DRMM model学习笔记
论文原名:A Deep Relevance Matching Model for Ad-hoc Retrieval
导读
本文是发表在CIKM2016上的一篇关于信息检索的文章。神经网络在信息检索上的利用主要有semantic matching和relevance matching两种方式。本文将两种方式的优劣进行分析比较,并提出了DRMM的模型。该模型可以有效的提取query和document之间各个term的相关性,并使用直方图的形式代替pooling,可以有效的区分相似和完全匹配,并保留更多信息。该模型也在测试中取得了相比较与其他模型明显和稳定的提升。
模块
这篇文章提出了模型主要包含三个部分:Matching Histogram Mapping, Feed forward Model, Term Gating Network 三个模块。
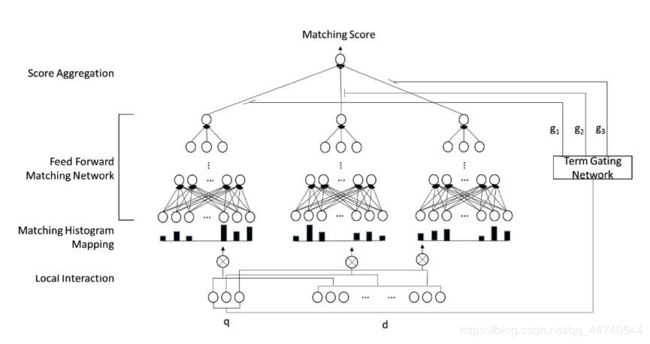
Matching Histogram Mapping模块:
输入:query中的每个词和doc所有词产生term pair,对于每一个pair使用相似度计算(论文中使用了余弦距离),考虑到位置对于匹配问题其实没有影响,此处不用位置信息Local interaction,而是将每个pair的相似度进行分级(即将相似性统计成一个直方图的形式,称之为document-aware q-term encoding)
e.g.:
Query:“ car ” ;
Document:(car,rent, truck, bump, injunction, runway)。
两两计算相似度为(1,0.2,0.7,0.3,-0.1,0.1),将[-1,1]的区间分为{[−1,−0.5], [−0.5,−0],[0, 0.5], [0.5, 1], [1, 1]} 5个区间。
可将原相似度进行统计,可以表示为[0,1,3,1,1]
论文探讨了三种直方图匹配的方法:
Count-based Histogram (CH): This is the simplest way
of transformation as described above which directly
takes the count of local interactions in each bin as the
histogram value.
Normalized Histogram (NH): We normalize the count
value in each bin by the total count to focus on the
relative rather than the absolute number of different
levels of interactions.
LogCount-based Histogram (LCH): We apply logarithm
over the count value in each bin, both to reduce the
range, and to allow our model to more easily learn
multiplicative relationships
基于次数的直方图(CH):这是最简单的方法
如上述所直接描述的变换
将每个bin中的本地交互计数作为直方图的值。
归一化直方图(NH):我们对计数进行归一化
值在每个容器中按总计数集中
相对的而不是绝对的不同的数量水平的交互。
基于对数的直方图(LCH):我们使用对数
超过计数值的每个箱子,都要减少范围,
并让我们的模型更容易学习乘法的关系
- 直方图相对于matching matrix的优点:
1.通过直方图,区别不同的匹配信号,而不像matching matrix所有匹配信号都混杂在一起
2.不需要zero padding,在matching matrix 中对于短文本需要进行padding,从而对其造成影响
Feed forward Matching Network模块:
即前馈神经网络模块,用来提取更高层次的相似度信息,对query的每个词形成的直方图(document-aware q-term encoding)输入到前馈神经网络
对于一个query q = { w 1 ( q ) , . . . , w M ( q ) } q = \{w^{(q)}_1,...,w^{(q)}_M\} q={w1(q),...,wM(q)}
对于一个document d = { w 1 ( d ) , . . . , w N ( d ) } d=\{w^{(d)}_1,...,w^{(d)}_N\} d={w1(d),...,wN(d)}
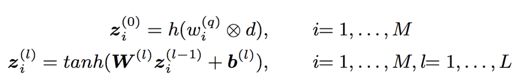
⨂ 代表interaction,也就是matching function for each pair of word vectors;
h() 就是上述的将相似度映射到一个fixed length histogram vector的函数了
z i ( 0 ) z_i^{(0)} zi(0) 表示histogram的计算
z i ( l ) z_i^{(l)} zi(l)表示feed forward matching network的整体输出
feed forward matching network最后一层并未使用tanh作为激活函数,而是直接输出全链接结果。
There are no special reason for the tanh in last full connection. In the original
paper, we added tanh in the TREC dataset, and found it worked good.
While we work on larger datasets like WikiQA, we found it is better to remove it.
In fact, I have no better idea about it. There needs more experiments to figure it
out.
Term Gating Network模块:
用来区分query中不同term的重要性(衡量query中term的importances的权重)。有TermVector和Inverse Document Frequency两种方式
使用softmax计算权重分布(term gating network的输出):
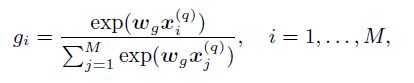
其中, w g w_g wg 代表weight vector,与 x i ( q ) x^{(q)}_i xi(q)维度相同,是一个训练参数; x i ( q ) x^{(q)}_i xi(q)是query中的每个词的embedding。得到权重分布后,对每个query词针对于一个doc的相关性分数计算加权和得到最终的相关性得分:

其中训练时,采用pairwise的loss值(基于pairwise的learning-to-rank框架),表示为pairwise ranking loss : triple (q,d+,d−) ,其中d+为正例,d-为负例。
hinge损失:
![]()
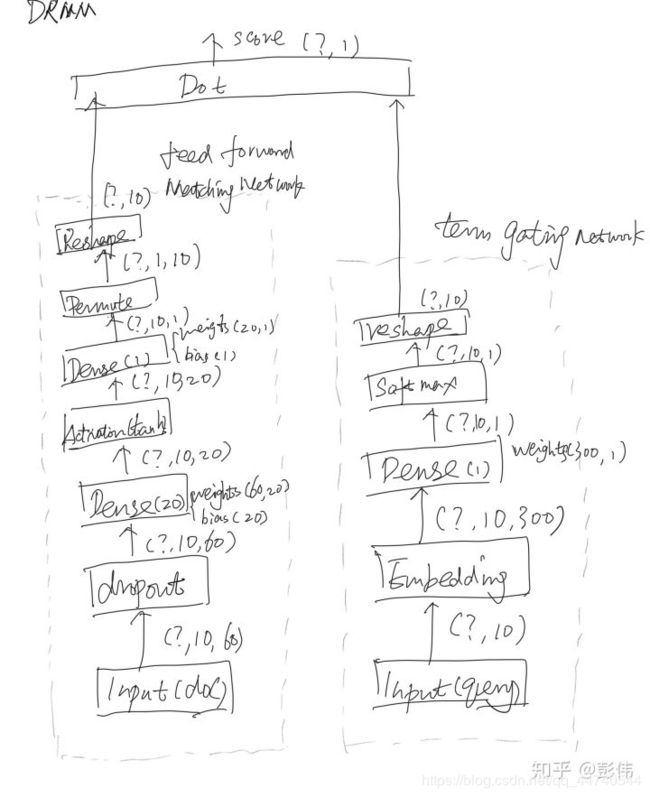
附知乎用户“彭伟”的初始化模块图
参考材料:
原文:A Deep Relevance Matching Model for Ad-hoc Retrieval
CSDN 论文阅读 | A Deep Relevance Matching Model for Ad-hoc Retrieval
CSDN DRMM model
知乎 一种深度相关性匹配模型(DRMM)的实现
知乎 Enhanced DRMM检索模型阅读笔记
智能立方 论文引介 | A Deep Relevance Matching Model for Ad-hoc Retrieval
文献 Deep Relevance Ranking Using Enhanced Document-Query Interactions
Learning-to-rank
- 学习排序 Learning to Rank 小结
- 排序学习(Learning to Rank)
- Learning to Rank算法介绍:RankSVM 和 IR SVM