Turbocharge SQL with advanced Oracle indexing
Oracle Tips by Burleson Consulting
March 26, 2002 - Updated June 28, 2007
For complete details on Oracle indexing for high performance, see my book "Oracle Tuning: The Definitive Reference".
Oracle includes numerous data structures to improve the speed of Oracle SQL queries. Taking advantage of the low cost of disk storage, Oracle includes many new indexing algorithms that dramatically increase the speed with which Oracle queries are serviced. This article explores the internals of Oracle indexing; reviews the standard b-tree index, bitmap indexes, function-based indexes, and index-only tables (IOTs); and demonstrates how these indexes may dramatically increase the speed of Oracle SQL queries.
Oracle uses indexes to avoid the need for large-table, full-table scans and disk sorts, which are required when the SQL optimizer cannot find an efficient way to service the SQL query. I begin our look at Oracle indexing with a review of standard Oracle b-tree index methodologies.
The Oracle b-tree index
The oldest and most popular type of Oracle indexing is a standard b-tree index, which excels at servicing simple queries. The b-tree index was introduced in the earliest releases of Oracle and remains widely used with Oracle.
B-tree indexes are used to avoid large sorting operations. For example, a SQL query requiring 10,000 rows to be presented in sorted order will often use a b-tree index to avoid the very large sort required to deliver the data to the end user.
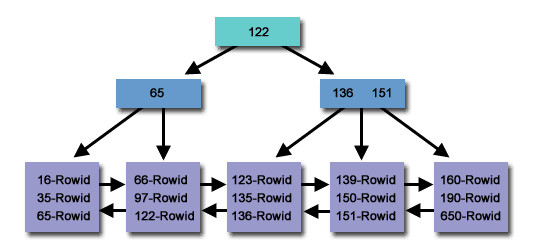
An Oracle b-tree index
Oracle offers several options when creating an index using the default b-tree structure. It allows you to index on multiple columns (concatenated indexes) to improve access speeds. Also, it allows for individual columns to be sorted in different orders. For example, we could create a b-tree index on a column called last_name in ascending order and have a second column within the index that displays the salary column in descending order.
While b-tree indexes are great for simple queries, they are not very good for the following situations:
- Low-cardinality columns梒olumns with less than 200 distinct values do not have the selectivity required in order to benefit from standard b-tree index structures.
- No support for SQL functions桞-tree indexes are not able to support SQL queries using Oracle's built-in functions. Oracle9i provides a variety of built-in functions that allow SQL statements to query on a piece of an indexed column or on any one of a number of transformations against the indexed column.
Prior to Oracle9i, the Oracle SQL optimizer had to perform time-consuming long-table, full-table scans due to these shortcomings. Consequently, it was no surprise when Oracle introduced more robust types of indexing structures.
Bitmapped indexes
Oracle bitmap indexes are very different from standard b-tree indexes. In bitmap structures, a two-dimensional array is created with one column for every row in the table being indexed. Each column represents a distinct value within the bitmapped index. This two-dimensional array represents each value within the index multiplied by the number of rows in the table. At row retrieval time, Oracle decompresses the bitmap into the RAM data buffers so it can be rapidly scanned for matching values. These matching values are delivered to Oracle in the form of a Row-ID list, and these Row-ID values may directly access the required information.
The real benefit of bitmapped indexing occurs when one table includes multiple bitmapped indexes. Each individual column may have low cardinality. The creation of multiple bitmapped indexes provides a very powerful method for rapidly answering difficult SQL queries.
For example, assume there is a motor vehicle database with numerous low-cardinality columns such as car_color, car_make, car_model, and car_year. Each column contains less than 100 distinct values by themselves, and a b-tree index would be fairly useless in a database of 20 million vehicles. However, combining these indexes together in a query can provide blistering response times a lot faster than the traditional method of reading each one of the 20 million rows in the base table. For example, assume we wanted to find old blue Toyota Corollas manufactured in 1981:
Oracle uses a specialized optimizer method called a bitmapped index merge to service this query. In a bitmapped index merge, each Row-ID, or RID, list is built independently by using the bitmaps, and a special merge routine is used in order to compare the RID lists and find the intersecting values. Using this methodology, Oracle can provide sub-second response time when working against multiple low-cardinality columns:
Function-based indexes
One of the most important advances in Oracle indexing is the introduction of function-based indexing. Function-based indexes allow creation of indexes on expressions, internal functions, and user-written functions in PL/SQL and Java. Function-based indexes ensure that the Oracle designer is able to use an index for its query.
Prior to Oracle8, the use of a built-in function would not be able to match the performance of an index. Consequently, Oracle would perform the dreaded full-table scan. Examples of SQL with function-based queries might include the following:
Select * from customer where substr(cust_name,1,4) = 態URL?
Select * from customer where to_char(order_date,扢M? = ?1;
Select * from customer where upper(cust_name) = 慗ONES?
Select * from customer where initcap(first_name) = 慚ike?
In Oracle, Oracle always interrogates the where clause of the SQL statement to see if a matching index exists. By using function-based indexes, the Oracle designer can create a matching index that exactly matches the predicates within the SQL where clause. This ensures that the query is retrieved with a minimal amount of disk I/O and the fastest possible speed.
Index-only tables
Beginning with Oracle8, Oracle recognized that a table with an index on every column did not require table rows. In other words, Oracle recognized that by using a special table-access method called an index fast full scan, the index could be queried without actually touching the data itself.
Oracle codified this idea with its use of index-only table (IOT) structure. When using an IOT, Oracle does not create the actual table but instead keeps all of the required information inside the Oracle index. At query time, the Oracle SQL optimizer recognizes that all of the values necessary to service the query exist within the index tree, at which time the Oracle cost-based optimizer has a choice of either reading through the index tree nodes to pull the information in sorted order or invoke an index fast full scan, which will read the table in the same fashion as a full table scan, using sequential prefetch (as defined by the db_file_multiblock_read_count parameter). The multiblock read facility allows Oracle to very quickly scan index blocks in linear order, quickly reading every block within the index tablespace. Here is an example of the syntax to create an IOT.
Index performance
Oracle indexes can greatly improve query performance but there are some important indexing concepts to understand.
- Index clustering
- Index blocksizes
Indexes and blocksize
Indexes that experience lots of index range scans of index fast full scans (as evidence by multiblock reads) will greatly benefit from residing in a 32k blocksize.
Today, most Oracle tuning experts utilize the multiple blocksize feature of Oracle because it provides buffer segregation and the ability to place objects with the most appropriate blocksize to reduce buffer waste. Some of the world record Oracle benchmarks use very large data buffers and multiple blocksizes.
According to an article by Christopher Foot, author of the OCP Instructors Guide for Oracle DBA Certification, larger block sizes can help in certain situations:
"A bigger block size means more space for key storage in the branch nodes of B-tree indexes, which reduces index height and improves the performance of indexed queries."
In any case, there appears to be evidence that block size affects the tree structure, which supports the argument that data blocks affect the structure of the tree.
Indexes and clustering
The CBO's decision to perform a full-table vs. an index range scan is influenced by the clustering_factor (located inside the dba_indexes view), db_block_size, and avg_row_len. It is important to understand how the CBO uses these statistics to determine the fastest way to deliver the desired rows.
Conversely, a high clustering_factor, where the value approaches the number of rows in the table (num_rows), indicates that the rows are not in the same sequence as the index, and additional I/O will be required for index range scans. As the clustering_factor approaches the number of rows in the table, the rows are out of sync with the index.
Oracle Metalink Note:223117.1 has some great advice for tuning-down 揹b file sequential read?waits by table reorganization in row-order:
- If Index Range scans are involved, more blocks than necessary could be being visited if the index is unselective: by forcing or enabling the use of a more selective index, we can access the same table data by visiting fewer index blocks (and doing fewer physical I/Os).
- If the index being used has a large Clustering Factor, then more table data blocks have to be visited in order to get the rows in each Index block: by rebuilding the table with its rows sorted by the particular index columns we can reduce the Clustering Factor and hence the number of table data blocks that we have to visit for each index block.
This validates the assertion that the physical ordering of table rows can reduce I/O (and stress on the database) for many SQL queries.
Also see:
-
Oracle SQL clustering_factor tuning index access
-
Oracle SQL clustering_factor
-
The importance of clustering_factor in multi-block I/O
-
Oracle index rebuilding - indexes rebuild script
-
Oracle table index rebuilding benefits
Conclusion
Oracle dominates the market for relational database technology, so Oracle designers must be aware of the specialized index structures and fully understand how they can be used to improve the performance of all Oracle SQL queries. Many of these techniques are discussed my book "Oracle Tuning: The Definitive Reference".
This text details the process of creating all of Oracle's index tree structures and offers specialized tips and techniques for ensuring SQL queries are serviced using the fastest and most efficient indexing structure.