- 请求:导入import requests
- r=requests.get('中间是网址') 再提取 html=r.content
- 解析:导入package(包)
- from bs4 import BeautifulSoup 然后创建一BeautifulSoup对象:soup = BeautifulSoup(html,'html.parser') #html.parser是解析器a_s = div_people_list.find_all('a', attrs={'target': '_blank'}); 使用BeautifulSoup对象的find方法
div_people_list = soup.find('div', attrs={'class': 'people_list'})
这里我们使用了BeautifulSoup对象的find方法。这个方法的意思是找到带有‘div’这个标签并且参数包含" class = 'people_list' "的HTML代码。如果有多个的话,find方法就取第一个。那么如果有多个呢?正好我们后面就遇到了,现在我们要取出所有的“a”标签里面的内容:
a_s = div_people_list.find_all('a', attrs={'target': '_blank'})
这里我们使用find_all方法取出所有标签为“a”并且参数包含“ target = ‘_blank‘ ”的代码,返回一个列表。“a”标签里面的“href”参数是我们需要的老师个人主页的信息,而标签里面的文字是老师的姓名。我们继续:
这里我们使用BeautifulSoup支持的方法,使用类似于Python字典索引的方式把“a”标签里面“href”参数的值提取出来,赋值给url(Python实际上是对对象的引用),用get_text()方法把标签里面的文字提起出来。
1、请求
这里我们使用的package是requests。这是一个第三方模块(具体怎么下载以后再说),对HTTP协议进行了高度封装,非常好用。所谓HTTP协议,简单地说就是一个请求过程。我们先不管这玩意是啥,以后再讨论。这个部分,我们要实现的目的是把网页请求(或者说下载)下来。
首先我们导入requests
:
import requests
下面调用requests
的get函数,把网页请求下来:
r = requests.get('http://www.wise.xmu.edu.cn/people/faculty')
返回的“r”的是一个包含了整个HTTP协议需要的各种各样的东西的对象。我们先不管都有啥,先把我们需要的网页提取出来:
html = r.content
好了,到这一步我们已经获取了网页的源代码。具体源代码是什么样的呢?右键,点击“查看源文件”或者“查看源”就可以看到:
view-source:http://www.wise.xmu.edu.cn/people/faculty
2、解析
当然从这一大坨代码里面找信息太麻烦了。我们可以用浏览器提供的另外一个工具:审查元素。这里我们先不讲怎么使用审查元素,先从源代码里面找。找到的我们需要的信息如下:
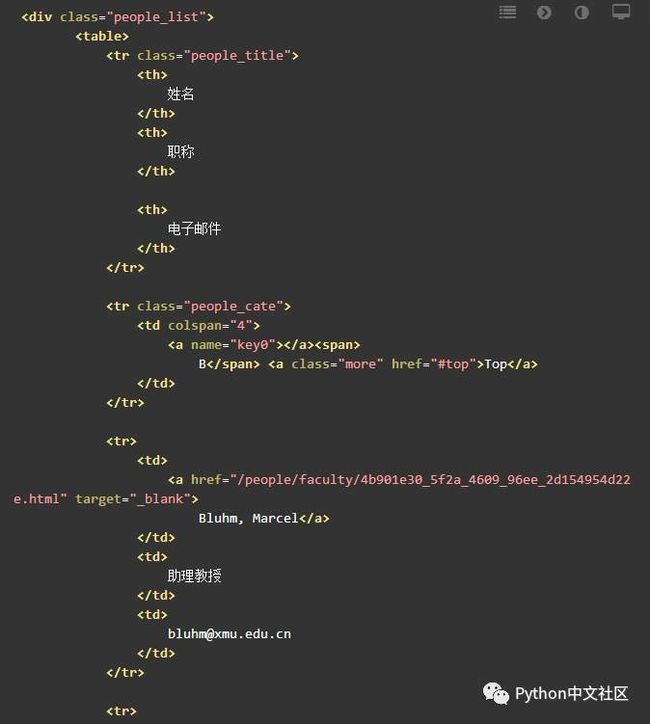
这里我们使用bs4来解析。bs4是一个非常好的解析网页的库,后面我们会详细介绍。这次的解析先给大家看bs4里面最常用的几个BeautifulSoup对象的方法(method)。我们使用的这几个方法,主要是通过HTML的标签和标签里面的参数来定位,然后用特定方法(method)提取数据。
首先还是导入package:
from bs4 import BeautifulSoup
然后创建一个BeautifulSoup对象:
soup = BeautifulSoup(html,'html.parser') #html.parser是解析器
下面我们根据我们看到的网页提取。首先提取我复制的这部分的代码的第一行,先定位到这部分代码:
div_people_list = soup.find('div', attrs={'class': 'people_list'})
这里我们使用了BeautifulSoup对象的find方法。这个方法的意思是找到带有‘div’这个标签并且参数包含" class = 'people_list'
"的HTML代码。如果有多个的话,find方法就取第一个。那么如果有多个呢?正好我们后面就遇到了,现在我们要取出所有的“a”标签里面的内容:
a_s = div_people_list.find_all('a', attrs={'target': '_blank'})
这里我们使用find_all
方法取出所有标签为“a”并且参数包含“ target = ‘_blank‘
”的代码,返回一个列表。“a”标签里面的“href”参数是我们需要的老师个人主页的信息,而标签里面的文字是老师的姓名。我们继续:
for a in a_s:
url = a['href']
name = a.get_text()
这里我们使用BeautifulSoup支持的方法,使用类似于Python字典索引的方式把“a”标签里面“href”参数的值提取出来,赋值给url(Python实际上是对对象的引用),用get_text()
方法把标签里面的文字提起出来。
事实上,使用这四个方法就可以正常地解析大部分HTML了。不过如果只用这四个方法,很多程序会写的异常原始。所以我们后面再继续介绍更多解析方法。
储存
这里我们先弱化一下具体的储存方法,先输出到控制台上面。我们在刚才的代码的基础上加一行代码:
for a in a_s:
url = a['href']
name = a.get_text()
print name,url
使用print关键词把得到的数据print出来。让我们看看结果:

好的,到这里一个原型就完成了。这就是一个非常简单的爬虫,总代码不过十几行。复杂到几百几千行的爬虫,都是在这样的一个原型的基础上不断深化、不断完善得到的。
from bs4 import BeautifulSoup
import requests
r = requests.get('http://www.wise.xmu.edu.cn/people/faculty')
html = r.content
view-source:http://www.wise.xmu.edu.cn/people/faculty
soup = BeautifulSoup(html,'html.parser') #html.parser是解析器
div_people_list = soup.find('div', attrs={'class': 'people_list'})
a_s = div_people_list.find_all('a', attrs={'target': '_blank'})
for a in a_s:
url = a['href']
name = a.get_text()
for a in a_s:
url = a['href']
name = a.get_text()
print (name,url)
原网页http://www.100weidu.com/weixin/CMy033CKgj