单例设计模式单件
package com.sosop.designpattern.singleton;
/*
* 单件模式:保证一个类必须只有一个实例,并提供全局的访问点
*
* 所以单例模式必须有私有的构造器,没有私有构造器根本不用谈单件
*
* 必须考虑到并发情况下创建了多个实例对象
* */
/**
* 虽然有锁,但是只在第一次创建对象的时候加锁,并发时不会存在效率
- 27种迹象显示你应该辞掉程序员的工作
vipshichg
工作
1、你仍然在等待老板在2010年答应的要提拔你的暗示。 2、你的上级近10年没有开发过任何代码。 3、老板假装懂你说的这些技术,但实际上他完全不知道你在说什么。 4、你干完的项目6个月后才部署到现场服务器上。 5、时不时的,老板在检查你刚刚完成的工作时,要求按新想法重新开发。 6、而最终这个软件只有12个用户。 7、时间全浪费在办公室政治中,而不是用在开发好的软件上。 8、部署前5分钟才开始测试。