可分离卷积-Separable Convolutions
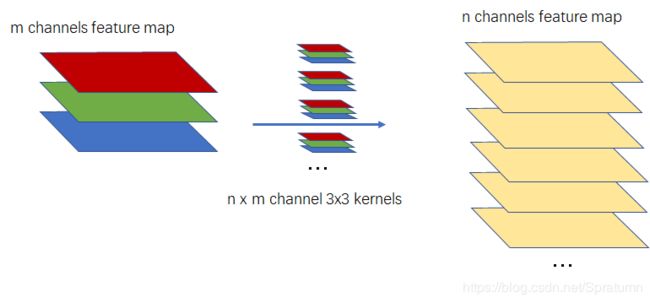
经典卷积层
一般卷积神经网络中,卷积运算的是使用与输入的feature map相同channel大小的kernel,kernel的每个通道与输入的每个通道对应卷积然后相加就得到输出feature的一个通道上的一个数据点。
因此有对应关系:
输入的通道数=每个kernel的通道数
输出的通道数=使用的kernel的数目
可以计算出这一层的训练参数:
N 1 = K × K × C i n × C o u t N_1=K \times K \times C_{in} \times C_{out} N1=K×K×Cin×Cout
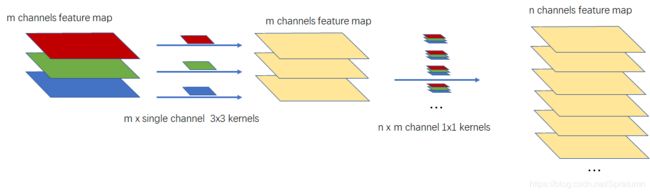
Depthwise Separable Convolutions
为了将卷积网络中的参数量减少同时又不明显的降低效果,引出了一种deep wise convolution。将卷积运算分为两个部分,首先使用一个单通道的kernel与输入feature map 的每一个通道分别进行卷积运算。获得的中间feature map 通道数与输入相同,然后再使用与中间feature map 相同通道数的kernel与其进行卷积,与上面的常规卷积层不同的是,这里的kernel的尺寸为1x1。
可以计算出这一层的训练参数:
N 2 = K × K × C i n + 1 × 1 × C i n × C o u t N_2=K \times K \times C_{in} +1\times1\times C_{in} \times C_{out} N2=K×K×Cin+1×1×Cin×Cout
做一个简单的例子进行对比:
K = 7 , C i n = 3 , C o u t = 8 K=7,C_{in}=3,C_{out}=8 K=7,Cin=3,Cout=8
N 1 = 7 × 7 × 3 × 8 = 1176 N 2 = 7 × 7 × 3 + 1 × 1 × 3 × 8 = 171 N_1=7 \times 7 \times 3 \times 8 = 1176 \\ N_2=7 \times 7 \times 3 +1\times1\times 3 \times 8 =171 N1=7×7×3×8=1176N2=7×7×3+1×1×3×8=171
经过这样的轻量化,参数会变为传统卷积参数量的 171 1176 = 0.145 \frac{171}{1176}=0.145 1176171=0.145.
过实验验证,轻量化后的结果精度降低一般约为1%,因此这个轻量化操作是非常有意义的。
代码示例
from torch import nn
from torchsummary import summary
class SeparableConv2d(nn.Module):
def __init__(self,in_channels,out_channels
,kernel_size=3,stride=1
,padding=0,dilation=1):
super(SeparableConv2d, self).__init__()
# groups=in_channels every filter match one feature map
self.deepwise_conv = nn.Conv2d(in_channels,in_channels
,kernel_size=kernel_size
,stride=stride
,padding=padding
,dilation=dilation
,groups=in_channels
,bias=False)
self.pointwise_conv = nn.Conv2d(in_channels,out_channels
,kernel_size=1
,bias=False)
def forward(self,x):
out = self.pointwise_conv(self.deepwise_conv(x))
return out
if __name__ == '__main__':
sep_conv = SeparableConv2d(3,8,kernel_size=7)
summary(sep_conv,(3,10,10))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 3, 4, 4] 147
Conv2d-2 [-1, 8, 4, 4] 24
================================================================
Total params: 171
Trainable params: 171
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.00
Params size (MB): 0.00
Estimated Total Size (MB): 0.00
----------------------------------------------------------------
Size (MB): 0.00
----------------------------------------------------------------