【系列论文研读】Semi-supervised learning:VAT,TEM,S4L,UDA
一、Virtual Adversarial Training (VAT)
原文:Virtual adversarial training: a regularization method for supervised and semi-supervised learning.(2018PAMI)
作者:T. Miyato, S.-i. Maeda (Kyoto University, Kyoto, Japan)
1、对抗训练
希望在对x的每个维度添加微小扰动的情况下,模型得到的预测值仍然为y。对于网络,有p(x),p(x+r),p为网络中间层,则对抗目标是最大化两者的距离。
目标攻击:原图为狗,加扰动使其收敛到label 猫
详情参考:https://zhen8838.github.io/2020/01/31/ssl-vat/
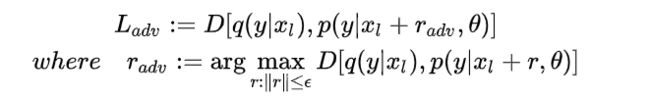
2、VAT+semi
idea:把所有数据进行对抗训练得到对抗损失函数;标签数据得到监督损失

其中,对于有标签数据,p的网络输出代表其真实标签;无标签数据的p为网络对其的预测标签
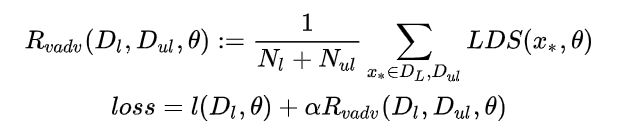
参考:https://zhuanlan.zhihu.com/p/66389797
二、II-Model and Temporal ensembling
原文:Temporal Ensembling for Semi-Supervised Learning. (2017ICLR)
作者:Samuli Laline、Timo Aila.(nvidia)
1. 双模型
作者让同一个图片输入网络两次,由于有一些随机的因素(dropout, augmentation等),会使得两次的隐藏层的输出(也就是z)会不一样,作者把两个不同的z做差,然后求l2,作为loss的一部分,当然loss的另一部分就是那些有标签数据的交叉熵(cross entropy)。另外,由于模型最开始时是很不准确的,所以产生的z可能没有多大意义,所以需要先对有label的数据进行训练,也就是需要把两次不同的z比较的loss进行屏蔽。作者这里设置了一个随时间变化的变量w(t),在t=0时,设置w(t)为0,也是z比较的loss权重为0,然后w(t)随着时间增大而增大。

2. Temporal ensembling model
和双模型的不同点:比较的z来源不同。在双模型中,两个z都是来自同一迭代时间内产生的两次结果。但在时序组合模型中,一个z来自上次迭代周期产生的结果,一个z来自当前迭代时间内产生的结果。使用z是历史z的加权和![]()
参考:https://www.cnblogs.com/huangshiyu13/p/6634215.html
三、MixMatch
文章:MixMatch: A Holistic Approach to Semi-Supervised Learning(NIPS2019)
作者:David Berthelot(Google Research)
主要idea就是mixup上的扩展。对于无标签数据用预测值替代。该文还有对预测值的处理也比较关键。

别人写的太好无法超越,直接参考:https://zhuanlan.zhihu.com/p/66281890
四、S4L
文章:S4L: Self-Supervised Semi-Supervised Learning(ICCV2019)
作者:Xiaohua Zhai(Google)
they combine self-supervised rotation prediction, VAT, entropy minimization, Pseudo-Labels and fifine-tuning into a single model with multiple training steps.
效果:超过VAT
五、UDA
文章:Unsupervised Data Augmentation for Consistency Training(2019cvpr)
作者:Qizhe Xie...(Carnegie Mellon University ,Google Research)
key idea:有针对性的数据增强效果明显优于无针对性的数据增强
针对最先进的半监督策略:Minimize a divergence metric between the two distributions。此过程强制使模型对噪声不敏感,因此相对于输入(或隐藏)空间的变化更平滑。 从另一个角度来看,将一致性损失降至最低会逐渐将标签信息从已标记的数据传播到未标记的数据。

1. AutoAugment
图像分类:“自动增强”,即使用强化学习来搜索图像增强的“最优”组合,其性能明显优于任何人工设计的优化方法。
文本分类:把一个样本(语言A)转换成另一个语言B再转换回来,以此得到增强样本
2, TSA(Training Signal Annealing)——针对有标签和无标签的不平衡
它会在训练过程中逐步释放有标签样本的"training signals",如果这个样本在第t步训练时正确预测其标签的概率值大于阈值,那么就把它从loss function中移除,从而减少过拟合现象。
参考:https://www.jianshu.com/p/5d4e18b8de04
六、IIC
文章:Invariant Information Clustering for Unsupervised Image Classifification and Segmentation
作者:Xu Ji...(University of Oxford)
idea:两个loss。第一个,图像和变化后的图像之间的最大化互信息。第二个,和先前聚类产生的虚拟标签的差异。

目前的simi-supervised 的方法对比:MixMatch和UDA好像比较好
数据来源:A survey on Semi-, Self- and Unsupervised Techniques in Image Classifification
