自下而上和自上而下的注意力模型《Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering》
本文有点长,请耐心阅读,定会有收货。如有不足,欢迎交流, 另附:论文下载地址
一、文献摘要介绍
Top-down visual attention mechanisms have been used extensively in image captioning and visual question answering (VQA) to enable deeper image understanding through fifine-grained analysis and even multiple steps of reasoning. In this work, we propose a combined bottom-up and top-down attention mechanism that enables attention to be calculated at the level of objects and other salient image regions. This is the natural basis for attention to be considered. Within our approach, the bottom-up mechanism (based on Faster R-CNN) proposes image regions, each with an associated feature vector, while the top-down mechanism determines feature weightings. Applying this approach to image captioning, our results on the MSCOCO test server establish a new state-of-the-art for the task, achieving CIDEr / SPICE / BLEU-4 scores of 117.9, 21.5 and 36.9, respectively. Demonstrating the broad applicability of the method, applying the same approach to VQA we obtain fifirst place in the 2017 VQA Challenge.
作者认为自上而下的视觉注意力机制已经广泛的应用于图像描述和视觉问答中,以通过细粒度分析,甚至推理多个步骤实现对图像的更深入理解。因此作者提出了一种自下而上和自上而下的组合注意力机制,使注意力可以在对象和其他显著图像区域的水平上进行计算。自下而上的机制(基于 Faster R-CNN)提出了图像区域,每个区域都具有关联的特征向量,而自上而下的机制决定了特征权重,作者还在2017年VQA挑战赛中获得了第一名,下面就让我们来剖析一下该框架吧。
二、网络框架介绍
2.1Bottom-Up Attention Model
给定一个图像  ,我们的图像描述模型和
,我们的图像描述模型和![]() 模型都将一组可变大小的
模型都将一组可变大小的  个图像特征
个图像特征![]() 作为输入,以使每个图像特征都进行编码图像的主要区域。空间特征
作为输入,以使每个图像特征都进行编码图像的主要区域。空间特征 可以定义自下而上的注意力模型的输出,也可以按照标准实践定义为
可以定义自下而上的注意力模型的输出,也可以按照标准实践定义为![]() 的空间输出层。
的空间输出层。
空间特征的定义是通用的。但是,在这项工作中,作者根据边界框定义了空间区域,并使用Faster R-CNN实现了自下而上的注意力模型,Faster R-CNN是一种对象检测模型,旨在识别属于某些类的对象实例,并使用边界框定位它们。其他区域推荐网络也可以作为一种关注机制进行培训。
Faster R-CNN检测对象分两个阶段。第一个阶段,称为区域推荐网络(Region Proposal Network,RPN),用来预测对象推荐。一个小网络在CNN的中间特征上滑动(作用是把每个滑动窗口映射到一个低维特征)。在每个空间位置,该网络都会为多个比例和纵横比的锚框预测与类无关的客观评分和边界框优化。使用贪婪非最大抑制和交并比(IoU)阈值,将顶部的推荐作为第二阶段的输入。在第二阶段,使用兴趣区域(RoI)合并为每个Box建议提取一个小的特征图(例如14×14)。 然后将这些特征图一起批处理,作为对CNN最终层的输入。 该模型的最终输出包括在类别标签上的softmax分布以及每个框提议的特定于类别的边界框优化。
在这项工作中,作者结合使用了Faster R-CNN和ResNet-101CNN。为了生成用于图像描述或VQA图像特征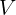 的输出集,我们获取模型的最终输出,并使用IoU阈值对每个对象类别执行非最大抑制。对于每个选定区域
的输出集,我们获取模型的最终输出,并使用IoU阈值对每个对象类别执行非最大抑制。对于每个选定区域  ,
,![]() 被定义为该区域的平均池化卷积特征,因此图像特征向量的维D为2048。以此方式使用,Faster R-CNN有效地起到了“硬”注意力机制,这是因为仅从大量可能的配置中选择了相对较少的图像边界框特征。
被定义为该区域的平均池化卷积特征,因此图像特征向量的维D为2048。以此方式使用,Faster R-CNN有效地起到了“硬”注意力机制,这是因为仅从大量可能的配置中选择了相对较少的图像边界框特征。
为了对自下而上的注意力模型进行预训练,我们首先用预训练好的ResNet-101初始化Faster R-CNN,以便在ImageNet上进行分类,然后我们对视觉基因组数据进行训练。帮助学习良好的特征表示,我们还添加了一个额外的训练输出,用于预测属性类(除对象类之外)。为了预测区域 的属性,我们将平均池化卷积特征与已学习的地面真实对象类嵌入在一起,并将其输入到附加输出层中,该输出层定义每个属性类上的![]() 分布以及"无属性类别"。
分布以及"无属性类别"。
原始的Faster R-CNN多任务损失函数包含四个组件,分别针对RPN和最终对象类建议在分类和边界框回归输出上定义。 我们保留了这些组件,并添加了一个额外的多类损失组件来训练属性预测器。下图,我们提供了模型输出的一些示例。

2.2 Captioning Model
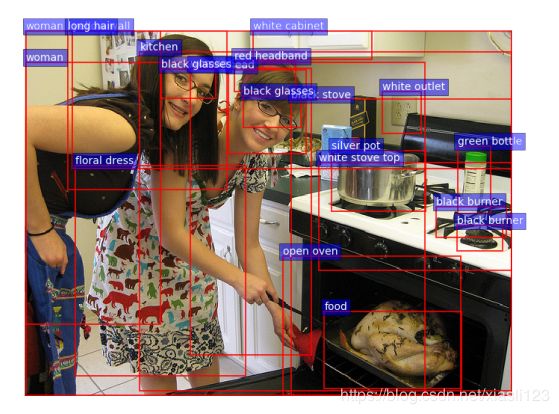
给定一组图像特征,作者提出的图像描述模型使用现有的部分输出序列作为上下文,使用"软"自上而下的注意力机制在描述生成过程中对每个特征进行加权。描述模型标准实现是由两个LSTM层组成,使用以下表示法在单个时间步上引用LSTM操作:
![]()
其中,![]() 是LSTM的输入向量,
是LSTM的输入向量,![]() 是LSTM的输出向量。在这里,为了符号上的方便,省略了记忆单元的传播。整个描述模型如下图所示。
是LSTM的输出向量。在这里,为了符号上的方便,省略了记忆单元的传播。整个描述模型如下图所示。
1.Top-Down Attention LSTM
在图像描述模型中,我们将第一个LSTM层描述为自上而下视觉注意力模型,第二个LSTM层描述为一个语言模型,在随后的方程式中用上标来指示每一层。在每个时间步长上注意力LSTM的输入向量均由语言LSTM的先前输出组成,并与均值池化图像特征![]() 以及先前生成的单词的编码连接,由下式给出:
以及先前生成的单词的编码连接,由下式给出:
![]()
其中,![]() 是词汇表
是词汇表![]() 的词嵌入矩阵,
的词嵌入矩阵,![]() 是时间步
是时间步  处输入单词的
处输入单词的 ![]() 编码。这些输入分别为注意力LSTM提供了有关语言LSTM的状态,图像的整体内容以及到目前为止生成的部分图像描述输出的最大上下文信息。 嵌入单词是从随机初始化中学习而无需预训练的。
编码。这些输入分别为注意力LSTM提供了有关语言LSTM的状态,图像的整体内容以及到目前为止生成的部分图像描述输出的最大上下文信息。 嵌入单词是从随机初始化中学习而无需预训练的。
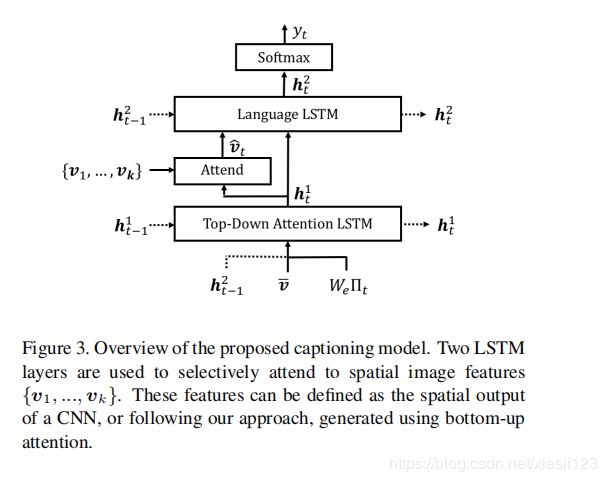
给定注意力LSTM的输出 ![]() ,在每个时间步 处,我们为k个图像特征
,在每个时间步 处,我们为k个图像特征 中的每一个都生成一个归一化注意力权重
中的每一个都生成一个归一化注意力权重![]() ,如下
,如下
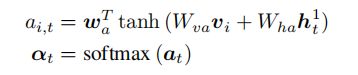
其中,![]() 和
和![]() 是学习参数。用所有输入特征的凸组合计算语言LSTM输入的注意力图像特征,如下所示:
是学习参数。用所有输入特征的凸组合计算语言LSTM输入的注意力图像特征,如下所示:

2.Language LSTM
语言模型LSTM的输入包含注意力图像特征和注意力LSTM的输出,由下式给出:
![]()
用符号![]() 指代单词序列
指代单词序列![]() ,在每个时间步 ,可能的输出词的条件分布有下式给出:
,在每个时间步 ,可能的输出词的条件分布有下式给出:
![]()
其中,![]() 和
和![]() 是可学习权重和偏差。在完全输出序列上的分布计算,为条件分布的乘积:
是可学习权重和偏差。在完全输出序列上的分布计算,为条件分布的乘积:

3.目标函数
给定一个目标地面真实序列 ![]() 和 带有参数
和 带有参数![]() 的图像描述模型,我们最小化以下交叉熵损失:
的图像描述模型,我们最小化以下交叉熵损失:

另外文章还用到了SCST中的强化学习方法来对CIDEr分数进行优化:

梯度可以被近似为:
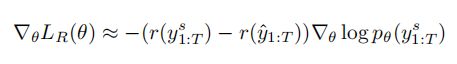
其中![]() 是强化学习中samlpe得到的caption,
是强化学习中samlpe得到的caption,![]() 是通过贪婪解码当前模型的基线分数。
是通过贪婪解码当前模型的基线分数。
2.3 VQA Model
给定一组空间图像特征,作者提出的VQA模型还使用"软"自上而下的注意力机制来加权每个特征,用问题表示作为上下文,模型如下图所示。

该模型实现了众所周知的问题和图像的联合多模嵌入,并对一组候选答案的分数进行了回归的预测。
网络内的学习非线性变换采用门控双曲正切(gated tanh)激活来实现的。我们的每个"门控 tanh"层都实现了一个函数![]() :
:
![]() ,参数
,参数 ![]() 定义如下:
定义如下:
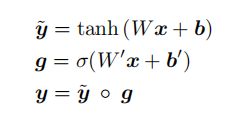
其中, 是
是![]() 激活函数,
激活函数,![]() 是可学习权重,
是可学习权重,![]() 是可学习偏差。
是可学习偏差。![]() 是逐元素乘积。向量
是逐元素乘积。向量![]() 的乘积作用为充当中间激活
的乘积作用为充当中间激活![]() 的门。
的门。
首先将每个问题编码为门控循环单元(GRU)的隐藏状态![]() ,其中每个输入单词都使用学习单词嵌入来表示。 给定GRU的输出
,其中每个输入单词都使用学习单词嵌入来表示。 给定GRU的输出![]() ,我们为
,我们为  个图像特征
个图像特征  中的每一个,生成未归一化的关注权重
中的每一个,生成未归一化的关注权重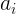 ,如下所示:
,如下所示:
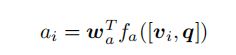
其中,![]() 是一个可学习的参数向量。而normalized attention weight
是一个可学习的参数向量。而normalized attention weight ![]() 和attended image feature
和attended image feature ![]() 就以caption 部分的方式计算。输出的相应
就以caption 部分的方式计算。输出的相应 的分布由下式给出:
的分布由下式给出:

其中,![]() 是问题和图像的联合表示,
是问题和图像的联合表示,![]() 是可学习权重。由于篇幅限制,文章没有给出更多的VQA模型的细节,更多细节详见Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challenge
是可学习权重。由于篇幅限制,文章没有给出更多的VQA模型的细节,更多细节详见Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challenge
关键代码如下:
#---------注意力的计算-------------
class Attention(nn.Module):
def __init__(self, v_dim, q_dim, num_hid):
super(Attention, self).__init__()
self.nonlinear = FCNet([v_dim + q_dim, num_hid])
self.linear = weight_norm(nn.Linear(num_hid, 1), dim=None)
def forward(self, v, q):
"""
v: [batch, k, vdim]
q: [batch, qdim]
"""
logits = self.logits(v, q)
w = nn.functional.softmax(logits, 1)
return w
def logits(self, v, q):
num_objs = v.size(1)
q = q.unsqueeze(1).repeat(1, num_objs, 1)
vq = torch.cat((v, q), 2)
joint_repr = self.nonlinear(vq)
logits = self.linear(joint_repr)
return logits
class BaseModel(nn.Module):
def __init__(self, w_emb, q_emb, v_att, q_net, v_net, classifier):
super(BaseModel, self).__init__()
self.w_emb = w_emb
self.q_emb = q_emb
self.v_att = v_att
self.q_net = q_net
self.v_net = v_net
self.classifier = classifier
def forward(self, v, b, q, labels):
"""Forward
v: [batch, num_objs, obj_dim]
b: [batch, num_objs, b_dim]
q: [batch_size, seq_length]
return: logits, not probs
"""
w_emb = self.w_emb(q)
q_emb = self.q_emb(w_emb) # [batch, q_dim]
#---------特征的融合和答案的预测-------------
att = self.v_att(v, q_emb)
v_emb = (att * v).sum(1) # [batch, v_dim] 得到的V^
# 问题(q)和图像的表示(vˆ)通过非线性层
q_repr = self.q_net(q_emb)
v_repr = self.v_net(v_emb)
# 然后逐元素乘积进而融合特征
joint_repr = q_repr * v_repr
logits = self.classifier(joint_repr) # 分类
return logits
三、实验分析
作者使用Visual Genome 数据集来预训练自下而上的注意力模型,并在训练VQA模型时进行数据增强。 数据集包含108K张图像,并用包含对象,属性和关系的场景图进行了密集注释,以及170万个视觉问题。整体上的 图像描述(image caption)和视觉问答(VQA)都是当时state-of-the-art的,论文对图像描述进行了详细的分析,视觉问答分析较少,下图是image caption性能表现:
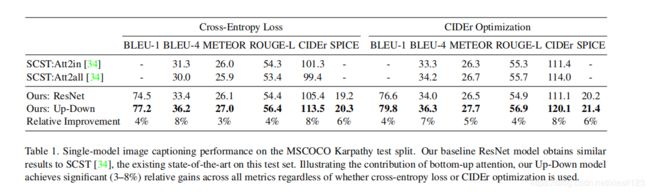
作者选取了只有up-down的attention机制的ResNet作为基准模型(baseline),来代替bottom-up attention机制,可以看到,无论有没有加CIDEr的强化学习训练、有没有使用bottom-up机制,本文的模型都比SCST的方法要好。而且SCST是从4个随机初始化的模型里面选了一个最好的,而本文这里的对比就只用了一个模型。
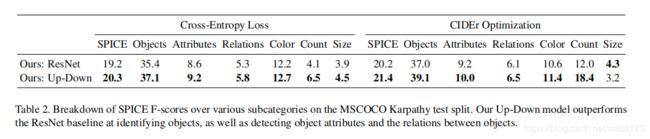
下图展示了up-down模型各个方面比基准模型ResNet都优越。
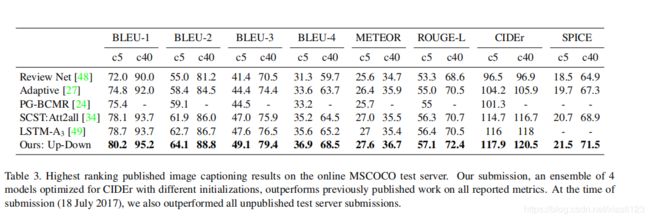
图像描述模型与其他方法也表现出高性能。
视觉问答(VQA)模型与其他方法也表现出高性能。

对于每个生成的单词,作者将注意力权重可视化,如下图所示。

VQA模型的可视化。

四、结论
We present a novel combined bottom-up and top-down visual attention mechanism. Our approach enables attention to be calculated more naturally at the level of objects and other salient regions. Applying this approach to image captioning and visual question answering, we achieve state-of-the-art results in both tasks, while improving the interpretability of the resulting attention weights.
At a high level, our work more closely unififies tasks involving visual and linguistic understanding with recent progress in object detection. While this suggests several directions for future research, the immediate benefifits of our approach may be captured by simply replacing pretrained CNN features with pretrained bottom-up attention features.
作者提出了一种新的自下而上和自上而下的视觉注意机制,直接的好处就是用预训练好的自下而上的注意力特征代替预训练好的CNN特征。个人理解自上而下注意力就是利用目标检测技术(Faster R-CNN)在物体层面从面到点attention, 而自上而下注意力就是从点到面的角度进行attention。