Introduction to Data Science in Python 第 3 周 Assignment
Assignment 3 - More Pandas
Question 1 (20%)
Load the energy data from the file Energy Indicators.xls, which is a list of indicators of energy supply and renewable electricity production from the United Nations for the year 2013, and should be put into a DataFrame with the variable name of energy.
Keep in mind that this is an Excel file, and not a comma separated values file. Also, make sure to exclude the footer and header information from the datafile. The first two columns are unneccessary, so you should get rid of them, and you should change the column labels so that the columns are:
['Country', 'Energy Supply', 'Energy Supply per Capita', '% Renewable']
Convert Energy Supply to gigajoules (there are 1,000,000 gigajoules in a petajoule). For all countries which have missing data (e.g. data with “…”) make sure this is reflected as np.NaN values.
Rename the following list of countries (for use in later questions):
"Republic of Korea": "South Korea",
"United States of America": "United States",
"United Kingdom of Great Britain and Northern Ireland": "United Kingdom",
"China, Hong Kong Special Administrative Region": "Hong Kong"
There are also several countries with numbers and/or parenthesis in their name. Be sure to remove these,
e.g.
'Bolivia (Plurinational State of)' should be 'Bolivia',
'Switzerland17' should be 'Switzerland'.
Next, load the GDP data from the file world_bank.csv, which is a csv containing countries’ GDP from 1960 to 2015 from World Bank. Call this DataFrame GDP.
Make sure to skip the header, and rename the following list of countries:
"Korea, Rep.": "South Korea",
"Iran, Islamic Rep.": "Iran",
"Hong Kong SAR, China": "Hong Kong"
Finally, load the Sciamgo Journal and Country Rank data for Energy Engineering and Power Technology from the file scimagojr-3.xlsx, which ranks countries based on their journal contributions in the aforementioned area. Call this DataFrame ScimEn.
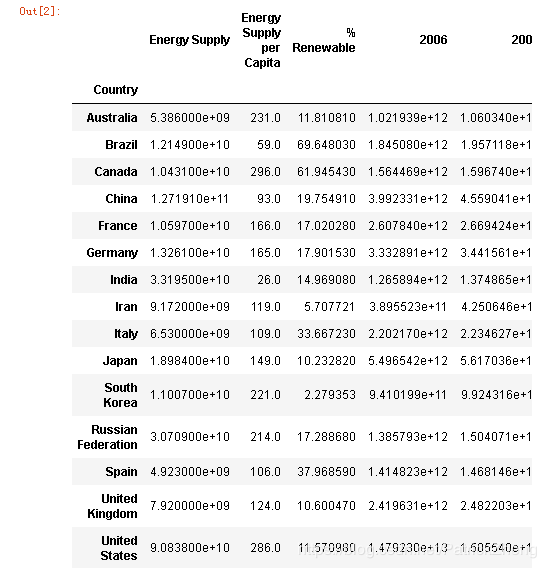
Join the three datasets: GDP, Energy, and ScimEn into a new dataset (using the intersection of country names). Use only the last 10 years (2006-2015) of GDP data and only the top 15 countries by Scimagojr ‘Rank’ (Rank 1 through 15).
The index of this DataFrame should be the name of the country, and the columns should be [‘Rank’, ‘Documents’, ‘Citable documents’, ‘Citations’, ‘Self-citations’,
‘Citations per document’, ‘H index’, ‘Energy Supply’,
‘Energy Supply per Capita’, ‘% Renewable’, ‘2006’, ‘2007’, ‘2008’,
‘2009’, ‘2010’, ‘2011’, ‘2012’, ‘2013’, ‘2014’, ‘2015’].
This function should return a DataFrame with 20 columns and 15 entries.
import pandas as pd
import numpy as np
def get_energy():
###########################
# Part One
# Enery Indicators.xls
#
energy_df = pd.read_excel('Energy Indicators.xls', skiprows=16)
del energy_df['Unnamed: 0']
del energy_df['Unnamed: 1']
# Drop NA data in excel
energy_df.dropna(inplace=True)
# change the column labels ['Country', 'Energy Supply', 'Energy Supply per Capita', '% Renewable']
energy_df.rename(columns={"Unnamed: 2":"Country", "Renewable Electricity Production": "% Renewable", "Energy Supply per capita": "Energy Supply per Capita"}, inplace=True)
# Convert Energy Supply to gigajoules (there are 1,000,000 gigajoules in a petajoule).
energy_df.replace('...', np.NaN, inplace=True)
# For all countries which have missing data (e.g. data with "...") make sure this is reflected as np.NaN values
energy_df['Energy Supply'] = energy_df['Energy Supply'] * 1000000
# There are also several countries with numbers and/or parenthesis in their name
energy_df['Country'] = energy_df['Country'].str.replace(' \(.*\)', '')
energy_df['Country'] = energy_df['Country'].str.replace('[0-9]*', '')
# Rename the following list of countries
x = {
"Republic of Korea": "South Korea",
"United States of America": "United States",
"United Kingdom of Great Britain and Northern Ireland": "United Kingdom",
"China, Hong Kong Special Administrative Region": "Hong Kong"
}
for item in x:
energy_df['Country'].replace(item, x[item], inplace=True)
return energy_df
def get_gdp():
# Part TWO
# world_bank.csv
gdp_df = pd.read_csv('world_bank.csv', skiprows=4)
# rename the following list of countries
y = {
"Korea, Rep.": "South Korea",
"Iran, Islamic Rep.": "Iran",
"Hong Kong SAR, China": "Hong Kong"
}
for item in y:
gdp_df['Country Name'].replace(item, y[item], inplace=True)
gdp_df.rename(columns={'Country Name': 'Country'}, inplace=True)
return gdp_df
def get_rank():
###########################
# Part THREE
# scimagojr-3.xlsx
ScimEn = pd.read_excel('scimagojr-3.xlsx')
return ScimEn
def answer_one():
energy_df = get_energy()
gdp_df = get_gdp()
ScimEn = get_rank()
###########################
#
# Use only the last 10 years (2006-2015) of GDP data and only the top 15 countries by Scimagojr 'Rank' (Rank 1 through 15).
for i in range(1960, 2006):
gdp_df.drop([str(i)], axis=1, inplace=True)
ScimEn = ScimEn[0:15]
# Join the three datasets: GDP, Energy, and ScimEn into a new dataset (using the intersection of country names).
temp1 = pd.merge(energy_df, gdp_df, how="inner", left_on="Country", right_on="Country")
temp2 = pd.merge(temp1, ScimEn, how="inner")
# The index of this DataFrame should be the name of the country
temp2.set_index('Country', inplace=True)
# the columns should be ['Rank', 'Documents', 'Citable documents', 'Citations', 'Self-citations', 'Citations per document', 'H index', 'Energy Supply', 'Energy Supply per Capita', '% Renewable', '2006', '2007', '2008', '2009', '2010', '2011', '2012', '2013', '2014', '2015'].
list_to_be_drop = ['Country Code', 'Indicator Name', 'Indicator Code']
for item in list_to_be_drop:
temp2.drop(item, axis=1, inplace=True)
# Check
# real = temp2.columns.tolist()
# shouldbe = ['Rank', 'Documents', 'Citable documents', 'Citations', 'Self-citations', 'Citations per document', 'H index', 'Energy Supply', 'Energy Supply per Capita', '% Renewable', '2006', '2007', '2008', '2009', '2010', '2011', '2012', '2013', '2014', '2015']
# print(real.sort() == shouldbe.sort())
# for item in real:
# if item in shouldbe:
# print('YES: {} in'.format(item))
# else:
# print('NO: {} not in'.format(item))
return temp2
answer_one()
Question 2 (6.6%)
The previous question joined three datasets then reduced this to just the top 15 entries. When you joined the datasets, but before you reduced this to the top 15 items, how many entries did you lose?
This function should return a single number.
# 三个集合的并集: A + B + C - AB - AC - BC + ABC
# 本题要求的是“lose after merging”,也就是 三者并集 减去 三者交集,即
# A + B + C - AB - AC - BC
def answer_two():
energy_df = get_energy()
gdp_df = get_gdp()
rank_df = get_rank()
energy_len = len(energy_df)
# print(energy_len)
gdp_len = len(gdp_df)
# print(gdp_len)
rank_len = len(rank_df)
# print(rank_len)
tempAB = pd.merge(energy_df, gdp_df, how="inner")
merge_AB_len = len(tempAB)
# print(merge_AB_len)
tempAC = pd.merge(energy_df, rank_df, how="inner")
merge_AC_len = len(tempAC)
# print(merge_AC_len)
tempBC = pd.merge(rank_df, gdp_df, how="inner")
merge_BC_len = len(tempBC)
# print(merge_BC_len)
result = energy_len + gdp_len + rank_len - merge_AB_len - merge_AC_len - merge_BC_len
# print(result)
return result
answer_two()
![]()
Question 3 (6.6%)
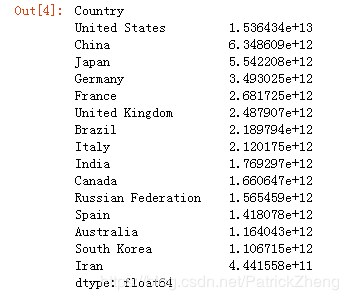
What is the average GDP over the last 10 years for each country? (exclude missing values from this calculation.)
This function should return a Series named avgGDP with 15 countries and their average GDP sorted in descending order.
def answer_three():
Top15 = answer_one()
gdp_list = Top15[[str(i) for i in range(2006, 2016)]]
# 默认是按列进行统计,这里要标记axis=1(按行统计)
avgGDP = gdp_list.mean(axis=1).sort_values(ascending=False)
return avgGDP
answer_three()
Question 4 (6.6%)
By how much had the GDP changed over the 10 year span for the country with the 6th largest average GDP?
This function should return a single number.
def answer_four():
Top15 = answer_one()
_6th = answer_three().index[5]
gdp_list = Top15[[str(i) for i in range(2006, 2016)]]
result = gdp_list.loc[_6th]
return result[-1] - result[0]
answer_four()
![]()
Question 5 (6.6%)
What is the mean Energy Supply per Capita?
This function should return a single number.
def answer_five():
Top15 = answer_one()
return Top15['Energy Supply per Capita'].mean(axis=0)
answer_five()
![]()
Question 6 (6.6%)
What country has the maximum % Renewable and what is the percentage?
This function should return a tuple with the name of the country and the percentage.
def answer_six():
Top15 = answer_one()
max = Top15['% Renewable'].max()
result = Top15[Top15['% Renewable'] == max]
return (result.index[0], max)
answer_six()
![]()
Question 7 (6.6%)
Create a new column that is the ratio of Self-Citations to Total Citations.
What is the maximum value for this new column, and what country has the highest ratio?
This function should return a tuple with the name of the country and the ratio.
def answer_seven():
Top15 = answer_one()
total_citations = Top15['Self-citations'].sum() # 万恶啊,不是算总数。。
Top15['Ratio'] = Top15['Self-citations'] / Top15['Citations']
max = Top15['Ratio'].max()
result = Top15[Top15['Ratio'] == max]
return (result.index[0], max)
answer_seven()
![]()
Question 8 (6.6%)
Create a column that estimates the population using Energy Supply and Energy Supply per capita.
What is the third most populous country according to this estimate?
This function should return a single string value.
def answer_eight():
Top15 = answer_one()
Top15['Population'] = Top15['Energy Supply'] / Top15['Energy Supply per Capita']
Top15.sort_values(by='Population', ascending=False, inplace=True)
return Top15.iloc[2].name
answer_eight()
![]()
Question 9 (6.6%)
Create a column that estimates the number of citable documents per person.
What is the correlation between the number of citable documents per capita and the energy supply per capita? Use the .corr() method, (Pearson’s correlation).
This function should return a single number.
(Optional: Use the built-in function plot9() to visualize the relationship between Energy Supply per Capita vs. Citable docs per Capita)
def answer_nine():
Top15 = answer_one()
Top15['PopEst'] = Top15['Energy Supply'] / Top15['Energy Supply per Capita']
Top15['Citable docs per Capita'] = Top15['Citable documents'] / Top15['PopEst']
result = Top15['Citable docs per Capita'].corr(Top15['Energy Supply per Capita'])
return result
answer_nine()
![]()
Question 10 (6.6%)
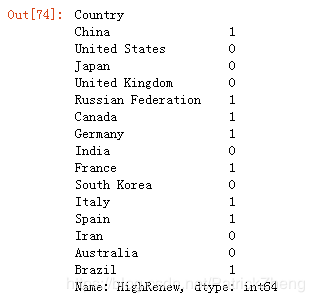
Create a new column with a 1 if the country’s % Renewable value is at or above the median for all countries in the top 15, and a 0 if the country’s % Renewable value is below the median.
This function should return a series named HighRenew whose index is the country name sorted in ascending order of rank.
def answer_ten():
Top15 = answer_one()
median = Top15['% Renewable'].median()
Top15['HighRenew'] = (Top15['% Renewable'] >= median) * 1
return Top15.sort_values('Rank')['HighRenew']
answer_ten()
Question 11 (6.6%)
Use the following dictionary to group the Countries by Continent, then create a dateframe that displays the sample size (the number of countries in each continent bin), and the sum, mean, and std deviation for the estimated population of each country.
ContinentDict = {'China':'Asia',
'United States':'North America',
'Japan':'Asia',
'United Kingdom':'Europe',
'Russian Federation':'Europe',
'Canada':'North America',
'Germany':'Europe',
'India':'Asia',
'France':'Europe',
'South Korea':'Asia',
'Italy':'Europe',
'Spain':'Europe',
'Iran':'Asia',
'Australia':'Australia',
'Brazil':'South America'}
This function should return a DataFrame with index named Continent ['Asia', 'Australia', 'Europe', 'North America', 'South America'] and columns ['size', 'sum', 'mean', 'std']
ContinentDict = {'China':'Asia',
'United States':'North America',
'Japan':'Asia',
'United Kingdom':'Europe',
'Russian Federation':'Europe',
'Canada':'North America',
'Germany':'Europe',
'India':'Asia',
'France':'Europe',
'South Korea':'Asia',
'Italy':'Europe',
'Spain':'Europe',
'Iran':'Asia',
'Australia':'Australia',
'Brazil':'South America'}
def answer_eleven():
Top15 = answer_one()
Top15['PopEst'] = Top15['Energy Supply'] / Top15['Energy Supply per Capita']
Top15_population = Top15['PopEst']
group = Top15_population.groupby(ContinentDict)
# size = pd.DataFrame(group.size(), columns=['size'])
# print(size)
# sum = pd.DataFrame(group.sum()).rename(columns={'PopEst': 'sum'})
# print(sum)
# mean = pd.DataFrame(group.mean()).rename(columns={'PopEst': 'mean'})
# print(mean)
# std = pd.DataFrame(group.std()).rename(columns={'PopEst': 'std'})
# print(std)
# result = pd.merge(size, sum, left_index=True, right_index=True).merge(mean, left_index=True, right_index=True).merge(std, left_index=True, right_index=True)
size = group.size().astype('float64')
sum = group.sum()
mean = group.mean()
std = group.std()
result = pd.DataFrame({
'size': size,
'sum': sum,
'mean': mean,
'std': std
})
return result
answer_eleven()

Question 12 (6.6%)
Cut % Renewable into 5 bins. Group Top15 by the Continent, as well as these new % Renewable bins. How many countries are in each of these groups?
This function should return a Series with a MultiIndex of Continent, then the bins for % Renewable. Do not include groups with no countries.
ContinentDict = {'China':'Asia',
'United States':'North America',
'Japan':'Asia',
'United Kingdom':'Europe',
'Russian Federation':'Europe',
'Canada':'North America',
'Germany':'Europe',
'India':'Asia',
'France':'Europe',
'South Korea':'Asia',
'Italy':'Europe',
'Spain':'Europe',
'Iran':'Asia',
'Australia':'Australia',
'Brazil':'South America'}
def answer_twelve():
Top15 = answer_one()
cut = pd.cut(Top15['% Renewable'], bins=5)
Top15['bin'] = cut
group = Top15.groupby(by=[ContinentDict, cut])
# for name, group in result:
# print(name)
# print(group)
result = group.size()
return result
answer_twelve()

Question 13 (6.6%)
Convert the Population Estimate series to a string with thousands separator (using commas). Do not round the results.
e.g. 317615384.61538464 -> 317,615,384.61538464
This function should return a Series PopEst whose index is the country name and whose values are the population estimate string.
def answer_thirteen():
Top15 = answer_one()
Top15['PopEst'] = Top15['Energy Supply'] / Top15['Energy Supply per Capita']
Top15['PopEst'] = Top15['PopEst'].map(lambda x: format(x, ',')) # 来源:https://blog.csdn.net/dta0502/article/details/82974541
result = Top15['PopEst']
return result
answer_thirteen()

