Attention机制细节及代码讲解
Attention机制
attention机制是用于提升基于LSTM(GRU,RNN)的encoder、decoder模型的方法,被广泛应用于nlp的生成模型中。
attention方法之所以好用,是因为attention方法可以给模型赋予区分辨别的能力,例如在机器翻译中,可以为不同的词赋予不同的权重以表示单词的重要程度,这使神经网络模型更加灵活。
1.传统encoder-decoder模型
在传统的seq2seq模型中,本质就是寻找一个从输入X到输出Y的映射关系。其中下图的长方形单元就是(LSTM,GRU,RNN等)就是通过这些神经网络单元来搭建输入到输出的映射关系。
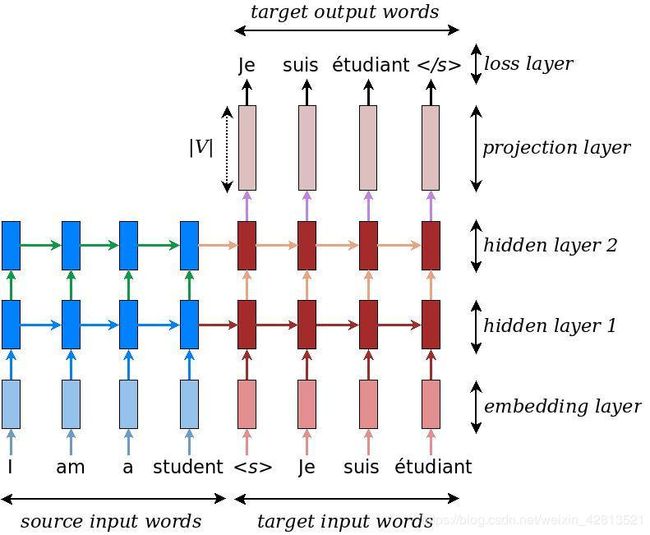
但是如上图所示,神经网络模型选择GRU单元。在encoder中最先输入的单词‘I’经过一系列GRU单元到达decoder时,虽然输入融合了一部分输入单词‘I’的信息,但是单词‘I’的信息已经损耗了一大部分,这使得decoder预测的不准确。(这就是引入attention的重要原因)。
2.attention机制
attention机制通过给输入的单词施加一定的权重,使得在预测某个词的时候可以重点关注某个输入词。
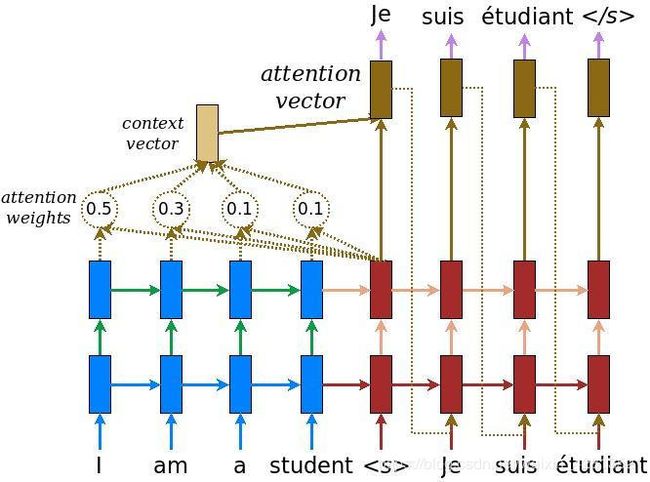
如下图所示:
比如在decoder生成‘Je’的时候,输入‘I am a student’四个单词分别具有[05,0.3,0.1,0.1]的attention weight,这样,在decoder中就会更加关注‘I’这个单词。这就是attention的简单理解:
attention通过以下公式计算(下面还有具体的代码实现细节):
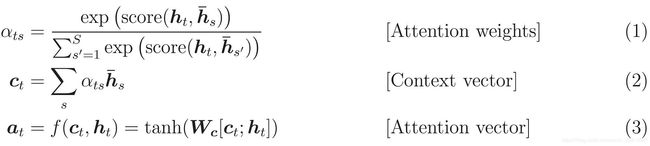
attention weight 通过encoder-output和decoder中的hidden-state先进行激活函数tanh然后再接一层全连接层(size=max_len输入的长度),最后加个softmax层就会得到各个单词的attention_weight。
将attention_weight和eoncoder_output输出对应相乘然后相加就会得到context vector。
最后将context vector和decoder的输入的embedding做一个concat后就可以得到attention_vector.
下面是实现的具体细节:
FC = Fully connected (dense) layer
EO = Encoder output
H = hidden state
X = input to the decode
score = FC(tanh(FC(EO) + FC(H)))
attention weights = softmax(score, axis = 1). Softmax by default is applied on the last axis but here we want to apply it on the 1st axis, since the shape of score is (batch_size, max_length, hidden_size). Max_length is the length of our input. Since we are trying to assign a weight to each input, softmax should be applied on that axis.
context vector = sum(attention weights * EO, axis = 1). Same reason as above for choosing axis as 1.
embedding output = The input to the decoder X is passed through an embedding layer.
merged vector = concat(embedding output, context vector)
This merged vector is then given to the GRU
下面是attention实现的代码细节:
tensorflow 2.0实现
class BahdanauAttention(tf.keras.layers.Layer):
def __init__(self, units):
super(BahdanauAttention, self).__init__()
self.W1 = tf.keras.layers.Dense(units)
self.W2 = tf.keras.layers.Dense(units)
self.V = tf.keras.layers.Dense(1)
def call(self, query, values):
# query为上次的GRU隐藏层
# values为编码器的编码结果enc_output
# 在seq2seq模型中,St是后面的query向量,而编码过程的隐藏状态hi是values。
hidden_with_time_axis = tf.expand_dims(query, 1)
print("query",query.shape) #query.shape(batch_size, hadden_unit)=(64, 1024)
# 计算注意力权重值
score = self.V(tf.nn.tanh(
self.W1(values) + self.W2(hidden_with_time_axis)))
aaa=tf.nn.tanh(
self.W1(values) + self.W2(hidden_with_time_axis))
va=self.V(aaa)
print("values.shape",values.shape) #values.shape(batch_size,sequence length,hidden_unit)(64, 260, 1024)
print("hidden_with_time_axis",hidden_with_time_axis.shape)#hidden_with_time_axis (64, 1, 1024)
print("self.W1(values).shape",self.W1(values).shape)#self.W1(values).shape (64, 260, 10)
print("self.W2(hidden_with_time_axis",self.W2(hidden_with_time_axis).shape)#self.W2(hidden_with_time_axis (64, 1, 10)
print("aaa",aaa.shape)#aaa (64, 260, 10)
print("va",va.shape)#va (64, 260, 1)
print("score.shape",score.shape)#score.shape (64, 260, 1)
# attention_weights shape == (batch_size, max_length, 1)(64, 260, 1)
attention_weights = tf.nn.softmax(score, axis=1)
# # 使用注意力权重*编码器输出作为返回值,将来会作为解码器的输入
# context_vector shape after sum == (batch_size, hidden_size)
context_vector = attention_weights * values
print("context_vector........",context_vector.shape)#context_vector........ (64, 260, 1024)
context_vector = tf.reduce_sum(context_vector, axis=1)
print("context_vectorxxxxxxx",context_vector.shape)#context_vectorxxxxxxx (64, 1024)
return context_vector, attention_weights
结果:
attention_layer = BahdanauAttention(10)
sample_hidden.shape=(64, 1024)
sample_output.shape=(64, 260, 1024)
attention_result, attention_weights = attention_layer(sample_hidden, sample_output)
print("Attention result shape: (batch size, units) {}".format(attention_result.shape))
print("Attention weights shape: (batch_size, sequence_length, 1) {}".format(attention_weights.shape))
以下是代码中对应的输出维度:
Attention result shape: (batch size, units) (64, 1024)
Attention weights shape: (batch_size, sequence_length, 1) (64, 260, 1)