众所周知,一个文字从输入到显示到存储是有一个固定过程的,其过程为:输入码(根据输入法不同而不同)→机内码(根据语言环境不同而不同,不同的系统语言编码也不一样)→字型码(根据不同的字体而不同)→存储码(根据保存的编码类型不同而不同)。不同的存储码之间又有什么异同呢?
一、ASCII系列编码
首先来说明ASCII码(American Standard Code for Information Interchange,美国标准信息交换码),这个编码的时代就久远了,是由美国国家标准局(ANSI)制定,目前计算机中用得最广泛的字符集及其编码。 ASCII码有7位码和8位码两种形式。,英文编码用的。ASCII码图:
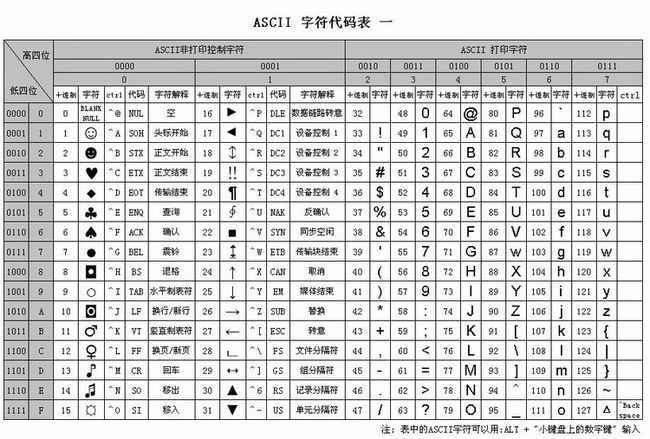
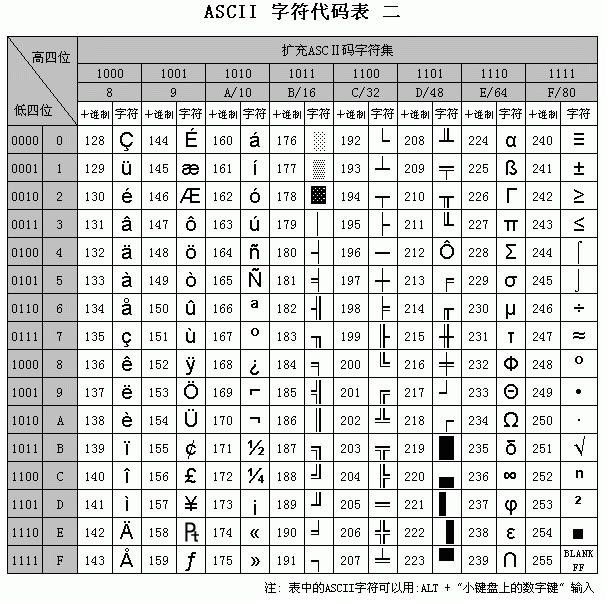
上图可以发现,最高位均为0,这样就浪费了128位的空间,于是就有了扩展ASCII码,如下图:
二、国标系列编码
接下来看看GB系列的编码。所谓GB嘛,就是国标。以GB2312-80来说明,这个编码是有区位码的概念的,每个字符用两个字节来表示。所谓区位码就是制定标准时,一个大矩阵,从0开始。但是由于一些特殊的编码在计算机中是有特殊的意义的,所以是不能直接使用区位码在计算机中表示字符的,这样就有了计算机内码,不同地区的计算机内码也就不同。对于国内的计算机,内码为GB2312-80(确切说显示在GB18030)。对于日本的就是Shift_JIS。
那么区位码的作用是什么呢?这就又得拿出另外一个概念了,那就是字型码。字型码中的字型是按照文字的区位码确定的,字型码存储在哪里呢?对,就是字体文件,每一个字体文件,都以区位码的形式存储自己的字型库。区位码到内码是如何转换的?首先,两个字节,每个字节的范围应该是0-255,但是由于编码可能会混合存储,为了避免GB编码与ASCII编码混乱,所以规定,GB2312-80的内码两个字节的最高位均为1,这样就不会与ASCII码产生混淆了。同时去除ASCII码中32个控制字符,也作为预留空间,这样可选范围就变为0xA0~0xFF(有一说法为作为国际通用的精确数字计算使用的BCD编码的范围是0x00~0x99,由此导致可选范围为0x9A~0xFF。同时为了预留一定空间避免冲突,可选范围应该在0xA0~0xFF之间,具体是哪个待考证)。作为习惯使用,从1开始,而0xFF在计算机中是有结束意思的,特别是在C语言中,所以舍弃。这样最终的范围就是0xA1~0xFE,即94X94。
最终变为这样:GB2312-80共收集了共7445个汉字和图形符号,其中汉字6763个,分为二级,一级汉字 3755个,二级汉字3008个。汉字图形符号根据其位置将其分为94个“区”,每个区包含94个汉字字符,每个汉字字符又称为一个“位”。汉字区的内码范围高字节从B0-F7,低字节从A1-FE,占用的码位是72*94=6768。其中有5个空位是D7FA-D7FE。区的序号和位的序号都是从01到94。所以区位码到机内码的转换方法为:机内码两个字节,每个字节各减去0xA0,转换为十进制即为区位码。
那么在内存中,文字又是如何存放的呢?我的猜测是,内存中是以当前系统的内码存放的,不管文件的存储编码为Unicode或者别的,在内存中均会转换为内码,因为字体文件即字型是根据计算机内码进行显示的。
上面只说了GB2312-80,其实现在标准已经进化了,经过GB2312-80→GBK→GB18030的进化,最新的GB18030,收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。是四字节可变长编码。而GBK则是双字节编码。至于上面说的94限制,在这里使用了双字节第一个字节最高位为1,第二个字节最高位无限制的表示方式,打开了一倍的存储区域,这样是不影响存储的,同时提高了空间的利用率。具体还请参考GB2312,GBK,GB18030 这几种字符集的主要区别 。
三、UNICODE万国码
UNICODE码,又叫万国码,统一码,单一码。看名字就知道,他统一了全世界的所有文字编码,是由UNICODE组织创造的。计算机网络飞速发展,为了解决不同区域不同国家的文字存储于显示问题,万国码应运而生。但其实UNICODE只是规定了各个文字的编码,并没有规定编码的存储方式,这有点像上面说的区位码。而且UNICODE中有很多编码是系统保留的,如0XFF,也是会出现在UNICODE中的。这在存储中是会出现很多问题的,比如说很多文字处理系统,都把0xFF作为结束标志。所以直接使用UNICODE进行编码是不可以的。于是就有了一系列的实现方案,即UTF系列编码。
UTF系列包括UTF-8,UTF-16,UTF-32。UTF-8是四字节可变长字符编码,编码方案为:首字节的前N位为1,N为该字符编码占用的字节数,且在最后一个1后面跟一个0,其余每个字节的前两位均为10,而剩下的位则用于实现UNICODE。即:
|
Unicode编码(十六进制)
|
UTF-8 字节流(二进制)
|
|
000000 - 00007F
|
0xxxxxxx
|
|
000080 - 0007FF
|
110xxxxx 10xxxxxx
|
|
000800 - 00FFFF
|
1110xxxx 10xxxxxx 10xxxxxx
|
|
010000 - 10FFFF
|
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
|
UTF-16为双字节表示,UTF-32则为四字节,他们均有大头与小头的区别,BOM(Byte Order Mark)标记如下:
|
UTF编码
|
Byte Order Mark (BOM)
|
| UTF-8 without BOM | 无 |
|
UTF-8 with BOM
|
EF BB BF
|
|
UTF-16LE
|
FF FE
|
|
UTF-16BE
|
FE FF
|
|
UTF-32LE
|
FF FE 00 00
|
|
UTF-32BE
|
00 00 FE FF
|
具体实现方案参考百度百科。
但是这就有点奇怪了,我们在保存文本时,可以看到有UNICODE选项,那么这个UNICODE是上面哪一种呢?其实都不是,他一般是指UCS-2(其实不太准确,因为UCS-2是UTF-16的子集,其实这里可以说UNICODE是UTF-16),什么是UCS-2呢?接着往下看。
四、UCS系列编码
UCS即Universal Multiple-Octet Coded Character Set,统一字符编码,是和UNICODE类似的一个编码方案,或者可以说是完全一样?至于为什么呢,是因为UCS与UNICODE是两个不同组织创造的,UCS是由ISO(世界标注化)组织创造的。但是在一段时间后,双方都意识到世界上不需要两个完全不兼容但是功能又一样的编码,于是他们就达成了共识。他有UCS-2,UCS-4两种实现方案。UCS-2使用两个字节表示字符,通常我们在保存文件是时选择保存为UNICODE其实就是保存为UCS-2编码。UCS-4使用四个字节保存一个字符。由于双方编码已达成共识,所以UCS-2可以看作是UTF-16的子集。UCS-4即为UTF-32的子集。
当前,Unicode深入人心,且UTF-8大行其道,UCS编码基本被等同于UTF-16,UTF-32了,所以目前UCS基本淡出人们的视野了。(Windows NT用的就是UCS-2)
五、其他编码
我们常见的还有一个叫做ANSI的编码。这个其实只是一个代码页指针,表示当前系统使用何种编码,在中文系统中,该指针指向的是GB18030。上面这些编码是我们经常接触到的,还有些不常用的,如BIG5码,繁体中文码。UTF-7,多用于邮件传输,等等。
那么这么多种字符集之间的兼容性又如何呢?
几乎所有编码均兼容ASCII码,GB系列编码高的兼容低的。UTF系列互不兼容。GB与UTF互不兼容。BIG5与其他互不兼容。其余的再总结,暂时只想到了这么多。
六、补充知识
关于URL编码:表单提交的内容,是按照ContentType中Charset设置的字符集进行转换的(不是在网页中mete中的ContentType。),控制字符直接转换为%ASCII码,数字英文则直接以数字英文的方式传输。对于中文或者其他文字来说,则是先转换为十进制的字符编码(字符编码为设置的字符集),转换后的形式为&#XXXXX;,然后再对转换后的编码进行URL编码,即转换为%ASCII码形式,发送给客户端。这是对于使用URL进行提交内容即GET方式的编码。
例如:%26%2321834%3B%26%2321834%3B%26%2321834%3B%26%2321834%3B,使用URL解码后为:啊啊啊啊即啊的UTF-8十进制编码。这是在Charset设置为ISO-8859-1情况下的编码。如果把Charset设置为UTF-8,则会变为:%E5%95%8A%E5%95%8A%E5%95%8A%E5%95%8A,这是各个字符对应的UTF-8编码。
经测试:,这样设置后,是不会对URL进行UTF-8编码的。
七、更多内容
更多关于编码的实现方法与历史,请参考对应的wiki百科。下面有几篇博文,对我帮助很大:
Ansi,UTF8,Unicode,ASCII编码的区别
字符编码笔记:ASCII,Unicode和UTF-8
中文编码转换---6种编码30个方向的转换
URL编码与解码