动手学习深度学习|机器翻译\注意力机制
机器翻译及相关技术
机器翻译(MT):将一段文本从一种语言自动翻译为另一种语言,用神经网络解决这个问题通常称为神经机器翻译(NMT)。
主要特征:输出是单词序列而不是单个单词。 输出序列的长度可能与源序列的长度不同。
分词: 字符串---单词组成的列表
建立词典: 单词组成的列表---单词id组成的列表
Encoder-Decoder: 可以应用在对话系统、生成式任务中。
encoder:输入到隐藏状态
decoder:隐藏状态到输出
集束搜索(Beam Search)
维特比算法:选择整体分数最高的句子(搜索空间太大)
二 注意力机制与Seq2Seq模型
解码的目标词语可能只与原输入的部分词语有关,而并不是与所有的输入有关,在seq2seq模型中,解码器只能隐式地从编码器的最终状态中选择相应的信息。然而,注意力机制可以将这种选择过程显式地建模。
两个常用的注意层 Dot-product Attention 和 Multilayer Perceptron Attention
1 Softmax屏蔽
softmax操作符的一个屏蔽操作
2 点积注意力
The dot product 假设query和keys有相同的维度,通过计算query和key转置的乘积来计算attention score,通常还会除去 转存失败重新上传取消减少计算出来的score对维度的依赖性
转存失败重新上传取消减少计算出来的score对维度的依赖性
3 多层感知机注意力
将key 和 value 在特征的维度上合并(concatenate),然后送至 a single hidden layer
perceptron 这层中 hidden layer 为 ℎ and 输出的size为 1 .隐层激活函数为tanh,无偏置.
4 总结
注意力层显式地选择相关的信息。
注意层的内存由键-值对组成,因此它的输出接近于键类似于查询的值。
5 引入注意力机制的Seq2seq模型
带有注意机制的seq2seq的编码器与之前章节中的Seq2SeqEncoder相同,我们添加了一个MLP注意层(MLPAttention),它的隐藏大小与解码器中的LSTM层相同。
三 Transformer
CNNs 易于并行化,却不适合捕捉变长序列内的依赖关系。
RNNs 适合捕捉长距离变长序列的依赖,但是却难以实现并行化处理序列。
为了整合CNN和RNN的优势,使用注意力机制设计了Transformer模型。该模型利用attention机制实现了并行化捕捉序列依赖,并且同时处理序列的每个位置的tokens,上述优势使得Transformer模型在性能优异的同时大大减少了训练时间。
与seq2seq模型相似,Transformer同样基于编码器-解码器架构,其区别主要在于以下三点:
Transformer blocks:将seq2seq模型重的循环网络替换为了Transformer
Blocks,该模块包含一个多头注意力层(Multi-head Attention Layers)以及两个position-wise
feed-forward networks(FFN)。对于解码器来说,另一个多头注意力层被用于接受编码器的隐藏状态。
Add and norm:多头注意力层和前馈网络的输出被送到两个“add and norm”层进行处理,该层包含残差结构以及层归一化。
Position encoding:由于自注意力层并没有区分元素的顺序,所以一个位置编码层被用于向序列元素里添加位置信息。
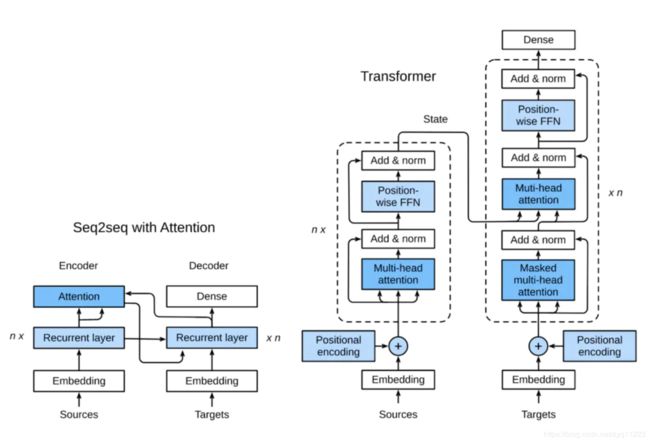
1 多头注意力层
多头注意力层包含h个并行的自注意力层,每一个这种层被成为一个head。对每个头来说,在进行注意力计算之前,我们会将query、key和value用三个现行层进行映射,这h个注意力头的输出将会被拼接之后输入最后一个线性层进行整合。

2 基于位置的前馈网络
Transformer模块另一个非常重要的部分就是基于位置的前馈网络(FFN),它接受一个形状为(batch_size,seq_length,feature_size)的三维张量。Position-wise FFN由两个全连接层组成,他们作用在最后一维上。因为序列的每个位置的状态都会被单独地更新,所以我们称他为position-wise,这等效于一个1x1的卷积。
与多头注意力层相似,FFN层同样只会对最后一维的大小进行改变;除此之外,对于两个完全相同的输入,FFN层的输出也将相等。
3 Add and Norm
除了上面两个模块之外,Transformer还有一个重要的相加归一化层,它可以平滑地整合输入和其他层的输出,因此我们在每个多头注意力层和FFN层后面都添加一个含残差连接的LayerNorm层。这里 Layer Norm 与7.5小节的Batch Norm很相似,唯一的区别在于Batch Norm是对于batch size这个维度进行计算均值和方差的,而Layer Norm则是对最后一维进行计算。层归一化可以防止层内的数值变化过大,从而有利于加快训练速度并且提高泛化性能。
4 编码器
编码器包含一个多头注意力层,一个position-wise FFN,和两个 Add and Norm层。对于attention模型以及FFN模型,我们的输出维度都是与embedding维度一致的,这也是由于残差连接天生的特性导致的,因为我们要将前一层的输出与原始输入相加并归一化。
5 解码器
Transformer模型的解码器与编码器结构类似,然而,除了之前介绍的几个模块之外,编码器部分有另一个子模块。该模块也是多头注意力层,接受编码器的输出作为key和value,decoder的状态作为query。与编码器部分相类似,解码器同样是使用了add and norm机制,用残差和层归一化将各个子层的输出相连。