数据结构课程设计(三)---Huffman编码
1、任务简述:
对一篇英文文章,统计其中26个小写字母出现的频次,对这些小写字母进行Huffman编码。
要求:
(1)从文件读入原始文本文件,并在屏幕上显示出文本;
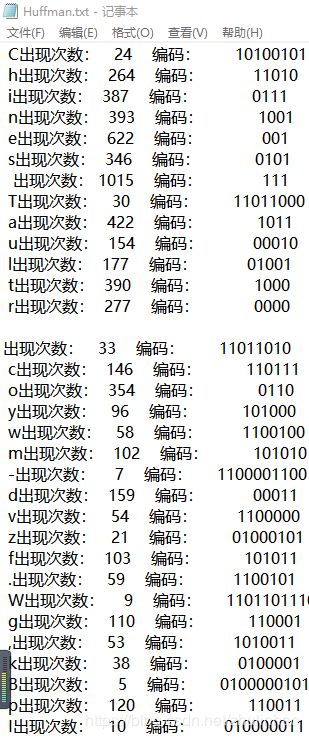
(2)按照字母顺序输出字母的出现次数,以及相应的编码。
(3)同时具备解码功能。即输入一串二进制编码,能够还原出文本
2、算法描述:
数据结构:

一颗有n个叶子(n个字符得文章)结点的Huffman树共有2n-1个结点,可以存储在一个大小为2n-1的一维数组中。译码需要从上往下走,编码需要从下往上走,所以对于每个节点都需要知道其双亲,同时也要知道其孩子的信息,所以定义如下结构:
准备操作:
1.寻找文章中不同字符的个数,并且保存到数组c中,这个只需要对文章进行一次遍历即可。
2.寻找数组c中没有双亲的节点中最小的两个值,由于在写这题的时候,我还没有学习到那些厉害的排序方法,而且感觉经典的排序算法有些繁琐,所有我查阅了相关资料,采用打擂法。
3.把Huffman编码以位存储进文件:这里我不是很会,请教了高中的同学,具体方法见总结。
编码,解码:
由于赫夫曼树中没有度为1的结点(这类树又称严格的(strict)(或正则的)二叉树),则一棵有n个叶子结点的赫夫曼树共有2n-1个结点,可以存储在一个大小为2n-1的一维数组中。如何选定结点结构?由于在构成赫夫曼树之后,为求编码需从叶子结点出发走一条从叶子到根的路径;而为译码需从根出发走一条从根到叶子的路径。则对每个结点而言,既需知双亲的信息,又需知孩子结点的信息。
把所有出现的字符(n个)权值先录入表,双亲、左孩子、右孩子均置为0。
编码:然后从n—2n-1的空间,依次选取表中权值最小的两个结点,保持最小左边,次小右边(确定唯一编码),结成新的结点存入表中,更新双亲、左右孩子信息。
解码时从2n-1开始寻找,1右孩子、0左孩子、一直寻找到一个左右孩子均为0的结点,就是那个字符。
3、源代码
#include 三、运行结果
下图为显示原始文本:

下图为按照字母顺序输出字母的出现次数,以及相应的编码:

解码结果:


5、总结
性能分析:
时间复杂度:在建树的时候需要寻找两个最小的权值,所以时间复杂度为O(n^2)
空间复杂度:O(n),n为文章中不字符的个数。
遇到的问题与解决方法:
难点在于位操作:
因为一次只能录入8位、所以在编码的时候不仅要循环考虑进行位操作的字符,还要考虑编码串的长度。(例如进行位操作的字符8位已经用完了,但是当前编码字符的01串还没有录到底)。而且编码到最后时,可能最后一个字符串只用了前几位、后面有几位是多余的。则需要返回这个多余位数、便于解码的最后进行判断。
心得体会:
运行结果正确,按照书上算法思路操作实现。本来打算只考虑26个英文字母,但是感觉可以多考虑一些,毕竟算法思路一样,所以考虑了我找的文章中出现的所有的字符,比如:“:”,“,”,“.”,“ ”,“ ”等等所有文中出现的字符。
存在问题和改进方法:
对于代码本身,问题应该不是很大,但是这题在生成编码的时候,我没有采用书上的思路,而是用了别人教给我的位操作,因为这部分内容,我可以写出来,但是感觉代码去判断左右孩子,来分配0,1较为麻烦,我想到是思路是:对每一个字符,为了确定其编码,我们可以对二叉树进行遍历,左孩子就是0,右孩子就是1,可以用数组来存储其编码。