上期我们谈到了系统综述和Meta分析的常用软件工具,今天我们就来重点解析一下Meta分析的方法步骤。
Meta分析是对具备特定条件的、同课题的诸多研究结果进行综合的一类统计方法,通常用于支持研究经费申请,指导临床实践和健康政策。
由于用于计算Meta分析的软件和脚本的广泛可用性,Meta分析可能会在已发表研究领域中以指数增长的形式持续下去,比如在心理科学中的运用(图1)。。
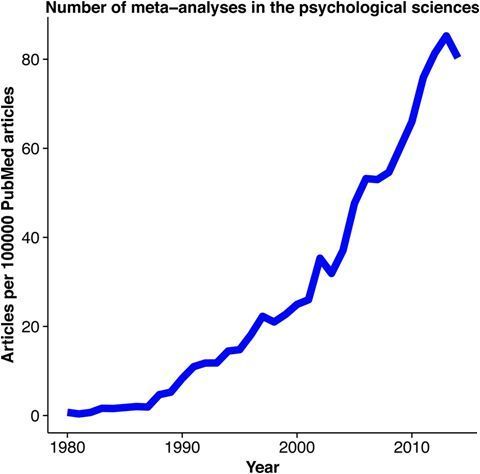
图1. 心理科学中的Meta分析
本文的目的是提供一个简短的Meta分析非技术性入门,以指导读者完成从预注册到结果发布的整个过程。
在心理学中发表最多Meta分析的25种期刊中,超过一半建议使用PRISMA指南,或相关Meta分析报告标准(MARS)(图2)。因此,本文将演示如何按照PRISMA指南进行Meta分析。本文提供了一个补充的R脚本来演示论文中描述的每个分析步骤,该步骤很容易适应研究人员用于他们自己的数据分析。
同时还强调了Meta分析声明和预注册的重要性,以提高透明度并帮助避免意外重复。更好地理解这个工具不仅可以帮助科学家进行他们自己的Meta分析,还可以改善他们对已发表Meta分析的评估。
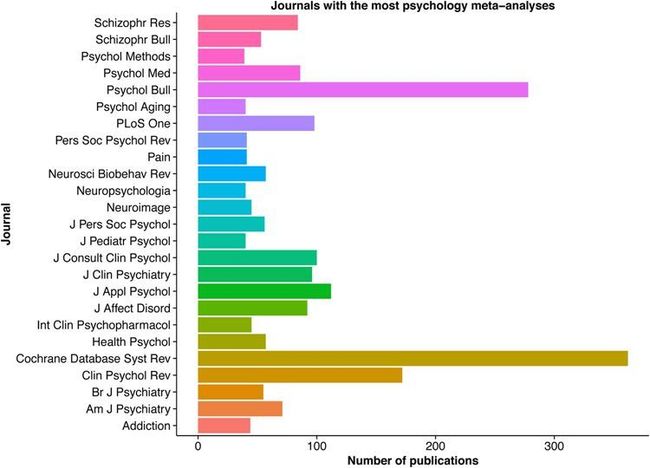
图2. 发表最多Meta分析的心理学期刊
一、Meta分析声明和预注册
预先登记Meta分析声明的主要好处是双重的。首先,预注册过程迫使研究人员为特定研究问题制定研究理论基础;其次,预注册通过提供先验分析目的的证据有助于避免偏倚。
在Meta分析的情况下,可以在已知结果以适应广受欢迎的结果或减少发表偏倚的证据后调整入选标准。PRISMA(PRISMA-P)指南提供了报告Meta分析声明的框架。这些指南建议声明应该包括以下详细信息,如研究原理,研究资格标准,检索策略,调节变量,偏倚风险和统计方法。
由于Meta分析是迭代过程,声明可能会随着时间的推移而发生变化。实际上,超过20%的Meta分析改变了原始声明。通过在分析之前记录声明,这些变化是一目了然的。与原始声明的任何偏差都可以在文章的方法部分中说明。
Meta分析可以在PROSPERO数据库中注册。虽然大多数期刊没有明确规定Meta分析注册是一项要求,但许多期刊要求提交PRISMA检查表,其中包括声明和研究注册。此外,预注册可能有助于避免意外的Meta分析重复,检查其他研究人员是否正在进行类似的Meta分析,可以节省宝贵的资源。
二、文学搜索和数据收集
Meta分析最重要的步骤之一是数据收集。为了进行有效的数据库搜索,需要确定适当的关键词和搜索限制。有许多数据库可供使用(例如PubMed, Embase, PsychInfo),然而,研究人员需要为他们的研究领域选择最合适的资源。可以根据PRIMSA流程图进行搜索并记录相关信息,该流程图详细介绍了所有阶段的信息流(图3)。
因此,重要的是要注意在使用指定的搜索术语后反馈了多少研究,丢弃了多少研究,以及出于什么原因。搜索术语和策略应该足够具体,以便读者重现搜索。还应提供研究的日期范围以及进行搜索的日期。
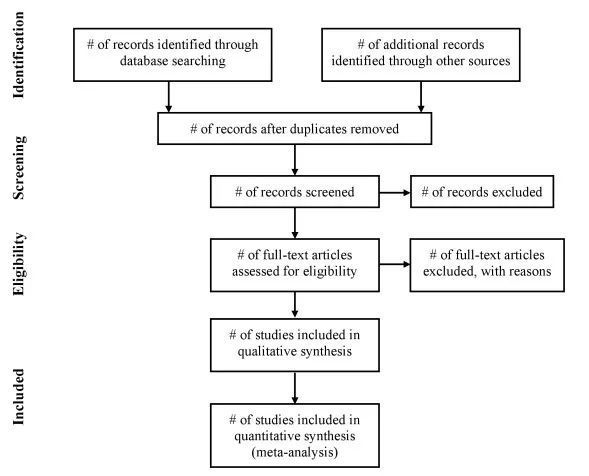
图3 PRIMSA流程图
数据收集表提供了从符合条件的研究中收集数据的标准化方法。对于相关数据的Meta分析,效应量信息通常被收集为Pearson’s r统计量。部分相关性通常在研究的报告中,然而,与零阶相关性相比,这些可能会扩大相关性。此外,部分变量可能因研究而异。许多Meta分析排除了与其分析的部分相关性。因此,应联系研究作者以提供缺失数据或零级相关性。
最后一个考虑因素是是否包括灰色文献的研究,灰色文献被定义为尚未正式发表的研究。这类文献包括会议摘要,论文和预印本。虽然包含灰色文献降低了发表偏倚的风险,但作品的方法学质量通常(但并非总是)低于正式发表的作品。无论如何,Meta分析应明确详细说明研究方案和方法中的搜索策略。
三、分析
各种工具可用于运行Meta分析,例如综合Meta分析和SPSS语法文件。对于本文,将使用R的“metafor”和“robumeta”软件包(R Development Core Team, 2015)。为了进行说明,将分析来自16项研究(Molloy等, 2014)Meta分析的数据,该研究分析了调查责任心和药物依从性之间的关联。
数据集包括相关性,研究样本量,以及可以评估为潜在调节变量的一系列连续(例如,平均年龄)和分类变量(例如,所使用的尽责性测量的类型)。这个Meta分析的数据以及分析示例都包含在metafor包中。与本文相关的脚本详细介绍了本文所述分析的所有方面,读者可以根据这些方面对相关数据进行自己的Meta分析。
第一个分析步骤是将数据从收集表格输入到.csv文件中以便在R中进行分析。由于Pearson’s r不是正态分布的,因此这些值将转换为Fisher's z标度。Meta分析中通常采用两种模型:固定效应模型和随机效应模型。固定效应模型假设所有研究都来自单一的常见群体,在类似条件下进行测试,不考虑研究的异质性,可能会高估综合效应量。而随机效应模型研究来自不同的群体,为了实现更少差异,加大了研究量。
在进行Meta分析计算后,应将Fisher's z转换回Pearson's r,以报告平均相关性和95%CI。对示例数据进行分析后发现,综合相关性和95%CI表明了责任心和药物依从性之间存在显著但适度的关系[r = 0.15; 95%CI(0.09,0.21),p <0.0001]。
四、异质性研究
观察到的效应差异有两个来源:研究内误差和效应量的真实异质性。出于Meta分析的目的,我们对效应量的真正异质性感兴趣。计算Q-统计量,即观察到的差异与研究内方差的比率,可以揭示整体异质性中有多少可归因于真实的研究间变化。相关的I2统计量是表示观察到的差异比例的百分比(其中25%,50%和75%分别代表低、中和高差异),其可以归因于研究之间的实际差异,而不是研究内的差异。
与Q统计量相比,I2的两个主要优点是它对所包含的研究数量不敏感,并且还可以计算CI。Tau-squared也可用于评估随机效应模型中研究异质性的总量。当Tau-squared为零时,这表明没有异质性。在示例数据中,I2为61.73%(95%CI; 25.28, 88.25),表示中度到高度的差异,Q统计量为38.16(p = 0.001),Tau-squared为0.008(95%CI; 0.002, 0.038)。
尽管这些测试提供了异质性的证据,但它们并未提供哪些研究可能不成比例地影响异质性。Baujat图可以很好的解析过度促成异质性和整体结果的研究。图的横轴表示研究异质性,而纵轴表示研究对整体结果的影响。落入图右上象限的研究对这两个因素贡献最大。检查从示例数据集生成的Bajaut图显示了三个研究对这两个因素都有贡献(图4)。
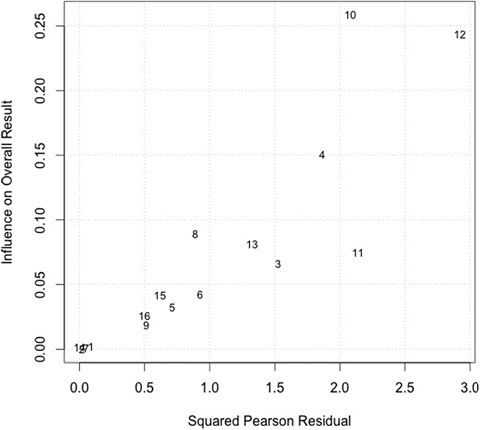
图4. 用于识别导致异质性的研究的Baujat图
五、森林图
森林图可以显示纳入研究中的效应量和CI,以及计算的综合效应量。图5显示了根据示例数据计算的森林图。每项研究都由一个点评估来表示,该点评估由效应的CI限定。综合效应量由图底部的多边形表示,多边形的宽度表示95%CI。与高I2和显著的Q统计量一致,森林图显示了异质性研究的样本。与其他研究相比,较大方阵的研究对综合效应量的贡献更大。在随机效应模型中,方阵的大小与CI和研究间差异相关。
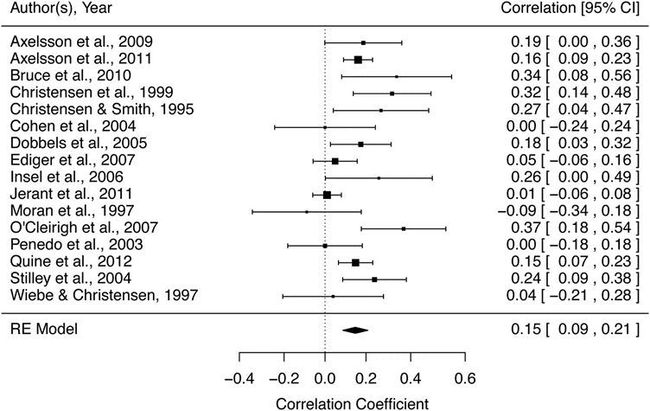
图5. 示例数据的森林图
责任心和药物依从性之间关系的示例数据总结。Meta分析中包含的每项研究均由点估计表示,该点估计以95%CI为界。综合效应量在图的底部显示为多边形,多边形的宽度表示95%CI。
六、发表偏倚
发表偏倚是一种现象,即具有更强效应量的研究更有可能被发表并随后被纳入Meta分析。漏斗图是一种可视化工具,用于检查Meta分析中潜在的发表偏倚。漏斗线以综合效应量为中心,由垂直线表示,这些点应等效地分布在漏斗线的两侧(图6A)。图6B使用从示例数据集中移除三个研究的模拟来说明漏斗的不均匀性,为发表偏倚提供了证据。
如果有发表偏倚的证据,可以使用修剪和填充方法。该方法假设漏斗图不对称是由于发表偏倚,通过将“缺失”研究归结为增加漏斗图对称性来调整Meta分析(图6C)。这种更新的估算研究的Meta分析不应用于形成结论,因为这些不是真正的研究,只是为了平衡不对称的漏斗图。图5A,C的比较说明了这一点,因为该方法被设计为仅通过创建现有研究的镜像来近似缺失的研究。
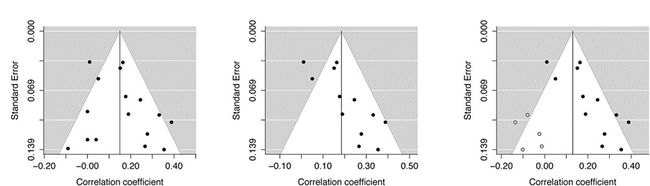
图6. 漏斗图以说明发布偏倚
漏斗图(A)包括Molloy等人的所有16项研究(2014)。 该图示出了对称性(即,点落在综合效应量的两侧)。漏斗图(B)模拟了移除Molloy等人数据集中的三种小效应和大标准误差的研究。情节不再是对称的,证明了发表偏倚的证据。漏斗图(C)修剪和填充程序会导致缺失的研究(空心圆圈),以创建更加对称的漏斗图。
七、调节变量分析
调节变量有助于观察到一些差异。因此,可以进行调节变量分析以确定异质性的来源以及这对研究之间观察到的效应量的变化有多大贡献。调节变量可以是连续变量或分类变量。例如,可以使用Meta回归模型进行调节变量分析,以检查平均年龄对Molloy等人(2014)数据集的影响。计算该分析表明,年龄没有调节效应[Q(1)= 1.43,p = 0.23]。
另外,可以检查方法学质量的调节效应。对实例数据的分析表明,方法学质量也没有缓和相关性[Q(1)= 0.64,p = 0.42]。然而,调节变量分析表明变量分类是否研究控制变量(是/否)是一个重要的调节者[Q(1)= 20.12,p <0.0001]。虽然可能存在其他未明确的研究异质性来源,但数据表明控制研究中的变量有助于整体观察到的异质性。
八、从单个研究中获得多种效应量的计算
如果从同一研究中收集了多组数据,则由于统计依赖性问题,应考虑这些研究中效应量的内部统计依赖性。最直接的方法是仅使用预先指定的标准收集每个研究的效应量。或者,可以聚合效应量(参见'MAc'R包中的'Agg'功能)。然而,如果没有报告研究内相关性,研究人员必须估计预期的相关性水平。
Robust方差评估(RVE)可以在不了解研究内相关性的情况下解释非独立效应。为了说明使用RVE处理多种效应量,我们创建了一个新的模拟数据集,其中前三个研究来自样本数据集,就像它们是从一项研究报告的三种效应量一样。使用RVE分析显示统计学上显著的点估计[0.15; 95%CI(0.08,0.22),p = 0.001]。
九、数据解释和报告
Meta分析的最后一步是数据解释和写作。PRISMA指南提供了一份列表,其中包括报告Meta分析时应包括的所有项目。遵循此列表将有助于确保报告Meta分析的质量,并有助于改进对稿件的评估。同时还可以提供用于分析的R脚本作为补充材料以帮助再现性。
本文的目的是提供一个非技术性的入门书,用于按照黄金标准指南进行相关数据的Meta分析。Meta分析是一种有效的数据合成方法,即使只需要两到三项研究,也可以有效地提高统计精度。
本文利用可自由访问的软件演示了Meta分析的每个分析步骤,其中补充脚本提供了执行本文所述分析的必要代码。还讨论了数据可视化的方法,识别可能过度影响样本异质性的研究,以及组合来自个体研究的多种效应量。还描述了关于发表偏倚和调节变量分析的Meta分析数据解释。
参考资料(图片均来自文献):
From pre-registration to publication: a non-technical primer for conducting a meta-analysis to synthesize correlational data;
Conscientiousness and medication adherence: a meta-analysis.
• END •