hadoop2.7.5 集群搭建(高可用)
附录hadoop所有版本下载地址:https://archive.apache.org/dist/hadoop/common/
由于需要用到hadoop的服务器配置特写出来分享此文档。
服务器:
| hostname |
ip |
系统 |
| node1 |
192.168.3.21 |
centos7.2 |
| node2 |
192.168.3.22 |
centos7.2 |
| node3 |
192.168.3.23 |
centos7.2 |
| node4 |
192.168.3.24 |
centos7.2 |
| node5 |
192.168.3.25 |
centos7.2 |
节点分配情况:
| NameNode | DataNode | NodeManager | Zookeeper | ZKFC | JournalNode | ResourceManager | |
| node1 | 1 | 1 | |||||
| node2 | 1 | 1 | 1 | ||||
| node3 | 1 | 1 | 1 | 1 | |||
| node4 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| node5 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
注:由于我的node1、node2服务器中已经跑了很多服务,考虑到资源占用问题基本只把2台服务器做数据存储节点,以及zookeeper节点,进行配置时可以根据自己服务器的情况进行更改。
节点介绍:
NameNode:存储文件所有的数据(创建时间、修改时间、名字、创建人),记录每个文件切分block块所在节点的信息,类似于lader。
DataNode:数据节点,存储切分的每一个block块。
NodeManager:计算节点,与ResourceManager进行通信,管理所有Container的生命周期,以及节点中资源的状态(cpu、内存)。
JournalNode:Hadoop2.X才出现的,用来维护2个NameNode进行信息同步,active的NodeNode节点向JournalNode写数据,standby的节点向JournalNode读取数据,达到2个节点信息同步的目的。
ResourceManager:负责集群中所有资源的统一管理和分配,它接收来自各个节点(NodeManager)的资源汇报信息,并把这些信息按照一定的策略分配给各个应用程序。
zookeeper:在这里只是做了节点选举的作用、加强集群稳定性、保证集群高效性(实际是做数据同步的)。
准备工作:
一 、hosts 网络配置
在每台服务器 /etc/hosts添加下列信息:
192.168.3.23 node3
192.168.3.22 node2
192.168.3.21 node1
192.168.3.24 node4
192.168.3.25 node5
二、时间同步
在集群种时间同步是一个很重要得因素,因为时间不同步会导致集群数据丢失,集群报错等一系列问题,所以搭建集群时必须要保证时间同步。
安装:
yum install ntp
启动:
systemctl start ntpd
查看状态:
systemctl enable ntpd
/etc/ntp.conf 中可以进行配置,如果无网环境可以指定局域网内得服务器。
三、关闭防火墙
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
firewall-cmd --state #查看默认防火墙状态(关闭后显示notrunning,开启后显示running)
注:这里简单得方式是关闭防火墙,如果不想关闭防火墙就加入对应得策略开放对应数据同步的端口就可以了。
四、jdk环境安装 (1.8)
下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
[root@node5 ~]# tar -xf jdk-8u181-linux-x64.tar.gz #解压缩
[root@node5 ~]# mv jdk1.8.0_181/ /usr/local/java #移动到存放路径[root@node5 java]# vim /etc/profile.d/jdk.sh
export JAVA_HOME=/usr/local/java export PATH=$PATH:$JAVA_HOME/bin export JRE_HOME=/usr/local/java/jre export CLASSPATH=$JAVA_HOME/lib:$JAVA_HOME/jre/lib[root@node5 java]# source /etc/profile #把环境变量添加到系统中
#配置环境变量推荐单独存放在/etc/profile.d/文件中,方便进行删除修改。
注:执行/etc/profile文件的原因是因为里面又循环遍历会把/etc/profile.d/中的都添加到系统中。
五、服务器间SSH免密钥登陆
这里做node1node2的免密码——操作 5台服务器同理就好。
进入node1:
[root@node1 ~]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa #获得自己的密钥。
[root@node1 ~]# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys #将自己的密钥添加到自己的私钥里。做到免密钥。
[root@node1 ~]# scp -r ~/.ssh/id_dsa.pub root@node2:/tmp/ #将node1的密钥传到node2服务器的tmp中。
进入node2:
[root@node2 ~]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa #获得自己的密钥。
[root@node2 ~]# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys #将自己的密钥添加到自己的私钥里。做到免密钥。
[root@node2 ~]# scp -r ~/.ssh/id_dsa.pub root@node1:/tmp/ #将node2的密钥传到node1服务器的tmp中。
添加密钥:
[root@node1 ~]# cat /tmp/id_dsa.pub >> ~/.ssh/authorized_keys #将node1的密钥添加到自己的私钥里。
[root@node2 ~]# cat /tmp/id_dsa.pub >> ~/.ssh/authorized_keys #将node1的密钥添加到自己的私钥里。
测试:
[root@node1 ~]# ssh node2 #不用输入密码直接进入node2
[root@node2 ~]# ssh node1 #不用输入密码直接进入node1
注:免密钥的操作就是相当于把每台服务器生成的密钥都添加到其他服务器中,做到免密钥的操作。
安装Hadoop HA:
安装解压:
[root@node1 ~]# cd /data/hadoop/ #进入已经下载的hadoop目录
[root@node1 hadoop]# tar -xf hadoop-2.7.5.tar.gz #解压缩
[root@node1 hadoop]# cd hadoop-2.7.5/ #进入目录
[root@node1 hadoop-2.7.5]# vim /etc/profile.d/hadoop.sh #配置环境变量
export HADOOP_HOME=/data/hadoop/hadoop-2.7.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin[root@node1 hadoop-2.7.5]# source /etc/profile #添加环境变量
配置文件:
[root@node1 hadoop-2.7.5]# cd etc/hadoop/ #进入配置文件
[root@node1 hadoop]# vim hadoop-env.sh #添加hadoop 和 Java的环境。
export JAVA_HOME=/usr/local/java
export HADOOP_PREFIX=/data/hadoop/hadoop-2.7.5[root@node1 hadoop]# cp core-site.xml.template core-site.xml #复制配置文件。
[root@node1 hadoop]# vim core-site.xml #修改配置文件 配置hadoop存储路径,访问设置。 添加configuration的内容
fs.defaultFS
hdfs://zsj
hadoop.tmp.dir
/media/hadoop/hadoop1
ha.zookeeper.quorum
node1:2181,node2:2181,node3:2181,node4:2181,node5:2181
hadoop.proxyuser.root.groups
root
Allow the superuser oozie to impersonate any members of the group group1 and group2
hadoop.proxyuser.root.hosts
0.0.0.0
The superuser can connect only from host1 and host2 to impersonate a user
[root@node1 hadoop]# cp hdfs-site.xml.template hdfs-site.xml
[root@node1 hadoop]# vim hdfs-site.xml #配置HDFS副本数,NameNode、JournalNode节点的一些信息。
dfs.replication
2
dfs.nameservices
zsj
dfs.ha.namenodes.zsj
nn1,nn2
dfs.namenode.rpc-address.zsj.nn1
node4:8020
dfs.namenode.rpc-address.zsj.nn2
node5:8020
dfs.namenode.http-address.zsj.nn1
node4:50070
dfs.namenode.http-address.zsj.nn2
node5:50070
dfs.namenode.shared.edits.dir
qjournal://node5:8485;node4:8485;node3:8485/zsj
dfs.client.failover.proxy.provider.zsj
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_dsa
dfs.journalnode.edits.dir
/opt/journal/data
dfs.ha.automatic-failover.enabled
true
dfs.permissions
false
[root@node1 hadoop]# cp yarn-site.xml.template yarn-site.xml #复制yarn配置文件
[root@node1 hadoop]# vim yarn-site.xml # 修改yarn的配置文件
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
cluster1
yarn.resourcemanager.ha.rm-ids
rm1,rm2,rm3
yarn.resourcemanager.hostname.rm1
node5
yarn.resourcemanager.hostname.rm2
node4
yarn.resourcemanager.hostname.rm3
node3
yarn.resourcemanager.zk-address
node1:2181,node2:2181,node3:2181,node4:2181,node5:2181
yarn.nodemanager.vmem-check-enabled
false
Whether virtual memory limits will be enforced for containers
yarn.nodemanager.vmem-pmem-ratio
8
Ratio between virtual memory to physical memory when setting memory limits for containers
[root@node1 hadoop]# cp mapred-site.xml.template mapred-site.xml #配置yarn
[root@node1 hadoop]# vim mapred-site.xml #配置yarn
mapreduce.framework.name
yarn
[root@node1 hadoop]# vim slavers #配置NodeManager,DataNode 由于做hadoop HA 没一个DataNode都会残生一个NodeManager节点。
node1
node2
node3
node4
node5
添加权限:
[root@node1 ~]# groupadd hadoop #添加hadoop用户组
[root@node1 ~]# useradd -g hadoop hadoop #添加hadoop用户并添加到用户组中
[root@node1 ~]# chown -R hadoop.hadoop /data/hadoop/hadoop-2.7.5 #对hadoop目录添加hadoop用户 -R代表所有
[root@node1 ~]#chown -R hadoop.hadoop /media/hadoop/hadoop1 #对hadoop的存储磁盘进行权限添加。
配置文件完成,同步所有配置文件5台服务器的配置文件必须统一。存储路径的没必要统一,节点的一定要统一。
启动:
前提完成上述配置 zookeeper集群必须启动。zookepper集群安装可以查询一下,后续会提供具体安装过程。
#找到任意一个主节点。
[root@node4 ~]# start-all.sh #启动hadoop
[root@node4 ~]# hdfs namenode -format #格式化namenode
[root@node4 ~]# hadoop-daemon.sh start namenode #启动namenode
[root@node5 ~]# hdfs namenode -bootstrapStandby # 去另一个namenode节点同步namenode
[root@node4 ~]# stop-all.sh #关闭集群
[root@node4 ~]# start-all.sh #启动hadoop集群。
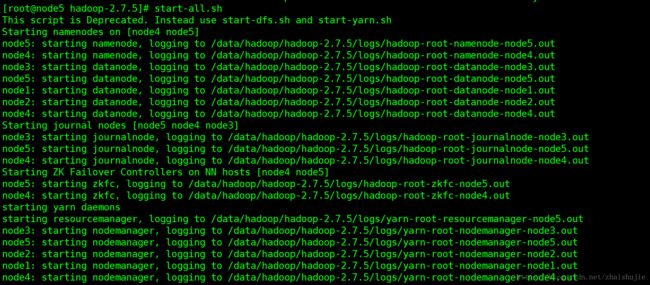
查询服务器节点信息:
[root@node5 hadoop-2.7.5]# jps
30048 QuorumPeerMain #zookeeper
2273 JournalNode
1778 NameNode
2520 DFSZKFailoverController
2968 NodeManager
3288 Jps
1967 DataNode
-----------------------------------
[root@node4 ~]# jps
82529 NodeManager
31429 QuorumPeerMain
82036 NameNode
82791 Jps
80102 ResourceManager
82298 JournalNode
82413 DFSZKFailoverController
82159 DataNode
-----------------------------------
[root@node3 hadoop1]# jps
10528 DataNode
10656 JournalNode
11906 QuorumPeerMain
10772 NodeManager
10986 Jps
-----------------------------------
[root@node2 hadoop1]# jps
3260 QuorumPeerMain
31660 DataNode
31804 NodeManager
32093 Jps
-----------------------------------
[root@node1 hadoop1]# jps
14273 DataNode
3296 QuorumPeerMain
15647 Jps
14654 NodeManager
可以看出启动的节点和刚开始设计的完全一样。
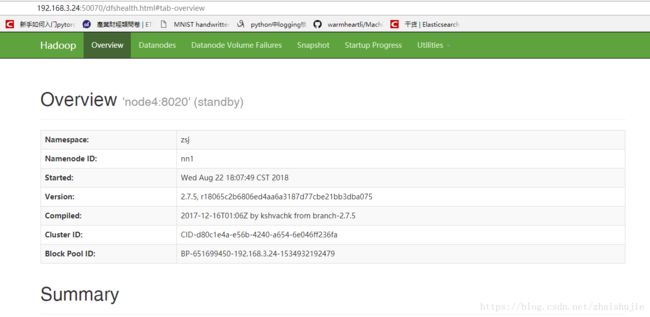
打开UI界面: 192.168.3.24:50070 192.168.3.25:50070
standby节点 :
active节点:
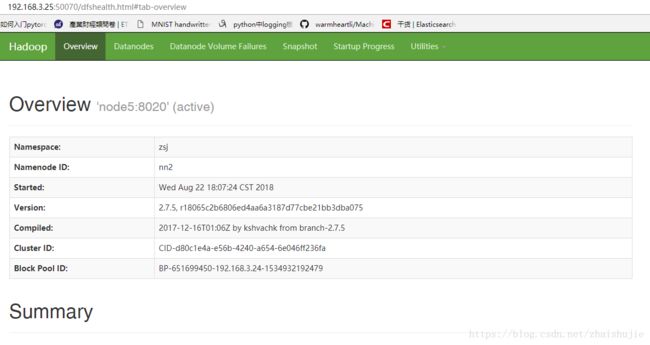
standby、active节点是zookeeper集群通过该服务器运行资源进行选举出来的。
数据节点信息:

这里节点里面我挂载的有2T的硬盘有1T的硬盘。
到此Hadoop HA的搭建已经全部配置完成,转载请付源地址! change the world~