机器学习入门必读:6种简单实用算法及学习曲线、思维导图

导读:大部分的机器学习算法主要用来解决两类问题——分类问题和回归问题。在本文当中,我们介绍一些简单但经典实用的传统机器学习算法,让大家对机器学习算法有一个基本的感性认识。
有的人说机器学习入门并不难,有的人会觉得机器学习难以理解。那么该如何去学习机器学习这种技术与方法呢?在本文当中,我们将介绍掌握机器领域知识的学习曲线、技术栈以及常用框架。
作者:卢誉声
来源:大数据DT(ID:hzdashuju)

01 机器学习算法
1. 分类算法
这是一种监督学习方法。有很多算法帮助我们解决分类问题,比如K近邻、决策树、朴素贝叶斯、贝叶斯网络、逻辑回归、SVM等算法。人工神经网络和深度学习也往往用来解决分类问题。这些都是常见和常用的分类算法,只不过不同的算法都有其优劣,会应用在不同的场景下。
我们举一个例子。假设我们知道某个鸟的各个特征,现在要根据这些特征确定这只鸟属于哪种鸟类,这就是所谓的分类问题。
首先,我们要收集能收集到的所有的鸟类信息,包括鸟的各种特征以及鸟的种类,其中颜色、体重、翅膀等属性都属于特征,而种类则是鸟的标签。
其次,我们建立的机器学习的目的就是让用户输入一个鸟的特征,然后输出这个鸟的种类,也就是对应的标签。这个过程就是一个根据鸟的属性分类的过程,只不过是由计算机自动完成的。
2. 回归算法
回归算法也是一种有监督学习方法。回归算法来自于回归分析,回归分析是研究自变量和因变量之间关系的一种预测模型技术。这些技术应用于预测,时间序列模型和找到变量之间的关系。
举个简单例子,我们可以通过计算得出在某些情况下服务器接收请求数量与服务器CPU、内存占用压力之间的关系。
最简单的回归算法就是线性回归,相信大家都对线性回归有所了解。虽然线性回归比较简单,但是越简单粗暴的算法在面对有些实际问题的时候就越实用。深度学习也可以用于解决回归问题。

3. 聚类算法
聚类算法是一类无监督学习算法。聚类是研究(样品或指标)分类问题的一种统计分析方法,同时也是数据挖掘的一个重要算法。
聚类分析以相似性为基础,在一个聚类中的模式比不在同一聚类中的模式具有更多的相似性,这是聚类分析的最基本原理。聚类分析的算法可以分成很多类方法,比如划分法、层次法、基于密度的方法、基于网络的方法和基于模型的方法。
最有名的聚类算法就是K-Means(K-均值)算法,是最为经典的、基于划分的聚类方法。该算法的主要思路是以空间中k个点为形心进行聚类,将最靠近它们的对象归类。通过迭代的方法,逐次更新各簇的形心的值,直至得到最好的聚类结果。(形心可以是实际的点,也可以是虚拟点)。
通过该算法我们可以将特征相似的数据聚合称为一个数据群组,而将特征相差较大的数据分开。
4. 关联分析算法
关联分析是除了聚类以外的一种常用无监督学习方法。用于发现存在于大量数据集中的关联性或相关性,从而描述了一个事物中某些属性同时出现的规律和模式。
关联分析最典型的应用就是购物车分析。我们可以从用户的订单中寻找经常被一起购买的商品,并挖掘这些商品之间的潜在关系,这样有助于线上、线下商家指定购买与销售策略。
最著名的关联分析算法就是Apriori算法和FP-growth算法。Apriori算法就是根据有关频繁项集特性的先验知识而命名的。它使用一种称作逐层搜索的迭代方法。而FP-growth是针对Apriori算法的改进算法,通过两次扫描事务数据库,把每个事务所包含的频繁项目按其支持度降序压缩存储到FP-tree中。
在以后发现频繁模式的过程中,不需要再扫描事务数据库,而仅在FP-tree中进行查找即可,并通过递归调用FP-growth的方法来直接产生频繁模式,因此在整个发现过程中也不需产生候选模式。该算法克服了Apriori算法中存在的问题,在执行效率上也明显好于Apriori算法,同时能生成有向关系,比Apriori更为泛用。

5. 集成算法
前面几节介绍了常见的机器学习算法,但是我们会发现每个单独的机器学习算法往往只能解决特定场景下的特定问题,如果问题会变得更为复杂,就难以使用一个学习器达到目标。这时候我们就需要集成多个学习器,协同完成机器学习任务。
所谓集成学习就是使用一系列学习器进行学习,并使用某种规则把各个学习结果进行整合,从而获得比使用单个学习器更好的学习效果的一种机器学习方法。一般情况下,集成学习中的多个学习器都是同质的“弱学习器”。
集成学习的主要思路是先通过一定的规则生成多个学习器,再采用某种集成策略进行组合,然后综合判断输出最终结果。
一般而言,通常所说的集成学习中的多个学习器都是同质的“弱学习器”。基于该“弱学习器”,通过样本集扰动、输入特征扰动、输出表示扰动、算法参数扰动等方式生成多个学习器,进行集成后获得一个精度较好的“强学习器”。
最著名的集成算法就是Boosting类算法,包括AdaBoosting等常用算法。这类算法需要同时训练多个模式,基本思路就是根据训练时的正确率和错误率调整不同学习器的权重,最终预测时使用带权重的投票法产生最终结果。
还有一类集成算法为Bagging类算法,主要思路是分别训练几个不同的模型,然后用模型平均的方法做出最终决策。
最著名的Bagging类算法就是随机森林,该算法还融入了随机子空间方法,是以决策树为基础分类器的一个集成学习模型,它包含多个由Bagging集成学习技术训练得到的决策树,当输入待分类的样本时,最终的分类结果由单个决策树的输出结果投票决定。
6. 强化算法
强化学习(reinforcement learning)和我们在前面提到的算法不太一样,其主要用于训练一个可以感知环境的自制感知器,通过学习选择能达到其目标的最优动作。这个很具有普遍性的问题应用于学习控制移动机器人,在工厂中学习最优操作工序以及学习棋类对弈等。
当某个智能体在其环境中做出每个动作时,施教者会提供奖励或惩罚信息,以表示结果状态的正确与否。该智能体的任务就是从这个非直接的,有延迟的回报中学习,以便后续的动作产生最大的累积效应。
——引用自米歇尔(Mitchell T.M.)《机器学习》
最著名的增强学习算法就是Q-Learning算法。由于增强学习算法不在本文讨论范畴,并由于其本身的复杂性,我们在这里只做简单的介绍但不做深入讨论。

02 如何掌握机器学习
1. 学习曲线
首先,我们必须清楚机器学习是计算机科学中的一个领域,所以要能够掌握机器学习,真正通过计算机把机器学习应用起来是需要以计算机科学为基础的。比如要了解基础的程序设计语言,至少是Python或者MATLAB,要知道基本的数据结构,要知道基本的数据处理技术,要知道基本的数据存储查询技术等。
其次,机器学习算法一般都有比较严密完善的数学原理,如果不能从数学的角度去理解机器学习,我们是无法理解其中一些本质核心的东西的,那就永远只能从使用模型的角度对这个领域浅尝辄止了。
另外机器学习也是一个依靠经验的领域,许多参数和方法都需要依靠日常的经验积累出来,从而形成一种解决问题的思维和感觉,这样在利用机器学习技术解决现有问题时会更快、更有效,往往能找到合适的解决方案。
所以机器学习是有学习曲线的,也许更像一个无限循环的S形学习曲线,一开始学习基本的机器学习算法,做简单的实验非常容易入手。根据经验,进一步学习更多的机器学习算法后可能会逐渐迷失在各种机器学习模型之中,学习难度陡然上升。
当你将大多数经典模型融会贯通之后,你又会觉得各种类型的机器学习算法变化无非几类,于是学习难度曲线又会变得平滑。但当你开始解决实际问题时,就又会陷入陡峭的学习曲线中,在攀爬式的学习中不断积累经验。
总而言之,机器学习是一个需要不断进行理论和经验积累的技术,每过一个阶段都会遇到相应的瓶颈。这不是一成不变的,而是一个需要不断学习实践的技术。只有在不断遇到问题并解决问题后才能不断前行。
2. 技术栈
我们把深度学习的技术栈分为3个类别。第1类是基础数学工具,第2类是机器学习基础理论方法,第3类是机器学习的实践工具与框架。我们在这里对这几类内容做一个概述,如果读者在学习过程当中发现有不甚了解的基础概念或知识时,可以翻看本文寻找你需要的工具和技术并进行了解,循环往复、温故而知新。
基础数学工具包括高等数学、线性代数、概率论与数理统计、离散数学、矩阵理论、随机过程、最优化方法和复变函数等。没错,基础数学工具在机器学习领域乃至其工程领域必不可少,望读者能够对这些知识有一个较为全面的掌握。
机器学习基础理论方法包括决策树、支持向量机、贝叶斯、人工神经网络、遗传算法、概率图模型、规则学习、分析学习、增强学习,等等。
机器学习的实践工具与框架类目就比较繁杂了,包括基础语言与工具、工程框架、数据存储工具和数据处理工具。
基础语言与工具有MATLAB及其工具包,Python与相应的库(NumPy、SciPy、Matplotlib和Scikit-learn等)。
工程框架包括TensorFlow、MXNet、Torch和PyTorch、Keras等。
数据存储包括Oracle、SQL Server、MySQL、PostgreSQL等传统的关系型数据库,LevelDB、LMDB、Redis等K/V型数据库,MongoDB等文档型数据库,Neo4j等图形数据库,HBase、Cassandra等列数据库,数不胜数。
数据处理工具则包括批处理、实时处理两大类。批处理工具有Hadoop,以及基于Hadoop的Hive和Pig。
实时处理工具有Storm和Hurricane实时处理系统。至于非常有名的Spark应该属于改良的批处理工具,也能用于实时处理场景。
最后送上移动平台深度学习入门路径:
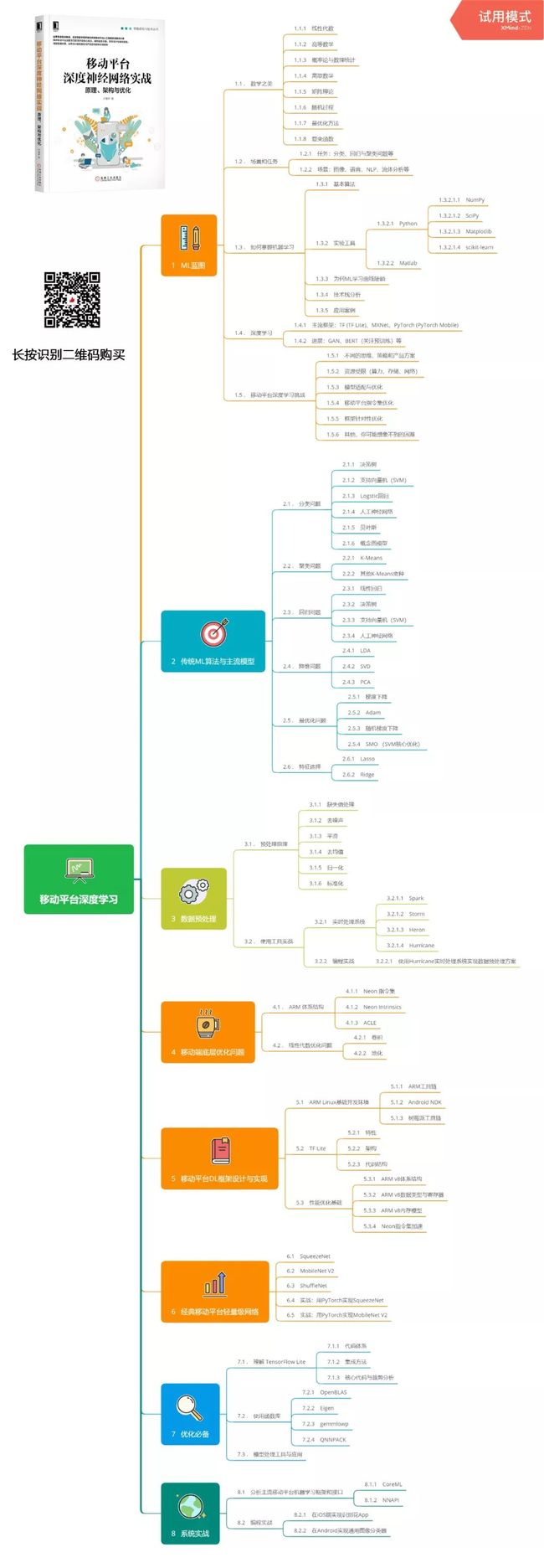
关注「大数据DT」,在公众号后台对话框回复移动平台,获取高清大图下载方式。
关于作者:卢誉声,Autodesk数据平台和计算平台资深工程师,负责平台架构研发工作。工作内容涵盖大规模分布式系统的服务器后端、前端以及SDK的设计与研发,在数据处理、实时计算、分布式系统设计与实现、性能调优、高可用性和自动化等方面积累了丰富的经验。擅长C/C++、JavaScript开发,此外对Scala、Java以及移动平台等也有一定研究。
本文摘编自《移动平台深度神经网络实战》,经出版方授权发布。
延伸阅读《移动平台深度神经网络实战》
点击上图了解及购买
转载请联系微信:DoctorData
推荐语:新智元年度Top1好书!精讲移动平台深度学习系统所需核心算法、硬件级指令集、系统设计与编程实战、海量数据处理、业界流行框架裁剪与产品级性能优化策略等,深入、翔实。

有话要说????
Q: 你尝试过哪些机器学习算法?
欢迎留言与大家分享
猜你想看????
2020大风口!什么是图神经网络?有什么用?终于有人讲明白了
学AI哪家强?2019全球排行清华第1,北大第2
什么是折线图?怎样用Python绘制?怎么用?终于有人讲明白了
什么是机器学习?有哪些应用?终于有人讲明白了
据统计,99%的大咖都完成了这个神操作
????
原来你也在看