04_TrainingModels_02_regularization_Ridge_Lasso_Elastic Net_Early Stopping
04_TrainingModels_Normal Equation(正态方程,正规方程) Derivation_Gradient Descent_Polynomial Regression: https://blog.csdn.net/Linli522362242/article/details/104005906
04_TrainingModels_03 : https://blog.csdn.net/Linli522362242/article/details/104097191
#########################
WARNING
PolynomialFeatures(degree=d) transforms an array containing ![]() features into an array containing features (without the feature^0 ==1 or intercept), where n! is the factorial of n, equal to 1 × 2 × 3 × ... × n. Beware of the combinatorial explosion of the number of features!
features into an array containing features (without the feature^0 ==1 or intercept), where n! is the factorial of n, equal to 1 × 2 × 3 × ... × n. Beware of the combinatorial explosion of the number of features!
a^3: one features with degree=3 ==>PolynomialFeatures OR poly_features.transform() ==> (1+3)! / (1! * 3!)==4 OR a^3, a^2, a, 1
a^2 : (1+2)! / 1! 2! ==3 ==> [1, a, a^2 ] e.g. ![]() ==Hiding a^0=1(include_bias=False)==>
==Hiding a^0=1(include_bias=False)==> ![]() so
so

a^2 , b^2 ==> (2+2)! / 2!2! =6 e.g. 1, a, b, a*b, a^2, b^2
#########################
Learning Curves
If you perform high-degree Polynomial Regression, you will likely fit the training data much better than with plain Linear Regression. For example, Figure 4-14 applies a 300-degree polynomial model to the preceding training data, and compares the result with a pure linear model and a quadratic model (2nddegree polynomial). Notice how the 300-degree polynomial model wiggles( 扭动) around to get as close as possible to the training instances.
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
for style, width, degree in ( ("y-", 1, 300), ("b--", 2,2), ("r-+", 2,1) ):
polybig_features = PolynomialFeatures(degree=degree, include_bias=False)
std_scaler = StandardScaler()
lin_reg = LinearRegression()
polynomial_regression = Pipeline([
("poly_features", polybig_features),#adding new features base on degree and the specify feature
("std_scaler", std_scaler),
("lin_reg", lin_reg),
])
#https://blog.csdn.net/Linli522362242/article/details/103387527
# When you call the pipeline’s fit() method(learning data), it calls fit_transform() sequentially on all transformers,
# passing the output of each call as the parameter to the next call, until it reaches the final estimator,
# for which it just calls the fit() method.
#transform() contains fill data action
polynomial_regression.fit(X,y) # lin_reg.fit(X_poly,y) #fit_transform(X) then ...fit(X_poly,y)
y_newbig = polynomial_regression.predict(X_new) #lin_reg.predict # transform(X_new)...predict(X_new)
plt.plot(X_new, y_newbig, style, label=str(degree), linewidth=width)
plt.plot(X, y, "b.", linewidth=3)
plt.legend(loc="upper left")
plt.xlabel("$x_1$", fontsize=18)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.axis([-3,3, 0,10])
plt.title("Figure 4-14. High-degree Polynomial Regression")
plt.show()
Of course, this high-degree Polynomial Regression model is severely overfitting the training data, while the linear model is underfitting it. The model that will generalize best in this case is the quadratic model. It makes sense since the data was generated using a quadratic model, but in general you won’t know what function generated the data, so how can you decide how complex your model should be? How can you tell that your model is overfitting or underfitting the data?
In (https://blog.csdn.net/Linli522362242/article/details/103587172) you used cross-validation to get an estimate of a model’s generalization performance. If a model performs well (rmse is 0.0 in DecisionTreeRegressor) on the training data but generalizes poorly according to the cross-validation metrics(rmse is 70644.94463282847 ±2939 in DecisionTreeRegressor by using cross-validation(cv=10) ), then your model is overfitting.
################################DecisionTreeRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import mean_squared_error
tree_reg = DecisionTreeRegressor()
tree_reg.fit(housing_prepared, housing_label)
housing_predictions = tree_reg.predict(housing_prepared)
tree_mse = mean_squared_error(housing_label,housing_predictions)
tree_rmse = np.sqrt(tree_mse)####################
tree_rmse####################
![]() Seem the mode is perfect??
Seem the mode is perfect??
from sklearn.model_selection import cross_val_score
scores = cross_val_score(tree_reg, housing_prepared, housing_label, scoring="neg_mean_squared_error",cv=10)
tree_rmse_scores = np.sqrt(-scores)
def display_scores(scores):
print("Scores:", scores)
print("Mean:", scores.mean())
print("Standard deviation:", scores.std())
display_scores(tree_rmse_scores) overfitting
overfitting
#################################DecisionTreeRegressor & Cross-Validation
If it performs poorly on both, then it is underfitting. This is one way to tell when a model is too simple or too complex.
##########################################LinearRegression
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(housing_prepared, housing_label) #housing_label
from sklearn.metrics import mean_squared_error
housing_predictions = lin_reg.predict(housing_prepared)
lin_mse = mean_squared_error(housing_label, housing_predictions)
lin_rmse = np.sqrt(lin_mse)
lin_rmse![]()
lin_scores = cross_val_score(lin_reg, housing_prepared, housing_label, scoring="neg_mean_squared_error", cv=10)
lin_rmse_scores = np.sqrt(-lin_scores)
display_scores(lin_rmse_scores) underfitting
underfitting
Okay, this is better than nothing but clearly not a great score: most districts’ median_housing_values range between $120,000 and $264,000, so a typical prediction error of $68,628 is not very satisfying. This is an example of a model underfitting the training data. When this happens it can mean that the features do not provide enough information to make good predictions, or that the model is not powerful enough. As we saw in the previous chapter, the main ways to fix underfitting are to select a more powerful model, to feed the training algorithm with better features, or to reduce the constraints on the model. This model is not regularized, so this rules out the last option. You could try to add more features (e.g., the log of the population), but first let’s try a more complex model to see how it does.
################################LinearRegression & Cross-Validation
Another way is to look at the learning curves: these are plots of the model’s performance on the training set and the validation set as a function of the training set size. To generate the plots, simply train the model several times on different sized subsets of the training set. The following code defines a function that plots the learning curves of a model given some training data:
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
def plot_learning_cures(model, X,y):
# X_validationSet#y_validationSet
X_train, X_val, y_train, y_val = train_test_split(X,y, test_size=0.2, random_state=10)
train_errors, val_errors=[], []
for m in range( 1, len(X_train) ):#different size of training set
model.fit( X_train[:m], y_train[:m] )###############model
y_train_predict = model.predict( X_train[:m] )###############model
y_val_predict = model.predict( X_val )###############model
train_errors.append(mean_squared_error(y_train[:m], y_train_predict))
val_errors.append(mean_squared_error(y_val, y_val_predict))
# indices of train_errors
# plt.plot(list(range(len(train_errors))),np.sqrt(train_errors), "r-+", linewidth=2, label="Training set")
plt.plot(np.sqrt(train_errors), "r-+", linewidth=2, label="Training set")
plt.plot(np.sqrt(val_errors), "b-", linewidth=3, label="Validation set")
plt.legend(loc="upper right", fontsize=14)
plt.xlabel("Training set size", fontsize=14)
plt.ylabel("RMSE", fontsize=14)
lin_reg = LinearRegression()
plot_learning_cures(lin_reg, X,y)
plt.axis([0,80, 0,3])
plt.title("Figure 4-15. Learning curves")
plt.show()
This deserves a bit of explanation. First, let’s look at the performance on the training data: when there are just one or two instances in the training set, the model can fit them perfectly, which is why the curve starts at zero. But as new instances are added to the training set, it becomes impossible for the model to fit the training data perfectly, both because the data is noisy and because it is not linear at all. So the error on the training data goes up until it reaches a plateau(高原; 平稳时期,稳定水平; 停滞期), at which point adding new instances to the training set doesn’t make the average error much better or worse. Now let’s look at the performance of the model on the validation data. When the model is trained on very few training instances, it is incapable of generalizing properly, which is why the validation error is initially quite big. Then as the model is shown more training examples, it learns and thus the validation error slowly goes down. However, once again a
straight line cannot do a good job modeling拟合 the data, so the error ends up at a plateau, very close to the other curve.
These learning curves are typical of an underfitting model. Both curves have reached a plateau; they are close and fairly high(RMSE).
###############################
TIP
If your model is underfitting the training data, adding more training examples will not help. You need to use a more complex
model or come up with设法拿出 better features.
###############################
Now let’s look at the learning curves of a 10th-degree polynomial model on the same data (Figure 4-16):
from sklearn.pipeline import Pipeline
polynomial_regression = Pipeline((
("poly_features", PolynomialFeatures(degree=10, include_bias=False)),
("lin_reg", LinearRegression()),
))
plot_learning_cures(polynomial_regression, X,y)
plt.axis([0,80,0,3])
plt.title("Figure 4-16. Learning curves for the polynomial model")
plt.show()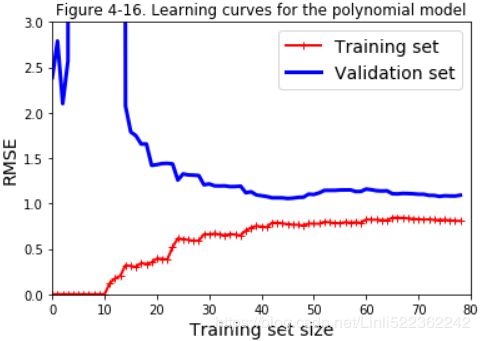
These learning curves look a bit like the previous ones, but there are two very important
differences:
- The error (RMSE)on the training data is much lower than with the Linear Regression model.
- There is a gap(overfitting) between the curves. This means that the model performs significantly better on the training data than on the validation data, which is the hallmark显著特点 of an overfitting model. However, if you used a much larger training set, the two curves would continue to get closer.
###################
TIP
One way to improve an overfitting model is to feed it more training data until the validation error reaches the training error.
###################
######################################
THE BIAS/VARIANCE TRADEOFF
An important theoretical result of statistics and Machine Learning is the fact that a model’s generalization error can be expressed as the sum of three very different errors:
- Bias偏差 : This part of the generalization error is due to wrong assumptions, such as assuming that the data is linear when it is actually quadratic. A high-bias model is most likely to underfit the training data.
- Variance方差: This part is due to the model’s excessive sensitivity to small variations in the training data. A model with many degrees of freedom多自由度 (such as a high-degree polynomial model) is likely to have high variance, and thus to overfit the training data.
- Irreducible error不能减少的误差 : This part is due to the noisiness of the data itself. The only way to reduce this part of the error is to clean up the data (e.g., fix the data sources, such as broken sensors, or detect and remove outliers). Increasing a model’s complexity will typically increase its variance and reduce its bias. Conversely, reducing a model’s complexity increases its bias and reduces its variance. This is why it is called a tradeoff.
######################################
*****************************************************************************extra materials
regularization is one approach to tackle the problem of overfitting by adding additional information, and thereby shrinking the parameter values of the model to induce a penalty against complexity针对复杂性引入惩罚项.
Ridge regression is an L2 penalized model where we simply add the squared sum of the weights to our least-squares cost function( is different with MSE(Mean Square of Error)
is different with MSE(Mean Square of Error) 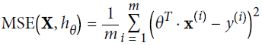 since
since ![]() ):
):


https://towardsdatascience.com/ridge-regression-for-better-usage-2f19b3a202db
We’ve seen the equation of multiple linear regression both in general terms and matrix version. It can be written in another version as follows.![]()
Here argmin means ‘Argument of Minimum’ that makes the function attain the minimum. In the context, it finds the β’s that minimize the RSS(Residual Sum of Squares ). And we know how to get the β’s from the matrix formula(![]() ). Now, the question becomes “What does this have to do with ridge regression?”.
). Now, the question becomes “What does this have to do with ridge regression?”.

‘L2 norm’: 
https://towardsdatascience.com/ridge-and-lasso-regression-a-complete-guide-with-python-scikit-learn-e20e34bcbf0b
In the equation (1.1) above, we have shown the linear model based on the n number of features. Considering only a single feature as you probably already have understood that w[0] will be slope and b(or ![]() ) will represent intercept. Linear regression looks for optimizing w and b such that it minimizes the cost function. The cost function can be written as
) will represent intercept. Linear regression looks for optimizing w and b such that it minimizes the cost function. The cost function can be written as
In the equation above I have assumed the data-set has M instances and p features. Note j=0, w0 = b = ![]() =w0 x1= w0 * x0
=w0 x1= w0 * x0
Ridge Regression : In ridge regression, the cost function is altered by adding a penalty equivalent to square of the magnitude of the coefficients .
.
The hyperparameter ![]() controls how much you want to regularize the model. If
controls how much you want to regularize the model. If ![]() = 0 then Ridge Regression is just Linear Regression. If
= 0 then Ridge Regression is just Linear Regression. If ![]() is very large, then all weights end up very close to zero and the result is a flat line going through the data’s mean.
is very large, then all weights end up very close to zero and the result is a flat line going through the data’s mean.
 p features Note j=0, w0 = b =
p features Note j=0, w0 = b = ![]() =w0 x1= w0 * x0
=w0 x1= w0 * x0
This is equivalent to saying minimizing the cost function in equation 1.2 under the condition as below, C is a constant

By increasing the value of the hyperparameter ![]() (the following uses
(the following uses![]() ), we increase the regularization strength(for tackling the problem of overfitting) and shrink the weights of our model(or reduce the value of wj or bj) since we want to make the function attain the minimum( including
), we increase the regularization strength(for tackling the problem of overfitting) and shrink the weights of our model(or reduce the value of wj or bj) since we want to make the function attain the minimum( including 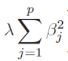 ). Note sometimes the value of wj or bj is not steady or maybe too large.
). Note sometimes the value of wj or bj is not steady or maybe too large.
Please note that we don't regularize the intercept term ![]() or
or ![]() (the following uses
(the following uses ![]() ).(we need to correct the last item in equation 1.3, by changing j=1 )
).(we need to correct the last item in equation 1.3, by changing j=1 )
*****************************************************************************
Regularized Linear Models
a good way to reduce overfitting is to regularize the model (i.e., to constrain it): the fewer degrees of freedom it has(lower variance), the harder it will be for it to overfit the data. For example, a simple way to regularize a polynomial model is to reduce the number of polynomial degrees. For a linear model, regularization is typically achieved by constraining the weights of the model( B is a weight or ![]() ). We will now look at Ridge Regression, Lasso Regression, and Elastic Net, which implement three different ways to constrain the weights.
). We will now look at Ridge Regression, Lasso Regression, and Elastic Net, which implement three different ways to constrain the weights.
Ridge岭 Regression
Ridge Regression (also called Tikhonov regularization) is a regularized version of Linear Regression: a regularization term equal to  is added to the cost function(). This forces the learning algorithm to not only fit the data but also keep the model weights
is added to the cost function(). This forces the learning algorithm to not only fit the data but also keep the model weights as small as possible. Note that the regularization term should only be added to the cost function during training. Once the model is trained, you want to evaluate the model’s performance using the unregularized performance measure.
as small as possible. Note that the regularization term should only be added to the cost function during training. Once the model is trained, you want to evaluate the model’s performance using the unregularized performance measure.
#############################################################
NOTE
It is quite common for the cost function used during training to be different from the performance measure used for testing. Apart from regularization, another reason why they might be different is that a good training cost function should have optimization-friendly derivatives优化过程中易于求导, while the performance measure used for testing should be as close as possible to the final objective接近最后的客观表现. A good example of this is a classifier trained using a cost function such as the log loss (discussed in a moment) but evaluated using precision/recall.
#############################################################
The hyperparameter α controls how much you want to regularize the model. If α = 0 then Ridge Regression is just Linear Regression. If α is very large, then all weights end up very close to zero and the result is a flat line going through the data’s mean. Equation 4-8 presents the Ridge Regression cost function:
Equation 4-8. Ridge Regression cost function
 Note:
Note:  is for convenient computation, , we should remove it for Practical application
is for convenient computation, , we should remove it for Practical application
Note that the bias term  is not regularized (the sum starts at i = 1, not 0). If we define w as the vector of feature weights (
is not regularized (the sum starts at i = 1, not 0). If we define w as the vector of feature weights ( ![]() to
to ![]() ), then the regularization term
), then the regularization term is simply equal to
is simply equal to ![]() , where
, where ![]() represents the ℓ2 norm of the weight vector. https://blog.csdn.net/Linli522362242/article/details/103387527
represents the ℓ2 norm of the weight vector. https://blog.csdn.net/Linli522362242/article/details/103387527
For Gradient Descent, just add 2αw to the MSE gradient vector (Equation 4-6).  +2αw (or +2α
+2αw (or +2α )
)
########################################![]() is
is ![]() , and use RSS(Residuals of Sum Squares) instead of MSE, the correct formula:
, and use RSS(Residuals of Sum Squares) instead of MSE, the correct formula:
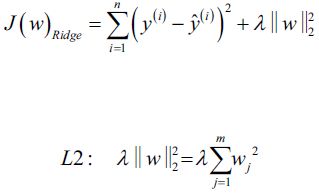
WARNING
It is important to scale the data (e.g., using a StandardScaler) before performing Ridge Regression, as it is sensitive to the scale of the input features. This is true of most regularized models.
########################################
np.random.seed(42)
m=20 #number of instances
X= 3*np.random.rand(m,1) #one feature #X=range(0,3)
#noise
y=1 + 0.5*X + np.random.randn(m,1)/1.5
X_new = np.linspace(0,3, 100).reshape(100,1)
from sklearn.linear_model import Ridge
def plot_model(model_class, polynomial, alphas, **model_kargs):
for alpha, style in zip( alphas, ("b-", "y--", "r:") ):
model = model_class(alpha, **model_kargs) if alpha>0 else LinearRegression()
if polynomial:
model = Pipeline([
("poly_features", PolynomialFeatures(degree=10, include_bias=False)),
("std_scaler", StandardScaler()),
("regul_reg", model) #regulized regression
])
model.fit(X,y)
y_new_regul = model.predict(X_new)
lw = 5 if alpha>0 else 1
plt.plot(X_new, y_new_regul, style, linewidth=lw, label=r"$\alpha = {}$".format(alpha) )
plt.plot(X,y, "b.", linewidth=3)
plt.legend(loc="upper left", fontsize=15)
plt.xlabel("$x_1$", fontsize=18)
plt.axis([0,3, 0,4])
plt.figure(figsize=(8,4) )
plt.subplot(121)
plot_model(Ridge, polynomial=False, alphas=(0,10,100), random_state=42)#plain Ridge models are used, leading to
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.subplot(122)
plot_model(Ridge, polynomial=True, alphas=(0,10**-5, 1), random_state=42)
plt.title("Figure 4-17. Ridge Regression")
plt.show()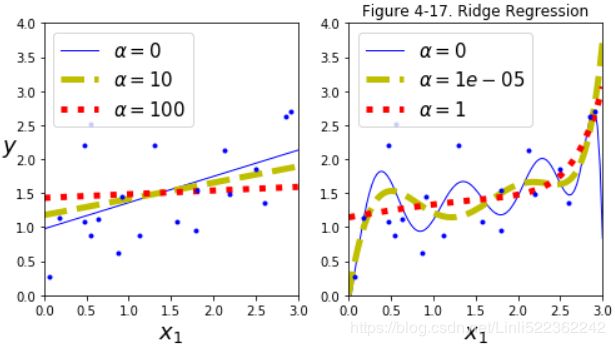
If α = 0 then Ridge Regression is just Linear Regression.
If α is very large, then all weights end up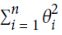 very close to zero and the result is a flat line going through the data’s mean
very close to zero and the result is a flat line going through the data’s mean
Figure 4-17 shows several Ridge models trained on some linear data using different α value. On the left, plain Ridge models are used, leading to linear predictions. On the right, the data is first expanded using PolynomialFeatures(degree=10), then it is scaled using a StandardScaler, and finally the Ridge models are applied to the resulting features: this is Polynomial Regression with Ridge regularization. Note how increasing α leads to flatter (i.e., less extreme, more reasonable) predictions; this reduces the model’s variance but increases its bias.
As with Linear Regression, we can perform Ridge Regression either by computing a closed-form equation or by performing Gradient Descent. The pros and cons are the same. Equation 4-9 shows the closed-form solution (where A is the n × n identity单位 matrix A( A square matrix full of 0s except for 1s on the main diagonal (top-left to bottom-right). ) except with a 0 in the top-left cell, corresponding to the bias term ).
Equation 4-9. Ridge Regression closed-form solution
 Note: Normal Equation(a closed-form equation)
Note: Normal Equation(a closed-form equation) ![]()
Here is how to perform Ridge Regression with Scikit-Learn using a closed-form solution (a variant of Equation 4-9 using a matrix factorization technique by André-Louis Cholesky):
from sklearn.linear_model import Ridge
ridge_reg = Ridge(alpha=1, solver="cholesky", random_state=42)
ridge_reg.fit(X,y)
ridge_reg.predict([[1.5]]) ![]()
ridge_reg = Ridge(alpha=1, solver="sag", random_state=42)
ridge_reg.fit(X,y)
ridge_reg.predict([[1.5]])![]()
And using Stochastic Gradient Descent:
Note: to be future-proof, we set max_iter=1000 and tol=1e-3 because these will be the default values in Scikit-Learn 0.21.
#small case of L
sgd_reg = SGDRegressor( penalty="l2", max_iter=1000, tol=1e-3, random_state=42)
sgd_reg.fit(X,y.ravel())
sgd_reg.predict([[1.5]])![]()
The penalty hyperparameter sets the type of regularization term to use. Specifying "l2" indicates that you want SGD to add a regularization term to the cost function equal to half the square of the ℓ2 norm of the weight vector : this is simply Ridge Regression.
: this is simply Ridge Regression.
This forces the learning algorithm to not only fit the data but also keep the model weights as small as possible
Lasso Regression
Least Absolute Shrinkage and Selection Operator Regression (simply called Lasso Regression) is another regularized version of Linear Regression: just like Ridge Regression, it adds a regularization term to the cost function, but it uses the ℓ1 norm of the weight vector instead of half the square of the ℓ2 norm (see Equation 4-10).
Equation 4-10. Lasso Regression cost function OR
OR

OR ![]() is
is ![]() , and use RSS(Residuals of Sum Squares) instead of MSE, the correct formula:
, and use RSS(Residuals of Sum Squares) instead of MSE, the correct formula:

Figure 4-18 shows the same thing as Figure 4-17 but replaces Ridge models with Lasso models and uses smaller α values.
from sklearn.linear_model import Lasso
plt.figure(figsize=(8,4))
plt.subplot(121)
plot_model(Lasso, polynomial=False, alphas=(0, 0.1, 1), random_state=42)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.subplot(122)
plot_model(Lasso, polynomial=True, alphas=(0, 10**-7, 1), random_state=42)
plt.title("Figure 4-18. Lasso Regression")
plt.show()
An important characteristic of Lasso Regression is that it tends to completely eliminate the weights of the least important features最不重要 (i.e., set them to zero). For example, the dashed line in the right plot on Figure 4-18 (with α = 10-7) looks quadratic, almost linear(compared to Figure 4-17 ):since all the weights for the high-degree polynomial features are equal to zero. In other words, Lasso Regression automatically performs feature selection and outputs a sparse model (i.e., with few nonzero feature weights).
J <==  at each point of coordinate axis
at each point of coordinate axis ![]() ,
, ![]()
N1 <== L1 norm:  e.g.
e.g. ![]()
N2 <== L2 norm: sqrt(  ) e.g.
) e.g. ![]()
t_init is the initial value of ![]() ,
, ![]()
t1a, t1b, t2a, t2b = -1, 3, -1.5, 1.5
# ignoring bias term
theta1s = np.linspace(t1a, t1b, 500) # 500 points
theta2s = np.linspace(t2a, t2b, 500) # 500 points
theta1, theta2 = np.meshgrid(theta1s, theta2s)
#theta1: 500pts*500 500 points are copied along the points on coordinate axis theta2
#theta2: 500pts*500 500 points are copied along the points on coordinate axis theta1
theta = np.c_[theta1.ravel(), theta2.ravel()] #(250000, 250000) #corresponding to (features1, feature2)
Xr = np.array([
[-1, 1], #[feature1, feature2]
[-0.3, -1], #[feature1, feature2]
[1, 0.1] #[feature1, feature2]
])
#Xt.T
#feature1, ..., feature1
#feature2, ..., feature2
#...
#yi = 2 * Xi1 + 0.5 * Xi2
yr = 2*Xr[:, :1] + 0.5*Xr[:, 1:] #instances' labels are stored in multiple rows & one column
#yr.T
#array([
# [label1, label2,...]
# ])
#MSE #hiding: shape(250000, 3)-shape(1, 3)*250000
J = ( 1/len(Xr) *np.sum(( theta.dot(Xr.T) -yr.T )**2, axis=1 )).reshape(theta1.shape) # MSE at (500,500)
N1 = np.linalg.norm(theta, ord=1, axis=1).reshape(theta1.shape)#L1 norm: row_i = sum(|theta_i1| + |theta_i2|)
N2 = np.linalg.norm(theta, ord=2, axis=1).reshape(theta1.shape)#L2 norm: row_i=sqrt(sum(theta_i1 **2 + theta_i2 **2) )
# np.argmin(J): minimum value's index==166874 after the J being flatten
theta_min_idx = np.unravel_index( np.argmin(J), J.shape) #get the index==(333, 374) in orginal J (without being flatten)
theta1_min, theta2_min=theta1[theta_min_idx],theta2[theta_min_idx] #get the corresponding minimum thata values
#theta1_min, theta2_min #(1.9979959919839678, 0.5020040080160322)
t_init = np.array([[0.25], #theta1
[-1] #theta2
]) #start point
Lasso gradient vector:
It is important to scale the data before performing Ridge Regression, as it is sensitive to the scale of the input features. This is true of most regularized models.
Ridge gradient vector :
The penalty term ![]() without using the term for convenient computation
without using the term for convenient computation![]()
![]()
 Note: here
Note: here  ==
==
#L1 norm, L2 norm
def bgd_path(theta, X, y, l1_alpha, l2_alpha, core=1, eta=0.1, n_iterations=50):
path = [theta]
for iteration in range(n_iterations):
#formula gradients = 2/m * X_b.T.dot( X_b.dot(theta)-y ) # 2*
gradients = core* 2/len(X) * X.T.dot( X.dot(theta)-y ) + l1_alpha*np.sign(theta) + 2*l2_alpha*theta
theta = theta -eta*gradients # l1: alpha #l2: alpha
path.append(theta)
return np.array(path)Equation 4-8. Ridge Regression cost function
Note: is for convenient computation, we should remove it for Practical application

plt.figure( figsize=(12,8) )
#initial theta=0 in Lasso, initial theta=1 in Ridge
for i, N, l1_alpha, l2_alpha, title in ( (0, N1, 0.5, 0, "Lasso"), (1, N2, 0, 0.1, "Ridge") ):
#J:unregularized MSE cost function; JR:regularized MSE cost function
JR = J + l1_alpha*N1 + l2_alpha* N2**2 #cost function
#get current minimum of theta1 and theta2 in regularized MSE cost function
thetaR_min_idx = np.unravel_index(np.argmin(JR), JR.shape)
theta1R_min, theta2R_min = theta1[thetaR_min_idx], theta2[thetaR_min_idx]
#contour levels
#min-max scaling x_new=x-min/(max-min) ==> x=x_new*(max-min)+min
levelsJ = (np.exp(np.linspace(0,1,20)) -1) *( np.max(J)-np.min(J) ) + np.min(J)
levelsJR =(np.exp(np.linspace(0,1,20)) -1) *( np.max(JR)-np.min(JR) ) + np.min(JR)
levelsN = np.linspace(0, np.max(N), 10)
path_J= bgd_path(t_init, Xr, yr, l1_alpha=0, l2_alpha=0) #an unregularized MSE cost function(α = 0)
path_JR = bgd_path(t_init, Xr, yr, l1_alpha, l2_alpha) #a regularized MSE cost function
path_N = bgd_path(t_init, Xr, yr, np.sign(l1_alpha)/3, np.sign(l2_alpha), core=0)
plt.subplot(221 + i*2)
plt.grid(True)
plt.axhline(y=0, color='k')
plt.axvline(x=0, color='k')
#J:unregularized MSE cost function
#the background contours (ellipses) represent an unregularized MSE cost function(α = 0)
plt.contourf(theta1, theta2, J, levels=levelsJ, alpha=0.9)
#The foreground contours (diamonds) represent the ℓ1 penalty
plt.contour(theta1, theta2, N, levels=levelsN)
plt.plot(path_J[:,0], path_J[:,1], "w-o")#the white circles show the Batch Gradient Descent path that cost function
plt.plot(path_N[:,0], path_N[:,1], "y-^")#the triangles show the BGD path for this penalty only (α → ∞).
plt.plot(theta1_min, theta2_min, "bs") #minimum values of theta1 , theta2
plt.title(r"$\ell_{}$ penalty".format(i+1), fontsize=16)
plt.axis([t1a,t1b, t2a,t2b])
if i==1:
plt.xlabel(r"$\theta_1$", fontsize=20)
plt.ylabel(r"$\theta_2$", fontsize=20, rotation=0)
plt.subplot(222 + i*2)
plt.grid(True)
plt.axhline(y=0, color="k")
plt.axvline(x=0, color="k")
#JR:regularized MSE cost function
plt.contourf(theta1, theta2, JR, levels=levelsJR, alpha=0.9)
plt.plot(path_JR[:,0], path_JR[:,1], "w-o")#the white circles show the Batch Gradient Descent path that cost func
plt.plot(theta1R_min, theta2R_min, "bs") #minimum values of theta1 , theta2
plt.title(title, fontsize=16)
plt.axis([t1a,t1b, t2a,t2b])
if i ==1:
plt.xlabel(r"$\theta_1$", fontsize=20)
plt.show()
You can get a sense of why this is the case by looking at above Figure: on the top-left plot, the background contours (ellipses) represent an unregularized MSE cost function (α = 0), and the white circles show the Batch Gradient Descent path with that
cost function. The foreground contours (diamonds) represent the ℓ1 penalty, and the yellow triangles show the BGD path for this penalty only (α → ∞). Notice how the path first reaches θ1 = 0, then rolls down a gutter until it reaches θ2 = 0. 
On the top-right plot, the contours represent the same cost function plus an ℓ1 penalty with α = 0.5. The global minimum is on the θ2 = 0 axis. BGD first reaches θ2 = 0( Lasso Regression automatically performs feature selection and outputs a sparse model (i.e., with few nonzero feature weights) ), then rolls down the gutter until it reaches the global minimum. 
The two bottom plots show the same thing but uses an ℓ2 penalty(with α = 0.1) instead. The regularized minimum is closer to θ = 0  than the unregularized minimum
than the unregularized minimum  , but(On Ridge) the weights do not get fully eliminated 但权重不能完全消除.
, but(On Ridge) the weights do not get fully eliminated 但权重不能完全消除.
################################
TIP
On the Lasso cost function, the BGD path tends to bounce反弹 across the gutter toward the end . This is because the slope changes abruptly at θ2 = 0( Lasso Regression automatically performs feature selection and outputs a sparse model (i.e., with few nonzero feature weights) ). You need to gradually reduce the learning rate in order to actually converge to the global minimum.
. This is because the slope changes abruptly at θ2 = 0( Lasso Regression automatically performs feature selection and outputs a sparse model (i.e., with few nonzero feature weights) ). You need to gradually reduce the learning rate in order to actually converge to the global minimum.
################################
The Lasso cost function is not differentiable无法进行微分运算 at θi = 0 (for i = 1, 2, ⋯, n), but Gradient Descent still works fine if you use a subgradient vector g instead when any θi = 0. Equation 4-11 shows a subgradient vector equation you can use for Gradient Descent with the Lasso cost function.
Equation 4-11. Lasso Regression subgradient vector

Here is a small Scikit-Learn example using the Lasso class. Note that you could instead use an SGDRegressor(penalty="l1").
from sklearn.linear_model import Lasso
lasso_reg = Lasso(alpha=0.1)
lasso_reg.fit(X,y)
lasso_reg.predict(([[1.5]
])
)#lasso_reg.intercept_, lasso_reg.coef_#(array([1.14537356]), array([0.26167212]))![]() # 1.14537356+ 0.26167212*1.5=1.53788174
# 1.14537356+ 0.26167212*1.5=1.53788174
from sklearn.linear_model import SGDRegressor
sgd_reg = SGDRegressor(penalty="l1", eta0=0.5, random_state=42)
sgd_reg.fit(X,y)
sgd_reg.predict([[1.5]])#sgd_reg.intercept_, sgd_reg.coef_ #(array([0.94102563]), array([0.4133915]))![]() # 0.94102563 + 0.4133915 * 1.5 = 1.56111288
# 0.94102563 + 0.4133915 * 1.5 = 1.56111288
Elastic Net
Elastic Net is a middle ground between Ridge Regression and Lasso Regression. The regularization term is a simple mix of both Ridge and Lasso’s regularization terms, and you can control the mix ratio r. When r = 0, Elastic Net is equivalent to Ridge Regression, and when r = 1, it is equivalent to Lasso Regression (see Equation 4-12).
Equation 4-12. Elastic Net cost function
So when should you use plain Linear Regression (i.e., without any regularization), Ridge, Lasso, or Elastic Net? It is almost always preferable to have at least a little bit of regularization, so generally you should avoid plain Linear Regression. Ridge is a good default, but if you suspect怀疑 that only a few features are actually useful, you should prefer Lasso or Elastic Net since they tend to reduce the useless features’ weights down to zero as we have discussed. In general, Elastic Net is preferred over Lasso since Lasso may behave erratically不规律地 when the number of features is greater than the number of training instances or when several features are strongly correlated.
Here is a short example using Scikit-Learn’s ElasticNet (l1_ratio corresponds to the mix ratio r):
from sklearn.linear_model import ElasticNet
elastic_net = ElasticNet(alpha=0.1, l1_ratio=0.5, random_state=42)
elastic_net.fit(X,y)
elastic_net.predict([[1.5]])#elastic_net.intercept_, elastic_net.coef_ # (array([1.08639303]), array([0.30462619]))![]()
Early Stopping
A very different way to regularize iterative learning algorithms such as Gradient Descent is to stop training as soon as the validation error reaches a minimum. This is called early stopping. Figure 4-20 shows a complex model (in this case a high-degree Polynomial Regression model) being trained using Batch Gradient Descent. As the epochs go by, the algorithm learns and its prediction error (RMSE) on the training set naturally goes down, and so does its prediction error on the validation set. However, after a while the validation error stops decreasing and actually starts to go back up. This indicates that the model has started to overfit the training data. With early stopping you just stop training as soon as the validation error reaches the minimum. It is such a simple and efficient regularization technique that Geoffrey Hinton called it a “beautiful free lunch.”
np.random.seed(42)
m=100
X = 6*np.random.rand(m,1)-3
y = 2+X + 0.5 * X**2 + np.random.randn(m,1)
X_train, X_val, y_train, y_val = train_test_split(X[:50], y[:50].ravel(), test_size=0.5, random_state=10)
poly_scaler = Pipeline([
("poly_features", PolynomialFeatures(degree=90, include_bias=False)),
("std_scaler", StandardScaler())
])
X_train_poly_scaled = poly_scaler.fit_transform(X_train)
#use the mean and variance which is from StandardScaler() of poly_scaler.fit_transform(X_train)
X_val_poly_scaled = poly_scaler.transform(X_val)
#Note that with warm_start=True, when the fit() method is called, it just continues
#training where it left off instead of restarting from scratch.
sgd_reg = SGDRegressor(max_iter=1, tol=-np.infty,warm_start=True,
penalty=None, learning_rate="constant", eta0=0.0005, random_state=42)
n_epochs=500
train_errors, val_errors=[],[]
for epoch in range(n_epochs):
sgd_reg.fit(X_train_poly_scaled, y_train)
y_train_predict = sgd_reg.predict(X_train_poly_scaled)
y_val_predict = sgd_reg.predict(X_val_poly_scaled)
train_errors.append(mean_squared_error(y_train, y_train_predict))
val_errors.append(mean_squared_error(y_val, y_val_predict))
best_epoch = np.argmin(val_errors)
best_val_rmse = np.sqrt(val_errors[best_epoch])
plt.annotate("Best model",
xy=(best_epoch, best_val_rmse),
xytext = (best_epoch, best_val_rmse+1),
ha="center",
arrowprops=dict(facecolor="black", shrink=0.05),
fontsize=16,
)
best_val_rmse -= 0.03 # just to make the graph look better (move the horizontal blackline down -0.03)
plt.plot([0, n_epochs], [best_val_rmse, best_val_rmse], "k:", linewidth=2) # horizontal black line
#hiding: list(range(0, n_epochs,1)),
plt.plot( np.sqrt(val_errors), "b-", linewidth=3, label="Validation set")
plt.plot( np.sqrt(train_errors), "r--", linewidth=2, label="Training set")
plt.legend(loc="upper right", fontsize=14)
plt.xlabel("Epoch", fontsize=14)
plt.ylabel("RMSE", fontsize=14)
plt.title("Figure 4-20. Early stopping regularization")
plt.show()
#################################
TIP
With Stochastic and Mini-batch Gradient Descent, the curves are not so smooth, and it may be hard to know whether you have reached the minimum or not. One solution is to stop only after the validation error has been above the minimum for some time (when you are confident that the model will not do any better), then roll back the model parameters to the point where the validation error was at a minimum.
#################################
Here is a basic implementation of early stopping:
from sklearn.base import clone
poly_scaler = Pipeline([
("poly_features", PolynomialFeatures(degree=90, include_bias=False)),
("std_scaler", StandardScaler())
])
X_train_poly_scaled = poly_scaler.fit_transform(X_train)
#use the mean and variance which is from StandardScaler() of poly_scaler.fit_transform(X_train)
X_val_poly_scaled = poly_scaler.transform(X_val)
#Note that with warm_start=True, when the fit() method is called, it just continues training where it left
#off instead of restarting from scratch.
sgd_reg = SGDRegressor(max_iter=1, tol=-np.infty, warm_start=True,
penalty=None, learning_rate="constant", eta0=0.0005, random_state=42)
minimum_val_error = float("inf")
best_epoch = None
best_model = None
for epoch in range(1000):
sgd_reg.fit(X_train_poly_scaled, y_train)
y_val_predict = sgd_reg.predict(X_val_poly_scaled)
val_error = mean_squared_error(y_val, y_val_predict)
if val_error < minimum_val_error:
minimum_val_error = val_error
best_epoch = epoch
best_model = clone(sgd_reg)best_epoch, best_model
Logistic Regression
some regression algorithms can be used for classification as well (and vice versa). Logistic Regression (also called Logit Regression) is commonly used to estimate the probability that an instance belongs to a particular class (e.g., what is the probability that this email is spam?). If the estimated probability is greater than 50%, then the model predicts that the instance belongs to that class (called the positive class, labeled “1”), or else it predicts that it does not (i.e., it belongs to the negative class, labeled “0”). This makes it a binary classifier.
Estimating Probabilities
So how does it work? Just like a Linear Regression model, a Logistic Regression model computes a weighted sum of the input features (plus a bias term), but instead of outputting the result directly like the Linear Regression model does, it outputs the logistic of this result (see Equation 4-13).
Equation 4-13. Logistic Regression model estimated probability (vectorized form) 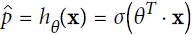
The logistic—also called the logit, noted σ(·)—is a sigmoid function (i.e., S-shaped) that outputs a number between 0 and 1. It is defined as shown in Equation 4-14 and Figure 4-21.
Equation 4-14. Logistic function
t = np.linspace(-10, 10, 100)
sigmoid = 1/( 1+np.exp(-t) )
plt.figure(figsize=(9,3))
plt.plot([-10, 10], [0,0], 'k-') #horizontal line/axis
plt.plot([-10, 10], [0.5, 0.5], "k:") #horizontal dotted line y=0.5
plt.plot([-10, 10], [1,1], "k:") #horizontal dotted line y=1.0
plt.plot([0,0], [-1.1, 1.1], "k-") #vertical line x=0.0
plt.plot(t, sigmoid, "b-", linewidth=2, label=r"$\sigma(t)=\frac{1}{1+e^{-t}}$")
plt.xlabel("t")
plt.legend(loc="upper left", fontsize=20)
plt.axis([-10,10, -0.1,1.1])
plt.title("Figure 4-21. Logistic function")
plt.show()
Once the Logistic Regression model has estimated the probability  that an instance x belongs to the positive class, it can make its prediction ŷ easily (see Equation 4-15).
that an instance x belongs to the positive class, it can make its prediction ŷ easily (see Equation 4-15).
Equation 4-15. Logistic Regression model prediction
Notice that σ(t) < 0.5 when t < 0, and σ(t) ≥ 0.5 when t ≥ 0, so a Logistic Regression model predicts 1 if  is positive, and 0 if it is negative.
is positive, and 0 if it is negative.
Note: and t= and
and
Training and Cost Function
Good, now you know how a Logistic Regression model estimates probabilities and makes predictions. But how is it trained? The objective of training is to set the parameter vector θ so that the model estimates high probabilities for positive instances (y =1) and low probabilities for negative instances (y = 0). This idea is captured by the cost function shown in Equation 4-16 for a single training instance x. OR
OR 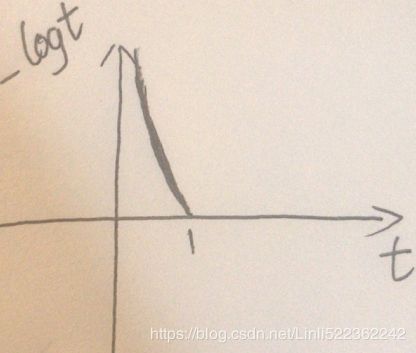
Equation 4-16. Cost function of a single training instance
 OR
OR 
This cost function makes sense because –log(t) grows very large when t approaches 0 (e.g. -log(0.1)==1,
-log(0.0000000001)==10,
so the cost ![]() will be large if the model estimates a probability
will be large if the model estimates a probability ![]() close to 0 for a positive instance(if y=1), and it
close to 0 for a positive instance(if y=1), and it ![]() will also be very large if the model estimates a probability
will also be very large if the model estimates a probability![]() close to 1 for a negative instance(if y=0).
close to 1 for a negative instance(if y=0).
On the other hand, – log(t) is close to 0 when t is close to 1,
so the cost ![]() will be close to 0 if the estimated probability
will be close to 0 if the estimated probability![]() is close to 0 for a negative instance(if y=0) ;
is close to 0 for a negative instance(if y=0) ; ![]() will be close to 0 if the estimated probability
will be close to 0 if the estimated probability ![]() is close to 1 for a positive instance(if y=1), which is precisely what we want.
is close to 1 for a positive instance(if y=1), which is precisely what we want.
The cost function over the whole training set is simply the average cost over all training instances. It can be written in a single expression (as you can verify easily), called the log loss, shown in Equation 4-17
Equation 4-17. Logistic Regression cost function (log loss) 


The bad news is that there is no known closed-form equation to compute the value of θ that minimizes this cost function (there is no equivalent of the Normal Equation). But the good news is that this cost function is convex, so Gradient Descent (or any other optimization algorithm) is guaranteed to find the global minimum ( , Once the left theta == right theta, the
, Once the left theta == right theta, the  ==
== ==0, we at
==0, we at  get the minimum of cost function(see above right figure), we should replace
get the minimum of cost function(see above right figure), we should replace ![]() with The partial derivatives of the cost function)
with The partial derivatives of the cost function)
(if the learning rate is not too large and you wait long enough). The partial derivatives of the cost function with regards to the jth model parameter ![]() is given by Equation 4-18.
is given by Equation 4-18.
Equation 4-18. Logistic cost function partial derivatives 
############################################
https://medium.com/mathematics-behind-optimization-of-cost-function/derivative-of-log-loss-function-for-logistic-regression-9b832f025c2d
and 

Next:



############################################
Equation 4-18. Logistic cost function partial derivatives

This equation(Equation 4-18) looks very much like Equation 4-5: for each instance it computes the prediction error  and multiplies it by the jth feature value
and multiplies it by the jth feature value , and then it computes the average over all training instances
, and then it computes the average over all training instances . Once you have the gradient vector containing all the partial derivatives you can use it in the Batch Gradient Descent algorithm. That’s it: you now know how to train a Logistic Regression model. For Stochastic GD you would of course just take one instance at a time, and for Mini-batch GD you would use a mini-batch at a time.
. Once you have the gradient vector containing all the partial derivatives you can use it in the Batch Gradient Descent algorithm. That’s it: you now know how to train a Logistic Regression model. For Stochastic GD you would of course just take one instance at a time, and for Mini-batch GD you would use a mini-batch at a time.
Decision Boundaries