并行程序设计方法实验(包括openmp、向量化实现pi计算、SPECOMP2012测试、矩阵乘法优化)
目录
一、实验环境
二、专题一之积分计算圆周率
2.1向量优化
2.2 OpenMP优化
三、专题二之测试SPECOMP2012
3.1初步了解SPECOMP
3.2系统基本配置
3.3实践
3.3.1 测定不同线程数的影响
3.3.2测定不同调度方式的影响
四、专题三之矩阵乘法优化
4.1普通版本
4.2矩阵转置
4.3分块优化
4.4矩阵转置+openmp优化
4.5 MPI并行
五、代码文档已开源至Github,欢迎投星支持。
一、实验环境
| 工具清单 |
|
| 虚拟机 |
VMware Workstation 14.1.1 build-7528167 |
| 系统镜像 |
ubuntu-16.04.3-desktop-amd64.iso |
| 内核版本 |
Linux ubuntu 4.13.0-41-generic |
| gcc版本 |
version 5.4.0 20160609 |
| 处理器内核总数 |
4 |
| 运行内存 |
4GB |
二、专题一之积分计算圆周率
2.1向量优化
根据求pi公式,尝试进行编程实践,分别给出串行、sse-float、sse-double、avx-float、avx-double、循环展开六个版本的代码(result.c),观察实验结果:
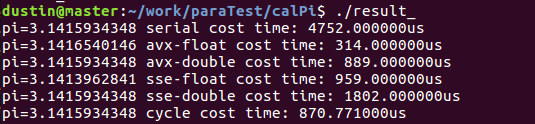
由于计算pi时计算结果的精度和耗费时间与dt大小的选取密切相关,在该专题实验中统一取dt=1280000,最终发现符合实验指导书中所给规律:
AVX-float>AVX-double≈SSE-float>SSE-double>serial
在规定的五个版本基础之上,做了一次简单的循环展开测试,优化结果也比较明显。由于通过手工进行循环展开,进而为每一次循环体中更多指令的流水并行提供了可能,但由于指令系统和编译器本身的局限性,不可能完全依靠手工循环展开进行优化,最佳的方案需要取一个折中。
- 问题一:编译选项问题
最开始代码未整合,各个版本分别放在一个c文件中,这样在编译时加的优化编译选项有所区别,如对串行版本,仅添加-O3,对sse版本添加-O3和-msse2,对avx版本添加-O3和-mavx2,分别编译运行,发现结果非常不好。另外,在对串行版本代码的编译过程中发现仅添加-O3和添加-O3 -msse2 -mavx2的结果也大不相同,明显后者较于前者做了更多“潜”优化,这样的话我们得到的结果从试验方法上来讲就不科学。
考虑到机器每次运行时的环境状态差异,以及编译选项不统一引来的“潜优化”问题,最终选择统一到一个c文件中,并对整个文件添加统一的优化选项,并进行多次试验求其平均值,发现试验结果良好,比较有说服力,验证了向量优化的实用性。
编译命令:gcc -mavx2 -msse2 -fopenmp -O3 pi.c -o result
- 问题二:精度问题
double和float型数据在机器中占的字节数是不同的,复习计组过程中重新学习了浮点数float和double型数据在机器中的存储方式。根据计算公式理论上来讲,dt选择越大,试验结果越逼近pi的真实值;然而当dt较大时会发现float版本的试验结果与真实pi的值相差甚远,可以认为已经从“误差”级别转为“错误”级别。因此我们需要找到一个dt的折中值,最终选择dt=1280000,试验结果比较好。精度的问题在大型科学计算中显得异常重要,启示我们在未来追求速度和精度的计算之道中也要更加理性的选择,妥善考虑。
2.2 OpenMP优化
OpenMP使用FORK-JOIN并行执行模型。所有的OpenMP程序开始于一个单独的主线程。主线程会一直串行地执行,一旦遇到并行域会根据机器情况和编译配置属性实现多线程并行,特别适和对与该专题中类似计算密集型任务的优化。
给出openmp和openmp+simd两种版本的代码,观察实验结果,符合预期:
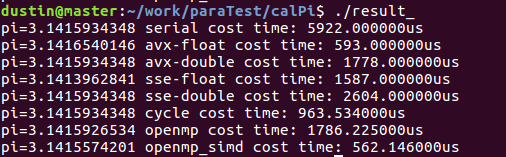
实验中dt依然取1280000;
- 问题一:openmp任务两级并行(手工向量化)
对计算任务进行openmp优化时,首先考虑任务的划分问题,由于实验环境中处理器核心数为4,对dt级别的计算任务分解为4个dt/4级别的任务,然后针对dt/4大小的任务考虑进行simd的进一步优化;
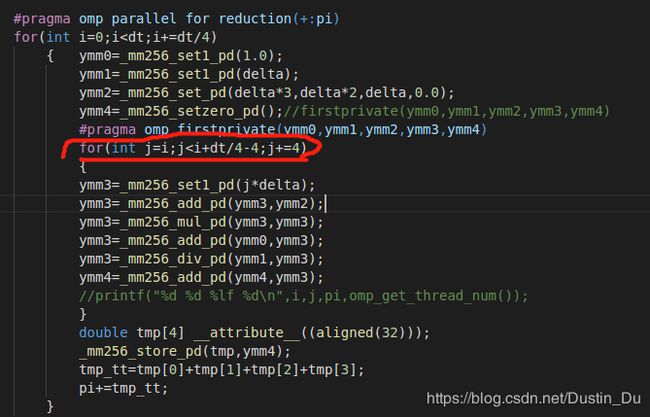
图中二层循环处比较关键,由于已经给每个线程划分一定的计算任务量,所以需要设计一个统一的计算任务体针对于每一个线程能如期执行。最开始由于考虑不周,将j的初始值定为0,这就导致每个线程分的的计算任务量是不同的,最终pi的累加值远大于真实值;
在寻找问题原因时采用打印变量值进行一步步的摸索,最终将问题定位于二层循环处;最终,成功实现openmp+simd的两级并行优化,进一步增加优化程度。
三、专题二之测试SPECOMP2012
3.1初步了解SPECOMP
SPEC是一家非营利性公司,旨在建立,维护和认可标准化基准和工具,以评估最新一代计算系统的性能和能效,其测试范围覆盖云、cpu、图形和工作站、web服务器等,在本次测试中我们使用的SPECOMP为高性能计算测试对象中的一个分支-OPENMP。
SPECOMP2012基准被设计用于测量使用基于OpenMP的3.1标准共享存储器的并行处理应用的性能。该基准还包括一个可选的指标,其中包括功率测量,共包括14个科学和工程应用代码,涵盖从计算流体动力学(CFD)到分子建模到图像处理的所有内容。可选的能耗测量基于SPEC功率和性能基准测试方法,该方法提供了有关如何将功率度量标准集成到标准化基准测试中的详细信息。
3.2系统基本配置
|
|
|
| hw_cpu_name |
Intel Core i5-7300HQ |
| hw_disk |
36 GB |
| hw_memory001 |
3.830 GB |
| hw_nchips |
4 |
| sw_file |
ext4 |
| sw_os001 |
Ubuntu 16.04.3 LTS |
| sw_os002 |
4.15.0-36-generic |
| sw_state |
Run level 5 |
3.3实践
安装过程整体顺利,在真正开始试验之间需要仔细阅读文档,另外可以登陆SPEC官网查询更加详细的使用指导[1]。
测试过程中设置运行选项为:
runspec --config=gcc.cfg --size=test --tune=base --iterations=1 --size=test --threads=X –I all
接下来会先进行编译工作,随后根据线程设置数运行。
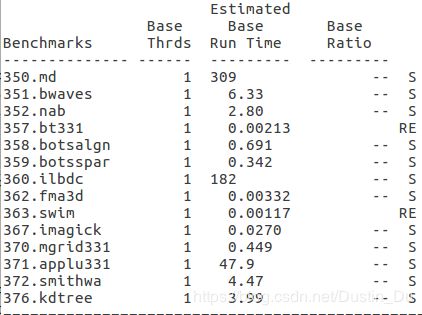
3.3.1 测定不同线程数的影响
357和363在执行过程中报错,结果日志中的数据不准确,原因是虚拟机中的内存大小不符合运行所需标准。
- export OMP_NUM_THREADS=1
- export OMP_NUM_THREADS=2

- export OMP_NUM_THREADS=4
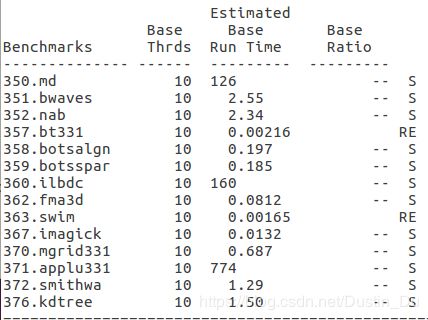
- export OMP_NUM_THREADS=7
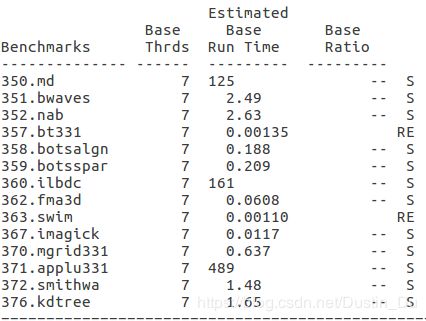
- export OMP_NUM_THREADS=10
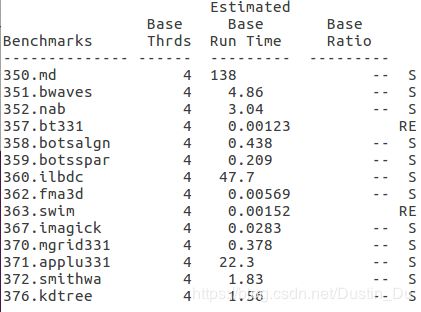
关于不同线程数情况下的结果,发现有三个耗时较长的程序,序号分别为350、360、371,随着环境变量中默认线程数的变化,发现对于350程序,线程数设置从1到4时,运算时间逐渐减少,当线程数设置超过4以后,运行总时间稳定在125s左右,这与omp并行程序一般的运行规律存在冲突;对于360、371程序,明显可以看到当线程数设置为4时,并行加速效果最佳,当超过4以后,由于机器本身的局限性以及线程数增加引起的开销增加,加速效果下降,符合常理,其中特别是371程序在线程数超过4以后运算时间明显增加,猜测代码中应该有大量的omp并行计算任务,观察源文件夹中这几个文件,与猜想一致。
带着疑问,从代码中尝试发现问题,对于350程序,发现主要的计算任务中用了很多的MPI函数,而omp程序只占了一小部分,所以猜测程序总体上运行时间受MPI进程数和omp线程数的综合影响。

3.3.2测定不同调度方式的影响
- export OMP_SCHEDULE=dynamic
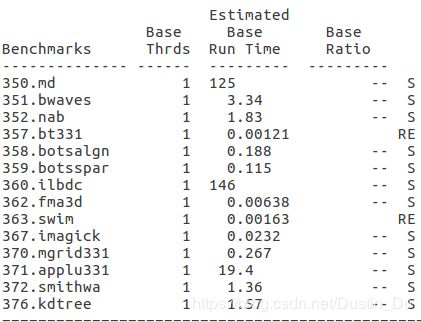
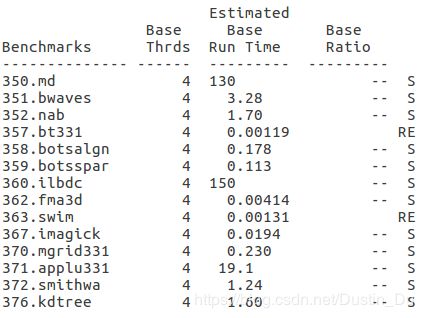
- export OMP_SCHEDULE=static
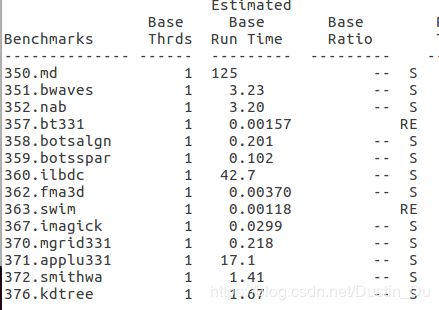
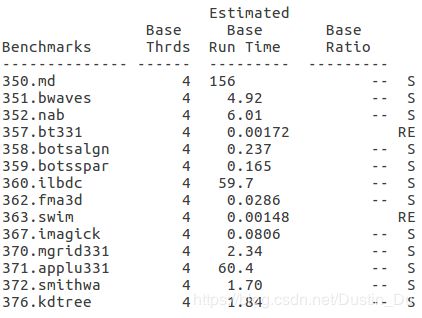
- export OMP_SCHEDULE=guided

三种调度方式中可以看出指导性和静态方式对360程序的加速效果较明显。
通过本次试验,基本熟悉了SPECOMP测试的流程方法,初步验证了omp的并行加速效果以及与机器配置的密切相关性。但仍存在一些问题未解决,如研究357和363程序的内存最低需求,探究350程序在线程数大于4后,加速效果未出现降低,不符合omp程序运行的一般经验。另外,相比以前使用的Linpack性能测试,结果明显不如Linpack来的直观,但后者所需的配置文件也较复杂一点。
四、专题三之矩阵乘法优化
在数学中,矩阵(Matrix)是指纵横排列的二维数据表格,最早来自于方程组的系数及常数所构成的方阵,这一概念由19世纪英国数学家凯利首先提出,现如今已成为高等代数学中的常见工具,并广泛用于统计分析等应用数学学科中,阵乘法同时也是并行计算领域常常被用来作为范例的一个话题。它的特点是首先计算量可能相当大,适合利用并行实现来提高效率。其次,它所使用的各种数据之间没有相互依赖性,可以充分使用并行处理的计算资源。
4.1普通版本
矩阵相乘最重要的方法是一般矩阵乘积。它只有在第一个矩阵的栏数(column)和第二个矩阵的列数(row)相同时才有定义。一般单指矩阵乘积时,指的便是一般矩阵乘积。若A为m×n矩阵,B为n×p矩阵,则他们的乘积AB会是一个m×p矩阵。其乘积矩阵的元素如下面式子得出:
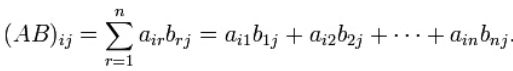
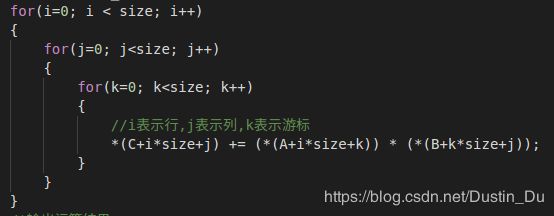
由于该算法很基础,显然运行速度比较慢,时间复杂度为O(n3)。
4.2矩阵转置
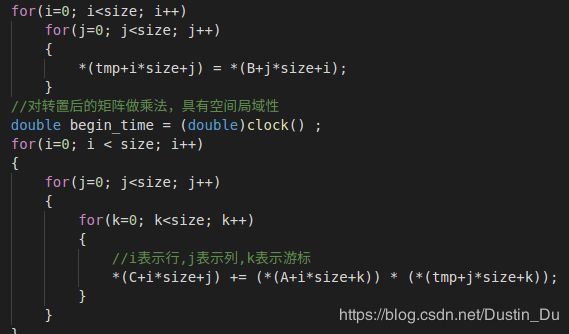
在C语言中,数组的存储按照行优先规则,为进一步利用cache,对矩阵乘法中的第二个矩阵进行装置,提高命中率,进一步提高速度。Tmp作为中间数组保存矩阵B装置后的结果,运行时间在下文统一展示。
4.3分块优化
核心是交叉乘加遍历,当数组大小增加时,时间局部性会明显降低,高速缓存中不命中数目增加。当使用分块技术时,时间局部性由分块大小来决定,而不是数组总大小来决定。本问题中选取块大小为bsize=4的方阵。
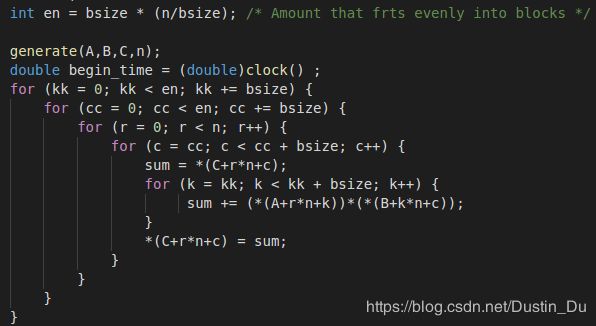
4.4矩阵转置+openmp优化
为进一步利用系统资源,在矩阵转置的基础上,进行openmp的初步优化。代码呈现如下:

4.5 MPI并行
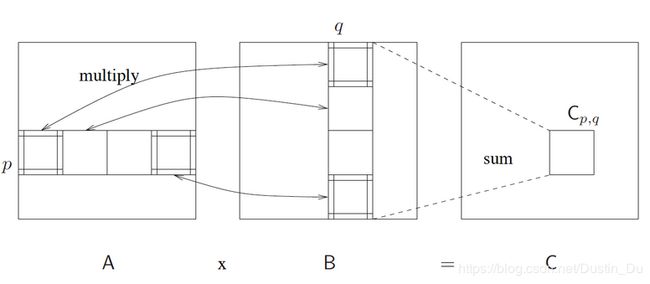
Mpi并行适用用数据规模较大,依赖性较弱的问题,如果采用更多的处理器,将会显著提高计算效率。实际中,通常并不可能有像矩阵元素那么多的处理器资源。这时我们该怎么做。对于一个大小为n × n 的大矩阵A,我们其实可以把它切分成s^2个子矩阵Ap,q,每个子矩阵的大小为 m × m,其中 m = n / s,即0 <= p, q < s。对于两个大矩阵A和B,现在我们有:
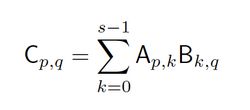
用图象形象表示如下:
- 使用较简单的MPI_Send和MPI_Recv实现
- 使用较高级的MPI_Scatter和MPI_Gather实现
具体代码详见c文件,文件中已加很多必要的注释,不再赘述。


五、代码文档已开源至Github,欢迎投星支持。