从Transformers学习跨模态编码器表示《LXMERT: Learning Cross-Modality Encoder Representations from Transformers》
目录
一、文献摘要介绍
二、网络框架介绍
三、实验分析
四、结论
这是视觉问答论文阅读的系列笔记之一,本文有点长,请耐心阅读,定会有收货。如有不足,随时欢迎交流和探讨。
一、文献摘要介绍
Vision-and-language reasoning requires an understanding of visual concepts, language semantics, and, most importantly, the alignment and relationships between these two modalities. We thus propose the LXMERT (Learning Cross-Modality Encoder Representations from Transformers) framework to learn these vision-and-language connections. In LXMERT, we build a large-scale Transformer model that consists of three encoders: an object relationship encoder, a language encoder, and a cross-modality encoder. Next, to endow our model with the capability of connecting vision and language semantics, we pre-train the model with large amounts of image-and-sentence pairs, via fifive diverse representative pre-training tasks: masked language modeling, masked object prediction (feature regression and label classification), cross-modality matching, and image question answering. These tasks help in learning both intra-modality and cross-modality relationships. After fine-tuning from our pretrained parameters, our model achieves the state-of-the-art results on two visual question answering datasets (i.e., VQA and GQA). We also show the generalizability of our pretrained cross-modality model by adapting it to a challenging visual-reasoning task, NLVR2, and improve the previous best result by 22% absolute (54% to 76%). Lastly, we demonstrate detailed ablation studies to prove that both our novel model components and pretraining strategies significantly contribute to our strong results; and also present several attention visualizations for the different encoders.
作者认为视觉和语言推理需要理解视觉概念,语言语义,最重要的是,这两种方式之间的对齐和关系。因此,我们提出了LXMERT(从Transformer学习跨模态编码器表示)框架来学习这些视觉和语言联系。在LXMERT中,我们建立了一个大型的Transformer模型,该模型由三个编码器组成:对象关系编码器,语言编码器和交叉模式编码器。接下来,为了使我们的模型具有连接视觉和语言语义的能力,我们通过五种多样的代表性预训练任务对模型进行了大量的图像和句子对训练:masked语言建模,masked对象预测(特征回归和标签分类),跨模态匹配和图像问题解答。这些任务有助于学习模态内和模态间的关系。在对我们的预训练参数进行微调之后,我们的模型在两个视觉问题回答数据集(即VQA和GQA)上获得了最新的结果。我们还通过将我们的预训练交叉模式模型适应于具有挑战性的视觉推理任务NLVR2来展示其可推广性,并将以前的最佳结果提高了22%的绝对值(54%至76%)。最后,我们展示了详细的消融研究,以证明我们新颖的模型组件和预训练策略均对我们的强劲成果做出了重要贡献;并提供了针对不同编码器的几种注意力可视化图。
二、网络框架介绍
2.1 Input Embeddings
一个句子首先被分成几个词![]() 长度为n。接下来,如图1所示,通过嵌入子层将单词
长度为n。接下来,如图1所示,通过嵌入子层将单词![]() 及其索引
及其索引 (
(![]() 在句子中的绝对位置)投影到向量,然后添加到索引感知单词嵌入中:
在句子中的绝对位置)投影到向量,然后添加到索引感知单词嵌入中:

具体地说,对象检测器检测来自图像的m个对象![]() (由图1中图像上的边框表示)。每个对象
(由图1中图像上的边框表示)。每个对象![]() 由其位置特征(即边界框坐标)
由其位置特征(即边界框坐标)![]() 和其2048维感兴趣区域(RoI)特征
和其2048维感兴趣区域(RoI)特征![]() 表示。我们没有直接使用RoI特征
表示。我们没有直接使用RoI特征![]() 而不考虑其位置
而不考虑其位置![]() ,而是通过添加2个全连接层的输出来学习位置感知嵌入
,而是通过添加2个全连接层的输出来学习位置感知嵌入![]() :
:
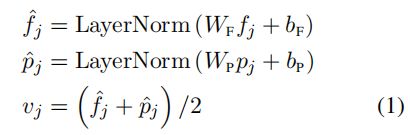

除了在视觉推理中提供空间信息外,位置信息的包含对于我们的masked目标预测预训练任务是必要的,因为图像嵌入层和随后的注意层对其输入的绝对指数是不可知的,所以没有指定对象的顺序。最后,在方程1中,在求和之前对投影特征进行层归一化,以平衡两种不同类型特征的能量。
2.2. Encoders
我们构建了编码器,即语言编码器、对象关系编码器和交叉模式编码器,主要基于两种注意层:自我注意层和交叉注意层。
单模态编码 在嵌入层之后,我们首先应用两个转换器编码器,即语言编码器和对象关系编码器,并且每一个编码器仅关注于单一模态(即语言或视觉)。与仅将Transformer编码器应用于语言输入的BERT不同,我们也将其应用于视觉输入(以及下文所述的跨模态输入)。单个模态编码器中的每个层(图1中的左侧虚线框)都包含一个自我注意('Self')子层和一个前馈('FF')子层,其中前馈子层进一步由两个完全连接的子层组成。我们分别在语言编码器和对象关系编码器中采用![]() 和
和![]() 层。 我们在每个子层之后添加一个残差连接和层归一化(在图1中用“ +”符号表示)。
层。 我们在每个子层之后添加一个残差连接和层归一化(在图1中用“ +”符号表示)。
跨模态编码 交叉模态编码器中的每个交叉模态层(图1中的右侧虚线框)均由两个自注意子层,一个双向交叉注意子层和两个前馈子层组成。在我们的编码器实现中,我们将这些交叉模态层叠加(即,使用第k层的输出作为第(k + 1)层的输入)。在第k层内部,首先应用了双向交叉注意子层(“交叉”),该子层包含两个单向交叉注意子层:一个从语言到视觉,另一个从视觉到语言。查询和上下文向量是第(k-1)层的输出(即语言特征![]() 和视觉特征
和视觉特征![]() ):
):

交叉注意子层用于交换信息和对齐两种模式之间的实体,以学习联合的交叉模式表示。为了进一步建立内部连接,然后将自关注子层(“self”)应用于交叉关注子层的输出:
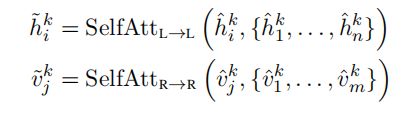
最后,第k层输出![]() 和
和![]() 由
由![]() 和
和![]() 顶部的前馈子层(FF)产生。 我们还在每个子层后添加了残差连接和层归一化,类似于单模态编码器。
顶部的前馈子层(FF)产生。 我们还在每个子层后添加了残差连接和层归一化,类似于单模态编码器。
2.3 Output Representations
如图1的最右侧所示,LXMERT跨模态模型分别具有针对语言,视觉和跨模态的三个输出。 语言和视觉输出是由交叉模式编码器生成的特征序列。 对于跨模态输出,我们在句子单词之前附加一个特殊标记[CLS](在图1的底部分支中表示为顶部黄色块),并且该特殊标记在语言特征序列中的对应特征向量为 用作交叉模式输出,图2展示LXMERT的预训练。
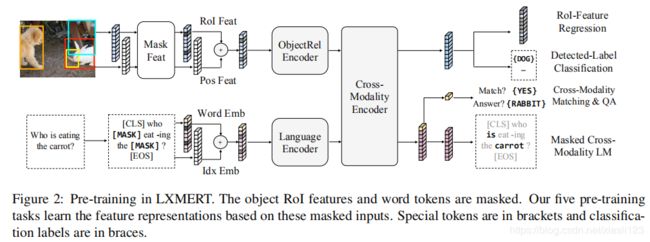
三、实验分析
在VQA和GQA上,从预先训练中微调了模型,而没有数据扩充。 在训练GQA时,我们仅将原始问题和原始图像作为输入,而不使用其他监督,然后根据两个交叉模式输出的串联训练分类器。
表1:训练前的数据量。
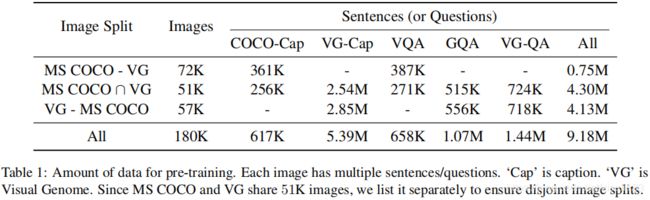
表2:测试集结果。

表3:使用BERT的Dev-set精度

表4:Dev-set精度显示图像-QA预训练任务的重要性

表5:不同视觉预训练任务的Dev-set精度。
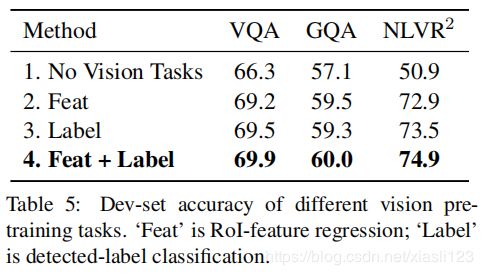
图3 可视化注意力图
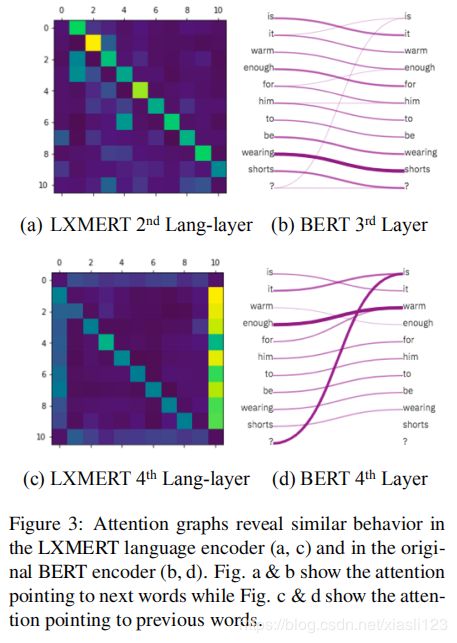
图4:LXMERT对象关系编码器第一层的注意图(A)及其恢复的场景图(B)。

图5:LXMERT交叉模态编码器中的注意力图显示,注意力集中在代词(用粉红色标记)、名词(用蓝色标记)和冠词(用红色标记)。
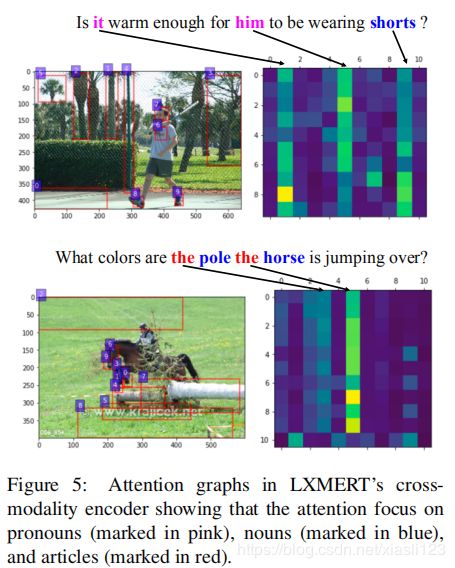
四、结论
We presented a cross-modality framework, LXMERT, for learning the connections between vision and language. We build the model based on Transfermer encoders and our novel cross-modality encoder. This model is then pre-trained with diverse pre-training tasks on a large-scale dataset of image-and-sentence pairs. Empirically, we show state-of-the-art results on two image QA datasets (i.e., VQA and GQA) and show the model generalizability with a 22% improvement on the challenging visual reasoning dataset of NLVR2 . We also show the effectiveness of several model components and training methods via detailed analysis and ablation studies.
作者提出了一个跨模式框架LXMERT,用于学习视觉和语言之间的联系。 基于Transfermer编码器和新颖的交叉模态编码器构建模型。 然后在图像和句子对的大规模数据集上使用各种预训练任务对该模型进行预训练。
本文实现的效果和Deep Modular Co-Attention Networks for Visual Question Answering实现的方法差不多,很相似,都是借鉴了Transforms的Encoder和Decoder方法,自注意和问题引导注意力,达到的效果还是不错的。值得阅读。