【NLP】Attention原理和源码解析

内容:
1. 核心思想
2. 原理解析(图解+公式)
3. 模型分类
4. 优缺点
5. TF源码解析
1. 核心思想
Attention的思想理解起来比较容易,就是在decoding阶段对input中的信息赋予不同权重。在nlp中就是针对sequence的每个time step input,在cv中就是针对每个pixel。
2. 原理解析
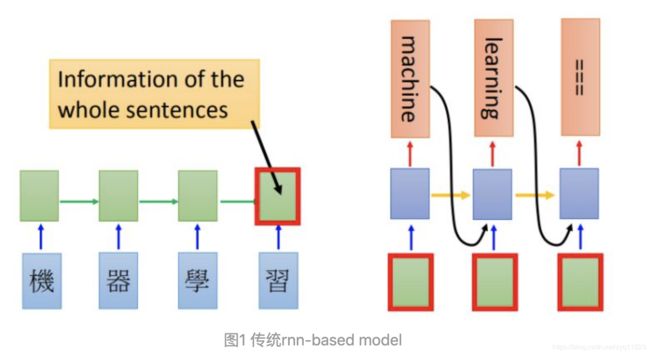
针对Seq2seq翻译来说,rnn-based model差不多是图1的样子:
而比较基础的加入attention与rnn结合的model是下面的样子(也叫soft attention):
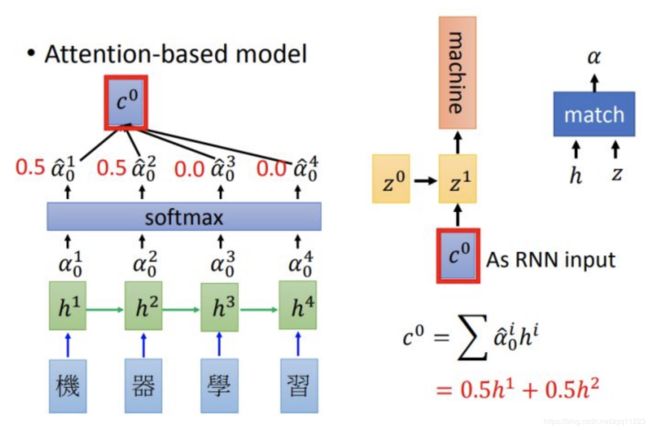
其中 α 0 1 \alpha_{0}^1 α01 是 h 0 1 h_{0}^1 h01 对应的权重,算出所有权重后会进行softmax和加权,得到 c^0 。
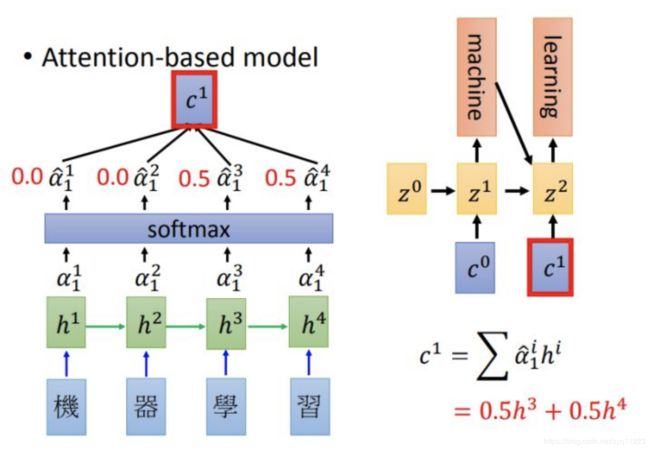
可以看到Encoding和decoding阶段仍然是rnn,但是decoding阶使用attention的输出结果 c 0 , c 1 c^0, c^1 c0,c1 作为rnn的输入。
那么重点来了, 权重 α \alpha α 是怎么来的呢?常见有三种方法:
- α 0 1 = c o s _ s i m ( z 0 , h 1 ) \alpha_{0}^1=cos\_sim(z_0, h_1) α01=cos_sim(z0,h1)
- α 0 = n e u r a l _ n e t w o r k ( z 0 , h ) \alpha_0 =neural\_network(z_0, h) α0=neural_network(z0,h)
- α 0 = h T W z 0 \alpha_0 = h^TWz_0 α0=hTWz0
思想就是根据当前解码“状态”判断输入序列的权重分布。
如果把attention剥离出来去看的话,其实是以下的机制:
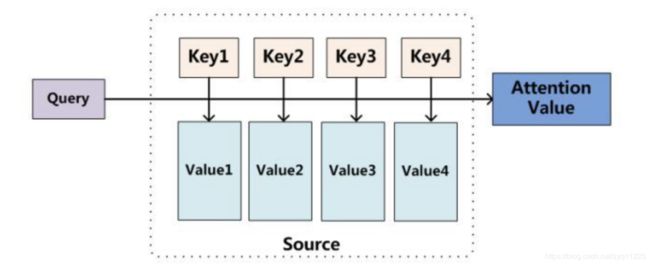
输入是query(Q), key(K), value(V),输出是attention value。如果与之前的模型对应起来的话,query就是 z 0 z_0 z0, z 1 z_1 z1 ,key就是 h 1 h_1 h1, h 2 h_2 h2, h 3 h_3 h3, h 4 h_4 h4 ,value也是 h 1 h_1 h1, h 2 h_2 h2, h 3 h_3 h3, h 4 h_4 h4。模型通过Q和K的匹配计算出权重,再结合V得到输出:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( s i m ( Q , K ) ) V Attention(Q, K, V) = softmax(sim(Q, K))V Attention(Q,K,V)=softmax(sim(Q,K))V
再深入理解下去,这种机制其实做的是寻址(addressing),也就是模仿中央处理器与存储交互的方式将存储的内容读出来,可以看一下李宏毅老师的课程。
3. 模型分类
3.1 Soft/Hard Attention
soft attention:传统attention,可被嵌入到模型中去进行训练并传播梯度
hard attention:不计算所有输出,依据概率对encoder的输出采样,在反向传播时需采用蒙特卡洛进行梯度估计
3.2 Global/Local Attention
global attention:传统attention,对所有encoder输出进行计算
local attention:介于soft和hard之间,会预测一个位置并选取一个窗口进行计算
3.3 Self Attention
传统attention是计算Q和K之间的依赖关系,而self attention则分别计算Q和K自身的依赖关系。具体的详解会在下篇文章给出~
4. 优缺点
优点:
在输出序列与输入序列“顺序”不同的情况下表现较好,如翻译、阅读理解
相比RNN可以编码更长的序列信息
缺点:
对序列顺序不敏感
通常和RNN结合使用,不能并行化
5. TF源码解析
发现已经有人解析得很明白了,即使TF代码有更新,原理应该还是差不多的,直接放上来吧:
Tensorflow源码解读(一):AttentionSeq2Seq模型
参考:
https://zhuanlan.zhihu.com/p/43493999