MongoDB分布式集群搭建(副本集+分片集群)、数据备份与恢复
文章目录
- MongoDB分片介绍
- MongoDB集群搭建
- 创建config server副本集
- 配置分片
- 配置mongos路由服务器
- 测试MongoDB分片
- MongoDB数据备份与恢复
MongoDB分片介绍
分片就是将数据库进行拆分,将大型集合分隔到不同服务器上。比如,本来100G的数据,可以分割成10份存储到10台服务器上,这样每台机器只有10G的数据,通过一个mongos的进程(路由)实现分片后的数据存储与访问,也就是说mongos是整个分片架构的核心,对客户端而言是不知道是否有分片的,客户端只需要把读写操作转达给mongos即可。虽然分片会把数据分隔到很多台服务器上,但是每一个节点都是需要有一个备用角色(副本集),这样能保证数据的高可用。当系统需要更多空间或者资源的时候,分片可以让我们按需方便扩展,只需要把mongodb服务的机器加入到分片集群中即可
MongoDB副本集配置见:https://blog.csdn.net/Powerful_Fy/article/details/103604693
分片架构图
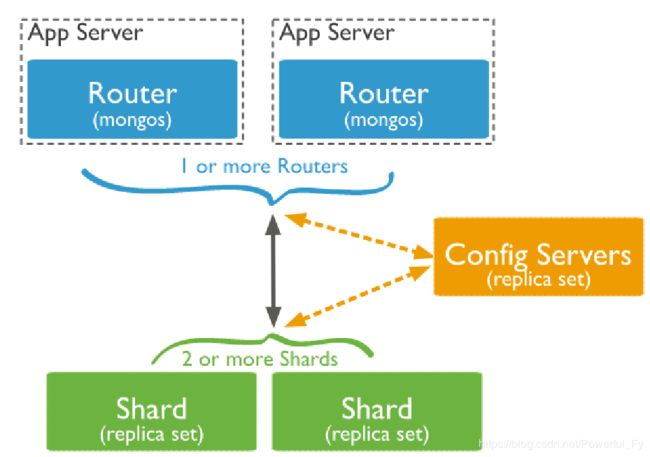
MongoDB分片集群先关概念
mongos: 数据库集群请求的入口,所有的请求都通过mongos进行协调,不需要在应用程序添加一个路由选择器,mongos自己就是一个请求分发中心,它负责把对应的数据请求转发到对应的shard服务器上。在生产环境通常有多个mongos作为请求的入口,防止其中一个挂掉所有的mongodb请求都没有办法操作。
config server: 配置服务器,存储所有数据库元信息(路由、分片)的配置。
shard: 存储了一个集合部分数据的MongoDB实例,每个分片是单独的mongodb服务或者副本集,在生产环境中,所有的分片都应该是副本集
mongos本身没有物理存储分片服务器和数据路由信息,只是缓存在内存里,config配置服务器则实际存储这些数据。mongos第一次启动或者关掉重启就会从config server加载配置信息,以后如果配置服务器信息变化会通知到所有的mongos更新自己的状态,这样 mongos 就能继续准确路由,在生产环境通常有多个config server配置服务器,因为它存储了分片路由的元数据,防止数据丢失
MongoDB集群搭建
服务器规划
A机器(192.168.234.128)搭建:mongos、config server、副本集1主节点、副本集2的仲裁、副本集3从节点
B机器(192.168.234.130)搭建:mongos、config server、副本集1从节点、副本集2主节点、副本集3的仲裁
C机器(192.168.234.125)搭建:mongos、config server、副本集1的仲裁、副本集2从节点、副本集3主节点
端口分配:mongos 2000、config 21000、副本集1 22001、副本集2 22002、副本集3 22003
分别在三台机上创建所需要的目录
[root@linux ~]# mkdir -p /data/mongodb/mongos/log
[root@linux ~]# mkdir -p /data/mongodb/config/{data,log}
[root@linux ~]# mkdir -p /data/mongodb/shard1/{data,log}
[root@linux ~]# mkdir -p /data/mongodb/shard2/{data,log}
[root@linux ~]# mkdir -p /data/mongodb/shard3/{data,log}
创建config server副本集
分别在三台机器创建配置文件
[root@linux ~]# mkdir /etc/mongod/
[root@linux ~]# vim /etc/mongod/config.conf
A机器配置文件内容
pidfilepath = /var/run/mongodb/configsrv.pid
dbpath = /data/mongodb/config/data
logpath = /data/mongodb/config/log/congigsrv.log
logappend = true
bind_ip = 127.0.0.1,192.168.234.128
port = 21000
fork = true
configsvr = true
replSet=configs #副本集名称
maxConns=20000 #设置最大连接数
B机器配置文件内容
pidfilepath = /var/run/mongodb/configsrv.pid
dbpath = /data/mongodb/config/data
logpath = /data/mongodb/config/log/congigsrv.log
logappend = true
bind_ip = 127.0.0.1,192.168.234.130
port = 21000
fork = true
configsvr = true
replSet=configs #副本集名称
maxConns=20000 #设置最大连接数
C机器配置文件内容
pidfilepath = /var/run/mongodb/configsrv.pid
dbpath = /data/mongodb/config/data
logpath = /data/mongodb/config/log/congigsrv.log
logappend = true
bind_ip = 127.0.0.1,192.168.234.125
port = 21000
fork = true
configsvr = true
replSet=configs #副本集名称
maxConns=20000 #设置最大连接数
分别在三台机器启动config server
[root@linux ~]# mongod -f /etc/mongod/config.conf
about to fork child process, waiting until server is ready for connections.
forked process: 27118
child process started successfully, parent exiting
登录任意一台机器的21000端口
[root@linux ~]# mongo --port 21000
配置副本集
> config = { _id: "configs", members: [ {_id : 0, host : "192.168.234.128:21000"},{_id : 1, host : "192.168.234.130:21000"},{_id : 2, host : "192.168.234.125:21000"}] }
初始化
> rs.initiate(config)
{
"ok" : 1,
"$gleStats" : {
"lastOpTime" : Timestamp(1576745749, 1),
"electionId" : ObjectId("000000000000000000000000")
},
"lastCommittedOpTime" : Timestamp(0, 0),
"$clusterTime" : {
"clusterTime" : Timestamp(1576745749, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
},
"operationTime" : Timestamp(1576745749, 1)
}
configs:SECONDARY>
configs:PRIMARY>
#初始化后命令行前缀先变为configs:SECONDARY(从),过一会儿就会自动变为configs:PRIMARY(主),在哪台机器配置副本集,哪台机器就优先变为主
配置分片
分别在三台机器创建配置以下文件
创建shard1配置文件
[root@linux ~]# vim /etc/mongod/shard1.conf
配置文件内容
pidfilepath = /var/run/mongodb/shard1.pid
dbpath = /data/mongodb/shard1/data
logpath = /data/mongodb/shard1/log/shard1.log
logappend = true
bind_ip = 0.0.0.0
port = 22001
fork = true
replSet=shard1 #副本集名称
shardsvr = true #declare this is a shard db of a cluster;
maxConns=20000 #设置最大连接数
创建shard2配置文件
[root@linux ~]# vim /etc/mongod/shard2.conf
配置文件内容
pidfilepath = /var/run/mongodb/shard2.pid
dbpath = /data/mongodb/shard2/data
logpath = /data/mongodb/shard2/log/shard2.log
logappend = true
bind_ip = 0.0.0.0
port = 22002
fork = true
replSet=shard2 #副本集名称
shardsvr = true #declare this is a shard db of a cluster;
maxConns=20000 #设置最大连接数
创建shard3配置文件
[root@linux ~]# vim /etc/mongod/shard3.conf
配置文件内容
pidfilepath = /var/run/mongodb/shard3.pid
dbpath = /data/mongodb/shard3/data
logpath = /data/mongodb/shard3/log/shard3.log
logappend = true
bind_ip = 0.0.0.0
port = 22003
fork = true
replSet=shard3 #副本集名称
shardsvr = true #declare this is a shard db of a cluster;
maxConns=20000 #设置最大连接数
在A机器创建完后,可以通过scp命令将3个配置文件拷贝的B机器和C机器,如果bindip不是用的0.0.0.0,而使用的是网卡的ip,那每台机器上的3个配置文件中的bindip需要指定所在机器的ip
分别在三台机器启动shard1
[root@linux ~]# mongod -f /etc/mongod/shard1.conf
about to fork child process, waiting until server is ready for connections.
forked process: 2138
child process started successfully, parent exiting
在192.168.234.128或者192.168.234.130登录MongoDB的22001端口,创建副本集,之所以不能在192.168.234.125登录,是因为125是shard1的仲裁节点
[root@linux ~]# mongo --port 22001
> use admin
> config = { _id: "shard1", members: [ {_id : 0, host : "192.168.234.128:22001"}, {_id: 1,host : "192.168.234.130:22001"},{_id : 2, host : "192.168.234.125:22001",arbiterOnly:true}] }
初始化
> rs.initiate(config)
分别在三台机器启动shard2
[root@linux ~]# mongod -f /etc/mongod/shard2.conf
about to fork child process, waiting until server is ready for connections.
forked process: 2229
child process started successfully, parent exiting
在130或者125机器登录MongoDB的22002端口,创建副本集,之所以不能在128登录,是因为128是shard2的仲裁节点
[root@linux02 ~]# mongo --port 22002
> use admin
> config = { _id: "shard2", members: [ {_id : 0, host : "192.168.234.128:22002" ,arbiterOnly:true},{_id : 1, host : "192.168.234.130:22002"},{_id : 2, host : "192.168.234.125:22002"}] }
初始化
> rs.initiate(config)
分别在三台机器启动shard3
[root@linux ~]# mongod -f /etc/mongod/shard3.conf
about to fork child process, waiting until server is ready for connections.
forked process: 2296
child process started successfully, parent exiting
在128或者125机器登录MongoDB的22003端口,创建副本集,之所以不能在130登录,是因为130是shard3的仲裁节点
[root@linux03 ~]# mongo --port 22003
> use admin
> config = { _id: "shard3", members: [ {_id : 0, host : "192.168.234.128:22003"}, {_id : 1, host : "192.168.234.130:22003", arbiterOnly:true}, {_id : 2, host : "192.168.234.125:22003"}] }
初始化
> rs.initiate(config)
配置mongos路由服务器
分别在三台机器创建配置文件
vim /etc/mongod/mongos.conf
配置文件内容
pidfilepath = /var/run/mongodb/mongos.pid
logpath = /data/mongodb/mongos/log/mongos.log
logappend = true
bind_ip = 0.0.0.0
port = 20000
fork = true
configdb = configs/192.168.234.128:21000,192.168.234.130:21000,192.168.234.125:21000
maxConns=20000
分别在三台机器启动mongos服务
[root@linux ~]# mongos -f /etc/mongod/mongos.conf
about to fork child process, waiting until server is ready for connections.
forked process: 2508
child process started successfully, parent exiting
#注意命令是mongos,前面用的是mongod
在任意一台机器登录MongoDB 20000端口
[root@linux03 ~]# mongo --port 20000
启用分片(将分片和路由器串联)
mongos> sh.addShard("shard1/192.168.234.128:22001,192.168.234.130:22001,192.168.234.125:22001")
mongos> sh.addShard("shard2/192.168.234.128:22002,192.168.234.130:22002,192.168.234.125:22002")
mongos> sh.addShard("shard3/192.168.234.128:22003,192.168.234.130:22003,192.168.234.125:22003")
查看集群状态
mongos> sh.status()
--- Sharding Status ---
sharding version: {
"_id" : 1,
"minCompatibleVersion" : 5,
"currentVersion" : 6,
"clusterId" : ObjectId("5dfb3b20efa1b5c09c72b7fd")
}
shards:
{ "_id" : "shard1", "host" : "shard1/192.168.234.128:22001,192.168.234.130:22001", "state" : 1 }
{ "_id" : "shard2", "host" : "shard2/192.168.234.125:22002,192.168.234.130:22002", "state" : 1 }
{ "_id" : "shard3", "host" : "shard3/192.168.234.125:22003,192.168.234.128:22003", "state" : 1 }
active mongoses:
"4.2.2" : 3
autosplit:
Currently enabled: yes
balancer:
Currently enabled: yes
Currently running: no
Failed balancer rounds in last 5 attempts: 0
Migration Results for the last 24 hours:
No recent migrations
databases:
{ "_id" : "config", "primary" : "config", "partitioned" : true }
config.system.sessions
shard key: { "_id" : 1 }
unique: false
balancing: true
chunks:
shard1 1
{ "_id" : { "$minKey" : 1 } } -->> { "_id" : { "$maxKey" : 1 } } on : shard1 Timestamp(1, 0)
测试MongoDB分片
在任意一台机器连接MongoDB的20000端口
[root@linux ~]# mongo --port 20000
指定要分片的库db1
mongos> sh.enableSharding("db1")
#如果db1不存在会自动创建,指定分片的库的第二种方式:db.runCommand({ enablesharding : “db1”})
在db1库中创建/指定分片的集合cl01
mongos> sh.shardCollection("db1.cl01",{"id":1} )
#第二种方式:db.runCommand( { shardcollection : “db1.cl01”,key : {id: 1} } )
查看状态sh.status()中databases项即可看到db1库与cl01集合
databases:
{ "_id" : "config", "primary" : "config", "partitioned" : true }
config.system.sessions
shard key: { "_id" : 1 }
unique: false
balancing: true
chunks:
shard1 1
{ "_id" : { "$minKey" : 1 } } -->> { "_id" : { "$maxKey" : 1 } } on : shard1 Timestamp(1, 0)
{ "_id" : "db1", "primary" : "shard2", "partitioned" : true, "version" : { "uuid" : UUID("ba87a89d-163e-4c38-8cf8-07c46cc6c595"), "lastMod" : 1 } }
db1.cl01
shard key: { "id" : 1 }
unique: false
balancing: true
chunks:
shard2 1
{ "id" : { "$minKey" : 1 } } -->> { "id" : { "$maxKey" : 1 } } on : shard2 Timestamp(1, 0)
#db1库被存储到了shard2中
MongoDB数据备份与恢复
备份指定的库
[root@linux ~]# mongodump --port 20000 -d db1 -o /tmp/mongobak
#将db1库备份到/tmp/mongobak目录下
备份目录下会自动生成以库名命名的目录
[root@linux ~]# ls /tmp/mongobak/db1/
cl01.bson cl01.metadata.json
#每个集合会生成2个文件,数据存放在.bson文件中,该文件为二进制文件,不能直接查看
备份指定集合
[root@linux ~]# mongodump --port 20000 -d db1 -c cl01 -o /tmp/mongobak
#依然会在备份目录下生成以库名命名的目录,将备份出的集合存放到该目录中
备份所有库
[root@linux ~]# mongodump --port 20000 -o /tmp/mongobak
导出集合为json文件
[root@linux ~]# mongoexport --port 20000 -d db1 -c cl01 -o /tmp/cl01.json
查看json文件
[root@linux ~]# head -5 /tmp/cl01.json
{"_id":{"$oid":"5dfb6786a2dbe0c90a06c844"},"id":1.0,"test":"testval"}
{"_id":{"$oid":"5dfb6786a2dbe0c90a06c845"},"id":2.0,"test":"testval"}
{"_id":{"$oid":"5dfb6786a2dbe0c90a06c846"},"id":3.0,"test":"testval"}
{"_id":{"$oid":"5dfb6786a2dbe0c90a06c847"},"id":4.0,"test":"testval"}
{"_id":{"$oid":"5dfb6786a2dbe0c90a06c848"},"id":5.0,"test":"testval"}
恢复所有库
[root@linux ~]# mongorestore --port 20000 --drop /tmp/mongobak/
恢复指定的库
[root@linux ~]# mongorestore --port 20000 -d db1 /tmp/mongobak/db1/
恢复指定的集合
[root@linux ~]# mongorestore --port 20000 -d db1 -c cl01 /tmp/mongobak/db1/cl01.bson
将json文件的数据导入集合
[root@linux ~]# mongoimport --port 20000 -d db1 -c cl01 --file /tmp/cl01.json