自用型监控系统方案设计
一、监控系统整体概述
系统背景:
在当前项目中,当我们对特定流程注入故障后,如何评估故障的效果以及系统应对故障的表现?传统方式是用户需要登录线上机器或者各种监控系统去查看具体的指标信息,然后通过人工判断,来判断故障的影响范围,产品使用上不够自动化,且没有闭环。我们期望引入监控系统,把之前需要人来做的事情交给系统来做,为故障注入后的影响进行量化分析。
整个监控系统对数据处理的四个步骤:
系统架构图:
组件说明:
API Gateway:agent 与 Server 所有交互都会通过API Gateway,统一由API Gateway进行管控,为整个MK提供一致的数据门面接口,实现之前约定的数据总线的方案。
Data Collector:为数据采集器,接受来自客户端推送上来的监控数据 或 拉去外部监控数据;
Data Transfer: 数据转换器,把采集到的非一致性架构的数据转换为统一的数据模型;
Config: 此模块主要提供一些Agent、Collector、Analyzer需要的一些元数据;
Schedule: 依赖Schedule,主要是期望能把周期性数据拉取采集任务转换为 schedule任务,降低重复编写分布式任务调度的复杂度,其次,借助schedule实现周期任务分发的负载均衡;
Diamond:采用Diamond作为数据采集规则的动态配置中心。
MQ: 把数据采集器采集到的数据转换为统一的消息格式,解耦数据采集与数据分析对数据使用差异性;其次,当数据分析器Data Analyzer集群宕机或处理性能下降时,MQ能起到数据缓存池的作用,一定程度上防止采集上来的数据未能处理而导致的数据丢失。
Data Analyzer: 数据分析器,对收集到的监控数据进行一定程度上的计算转换,并根据关注点规则,进行事件监控处理;
自研监控系统,需要面临一系列的抉择: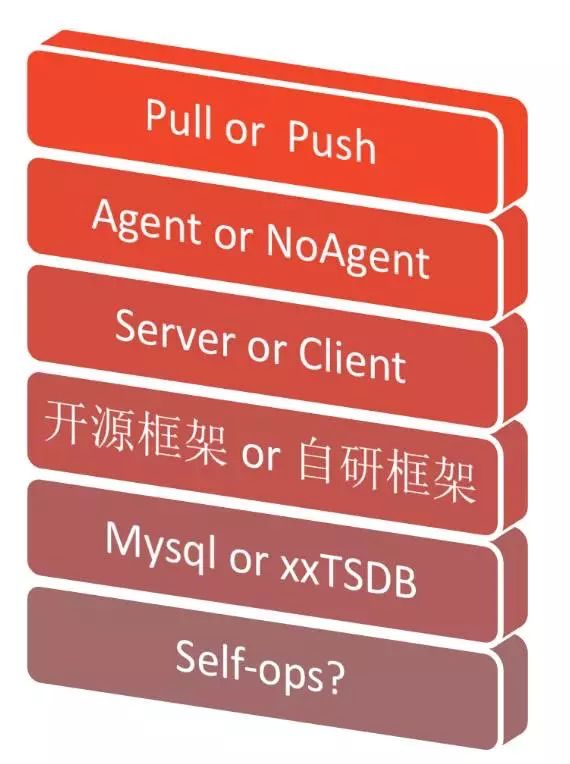
二、行业监控系统架构:
ONEAPM

CAT

参考:https://tech.meituan.com/CAT_in_Depth_Java_Application_Monitoring.html
三、数据采集方案
数据采集面的的挑战:
- 数据源多种多样
- 数据量大
- 变化快
- 如何保证数据采集的可靠性的性能
- 如何避免重复数据
- 如何保证数据的质量
3.1 采集方案
目前常用的数据采集方式有两种:
- 主动监控(客户端推模式-Push);
- 优势:
- 实时性好;
- 对服务端的压力相对较小;
- 插件化支持用户自定义采集脚本;
- 监控自动发现;
- 劣势:
- 数据聚合与异常处理复杂;
- 优势:
- 被动监控(服务端拉模式-Pull);
- 优势:
- 数据处理方便;
- 数据准确性、完备性更好;
- Edas已经存在根据staragent进行数据拉去的实践方案;
- 劣势:
- 集群规模大时,服务器压力大,任务分发易积压,分发线程忙,带来一定数据延迟;
- 数据拉取时服务隔离难(twitter);
- 无法区分服务失效和代理失效(twitter);
- 优势:
现有监控系统采集方案:
| 系统 | 采集方式 | 备注 |
|---|---|---|
| AliMonitor | Push | |
| Ali-Sunfire | Pull | |
| TLog | Pull | |
| aliyun-sls-ilogtail | Push | |
| Zabbix | push+pull | |
| Open-falcon | Push | |
| OneAPM | Push | |
| Cacti | Pull |
主动监控示意图(Push):
服务端提供一个接受数据请求的域名地址,客户端把数据推送到服务端,服务端负责数据解析与存储;
被动监控示意图(Pull):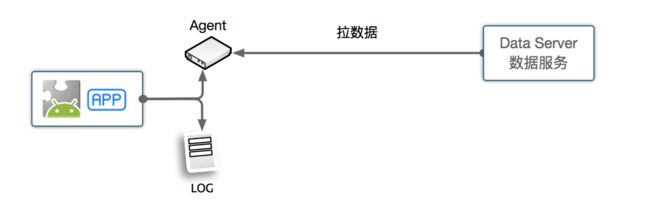
Agent一般具备的功能:
- LogFinder: 能够根据请求的时间区间返回区间内的监控数据;
- LogQuery: 能够根据偏移量定位到日志位置;
- LogCompression: 支持日志数据压缩;
此部分可以参考LogAgent的实现逻辑。
我们的需求:
- 轻量级;
- 可扩展;
- 支持系统监控(OS)、业务监控(Agent)
- 支持Agent自动注册以及静态数据主动上报;
- 监控项受控开启与关闭,具备开关功能(非常态化挂载);
- 需要具备数据堆积能力;
- 需要具备多数据源扩展能力;
方案结论:
客户端通过写本地磁盘日志的方式写指标数据,服务端通过 主动拉的方式到客户端上进行拉去数据;
3.2 分布式任务调度
我们采用服务端拉去日志的方式,所以需要一套对多个节点进行周期性调度拉取日志的框架。目前分布式定时调度服务阿里集团内有scheduleX以及开源的Quartz,考虑到服务单独输出减少依赖组件的需求,对Quartz的分布式持久化任务整合工作量评估后, 我们选择了使用quartz的方式。目前spring有对quartz进行整合,简化对quartz的使用。
不仅在监控数据采集上需要调度,在演练定时触发、演练监控定时开启等场景下都需要分布式任务调度服务,所以提供一套通用型的与业务无关的分布式调度服务API很有必要。
基于spring-quartz进行接口封装出统一的分布式调度服务接口服务SchedulerService, 这部分是单独的一个模块。
3.3 数据Metric指标
客户端打印的日志非Metric格式,通过日志数据采集上来的数据需要通过转换器Transfer进行转换为统一的Metric格式;
当前监控系统采集的数据指标分为两类:
- 系统OS监控指标;
- 应用性能指标;
系统监控指标Metric含义:
| category | Metric | Type | Tag | Description |
|---|---|---|---|---|
| cpu | system.cpu.idle | GAUGE | host | |
| system.cpu.system | GAUGE | host | ||
| system.cpu.user | GAUGE | host | ||
| system.cpu.util | GAUGE | host | cpu使用率 | |
| load | system.load.1min | GAUGE | host | |
| system.load.5min | GAUGE | host | ||
| system.load.15min | GAUGE | host | ||
| mem | system.mem.buffers | GAUGE | host | 当前系统的buffer cache的内存数(单位kb) |
| system.mem.cached | GAUGE | host | 当前系统的pagecache里的内存数(单位kb) | |
| system.mem.free | GAUGE | host | 当前系统的空闲内存(单位kb) | |
| system.mem.total | GAUGE | host | 当前系统的总内存(单位kb) | |
| system.mem.used | GAUGE | host | 当前系统的已经使用的内存(单位kb) | |
| system.mem.util | GAUGE | host | 当前系统的已经使用的内存占比 | |
| disk.partition | system.disk.partition.total | GAUGE | host、device | 当前系统的磁盘总字节数 |
| system.disk.partition.free | GAUGE | host、device | 当前系统的磁盘空闲字节数 | |
| system.disk.partition.used | GAUGE | host、device | 当前系统的磁盘使用字节数 | |
| system.disk.partition.used_ratio | GAUGE | host、device | 当前系统的磁盘使用率 | |
| disk.io | system.disk.io.read_merge | GAUGE | host、device | 每秒合并读完成次数 |
| system.disk.io.write_merge | GAUGE | host、device | 每秒合并写完成次数 | |
| system.disk.io.read | GAUGE | host、device | 每秒读完成次 | |
| system.disk.io.write | GAUGE | host、device | 每秒写完成次数 | |
| system.disk.io.util | GAUGE | host、device | io占比 | |
| processs | system.process.switches | GAUGE | host | |
| system.process.total | GAUGE | host | ||
| traffic | system.net.in.bytes | GAUGE | host | |
| system.net.out.bytes | GAUGE | host | ||
| system.net.in.packets | GAUGE | host | ||
| system.net.out.packets | GAUGE | host | ||
| system.net.packet.errs | GAUGE | host | ||
| system.net.packet.dropped | GAUGE | host | ||
| tcp | system.tcp.active_opens | GAUGE | host | 最近1min平均每秒主动建连的连接数 |
| system.tcp.passive_opens | GAUGE | host | 最近1min平均每秒被动建连的连接数 | |
| system.tcp.current_estab | GAUGE | host | 最近1min平均每秒处于ESTABLISHED和CLOSE-WAIT状态的TCP连接数 | |
| system.tcp.estab_resets | GAUGE | host | 最近1min平均每秒reset次数 | |
| system.tcp.out_segs | GAUGE | host | 最近1min平均每秒发送的tcp包数量 | |
| system.tcp.in_segs | GAUGE | host | 最近1min平均每秒接收到的tcp包数量 | |
| system.tcp.attempt_fails | GAUGE | host | 最近1min平均每秒建连失败次数 | |
| system.tcp.retran_segs | GAUGE | host | 最近1min平均每秒重传的包数量 | |
| udp | system.udp.in_dgm | GAUGE | host | 收到的udp报数目 |
| system.udp.out_dgm | GAUGE | host | 发送的udp报数目 | |
| system.udp.noport | GAUGE | host | udp协议层接收到目的地址或目的端口不存在的数据包 | |
| system.udp.in_errs | GAUGE | host | udp层接收到的无效数据包的个数 |
应用性能监控指标Metric含义:
| category | Metric | Type | Tag | Description |
|---|---|---|---|---|
| servlet | app.servlet.request.count | COUNTER | host、transaction,device | 时间区间内,请求总次数 |
| app.servlet.request.durations | COUNTER | host、transaction,device | 时间区间内,请求总时间 | |
| app.servlet.request.rt.mean | GAUGE | host、transaction,device | 请求的平均rt | |
| app.servlet.request.rt.max | GAUGE | host、transaction,device | 请求的最大rt | |
| app.servlet.request.rt.min | GAUGE | host、transaction,device | 请求的最小rt | |
| app.servlet.request.error_count | COUNTER | host、transaction,device |
其中device存储agentId,transaction存储请求名称;
Metric命名规范
key和tag只支持:[a-z][A-Z][0-9][-_./], 不能有空格, 大小写敏感, key原则上不包含大写。
格式为xxx.category[.sub_category]*, category和sub_category里面如果有多个单词,用下划线’_’连接, 不要用’.’连接。
需要动态聚合的维度, 放在tag里面, 同时在tagKey也在key中体现。 不需要聚合的维度, 放在key里面。
3.4 数据转换transfer
针对不同类型的类型,采用工厂方法提供自适配的解析器。针对system系统监控,继续拆分为领域适配器,比如针对CPU域、mem域提供不同的处理方式。
1 2 3 4 5 6 7 8 9 10 |
public interface MetricTransfer extends Transfer {
/**
* format data to metric list
*
* @param sourceData
* @return
*/
List |
四、数据分析方案
4.1 分析方案:
现有的监控系统数据分析模块主要分为两类:
- 批处理模型;
- 流处理模型(Spark Streaming、Storm、Flink);
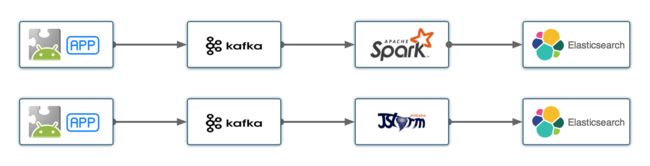
结论:考虑到我们要求部署节点少、拓扑简单以及本期研发周期时间紧,我们采暂且不采用流式处理方案,数据获取到后,直接给到后端进行分析处理;
4.2 监控点分析:
用户可以通过配置监控指标,来对关心的系统指标进行阈值判断,比如选择一批机器,关注CPU利用率超过90%,那么监控系统就需要把这批机器在演练期间CPU利用率超过90%的指标都找出来,并转换为Event事件。这点类似于监控系统中的报警系统模型。
数据分析器中处理监控指标的流程如下:
流程分析:
每一个Data Analyzer模块中都会包含一个Rule Set集合,Rule Set集合存放着生效后的关注点规则,在监控数据到达分析引擎中后,分析引擎通过filter机制,判断是否命中规则,如果命中规则,则根据规则与数据形成一条Event 事件数据,用于描述某次监控指标命中了监控指标阈值。后续复盘时,可以对Event 库中的指标事件进行聚合分析,形成需要的结论报告。
规则注册与更新机制:
关注点规则为内存数据集,当用户在界面是哪个新增了规则或者变更了规则的时候,都需要对内存中维护的这份规则集合进行修改操作。
规则存储:
当前规则为内存存储方式,在系统启动时从数据库中进行load全量有效关注点指标;带来的影响每一台机器都需要在内存中维护一份数据,如果某台机器数据更新失败,会带来数据的一致性问题,后续会考虑这部分数据移动到公共的外部快速存储设备中,比如Redis中。
数据模型:
我们把用户配置的关注点在系统指标上的阈值简称为“告警”,告警条件的判断以及存储流程中,主要涉及的领域模型为:Hosts、Metrics、triggers、functions、items、events、actions;
- hosts: 存储被监控的主机信息;
- metrics:存储监控到的数据指标;
- items: 存储支持的监控项配置信息。
- triggers:存储触发器的相关信息;
- events: 存储事件数据;
- actions:存储当触发器触发时,需要采取的动作(不再本期研发范围内);
触发器计算模型:
我们的需求是:监控某个关注对象下的某类监控指标下的特定聚合函数值 是否超过(也可能是其它运算符)某个固定阈值;那么我们把需求中拆解出几个对象出来,分别是:监控对象、监控指标、聚合函数、运算符、固定阈值,我们通过这几个对象的组合,可以对我们的意图进行对象化描述,表达式函数格式如下:
{:.()}
计算模型举例:
关注点描述为: 11.23.45.67 这台机器的 最近十分钟 load 指标 大于2 , 那么 表达式函数为:
{11.23.45.67:system.cpu.load.last(10m)} > 2
触发器中的聚合函数:
- max 最大值
- min 最小值
- avg 平均值
数据模型:
在监控指标分析域中涉及到的领域模型对象为:
- items
- triggers
- events
- actions
数据模型以及关联关系如下:
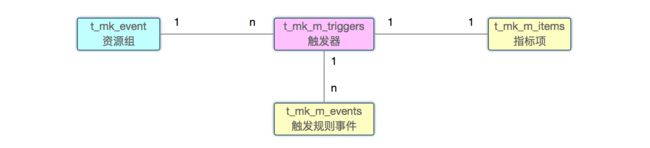
资源组与触发器为1:n的关系,监控项与触发器为1:1关系,触发器与事件为1:1关系;
五、数据存储方案
5.1 数据分类:
我们把数据类型分为五类:
- Metric指标数据(分为服务器和容器)
- 定义:metric描述一个指标在某个时间点的值是多少,可以使用tag来进行元数据标记划分;比如OS的系统监控指标;
- Event 事件数据(包括:系统、Docker数据采集)
- 定义:event记录系统在特定时刻下发生的具体信息,比如规则下发、故障启停、MkKit安装与卸载、Metric触发规则配置产生的事件等;
- Log 运行时日志数据
- 定义:event数据可以根据业务需求打上tag便于分析时筛选,统计,text中记录事件丰富上下文信
- Heartbeat 心跳数据
- 定义:定期执行的状态汇报,比如agent的心跳信息,进程的状态等;
- Trace 数据
- 定义:记录故障注入请求trace的信息;
5.2 数据存储方案:
监控数据是时间序列的数据,由于监控的对象数量巨大,所以存储的介质需要支持高的写入吞吐量,良好的扩充性,读取最近的数据速度要快,支持多数据类型,支持多种扫描方式等特点,目前主要的存储方式有SQL和NoSQL两种。通过对比,NoSQL在数据存储吞吐量,扩充性等方面具有优势,SQL在数据类型的支持,扫描多样性具有优势。
总而言之,监控数据更适合采用时序性存储媒介,比如OpenTSDB、HiTSDB等;考虑到种种原因,我们临时使用 Mysql,Mysql 能在一定程度上简化我们架构,让业务跑的更快一些。
不压缩的情况下:100台机器同时采集长达30天,占用空间49G;(单条1kb计算,5秒存储一次)。
5.3 行业常用存储方案
Cassandra
InfluxDB
MongoDB
OpenTSDB
KairosDB
HBase
5.4 监控指标存储规范
遵循metric规范;
一个metric由两部分组成,metric key和metric tag:
- metric key:它是用英文点号分隔的字符串,用来表征这个指标的含义
- metric tag:它定义了这个指标的不同切分维度,可以是单个,也可以是多个
- tag key: 用于描述维度的名称
- tag value: 用于描述维度的值
Metric的数据格式如下:
- metric key:存储当前指标的key
- metric tag:存储当前指标的tag
- metric value:存储当前指标的值
- timestamp:存储当前的时间戳
- metadata:存储当前指标的一些元信息
在Metric规范下,针对云上的多租户设计,我们增加了两个字段namespace、scope,用来对metric进行分类,一个是从用户角度进行划分,一个是从功能集角度划分,形成 MetricObject 对象属性描述如下:
| 字段 | 类型 | 描述 | 是否必填 |
|---|---|---|---|
| namespace | String | 命名空间,用于区分不同租户,存储userId | 必填 |
| scope | String | 范围,比如system、jvm、hsf、servlet等 | 必填 |
| metric | String | 指标Key | 必填 |
| metricType | MetricType | 指标类型 | 必填 |
| tags | map |
附加信息,当前只支持内置tag,不支持用户自定义tag(原因是采用mysql而不是nosql) | 必填,遵循OpenTSDB规范,至少要求有一个Tag |
| timestamp | Long | 时间戳 | 必填 |
| value | Double | 指标值 | 必填 |
举例:
1 2 3 4 5 6 7 8 9 10 11 |
{
"namespace": "1114805108664848",
"scope": "system",
"metric": "sys.memory.total",
"metricType": "COUNTER",
"tags": {
"host": "127.0.0.1"
},
"timestamp": 1470298287916,
"value": 1167126
}
|
MetricType 指标类型(参考:http://metrics.dropwizard.io/4.0.0/getting-started.html):
- COUNTER: 用于累加型的数据,反映的是数据随着时间单调递增的关系,如Tomcat接受到的HTTP请求的总次数
- GAUGE: 用于瞬态数据,表示指标在当前时间点的瞬时情况,反映的是数据随着时间上下波动的关系,如系统的load,JVM的内存使用率
- METER:用于对变化速率型指标进行度量,反映的是数据随时间的增长快慢关系,如某个接口的QPS
- HISTOGRAM:用于对分布型数据进行度量,反映的是数据随时间的统计学分布关系
Tags 标签存储方案:
由于生产环境中存储方案当前技术选型为使用Mysql存储Metric数据,Mysql不支持schemaless结构,所以无法做到Tags的key-value的动态扩展,我们使用Mysql的固定列模式,通过提供内置tag来达到相同的目的;Tags中的key为Mysql中的列名称,字段值为tags的value;
内置的tag字段为:
| 字段名称 | 字段描述 | 举例 |
|---|---|---|
| tag_host | 主机信息 | 127.0.0.1 |
| tag_device | 设备信息,比如磁盘盘符 | /usr/dev1 |
| tag_trace | 请求链路标识 | tid |
| tag_transaction | 请求事务标识 | createOrder |
Mysql数据模型如下:
六、监控数据查询方案
6.1 数据查询分类:
用户对时序数据的查询场景多种多样,总的来说时序数据的查询分为两种:
- 原始数据的查询(比如业务监控数据)
- 时序数据聚合运算的查询(比如系统监控数据)
某监控 指标展示计算解析:
监控中用户日志的计算逻辑是由用户自定义的计算方式(因为是业务监控),主要由求行数、对列值求和、对列值求平均、对列值求最大值、对列值求最小值;其大盘数据展示中并未对数据做再次聚合处理,展示的是采集的原始数据(原始数据分为秒级和分钟级),如果需要做计算,是通过前端的聚合函数进行的业务处理。
6.2 数据聚合分类:
在监控数据使用过程中,我们往往会针对单台机器进行分析或者多台(集群)机器进行分析,每一种分析中又会加入时间的概念,比如是采用原始采集的数据点还是进行多个点的合并形成一个新点。所以我们把数据分析计算分为两个维度,一个是‘机器’维度(空间聚合),一个时间维度(时间聚合);在Metric模型中我们通过两个方法分别定义,一个是Aggregator,一个是Down sample。
Aggregator:用来描述同一个时间点下,数据集合的聚合方式;比如一个集群的CPU使用率,在某一时刻下集群中所有机器的CPU使用率的平均值;需要注意的是,当随着集群规模越来越大的时候,我们也是需要从这个数据集合中进行采样,然后再做聚合计算。
Down sample:用来描述在多个时间点下,数据聚合的聚合方式;比如一台机器每隔5秒采集一个CPU使用率,最终数据展示时,需要按照1分钟一个点的方式进行展示,那么这个数据集合中在不丢数据的情况下会有12个数据项,我们需要将这12个数据项聚合为一个数据项。
6.3 数据聚合方式:
数据的聚合方式一般可以分为‘预聚合’和‘后聚合’;提前聚合可能引起数据膨胀但可以加速访问请求时的响应速度,访问时聚合虽然降低了一定的存储成本但可能会加慢响应速度。
大部分监控系统一般都支持预聚合(归档)数据处理(比如zabbix的数据归档表trends);由于一般原始数据采集周期比较小,比如分钟级,那么展示长时间的数据的视图需要扫描过多数据,展示比较慢,如果将数据归档成按小时,和按天的数据,那么展示时间跨度大的数据的效率大大提高;基于Metric的数据预处理,一般采用流式预聚合引擎,对数据进行降精度处理,比如阿里的DBPass产品,会对指标数据事先降时间精度,分为6个精度:1秒、5秒、15秒、1分钟、5分钟、15分钟。
基于Metric规范的时序数据库中,OpenTSDB支持预聚合和后聚合,Aliyun的HiTSDB优先采用后聚合,其通过采用倒排索引+前缀索引来加速数据查询。
6.4 数据计算算法:
在客户端数据采集计算的时候,通常也会遇到数据聚合的需求,主要是基于单机维度的数据聚合,比如我们期望采集固定周期周期范围内的数据,假如每个周期范围内存在多个数据点(D1,D2,D3),我们要怎样计算才能得到一个点的数据呢?
通常会有以下计算方式:
- 随机采样;
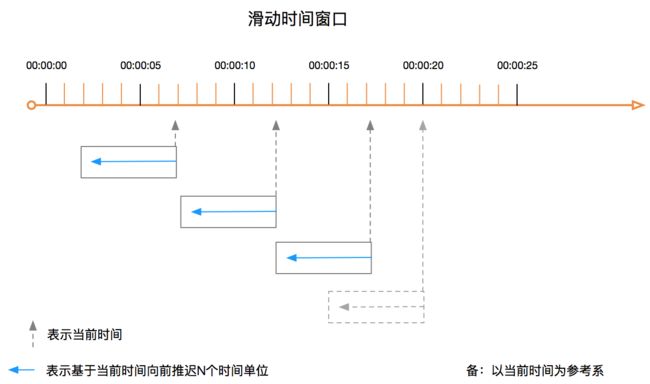
- 滑动窗口;
- 滑动时间窗口;
- 指数衰减随机采样(EWMA);

EWMA的Java实现方式可以参考:EWMA.java
EWMA算法 维护一个固定大小的集合,并认为该集合中的元素的权重不一样,元素的权重随元素距离当前时间的远近而呈现指数型的衰减。主要是解决数据集合中的离散点,让数据曲线跟加平滑。比如Load1、Load5、Load15目前的计算逻辑就采用EWMA算法;
6.5 数据查询API:
待补充
七、扩展阅读:
metric起源:
https://www.youtube.com/watch?v=czes-oa0yik
小米 open-falcon:
http://open-falcon.com/
网易企业级监控:
http://blog.163yun.com/archives/900
salesforce-Argus:
https://github.com/salesforce/argus
使用Metrics监控应用程序的性能:
http://www.cnblogs.com/yangecnu/p/Using-Metrics-to-Profiling-WebService-Performance.html
深入浅出时序数据库之预处理篇:
http://www.infoq.com/cn/articles/pretreatment-in-sequential-databases