ShardingSphere x Seata,一致性更强的分布式数据库中间件
日前,分布式数据库中间件 ShardingSphere 将 Seata 分布式事务能力进行整合,旨在打造一致性更强的分布式数据库中间件。
背景
数据库领域,分布式事务的实现主要包含:两阶段的 XA 和 BASE 柔性事务。
XA 事务底层,依赖于具体的数据库厂商对 XA 两阶段提交协议的支持。通常,XA 协议通过在 Prepare 和 Commit 阶段进行 2PL(2 阶段锁),保证了分布式事务的 ACID,适用于短事务及非云化环境(云化环境下一次 IO 操作大概需要 20ms,两阶段锁会锁住资源长达 40ms,因此热点行上的事务的 TPS 会降到 25/s 左右,非云化环境通常一次 IO 只需几毫秒,因此锁热点数据的时间相对较低)。
但在 BASE 柔性事务方面,ShardingSphere 提供的接入分布式事务的 SPI,只适用于对性能要求较高,对一致性要求比较低的业务。
Seata 核心的 AT 模式适用于构建于支持本地 ACID 事务的关系型数据库。通过整合 Seata,其 AT 模式在一阶段提交+补偿的基础上,通过 TC 的全局锁实现了 RC 隔离级别的支持,可提高 ShardingSphere 的分布式事务的一致性。
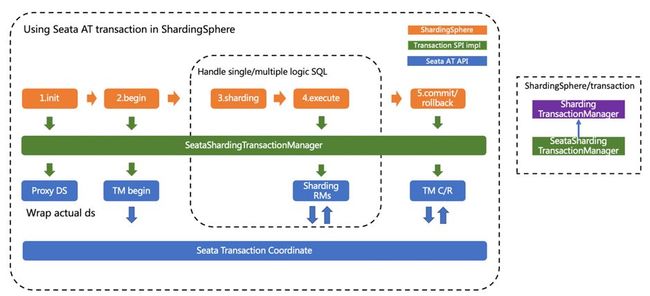
整合方案
整合 Seata AT 事务时,需要把 TM,RM,TC 的模型融入到 ShardingSphere 分布式事务的 SPI 的生态中。在数据库资源上,Seata 通过对接 DataSource 接口,让 JDBC 操作可以同 TC 进行 RPC 通信。同样,ShardingSphere 也是面向 DataSource 接口对用户配置的物理 DataSource 进行了聚合,因此把物理 DataSource 二次包装为 Seata 的 DataSource 后,就可以把 Seata AT 事务融入到 ShardingSphere 的分片中。
在 Seata 模型中,全局事务的上下文存放在线程变量中,通过扩展服务间的 transport,可以完成线程变量的传递,分支事务通过线程变量判断是否加入到整个 Seata 全局事务中。而 ShardingSphere 的分片执行引擎通常是按多线程执行,因此整合 Seata AT 事务时,需要扩展主线程和子线程的事务上下文传递,这同服务间的上下文传递思路完全相同。
Quick Start
ShardingSphere 已经实现了 base-seata-raw-jdbc-example,大家可以自行进行尝试:
https://github.com/apache/incubator-shardingsphere-example/tree/dev/sharding-jdbc-example/transaction-example/transaction-base-seata-example/transaction-base-seata-raw-jdbc-example
操作手册:
1、按照 seata-work-shop 中的步骤,下载并启动 seata server。
https://github.com/seata/seata-workshop
参考 Step6 和 Step7 即可。
2、在每一个分片数据库实例中执行 resources/sql/undo_log.sql 脚本,创建 undo_log 表
3、Run YamlConfigurationTransactionExample.java
关于 ShardingSphere
ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar(计划中)这 3 款相互独立的产品组成,提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如 Java 同构、异构语言、容器、云原生等各种多样化的应用场景。目前,已经拥有超过 8000 的 Star,57 位 Contributors。
关于 Seata
Seata 是阿里巴巴和蚂蚁金服共同开源的分布式事务中间件,融合了双方在分布式事务技术上的积累,并沉淀了新零售、云计算和新金融等场景下丰富的实践经验,以高效并且对业务 0 侵入的方式,解决微服务场景下面临的分布式事务问题。目前,已经拥有超过 9900 的 Star,83 位 Contributors。
