自动驾驶汽车到底涉及了哪些技术?
Google从2009年开始做自动驾驶,到现在已有8个年头。8个年头的技术积累还无法将自动驾驶技术量产落地,可见自动驾驶技术并不简单。
自动驾驶是一个庞大而且复杂的工程,涉及的技术很多,大部分答主仅从软件方面进行了介绍,而且太过细致。我从硬件和软件两方面谈一谈自动驾驶汽车所涉及的技术。
一. 硬件
离开硬件谈自动驾驶都是耍流氓。
先看个图,下图基本包含了自动驾驶研究所需要的各种硬件。
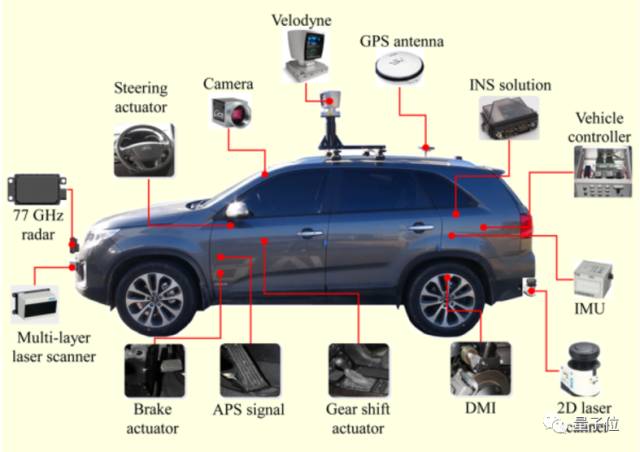
然而…
这么多传感器并不一定会同时出现在一辆车上。某种传感器存在与否,取决于这辆车需要完成什么样的任务。如果只需要完成高速公路的自动驾驶,类似Tesla 的 AutoPilot 功能,那根本不需要使用到激光传感器;如果你需要完成城区路段的自动驾驶,没有激光传感器,仅靠视觉是很困难的。
自动驾驶系统工程师要以任务为导向,进行硬件的选择和成本控制。
1.汽车
既然要做自动驾驶,汽车当然是必不可少的东西。
从我司做自动驾驶的经验来看,做开发时,能不选纯汽油车就别选。
一方面是整个自动驾驶系统所消耗的电量巨大,混动和纯电动在这方面具有明显优势。另一方面是是发动机的底层控制算法相比于电机复杂太多,与其花大量时间在标定和调试底层上,不如直接选用电动车研究更高层的算法。
国内也有媒体专门就测试车辆的选择做过调研。
调研文章地址:
http://www.sohu.com/a/139046349_120865
2.控制器
在前期算法预研阶段,推荐使用工控机(Industrial PC,IPC)作为最直接的控制器解决方案。因为工控机相比于嵌入式设备更稳定、可靠,社区支持及配套的软件也更丰富。
百度开源的Apollo推荐了一款包含GPU的工控机,型号为Nuvo-5095GC,如下图。

当算法研究得较为成熟时,就可以将嵌入式系统作为控制器,比如Audi和TTTech共同研发的zFAS,目前已经应用在最新款Audi A8上量产车上了。

3.CAN卡
工控机与汽车底盘的交互必须通过专门的语言——CAN。从底盘获取当前车速及方向盘转角等信息,需要解析底盘发到CAN总线上的数据;工控机通过传感器的信息计算得到方向盘转角以及期望车速后,也要通过 CAN卡 将消息转码成底盘可以识别的信号,底盘进而做出响应。
CAN卡可以直接安装在工控机中,然后通过外部接口与CAN总线相连。
Apollo使用的CAN卡,型号为ESD CAN-PCIe/402,如下图。

4.全球定位系统(GPS)+惯性测量单元(IMU)
人类开车,从A点到B点,需要知道A点到B点的地图,以及自己当前所处的位置,这样才能知道行驶到下一个路口是右转还是直行。
无人驾驶系统也一样,依靠GPS+IMU就可以知道自己在哪(经纬度),在朝哪个方向开(航向),当然IMU还能提供诸如横摆角速度、角加速度等更丰富的信息,这些信息有助于自动驾驶汽车的定位和决策控制。
Apollo的GPS型号为NovAtel GPS-703-GGG-HV,IMU型号为NovAtel SPAN-IGM-A1。

5.感知传感器
相信大家对车载传感器都耳熟能详了。
感知传感器分为很多种,包括视觉传感器、激光传感器、雷达传感器等。
视觉传感器就是摄像头,摄像头分为单目视觉,双目(立体)视觉。比较知名的视觉传感器提供商有以色列的Mobileye,加拿大的PointGrey,德国的Pike等。
激光传感器分为单线,多线一直到64线。每多一线,成本上涨1万RMB,当然相应的检测效果也更好。比较知名的激光传感器提供商有美国的Velodyne和Quanergy,德国的Ibeo等。国内有速腾聚创和禾赛科技。
雷达传感器是车厂Tier1的强项,因为雷达传感器已经在汽车上得到了广泛使用。知名的供应商当然是博世、德尔福、电装等。
6.硬件部分总结
组装一套可以完成某项功能的自动驾驶系统需要及其丰富的经验,并且要对各传感器的性能边界及控制器计算能力了如指掌。优秀的系统工程师能在满足功能的要求下将成本控制在最低,使其量产、落地的可能性更大。
二. 软件
大部分答主已对软件进行了阐述,我也从我的角度介绍以下软件的开发。
软件部分的内容已在我的回答:无人驾驶,个人如何研究? 中进行了介绍。
《无人驾驶,个人如何研究?》文章链接:
https://www.zhihu.com/question/20210846/answer/215490332
以下内容前半段为搬运。
软件包含四层:感知、融合、决策、控制。
各个层级之间都需要编写代码,去实现信息的转化,更细化的分类如下。
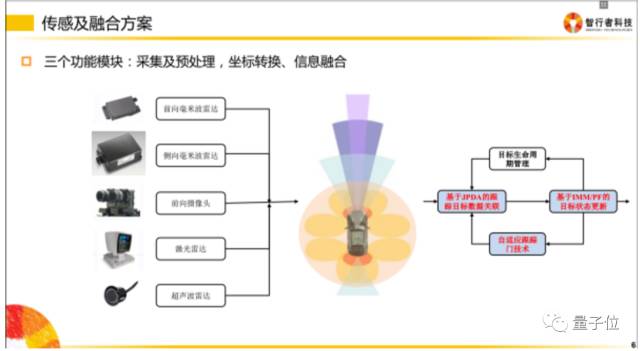
1.采集
传感器跟我们的PC或者嵌入式模块通信时,会有不同的传输方式。
比如我们采集来自摄像机的图像信息,有的是通过千兆网卡实现的通信,也有的是直接通过视频线进行通信的。再比如某些毫米波雷达是通过CAN总线给下游发送信息的,因此我们必须编写解析CAN信息的代码。
不同的传输介质,需要使用不同的协议去解析这些信息,这就是上文提到的“驱动层”。
通俗地讲就是把传感器采集到的信息全部拿到,并且编码成团队可以使用的数据。
2.预处理
传感器的信息拿到后会发现不是所有信息都是有用的。
传感器层将数据以一帧一帧、固定频率发送给下游,但下游是无法拿每一帧的数据去进行决策或者融合的。为什么?
因为传感器的状态不是100%有效的,如果仅根据某一帧的信号去判定前方是否有障碍物(有可能是传感器误检了),对下游决策来说是极不负责任的。因此上游需要对信息做预处理,以保证车辆前方的障碍物在时间维度上是一直存在的,而不是一闪而过。
这里就会使用到智能驾驶领域经常使用到的一个算法——卡尔曼滤波。
3.坐标转换
坐标转换在智能驾驶领域十分重要。
传感器是安装在不同地方的,比如超声波雷达(上图中橘黄色小区域)是布置在车辆周围的;当车辆右方有一个障碍物,距离这个超声波雷达有3米,那么我们就认为这个障碍物距离车有3米吗?
并不一定!因为决策控制层做车辆运动规划时,是在车体坐标系下做的(车体坐标系一般以后轴中心为O点),所以最终所有传感器的信息,都是需要转移到自车坐标系下的。
因此感知层拿到3m的障碍物位置信息后,必须将该障碍物的位置信息转移到自车坐标系下,才能供规划决策使用。
同理,摄像机一般安装在挡风玻璃下面,拿到的数据也是基于摄像机坐标系的,给下游的数据,同样需要转换到自车坐标系下。
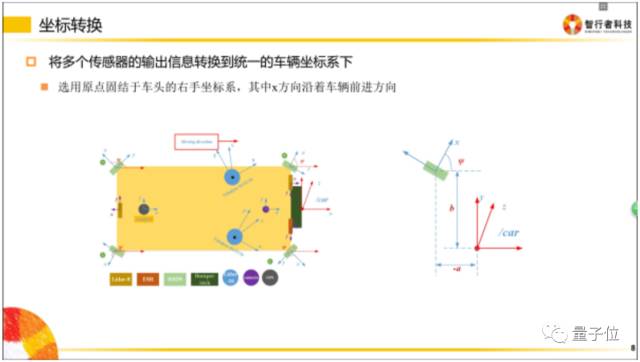
什么是自车坐标系?
请拿出你的右手,以大拇指 → 食指 → 中指 的顺序开始念 X、Y、Z。
然后把手握成如下形状:

把三个轴的交点(食指根部)放在自车坐标系后轴中心,Z轴指向车顶,X轴指向车辆前进方向。
各个团队可能定义的坐标系方向不一致,只要开发团队内部统一即可。
4.信息融合
信息融合是指把相同属性的信息进行多合一操作。
比如摄像机检测到了车辆正前方有一个障碍物,毫米波也检测到车辆前方有一个障碍物,激光雷达也检测到前方有一个障碍物,而实际上前方只有一个障碍物,所以我们要做的是把多传感器下这辆车的信息进行一次融合,以此告诉下游,前面有一辆车,而不是三辆车。

5.决策规划
这一层次主要设计的是拿到融合数据后,如何正确做规划。规划包含纵向控制和横向控制。
纵向控制即速度控制,表现为 什么时候加速,什么时候制动。
横向控制即行为控制,表现为 什么时候换道,什么时候超车等
6.软件长什么样子?
自动驾驶系统中的部分软件看起来和下面类似。
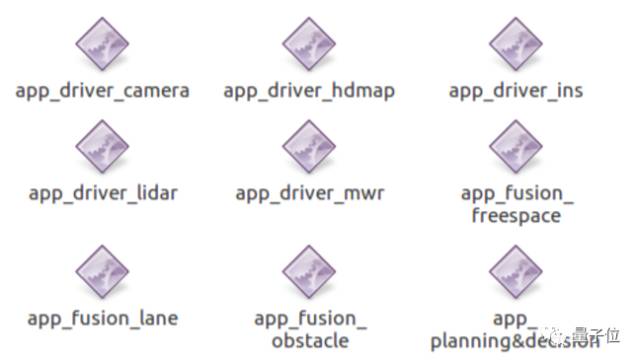
app_driver_camera 摄像机驱动
app_driver_hdmap 高精度地图驱动
app_driver_ins 惯导驱动
app_driver_lidar 激光传感器驱动
app_driver_mwr 毫米波传感器驱动
app_fusion_freespace 自由行驶区域融合
app_fusion_lane 车道线融合
app_fusion_obstacle 障碍物融合
app_planning&decision 规划决策
然而实际上攻城狮们会编写一些其他软件用于自己的调试工作,比如记录数据和回放数据的工具。

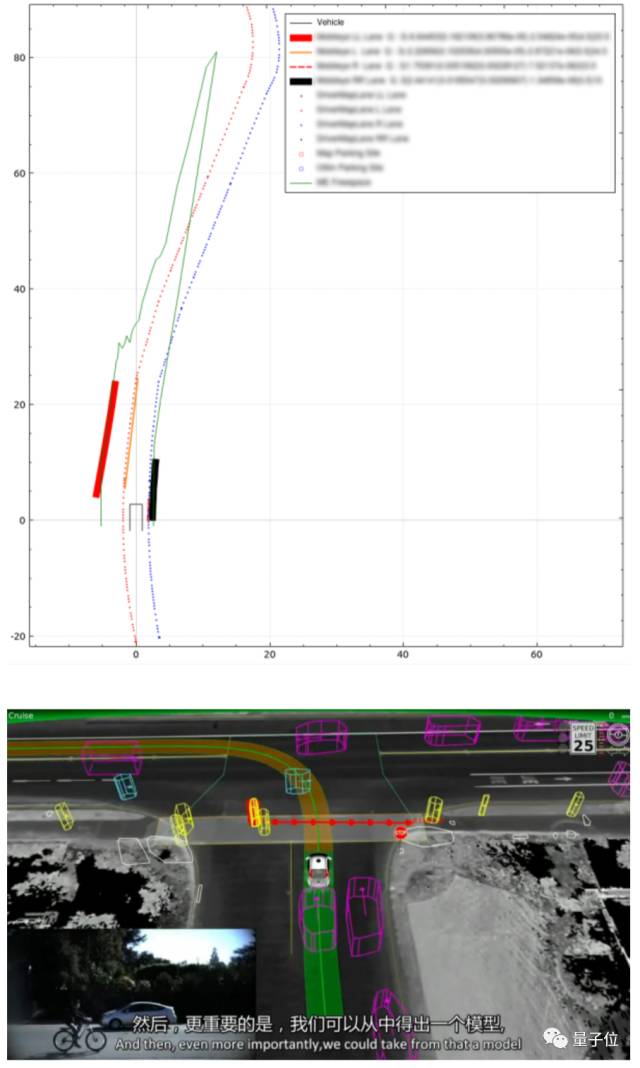
还有用于传感器信息显示的可视化程序,类似下图的效果。
点击左下角“阅读原文”处,解锁作者的更多文章
还可以直接参与讨论~
— 完 —