基于seq2seq的中文聊天机器人(一)
系列文章
1.基于seq2seq的中文聊天机器人(一)
2.基于seq2seq的中文聊天机器人(二)
3.基于seq2seq的中文聊天机器人(三)
1 背景介绍
聊天机器人的研究可以追溯到上个世纪五十年代,阿兰图灵提出了一个图灵测试来回答“机器能思考吗”的问题,随后掀起了人工智能研究的热潮。聊天机器人可应用于多个人机交互场景,比如问答系统、谈判、电子商务、辅导等。最近,随着移动终端数量的急剧增加,它也可以用于手机终端的虚拟助理,如Apple的Siri、微软的Cortana、Facebook的Messenger,Google助手等,让用户更容易地从终端上获取信息和服务。
当前主流的聊天机器人的设计目标主要集中在四个方面:
(1) 闲聊,即回答问候、情感和娱乐等信息;
(2) 指令执行,帮助用户完成特定的任务,包括酒店及餐厅预订、机票查询、旅行向导、网络搜索等;
(3) 问答,满足用户对知识和信息获取的需求;
(4) 推荐,通过分析用户兴趣和会话历史,推荐个性化内容。
我们做的是一款基于Seq2Seq的单轮对话中文聊天机器人。
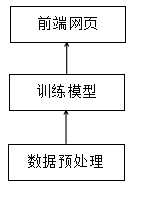
2 系统设计思路和框架
本次系统全部使用 Python 编写,在系统设计上遵循着配置灵活、代码模块化的思路,分为数据预处理器、训练模型、可视化展示3个模块。
模块间的逻辑关系大致为:
1)数据预处理是将原始语料进行初步的处理以满足于数据处理模块的要求;
3)训练模型是一个基于 TF 的 seq2seq 模型,用于定义神经网络并进行模型计算;
3)可视化展示是一个用前端框架写的简单的人机交互程序,在运行时调用API进行人机对话。
整体的框架图如下:
3 数据预处理
3.1语料库
语料通常指在统计自然语言处理中实际上不可能观测到大规模的语言实例。所以人们简单地用文本作为替代,并把文本中的上下文关系作为现实世界中语言的上下文关系的替代品。语料库一词在语言学上意指大量的文本,通常经过整理,具有既定格式与标记。其具备三个显著的特点:
语料库中存放的是在语言的实际使用中真实出现过的语言材料。
语料库以电子计算机为载体承载语言知识的基础资源,但不等于语言知识。
真实语料需要经过加工(分析和处理),才能成为有用的资源。
语料库的内容和质量决定了模型最后可以达到的天花板,语料集的清洗也是非常重要的,直接决定了模型的效果,甚至会影响模型的收敛,答非所问,语法错误等,因此语料的选择处理非常重要。
我们这是一个对话机器人项目,所以选择的语料主要是一些QA对,开放数据也很多可以下载,存放的格式是第一行为问题,第二行为回答,第三行又是问题,第四行为回答,以此类推。考虑语料数量和质量,我们选择小黄鸡50w分词语料库。
3.2语料预处理
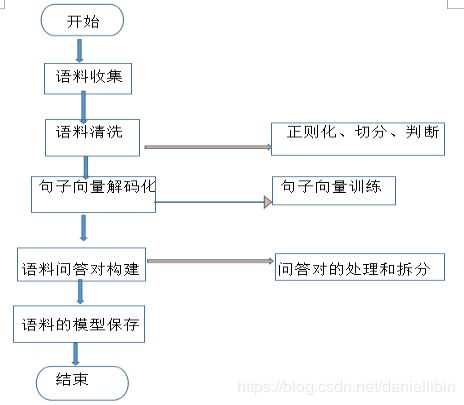
语料处理的主要流程如上图所示,在我们从网上获取到合适的语料库后开始对原始的语料库进行加工处理来满足模型训练的要求,提高训练效果。

(1)语料清洗
数据清洗,顾名思义就是在语料中找到我们感兴趣的东西,把不感兴趣的、视为噪音的内容清洗删除,包括对于原始文本提取标题、摘要、正文等信息,对于爬取的网页内容,去除标签、HTML、JS 等代码和注释等。常见的数据清洗方式有:人工去重、对齐、删除和标注等,或者规则提取内容、正则表达式匹配、根据词性和命名实体提取、编写脚本或者代码批处理等。由于语料本身实现大部分清洗功能,所以我们只需要在进行分词,去除停用词等处理,原始的语料内容如下所示。
(2)分词
中文语料数据为一批短文本或者长文本,比如:句子,文章摘要,段落或者整篇文章组成的一个集合。一般句子、段落之间的字、词语是连续的,有一定含义。而进行文本挖掘分析时,我们希望文本处理的最小单位粒度是词或者词语,所以这个时候就需要分词来将文本全部进行分词。
通过结巴分词库,我们最终的分词效果如下:

由于本文所用的语料时已经分词后的语料,所以我们的项目从第三步开始。
(3)句子规范化

其实这一部分是进一步的数据清洗过滤,将句子规范化,主要处理的内容是分词后的空格,较长的符号以及特殊字符,主要的处理方式包括正则表达式,遍历判断等。其中主要的处理正则表达式的处理包括:
取出分词处理后的语料;
将斜杠\过滤;
将较多的…,···,/.统统用…代替;
将较多的。,/。统统用。代替;
将较多的!,?分用!,?代替;
将非中英文的字符以及"。,?!~·过滤;
将ˇˊˋˍεπのゞェーω字符过滤,_regular_函数相关代码如下:
def _regular_(self, sen):
"""
句子规范化,主要是对原始语料的句子进行一些标点符号的统一
:param sen:
:return:
"""
sen = sen.replace('/', '')
sen = re.sub(r'…{1,100}', '…', sen)
sen = re.sub(r'\.{3,100}', '…', sen)
sen = re.sub(r'···{2,100}', '…', sen)
sen = re.sub(r',{1,100}', ',', sen)
sen = re.sub(r'\.{1,100}', '。', sen)
sen = re.sub(r'。{1,100}', '。', sen)
sen = re.sub(r'\?{1,100}', '?', sen)
sen = re.sub(r'?{1,100}', '?', sen)
sen = re.sub(r'!{1,100}', '!', sen)
sen = re.sub(r'!{1,100}', '!', sen)
sen = re.sub(r'~{1,100}', '~', sen)
sen = re.sub(r'~{1,100}', '~', sen)
sen = re.sub(r'[“”]{1,100}', '"', sen)
sen = re.sub('[^\w\u4e00-\u9fff"。,?!~·]+', '', sen)
sen = re.sub(r'[ˇˊˋˍεπのゞェーω]', '', sen)
返回过滤后的字符串,使用pickle保存成序列文件。
在对语料完成预处理后,在使用前还需要进行判断是否是一个好的语料,比如是否是属于汉字和数字。
def _good_line_(self, line):
"""
判断一句话是否是好的语料,即判断
:param line:
:return:
"""
if len(line) == 0:
return False
ch_count = 0
for c in line:
# 中文字符范围
if '\u4e00' <= c <= '\u9fff':
ch_count += 1
if ch_count / float(len(line)) >= 0.8 and len(re.findall(r'[a-zA-Z0-9]', ''.join(line))) < 3 \
and len(re.findall(r'[ˇˊˋˍεπのゞェーω]', ''.join(line))) < 3:
return True
return False
除此之外,还要判断QA对的长度是否符合min_q_len,max_q_len,min_a_len,max_a_len的设置,防止过长或过短短对话。
# 根据CONFIG文件中配置的最大值和最小值问答对长度来进行数据过滤
data = [x for x in data if self.min_q_len <= len(x[0]) <= self.max_a_len and self.min_a_len <= len(x[1]) <= self.max_a_len]
3.3 Word2index
(1)词表和索引生成
做完语料预处理之后,接下来需要考虑如何把分词之后的字和词语表示成计算机能够计算的类型。显然,如果要计算我们至少需要把中文分词的字符串转换成数字,确切的说应该是数学中的向量。所以我们需要将每个词进行数字化,这里选择建立索引的方式。以词表为基础建立索引库,根据用户提问中的关键词迅速找到包含特定关键词的段落。
用0到n的值来表示整个词汇,每个值表示一个单词,这里用VOCAB_SIZE来定义。还有问题的最大最小长度,回答的最大最小长度。除此之外还要定义UNK、SOS、EOS和PAD符号,分别表示未知单词,比如你超过 VOCAB_SIZE范围的则认为未知单词,GO表示decoder开始的符号,EOS表示回答结束的符号,而PAD用于填充,因为所有QA对放到同个seq2seq模型中输入和输出都必须是相同的,于是就需要将较短长度的问题或回答用PAD进行填充。
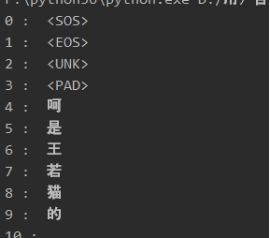
还要得到整个语料库所有单词的频率统计,还要根据频率大小统计出排名前n个频率的单词作为整个词汇,也就是前面对应的VOCAB_SIZE。另外我们还需要根据索引值得到单词的索引,还有根据单词得到对应索引值的索引。_fit_word_函数相关代码如图所示:
def _fit_word_(self, vocabularies):
"""
将词表中所有的词转化为索引,过滤掉出现次数少于4次的词
:param vocabularies:词表
:return:
"""
vocab_counter = collections.Counter(vocabularies)
index2word = [self.START] + [self.END] + [self.UNK] + [self.PAD] + [x[0] for x in vocab_counter if vocab_counter.get(x[0]) > 4]
self.word2index = dict([(w, i) for i, w in enumerate(index2word)]) #i代表顺序,作为索引
self.index2word =dict([(i, w) for i, w in enumerate(index2word)])
建立索引的效果如下:
在得到word2index和index2word,还要讲这些索引文件持久化保存起来,即w2i.pkl文件,以便直接拿来进行使用,代码如下:
ef _fit_data_(self):
"""
得到处理后语料库的所有词,并将其编码为索引值
:return:
"""
if not os.path.exists(self.word2index_path):
vocabularies = [x[0] + x[1] for x in self.data] #x[0]为question,x[1]为answer
self._fit_word_(itertools.chain(*vocabularies))
with open(self.word2index_path, 'wb') as fw:
pickle.dump(self.word2index, fw)
else:
with open(self.word2index_path, 'rb') as fr:
self.word2index = pickle.load(fr)
self.index2word = dict([(v,k) for k,v in self.word2index.items()]) # k为索引,v 为值
self.vocab_size = len(self.word2index)
(2)索引过程
信息检索技术的基础是对原始文档预处理后,将基本元素的位置信息记录在索引表中。通常以词表为基础建立索引库。信息索引就是创建文档的特征记录,通常以倒排表的方式建立。对文档进行预处理并建立信息索引是由系统预处理模块事先进行的。
用户提问时,将依据系统抽取的关键词从索引表中找出满足条件的所有段落取交集返回。由于索引结构常驻内存,因而检索速度快,而且一旦定位到段落,就可以作进一步的语义分析和处理。
信息索引建立完后,检索的过程就是对相关段落按权重大小排序后依次输出,段落权重的计算方法为:
首先,由词性为问题处理模块输出的关键词(包括其扩展)设置权重;
其次,根据类似工DF的定义为各关键词分配权重;
最后,依据权重的大小对检索出来的段落进行排序,依次送给答案抽取模块。
3.4 生成batch的训练数据
随机取出一个batch_size的预训练语料;
对语料中的问句和答句中的词转化为索引;
对不一样长的问句和答句进行pad填充;
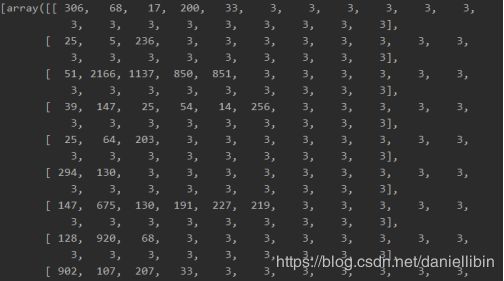
将每个对话索引转化为数组返回,返回格式如图所示。next_batch函数具体代码如下所示:
def next_batch(self, batch_size):
"""
生成一批训练数据
:param batch_size: 每一批数据的样本数
:return: 经过了填充处理的QA对
"""
data_batch = random.sample(self.data, batch_size)
batch = []
for qa in data_batch:
encoded_q = self.transform_sentence(qa[0]) #将句子转化为索引
encoded_a = self.transform_sentence(qa[1])
q_len = len(encoded_q)
# 填充句子
encoded_q = encoded_q + [self.func_word2index(self.PAD)] * (self.max_q_len - q_len)
encoded_a = encoded_a + [self.func_word2index(self.END)]
a_len = len(encoded_a)
encoded_a = encoded_a + [self.func_word2index(self.PAD)] * (self.max_a_len + 1 - a_len)
batch.append((encoded_q, q_len, encoded_a, a_len))
batch = zip(*batch)
batch = [np.asarray(x) for x in batch]
return batch
返回效果如图所示:
3.5 其他注意事项
(1)4种特殊标签
(2)Encoder-Decoder端的涉及的输入输出
对于encoder来说,问题的长短是不同的,那么不够长的要用PAD进行填充,比如问题为”how are you”,假如长度定为10,则需要将其填充为”how are you pad pad pad pad pad pad pad”。对于decoder来说,要以GO开始,以EOS结尾,不够长还得填充,比如”fine thank you”,则要处理成”go fine thank you eos pad pad pad pad pad “。第三个要处理的则是我们的target,target其实和decoder的输入是相同的,只不过它刚好有一个位置的偏移,比如上面要去掉go,变成”fine thank you eos pad pad pad pad pad pad”。