编译原理——词法分析器的C语言实现
前言
编译原理词法分析器的实验作业,现记录如下:
一、实验目的
通过设计编制调试一个具体的词法分析程序,加深对词法分析原理的理解。并掌握在对程序设计语言源程序进行扫描过程中将其分解为各类单词的词法分析方法。
编制一个读单词过程,从输入的源程序中,识别出各个具有独立意义的单词, 即关键字、标识符、常数、算符、界符五大类。并依次输出各个单词的内部编码及单词符号自身价值。(遇到错误时可显示“Error”,然后跳过错误部分继续显示)
二、实验内容
给定一个C语言的子集 ,如下:
关键字(小写)
main if else int return void while
算符或界符:
= + - * / < <= > >= = = != ; : , { } [ ] ( )
标识符是字母开头,后面字母和数字组合
数值指无符号常数
空格一般用来分隔标识符、数值、专用符号和关键字
三、实验要求
1. 请给出自己单词符号的种别码表
2. 给出标识符ID和数值NUM的正规式定义
3. 给出该语言的子集对应的状态转换图
4. 词法分析器的功能
输入:所给文法的源程序
输出:二元组(token 或sum ,syn)构成的序列。其中
syn 为单词种别码
token 为存放单词自身字符串
sum 为整型常数
5. 给出总体及各主要程序段的算法流程
把源程序放入一个数组中,用token数组取词;
进行匹配查找,和错误处理,最后输出。
6. 给出程序使用说明、程序运行示例
给出完整可执行程序的程序代码(有关键变量及关键语句的注释)
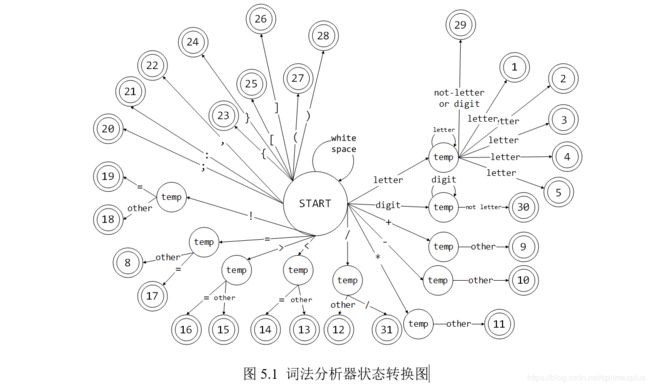
四、状态转换图的设计
-
词法单元形式
由于程序中的关键字可进行有限的枚举,而类似于变量名和数值则是无限的、不可全部枚举的,因此将词法分析中的token设计为二元组的形式。其中种别码相当于一个“外层编码”,若当前二元组存储的是唯一的关键字,则只使用种别码来标识(后文中简称“一词一码”)。若当前二元组存储的是不可完全枚举的标识符、数值等,则需使用种别码来标识当前处理的串的种类,同时使用属性值来标识当前串是哪一种类中的具体类型,也就是说多个词对应一个种别码(后文中简称“多次一码”)。
根据上面的分析,二元组token设置为:<种别码,属性值> -
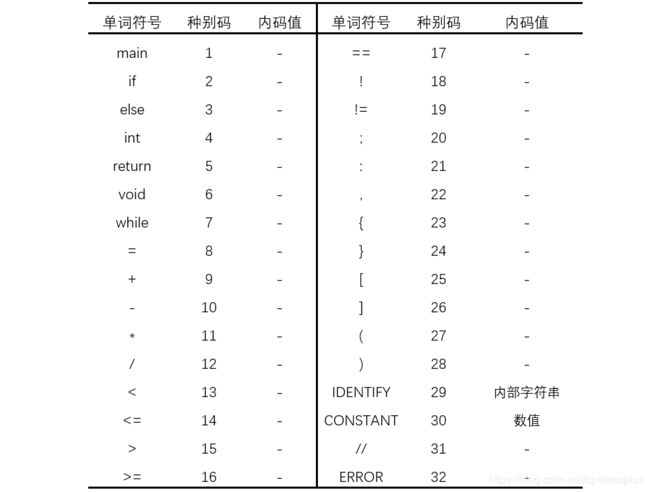
单词符号与其种别码及内码值
想要编写一个词法分析器,首先需要画出词法的状态转换图,根据状态转换图即可设计相应的程序来分析词法。而状态转化图的设计还需要给定单词符号以及其所对应的种别码及内码值。
由于关键字在程序中的存在是唯一且可枚举,因此这里采用“一词一码”的形式来赋给关键字种别码。由于标识符、数值是不可完全枚举的,因此采用“多次一码”的形式赋给具体的种别码及内码值。
根据实验要求,我将每个单词符号顺序赋值种别码以及内码,同时考虑到叹号 “!” 在C语言中代表“非”的意思,而给出的关键字中含有 “!=” 却没有 “!”,因此为合理起见,我在代码中加入了算符 “!”。
同样,我将注释符 “//” 也纳入token设计表中。
 状态转换图
状态转换图
五、分析(跳过)
六、代码实现
/*
*author: cuiyanran
*date: 2020-4-26 15:08
*version: 1.0
*IDE: Dev-C++
*/
#include