Linux通配符、Linux元字符(特殊字符)和Linux grep命令
1.Shell常见通配符
通配符是shell在做PathnameExpansion(路径名扩展)时用到的。说白了一般只用于文件名匹配,它是由shell解析的,比如find,ls,cp,mv等。
| 通配符 |
含义 |
实例 |
| * |
匹配 0 或多个字符 |
a*b a与b之间可以有任意长度的任意字符, 也可以一个也没有, 如aabcb, axyzb, a012b, ab。 |
| ? |
匹配任意一个字符 |
a?b a与b之间必须也只能有一个字符, 可以是任意字符, 如aab, abb, acb, a0b。 |
| [list] |
匹配 list 中的任意单一字符 |
a[xyz]b a与b之间必须 |
| [!list]或[^list] |
匹配 除list 中的任意单一字符 |
a[!0-9]b a与b之间必须也只能有一个字符, 但不能是阿拉伯数字, 如axb, aab, a-b。 |
| [c1-c2] |
匹配 c1-c2 中的任意单一字符 如:[0-9] [a-z] |
a[0-9]b 0与9之间必须也只能有一个字符 如a0b, a1b... a9b。 |
| [!c1-c2]或[^c1-c2] |
匹配不在c1-c2的任意字符 |
a[!0-9]b 如acb adb |
| {string1,string2,...} |
匹配 sring1 或 string2 (或更多)其一字符串 |
a{abc,xyz,123}b 列出aabcb,axyzb,a123b |
2. Shell Meta字符(元字符)
shell 除了有通配符之外,还有一系列自己的其他特殊字符。
| 字符 |
说明 |
| IFS |
由 |
| CR |
由 |
| = |
设定变量 |
| $ |
取变量值或取运算值 |
| > |
重定向 stdout |
| < |
重定向 stdin |
| | |
管道符号 |
| & |
重导向 file descriptor ,或将命令置于后台执行 |
| ( ) |
将其内的命令置于 nested subshell 执行,或用于运算或命令替换 |
| { } |
将其内的命令置于 non-named function 中执行,或用在变量替换的界定范围 |
| ; |
在前一个命令结束时,而忽略其返回值,继续执行下一个命令 |
| && |
在前一个命令结束时,若返回值为 true,继续执行下一个命令。即前一个命令成功运行后才运行后一条命令 |
| || |
在前一个命令结束时,若返回值为 false,继续执行下一个命令 |
| ! |
运算意义上的非(not)的意思 |
| # |
注释,常用在脚本中 |
| \ |
转移字符,去除其后紧跟的元字符或通配符的特殊意义 |
3. 转义字符
有时候,我们想让 通配符,或者元字符 变成普通字符,不需要使用它。那么这里我们就需要用到转义符了。 shell提供转义符有三种:
| 字符 |
说明 |
| ‘’(单引号) |
硬转义,其内部所有的shell 元字符、通配符都会被关掉。 |
| “”(双引号) |
软转义,其内部只允许出现特定的shell 元字符:$用于参数替换 `(反单引号,esc键下面)用于命令替换 |
| \(反斜杠) |
又叫转义,去除其后紧跟的元字符或通配符的特殊意义 |
4. Linux 文本过滤工具(vi、sed--stream editor for filtering and transforming text用于过滤和转换文本的流编辑器 、grep、awk)中的正则表达式。
正则表达式是描述一组字符串的模式。正则表达式的构造类似于算术表达式,通过使用各种运算符来组合更小的表达式。
grep可以理解三种不同版本的正则表达式语法:“basic”、“extended”和“perl”。在GNU grep中,basic和extened语法在可用功能上没有区别。在其他实现中,基本正则表达式的功能没有那么强大。下列描述适用于extened正则表达式;之后将总结基本正则表达式的不同之处。Perl正则表达式提供了额外的功能,并在pcresyntax(3)和pcrepattern(3)中进行了记录,但可能不是在每个系统上都可用。
基本构建块是匹配单个字符的正则表达式。大多数字符,包括所有的字母和数字,都是匹配自身的正则表达式。任何具有特殊含义的元字符都可以在其前面加上反斜杠。 这段时间。匹配任何单个字符。
字符类和括号表达式(Character Classes and Bracket Expressions)
中括号表达式是由[和]括起的字符列表。它匹配列表中的任何一个字符;如果列表的第一个字符是插入符号^,那么它将匹配列表中没有的任何字符。例如,正则表达式[0123456789]匹配任何单个数字。
在中括号表达式中,范围表达式由用连字符分隔的两个字符组成。它匹配在这两个字符之间排序的任何单个字符,包括使用区域设置的排序序列和字符集。例如,在默认的C区域设置中,[a-d]等价于[abcd]。许多语言环境按照字典顺序对字符进行排序,在这些语言环境中[a-d]通常不等于[abcd];例如,它可能等价于[aBbCcDd]。要获得中括号表达式的传统解释,可以通过将LC_ALL环境变量设置为值C来使用C语言环境。
最后,在中括号表达式中预定义了一些指定的字符类,如下所示。他们的名字是自解释的,它们是 [:alnum:], [:alpha:], [:cntrl:], [:digit:], [:graph:], [:lower:], [:print:], [:punct:], [:space:], [:upper:]和 [:xdigit:].。例如,[[:alnum:]]表示当前区域设置中数字和字母的字符类。在C语言环境和ASCII字符集编码中,这与[0-9A-Za-z]相同。(注意,这些类名中的中括号是符号名的一部分,必须包含在分隔中括号表达式的中括号之外。为了包含字符 ] ,请把它放到列表中的第一个位置;类似的,为了包含字符 ^ ,请把它放到列表中除了第一个位置之外的任何位置;最后,为了包含字符 - ,请把它放在列表中的最后位置)
锚定(Anchoring)
插入符号 ^ 和美元符号 $ 是元字符,它们分别匹配行首和行尾的空字符串。
反斜杠字符和特殊表达式 (The Backslash Character and Special Expressions)
符号 \< 和 \> 分别匹配单词开头和结尾的空字符串。符号 \b 匹配单词边缘的空字符串, \B 匹配空字符串,前提是它不在单词的边缘。符号 \w 是 [_[:alnum:]] 的同义词,而 \W 是 [^_[:alnum:]] 的同义词。
重复(Repetition)
正则表达式后面可以跟着几个重复运算符中的一个:
? 前一项是可选的,最多匹配一次。
* 前一项将匹配零次或多次。
+ 前一项将匹配一次或多次。
{n} 前一项恰好匹配n次。
{n,} 前一项匹配n次或更多次。
{,m} 前一项最多匹配m次。这是一个GNU扩展。
{n,m} 前一项匹配至少n次,但不超过m次。
连接(Concatenation)
可以连接两个正则表达式;生成的正则表达式匹配由两个子字符串连接而成的任何字符串,这两个子字符串分别匹配连接后的表达式。
交替(Alternation)
两个正则表达式可以由中缀运算符 | 连接;生成的正则表达式匹配任何与任一备用表达式匹配的字符串。
优先级(Precedence)
重复优先于连接,连接又优先于交替。整个表达式可以用圆括号括起来,以覆盖这些优先规则并形成子表达式。
反向引用和子表达式(Back References and Subexpressions)
反向引用\n(其中n是一位数字)匹配前面由正则表达式的第n个圆括号子表达式匹配的子字符串
基本正则表达式vs扩展正则表达式(Basic vs Extended Regular Expressions)
在基本正则表达式中,元字符?、+、{、|、( 和 ) 失去了它们的特殊含义;相反,使用反斜杠版本 \?, \+, \{, \|, \(,和 \) 。
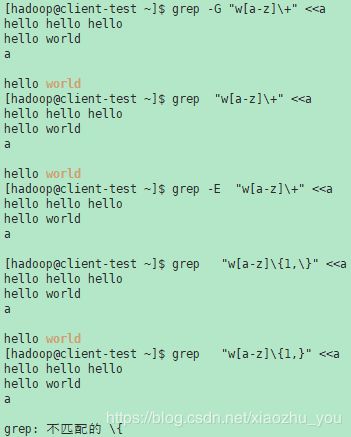
传统的egrep不支持{元字符,而一些egrep实现支持 \{ ,因此可移植脚本应该避免在grep -E模式中使用 {,而应该使用 [{] 来匹配字符 {。
GNU grep -E试图支持传统用法,如果 { 是一个无效区间规范的开始,那么它并不特殊。例如,命令 grep -E '{1' 搜索双字符串 {1,而不是报告正则表达式中的语法错误。POSIX允许这种行为作为扩展,但是可移植脚本应该避免这种行为。
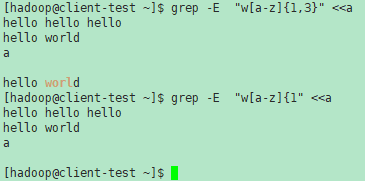


在正则表达式的使用过程中,一些字符是以特定方式处理的。最常使用的特殊字符如下:
| 字符 |
含义 |
| ^ |
指向一行的开头 |
| $ |
指向一行的结尾 |
| . |
任意单个字符 |
| [] |
字符范围。如[a-z] |
如果想将上述字符用作普通字符,就需要在它们前面加上\字符。例如,如果想使用$字符,你需要将它写为\$。
在方括号中还可以使用一些有用的特殊匹配模式,如下:
| 匹配模式 |
含义 |
| [:alnum:] |
字母与数字字符,如grep[[:alnum:]] words.txt |
| [:alpha:] |
字母 |
| [:ascii:] |
ASCII字符 |
| [:blank:] |
空格或制表符 |
| [:cntrl:] |
ASCII控制字符 |
| [:digit:] |
数字 |
| [:graph:] |
非控制、非空格字符 |
| [:lower:] |
小写字母 |
| [:print:] |
可打印字符 |
| [:punct:] |
标点符号字符 |
| [:space:] |
空白字符,包括垂直制表符 |
| [:upper:] |
大写字母 |
| [:xdigit:] |
十六进制数字 |

另外,如果指定了用于扩展的-E选项,那些用于控制匹配完成的其他字符可能会遵循正则表达式的规则,对于grep命令,我们还需要在这些字符前面加上\,下表是扩展部分一览:
| 选项 |
含义 |
| ? |
最多一次 |
| * |
必须匹配0次或多次 |
| + |
必须匹配1次或多次 |
| {n} |
必须匹配n次 |
| {n,} |
必须匹配n次或以上 |
| {n,m} |
匹配次数在n到m之间,包括边界 |
通配符和正则表达式比较:
- 通配符和正则表达式看起来有点像,不能混淆。可以简单的理解为通配符只有*,?,[],{}这4种,而正则表达式复杂多了。
- *在通配符和正则表达式中有其不一样的地方,在通配符中*可以匹配任意的0个或多个字符,而在正则表达式中他是重复之前的一个或者多个字符,不能独立使用的。比如通配符可以用*来匹配任意字符,而正则表达式不行,他只匹配任意长度的前面的字符。
5. grep
(1). grep简介
grep (global search regular expression(RE) and print out the line,使用正则表达式全面搜索文本并打印匹配的行)是一种强大的文本搜索工具,它能使用正则表达式在一个或多个文件中搜索字符串模式,并把匹配的行打印出来。Unix的grep家族包括grep、egrep和fgrep。egrep和fgrep的命令只跟grep有很小不同。egrep是grep的扩展,支持更多的re元字符,
fgrep就是fixed grep或fast grep,它们把所有的字母都看作单词,也就是说,正则表达式中的元字符表示回其自身的字面意义,不再特殊。linux使用GNU版本的grep。它功能更强,可以通过-E、-F命令行选项来使用egrep和fgrep的功能。
grep的工作方式是这样的,它在一个或多个文件中搜索字符串模板。如果模板包括空格,则模板必须使用引号,模板后的所有字符串被看作文件名。搜索的结果被送到屏幕,不影响原文件内容。
grep可用于shell脚本,因为grep通过返回一个状态值来说明搜索的状态,如果模板搜索成功,则返回0,如果搜索不成功,则返回1,如果搜索的文件不存在,则返回2。我们利用这些返回值就可进行一些自动化的文本处理工作。
用法:
grep [选项]... PATTERN [FILE]...
在每个 FILE 或是标准输入中查找 PATTERN。
默认的 PATTERN 是一个基本正则表达式(缩写为 BRE)。
或:
grep [OPTIONS] PATTERN [FILE...]
grep [OPTIONS] [-e PATTERN | -f FILE] [FILE...]
描述:
grep搜索指定的输入文件(或者标准输入如果没有指定文件或只给出一个连字符减号(-)作为文件名),查找包含与给定模式匹配的行。默认情况下,grep打印匹配的行。
此外,有两个变体程序egrep和fgrep是可用的。egrep和grep -E是一样的。fgrep和grep -F是一样的。不建议直接调用egrep或fgrep,但是提供了这种方法,允许依赖于它们的历史应用程序不加修改地运行。
(2). grep正则表达式元字符集(基本集)
- ^ :锚定行的开始 如:'^grep'匹配所有以grep开头的行。
- $ :锚定行的结束 如:'grep$'匹配所有以grep结尾的行。
- . :匹配一个非换行符的字符 如:'gr.p'匹配gr后接一个任意字符,然后是p。
- * :匹配零个或多个先前字符 如:' *grep'匹配所有0个或多个空格后紧跟grep的行。 .*一起用代表任意字符。
- [] :匹配一个指定范围内的字符,如'[Gg]rep'匹配Grep和grep。
- [^] :匹配一个不在指定范围内的字符,如:'[^A-FH-Z]rep'匹配不包含A-F和H-Z的一个字母开头,紧跟rep的行
- \(\) : 标记匹配字符,如'\(love\)',love被标记为\1。备注:即能捕获的分组
- \< :匹配单词开始的空字符,如:'\
- \> :匹配单词结束的空字符,如'grep\>'匹配包含以grep结尾的单词的行。
- x\{m\} :重复字符x,m次,如:'o\{5\}'匹配包含5个o的行。
- x\{m,\} :重复字符x,至少m次,如:'o\{5,\}'匹配至少有5个o的行。
- x\{m,n\} :重复字符x,至少m次,不多于n次,如:'o\{5,10\}'匹配5-10个o的行。
- \w :匹配文字和数字字符,也就是[A-Za-z0-9],如:'G\w*p'匹配以G后跟零个或多个文字或数字字符,然后是p。
- \W :\w的反置形式,匹配一个或多个非单词字符,如点号句号等。
- \b :匹配单词边界的空字符,如: '\bgrepb\'只匹配grep。
(3). 用于egrep和 grep -E的元字符扩展集
- + :匹配一个或多个先前的字符。如:'[a-z]+able',匹配一个或多个小写字母后跟able的串,如loveable,enable,disable等。
- ? :匹配零个或多个先前的字符。如:'gr?p'匹配gr后跟一个或没有字符,然后是p的行。
- a|b|c :匹配a或b或c。如:grep|sed匹配grep或sed
- () :分组符号,如:love(able|rs)ov+匹配loveable或lovers,匹配一个或多个ov。
- x{m},x{m,},x{m,n} :作用同x\{m\},x\{m,\},x\{m,n\}
(4). Grep命令选项
[hadoop@client-test ~]$ cat student1.txt
1,付坤,男,26
2,小猪,男,27
3,枫叶,女,28
4,小小,女,29
5,大大,女,30
[hadoop@client-test ~]$ cat student2.txt
6,五天,男,24
7,伯,男,25
8,仲,男,26
9,叔,男,27
10,季,男,30
11,姑,女,25
- 匹配器选择(Matcher Selection)(1~4)和匹配控制(Matching Control)(5~)
- -E, --extended-regexp 将PATTERN解释为扩展正则表达式(ERE,请参见下面)。(-E由POSIX指定)
- [hadoop@client-test ~]$ grep "[0-9]+" student1.txt
[hadoop@client-test ~]$ grep -E "[0-9]+" student1.txt
1,付坤,男,26
2,小猪,男,27
3,枫叶,女,28
4,小小,女,29
5,大大,女,30 [hadoop@client-test ~]$ grep -E "[0-9]{1,}" student1.txt
1,付坤,男,26
2,小猪,男,27
3,枫叶,女,28
4,小小,女,29
5,大大,女,30
- [hadoop@client-test ~]$ grep "[0-9]+" student1.txt
- -F, --fixed-strings, --fixed-regrep 将PATTERN解释为由断行符分隔的固定字符串列表,其中任何一个字符串都要匹配。(-F由POSIX指定,--fixed-regexp是一个过时的别名,请不要在新脚本中使用它。)
- -G, --basic-regexp 将PATTERN解释为基本的正则表达式(BRE,请参见下面)。这是默认的。
- [hadoop@client-test ~]$ grep -G "[0-9]{1,}" student1.txt
[hadoop@client-test ~]$ grep -G "[0-9]\{1,\}" student1.txt
1,付坤,男,26
2,小猪,男,27
3,枫叶,女,28
4,小小,女,29
5,大大,女,30
- [hadoop@client-test ~]$ grep -G "[0-9]{1,}" student1.txt
- -P, --perl-regexp 将PATTERN解释为Perl正则表达式。这是高度实验性的,grep -p可能会警告未实现的特性。
- -e PATTERN, --regexp=PATTERN 使用PATTERN作为模式。这可以用来指定多个搜索模式,或者保护以连字符(-)开头的模式。(-e由POSIX指定)
- -f FILE, --file=FILE 从文件中获取模式,每行一个。空文件包含零模式,因此不匹配任何内容。(-f由POSIX指定)
- [hadoop@client-test ~]$ grep -f "student2.txt" student1.txt
[hadoop@client-test ~]$ grep -f "student1.txt" student1.txt
1,付坤,男,26
2,小猪,男,27
3,枫叶,女,28
4,小小,女,29
5,大大,女,30
[hadoop@client-test ~]$ grep -f student1.txt student1.txt
1,付坤,男,26
2,小猪,男,27
3,枫叶,女,28
4,小小,女,29
5,大大,女,30
- [hadoop@client-test ~]$ grep -f "student2.txt" student1.txt
- -i, --ignore-case 忽略模式和输入文件中的大小写差别。(-i由POSIX指定)
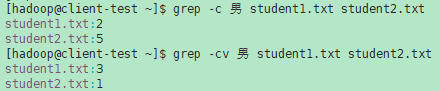
- -v, --invert-match 反转匹配的意义,选择不匹配的行。(-v由POSIX指定)
- [hadoop@client-test ~]$ grep -v 男 student1.txt
3,枫叶,女,28
4,小小,女,29
5,大大,女,30
- [hadoop@client-test ~]$ grep -v 男 student1.txt
- -w, --word-regexp 只选择那些包含与整个单词匹配的行。测试是匹配的子字符串必须位于行首,或者在前面加上非单词组成字符。类似地,它必须位于行尾,或者后跟非单词组成字符。组成单词的字符包括字母、数字和下划线。
- [hadoop@client-test ~]$ grep -w hello <
> helloxiaohzu
> Hi and hello
> haha hello ena
> heh helloa
> EOF
hello world
Hi and hello
haha hello ena
- [hadoop@client-test ~]$ grep -w hello <
- -x, --line-regexp 只选择与整行完全匹配的匹配项(即这些行)。(-x由POSIX指定)
-
[hadoop@client-test ~]$ grep -x hello <
helloxiaohzu
Hi and hello
hello
EOFhello
-
- -E, --extended-regexp 将PATTERN解释为扩展正则表达式(ERE,请参见下面)。(-E由POSIX指定)
- 一般输出控制(General Output Control)
- -c, --count 抑制正常输出;相反,打印每个输入文件的匹配行数。使用-v,--reverse -match选项(参见下面),计算不匹配的行。(-c由POSIX指定)
示例(1):
- --color[=WHEN], --colour[=WHEN] 用转义序列将匹配(非空)的字符串、匹配行、上下文行、文件名、行号、字节偏移量和分隔符(用于字段和上下文行组)包围起来,以便在终端上以颜色显示它们。这些颜色由环境变量GREP_COLORS定义。仍然支持已废弃的环境变量GREP_COLOR,但是它的设置没有优先级。WHEN是从来没有,总是,或自动。
- -L, --files-without-match 抑制正常输出;相反,打印通常不会打印输出的每个输入文件(即不匹配PATTERN的文件)的名称。扫描将在第一次匹配时停止。
示例(1):

- -l, --files-with-match 抑制正常输出;相反,打印输出通常会打印的每个输入文件(即匹配的文件)的名称。扫描将在第一次匹配时停止。(-l由POSIX指定)
示例(1):

- -m NUM, --max-count=NUM 在NUM个匹配行之后停止读取一个文件。如果输入是来自一个常规文件的标准输入,并且输出了NUM匹配行,那么grep将确保标准输入定位到退出前最后匹配行之后的位置,而不管是否存在尾部上下文行。这使调用进程能够恢复搜索。当grep在NUM匹配行之后停止时,它输出任何尾部的上下文行。当使用-c或--count选项时,grep输出的计数不会大于NUM,当使用-v或--reverse -match选项时,grep在输出NUM不匹配的行之后停止。
示例(1):

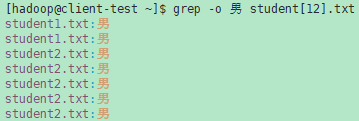
- -o, --only-matching 只打印匹配行中匹配的部分(非空),将每个匹配的部分放在单独的输出行中。
示例(1):
- -q, --quiet, --silent 安静的;不要向标准输出写入任何内容。如果找到任何匹配项,立即退出,状态为零,即使检测到错误也是如此。还请参见-s或--no-messages选项。(-q由POSIX指定)
示例(1):

- -s, --no-messages 禁止关于不存在或不可读文件的错误消息。可移植性注意:与GNU grep不同,第七版Unix grep不符合POSIX,因为它缺少-q,它的-s选项的行为类似于GNU grep的-q选项。usg风格的grep也缺少-q,但是它的-s选项表现得像GNU grep。可移植的shell脚本应该避免-q和-s,应该将标准输出和错误输出重定向到/dev/null。(-s由POSIX指定)
示例(1):
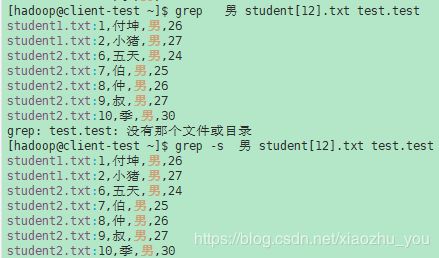
- -c, --count 抑制正常输出;相反,打印每个输入文件的匹配行数。使用-v,--reverse -match选项(参见下面),计算不匹配的行。(-c由POSIX指定)
- 输出行前缀控制(Output Line Prefix Control)
- -b, --byte-offset 在每一行输出之前,打印输入文件中每行基于0的字节偏移量。如果指定-o(--only-matching),则打印匹配部分本身的偏移量。
示例(1):
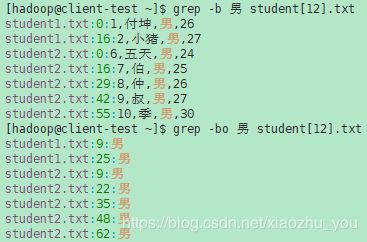
- -H, --with-filename 打印每个匹配项的文件名。这是搜索多个文件时的默认值。
示例(1):
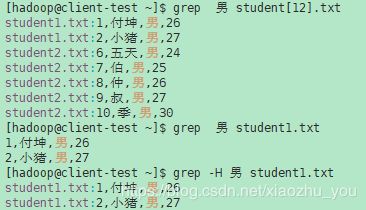
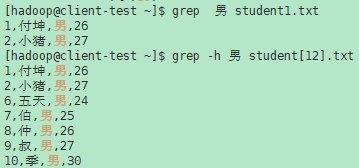
- -h, --no-filename 在输出时禁止文件名前缀。当只有一个文件(或只有标准输入)要搜索时,这是默认值。
示例(1):
- --lable=LABEL 将LABEL 作为标准输入文件名前缀
示例(1):
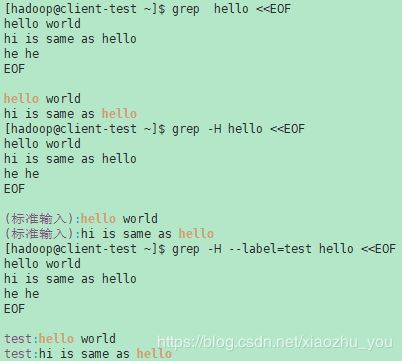
示例(2):

- -n, --line-number 在输出的每一行前面 以此行在输入文件中基于1的行号为 前缀。(-n由POSIX指定)
示例(1):
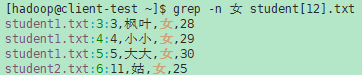
- -T, --initial-tab 确保实际行内容的第一个字符位于制表位上,使制表位的对齐看起来正常。这对于将输出前缀设置为实际内容的选项非常有用:-H、-n和-b。为了提高单个文件中的行都从同一列开始的概率,这还会导致行号和字节偏移量(如果存在)以最小大小字段宽度打印。
示例(1):

- -u, --unix-byte-offsets 报告unix风格的字节偏移量。这个切换会导致grep报告字节偏移量,就好像这个文件是一个unix样式的文本文件一样。这将产生与在Unix机器上运行grep相同的结果。除非同时使用-b选项,否则此选项无效;它对MS-DOS和MS-Windows以外的平台没有影响。
- -Z, --null 在文件名之后输出一个零字节(ASCII NUL字符),而不是通常跟在文件名后面的字符。例如,grep -lZ在每个文件名之后输出一个零字节,而不是通常的换行。这个选项使输出没有歧义,即使存在包含不寻常字符(如换行)的文件名。此选项可与find -print0、perl -0、sort -z和xargs -0等命令一起使用,以处理任意文件名,甚至是包含换行字符的文件名。
示例(1):

- -b, --byte-offset 在每一行输出之前,打印输入文件中每行基于0的字节偏移量。如果指定-o(--only-matching),则打印匹配部分本身的偏移量。
- 上下文行控制(Context Line Control)
- -A, --after-context=NUM 在匹配行之后打印尾随上下文NUM行(即打印匹配文本加上匹配文本结尾的NUM行)。在相邻匹配组之间放置包含组分隔符的行(在--group-separator中描述)。如果使用-o或--only-matching选项,则此项选无效,并给出警告。
示例(1):
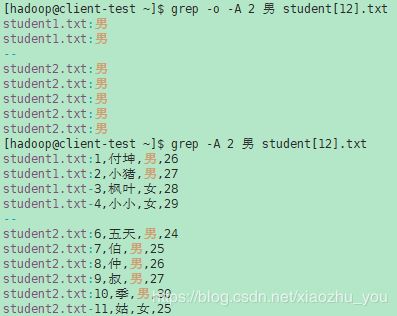
- -B NUM, --before-context=NUM 在匹配行之前打印前导上下文NUM行(即打印匹配文本加上匹配文本之前的NUM行)。在相邻匹配组之间放置包含组分隔符的行(在--group-separator中描述)。如果使用-o或--only-matching选项,则此项选无效,并给出警告。
示例(1):

- -C NUM, --context=NUM 打印输出上下文NUM行(即紧邻匹配文本上方NUM行加上匹配文本再加上紧邻匹配文本下方NUM行)。在相邻匹配组之间放置包含组分隔符的行(在--group-separator中描述)。如果使用-o或--only-matching选项,则没有效果,并给出警告。
示例(1):
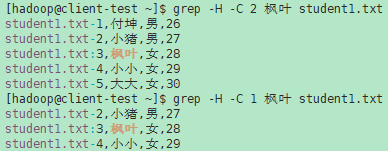
- --group-separator=SEP 使用SEP作为组分隔符。SEP默认为双连字符(--)
示例(1):
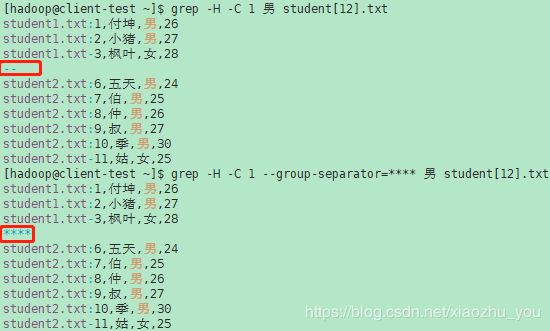
- --no-group-separator 使用空字符作为组分隔符。
- -A, --after-context=NUM 在匹配行之后打印尾随上下文NUM行(即打印匹配文本加上匹配文本结尾的NUM行)。在相邻匹配组之间放置包含组分隔符的行(在--group-separator中描述)。如果使用-o或--only-matching选项,则此项选无效,并给出警告。
- 文件和目录选择(File and Directory Selection)
- -a, --text 像处理文本(text)一样处理二进制文件;这相当于--binary-files=text
- --binary-files=TYPE 如果文件的前几个字节表示该文件包含二进制数据,则假定该文件的类型为TYPE。默认情况下,TYPE是 binary,grep通常输出一行消息,说明二进制文件匹配,如果没有匹配,则不输出消息。如果TYPE 是 without-match,则grep假定二进制文件不匹配;这等价于-I选项。如果TYPE是text,grep处理二进制文件时就像处理文本一样;这等价于-a选项。警告:grep --binary-files=text可能输出二进制垃圾,如果输出是终端,并且终端驱动程序将其中一些解释为命令,则可能会产生严重的副作用。
- -D ACTION, --devices=ACTION 如果输入文件是设备,FIFO或套接字,则使用ACTION来处理它。默认情况下,ACTION是read,这意味着读取设备时就像读取普通文件一样。如果ACTION是skip,设备将被无声地跳过。
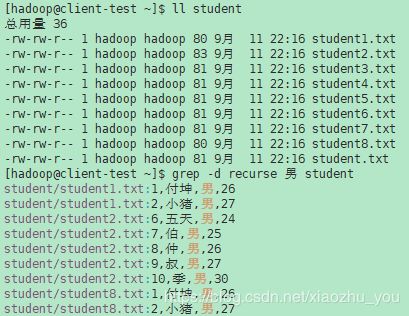
- -d ACTION, --directories=ACTION 如果输入文件是一个目录,则使用ACTION来处理它。默认情况下,ACTION是read,即,就像读取普通文件一样读取目录。如果ACTION是skip,则默默地跳过目录。如果ACTION是recurse,则仅当符号链接位于命令行上时,才递归地按照符号链接读取每个目录下的所有文件。这等价于-r选项。
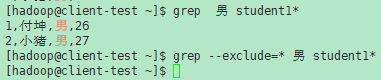
- --exclude=GLOB 跳过基本名称与GLOB(使用通配符匹配)匹配的文件。文件名glob可以使用*、?和[…]作为通配符,并使用\按字面意思引用通配符或反斜杠字符。
示例(1):
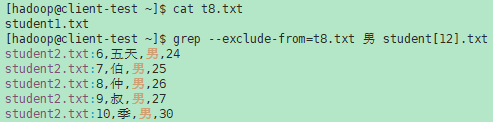
- --exclude-from=FILE 跳过基本名称与从FILE(使用通配符匹配,如--exclude中描述的那样)中读取的任何文件名称全局变量匹配的文件。
示例(1):
- --exclude-dir=DIR 从递归搜索中排除与模式DIR匹配的目录。
示例(1):
- -I 处理二进制文件,好像它不包含匹配的数据;这相当于--binary-files= without-match选项
- --include=GLOB 只搜索基本名称与GLOB(使用通配符匹配,如--exclude中描述的那样)匹配的文件。
示例(1):
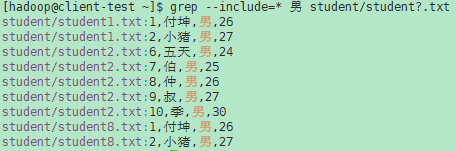
- -r, --recursive 仅当符号链接位于命令行上时,递归地按照符号链接读取每个目录下的所有文件。这等价于-d recurse 选项。
示例(1):
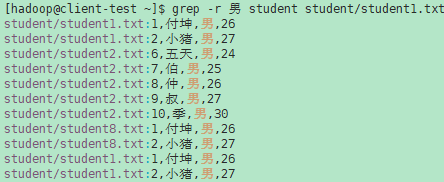
- -R, --dereference-recursive 递归地读取每个目录下的所有文件。遵循所有符号链接,不像-r。
- 其它选项 (Other Options)
- --line-buffered 对输出使用行缓冲。这可能会导致性能损失。
- -U, --binary 将文件视为二进制文件。默认情况下,在MS-DOS和MS-Windows下,grep通过查看从文件中读取的第一个32KB的内容来猜测文件类型。如果grep确定该文件是文本文件,它将从原始文件内容中删除CR字符(以使带^和$的正则表达式正确工作)。指定-U会推翻这种猜测,导致所有文件都被逐字读取并传递给匹配机制;如果文件是文本文件,每一行末尾都有CR/LF对,这将导致一些正则表达式失败。这个选项对MS-DOS和MS-Windows以外的平台没有影响。
- -z, --null-data 将输入视为一组行,每一行以零字节(ASCII NUL字符)而不是换行结束。与-Z或--null选项一样,这个选项可以与sort -Z之类的命令一起使用,以处理任意文件名。