基于seq2seq的中文聊天机器人(二)
系列文章
1.基于seq2seq的中文聊天机器人(一)
2.基于seq2seq的中文聊天机器人(二)
3.基于seq2seq的中文聊天机器人(三)
4 Seq2Seq训练模型
4.1Seq2Seq模型简介
Seq2Seq模型是输出的长度不确定时采用的模型,这种情况一般是在机器翻译的任务中出现,将一句中文翻译成英文,那么这句英文的长度有可能会比中文短,也有可能会比中文长,所以输出的长度就不确定了。如下图所,输入的中文长度为4,输出的英文长度为2。
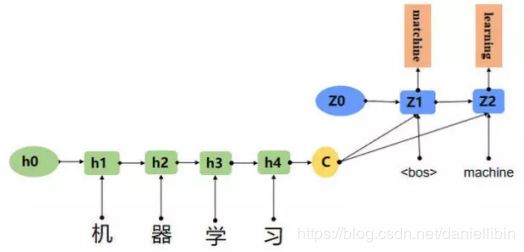
在网络结构中,输入一个中文序列,然后输出它对应的中文翻译,输出的部分的结果预测后面,根据上面的例子,也就是先输出“machine”,将"machine"作为下一次的输入,接着输出"learning",这样就能输出任意长的序列。
机器翻译、人机对话、聊天机器人等等,这些都是应用在当今社会都或多或少的运用到了我们这里所说的Seq2Seq。
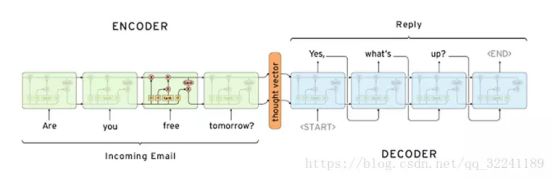
举个简单的例子,当我们使用机器翻译时:输入(Hello) —>输出(你好)。再比如在人机对话中,我们问机器:“你是谁?”,机器会返回答案“我是某某某”。如下图所示为一个简单的邮件对话的场景,发送方问:“你明天是否有空”;接收方回答:“有空,怎么了?”。
4.2Seq2Seq结构
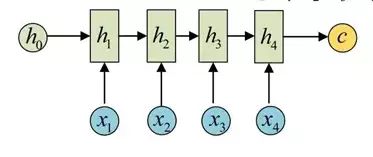
seq2seq属于encoder-decoder结构的一种,这里看看常见的encoder-decoder结构,基本思想就是利用两个RNN,一个RNN作为encoder,另一个RNN作为decoder。encoder负责将输入序列压缩成指定长度的向量,这个向量就可以看成是这个序列的语义,这个过程称为编码,如下图,获取语义向量最简单的方式就是直接将最后一个输入的隐状态作为语义向量C。也可以对最后一个隐含状态做一个变换得到语义向量,还可以将输入序列的所有隐含状态做一个变换得到语义变量。
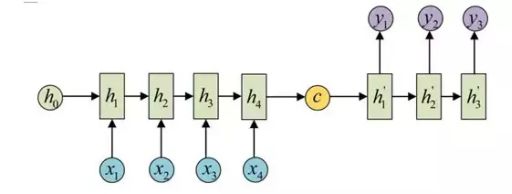
而decoder则负责根据语义向量生成指定的序列,这个过程也称为解码,如下图,最简单的方式是将encoder得到的语义变量作为初始状态输入到decoder的RNN中,得到输出序列。可以看到上一时刻的输出会作为当前时刻的输入,而且其中语义向量C只作为初始状态参与运算,后面的运算都与语义向量C无关。
decoder处理方式还有另外一种,就是语义向量C参与了序列所有时刻的运算,如下图,上一时刻的输出仍然作为当前时刻的输入,但语义向量C会参与所有时刻的运算。
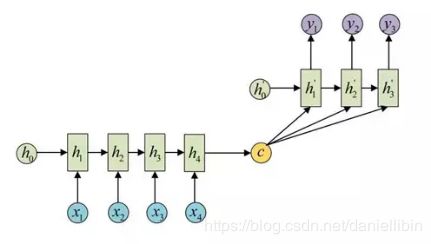
4.3如何训练Seq2Seq模型
RNN是可以学习概率分布,然后进行预测,比如我们输入t时刻的数据后,预测t+1时刻的数据,比较常见的是字符预测例子或者时间序列预测。为了得到概率分布,一般会在RNN的输出层使用softmax激活函数,就可以得到每个分类的概率。
Softmax 在机器学习和深度学习中有着非常广泛的应用。尤其在处理多分类(C > 2)问题,分类器最后的输出单元需要Softmax 函数进行数值处理。关于Softmax 函数的定义如下所示:
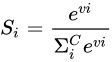
其中,Vi是分类器前级输出单元的输出。i 表示类别索引,总的类别个数为C,表示的是当前元素的指数与所有元素指数和的比值。Softmax 将连续数值转化成相对概率,更有利于我们理解。
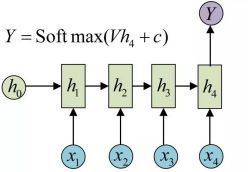
对于RNN,对于某个序列,对于时刻t,它的词向量输出概率为
![]()
则softmax层每个神经元的计算如下:
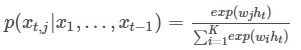
其中ht是隐含状态,它与上一时刻的状态及当前输入有关,即ht=f(ht−1,xt)。
那么整个序列的概率就为
![]()
而对于encoder-decoder模型,设有输入序列x1,xT,输出序列y1,yT,输入序列和输出序列的长度可能不同。那么其实就是要根据输入序列去得到输出序列的可能,于是有下面的条件概率,x1,xT发生的情况下y1,yT发生的概率等于p(yt|v,y1,…yt-1)连乘。其中v表示x1,xT对应的隐含状态向量,它其实可以等同表示输入序列。
![]()
此时,
![]()
decoder的隐含状态与上一时刻状态、上一时刻输出和状态向量v都有关,这里不同于RNN,RNN是与当前时刻输入相关,而decoder是将上一时刻的输出输入到RNN中。于是decoder的某一时刻的概率分布可用下式表示,
![]()
所以对于训练样本,我们要做的就是在整个训练样本下,所有样本的
![]()
概率之和最大,对应的对数似然条件概率函数为
![]()
,使之最大化,θ则是待确定的模型参数。
4.4源码讲解
(1)参数配置
模型保存目录
BASE_MODEL_DIR = ‘model’
模型名称
MODEL_NAME = ‘chatbot_model.ckpt’
#训练轮数
n_epoch = 200
#batch样本数
batch_size = 256
#训练时dropout的保留比例
keep_prob = 0.8
#有关语料数据的配置
data_config = {
# 问题最短的长度
"min_q_len": 1,
# 问题最长的长度
"max_q_len": 20,
# 答案最短的长度
"min_a_len": 2,
# 答案最长的长度
"max_a_len": 20,
# 词与索引对应的文件
"word2index_path": "data/w2i.pkl",
# 原始语料路径
"path": "data/xiaohuangji50w_fenciA.conv",
# 原始语料经过预处理之后的保存路径
"processed_path": "data/data.pkl",
}
#有关模型相关参数的配置
model_config = {
# rnn神经元单元的状态数
"hidden_size": 256,
# rnn神经元单元类型,可以为lstm或gru
"cell_type": "lstm",
# 编码器和解码器的层数
"layer_size": 4,
# 词嵌入的维度
"embedding_dim": 300,
# 编码器和解码器是否共用词嵌入
"share_embedding": True,
# 解码允许的最大步数
"max_decode_step": 80,
# 梯度裁剪的阈值
"max_gradient_norm": 3.0,
# 学习率初始值
"learning_rate": 0.001,
"decay_step": 100000,
# 学习率允许的最小值
"min_learning_rate":1e-6,
# 编码器是否使用双向rnn
"bidirection":True,
# BeamSearch时的宽度
"beam_width":200
}
(2)模型训练
import DataProcessing
import os
import tensorflow as tf
from SequenceToSequence import Seq2Seq
from tqdm import tqdm
import numpy as np
from CONFIG import BASE_MODEL_DIR, MODEL_NAME, data_config, model_config, \
n_epoch, batch_size, keep_prob
#是否在原有模型的基础上继续训练
continue_train = True
def train():
"""
训练模型
:return:
"""
du = DataProcessing.DataUnit(**data_config)
save_path = os.path.join(BASE_MODEL_DIR, MODEL_NAME)
steps = int(len(du) / batch_size) + 1
# 创建session的时候设置显存根据需要动态申请
tf.reset_default_graph()
config = tf.ConfigProto()
# config.gpu_options.per_process_gpu_memory_fraction = 0.9
config.gpu_options.allow_growth = True
with tf.Graph().as_default():
with tf.Session(config=config) as sess:
# 定义模型
model = Seq2Seq(batch_size=batch_size,
encoder_vocab_size=du.vocab_size,
decoder_vocab_size=du.vocab_size,
mode='train',
**model_config)
init = tf.global_variables_initializer()
writer=tf.summary.FileWriter('./graph/nlp',sess.graph)
sess.run(init)
if continue_train:
model.load(sess, save_path)
for epoch in range(1, n_epoch + 1):
costs = []
bar = tqdm(range(steps), total=steps,
desc='epoch {}, loss=0.000000'.format(epoch)) #进度条
for _ in bar:
x, xl, y, yl = du.next_batch(batch_size)
max_len = np.max(yl) #最长句子的长度
y = y[:, 0:max_len]
cost, lr = model.train(sess, x, xl, y, yl, keep_prob)
costs.append(cost)
bar.set_description('epoch {} loss={:.6f} lr={:.6f}'.format(epoch, np.mean(costs), lr))
model.save(sess, save_path=save_path)
if __name__ == '__main__':
train()
(3)Seq2Seq模型
- 初始化
class Seq2Seq(object):
def __init__(self, hidden_size, cell_type,
layer_size, batch_size,
encoder_vocab_size, decoder_vocab_size,
embedding_dim, share_embedding,
max_decode_step, max_gradient_norm,
learning_rate, decay_step,
min_learning_rate, bidirection,
beam_width,
mode
):
"""
初始化函数
"""
self.hidden_size = hidden_size
self.cell_type = cell_type
self.layer_size = layer_size
self.batch_size = batch_size
self.encoder_vocab_size = encoder_vocab_size
self.decoder_vocab_size = decoder_vocab_size
self.embedding_dim = embedding_dim
self.share_embedding = share_embedding
self.max_decode_step = max_decode_step
self.max_gradient_norm = max_gradient_norm
self.learning_rate = learning_rate
self.decay_step = decay_step
self.min_learning_rate = min_learning_rate
self.bidirection = bidirection
self.beam_width = beam_width
self.mode = mode
self.global_step = tf.Variable(0, trainable=False, name='global_step')
self.build_model()
def build_model(self):
"""
构建完整的模型
:return:
"""
self.init_placeholder()
self.embedding()
encoder_outputs, encoder_state = self.build_encoder()
self.build_decoder(encoder_outputs, encoder_state)
if self.mode == 'train':
self.build_optimizer()
self.saver = tf.train.Saver()
def init_placeholder(self):
"""
定义各个place_holder
:return:
"""
self.encoder_inputs = tf.placeholder(tf.int32, shape=[self.batch_size, None], name='encoder_inputs')
self.encoder_inputs_length = tf.placeholder(tf.int32, shape=[self.batch_size, ], name='encoder_inputs_length')
self.keep_prob = tf.placeholder(tf.float32, shape=(), name='keep_prob')
if self.mode == 'train':
self.decoder_inputs = tf.placeholder(tf.int32, shape=[self.batch_size, None], name='decoder_inputs')
self.decoder_inputs_length = tf.placeholder(tf.int32, shape=[self.batch_size, ],
name='decoder_inputs_length')
self.decoder_start_token = tf.ones(shape=(self.batch_size, 1), dtype=tf.int32) * DataUnit.START_INDEX
self.decoder_inputs_train = tf.concat([self.decoder_start_token, self.decoder_inputs], axis=1)
def embedding(self):
"""
词嵌入操作
:param share:编码器和解码器是否共用embedding
:return:
"""
with tf.variable_scope('embedding'):
encoder_embedding = tf.Variable(
tf.truncated_normal(shape=[self.encoder_vocab_size, self.embedding_dim], stddev=0.1), # tf.truncated_normal从截断的正态分布中输出随机值
name='encoder_embeddings')
if not self.share_embedding:
decoder_embedding = tf.Variable(
tf.truncated_normal(shape=[self.decoder_vocab_size, self.embedding_dim], stddev=0.1),
name='decoder_embeddings')
self.encoder_embeddings = encoder_embedding
self.decoder_embeddings = decoder_embedding
else:
self.encoder_embeddings = encoder_embedding
self.decoder_embeddings = encoder_embedding
def check_feeds(self, encoder_inputs, encoder_inputs_length,
decoder_inputs, decoder_inputs_length, keep_prob, decode):
"""
检查输入,返回输入字典
"""
input_batch_size = encoder_inputs.shape[0]
assert input_batch_size == encoder_inputs_length.shape[0], 'encoder_inputs 和 encoder_inputs_length的第一个维度必须一致'
if not decode:
target_batch_size = decoder_inputs.shape[0]
assert target_batch_size == input_batch_size, 'encoder_inputs 和 decoder_inputs的第一个维度必须一致'
assert target_batch_size == decoder_inputs_length.shape[
0], 'decoder_inputs 和 decoder_inputs_length的第一个维度必须一致'
input_feed = {self.encoder_inputs.name: encoder_inputs,
self.encoder_inputs_length.name: encoder_inputs_length}
input_feed[self.keep_prob.name] = keep_prob
if not decode:
input_feed[self.decoder_inputs.name] = decoder_inputs
input_feed[self.decoder_inputs_length.name] = decoder_inputs_length
return input_feed
def save(self, sess, save_path='model/chatbot_model.ckpt'):
"""
保存模型
:return:
"""
self.saver.save(sess, save_path=save_path)
def load(self, sess, save_path='model/chatbot_model.ckpt'):
"""
加载模型
"""
self.saver.restore(sess, save_path)
- 编码器
def one_cell(self, hidden_size, cell_type):
"""
一个神经元
:return:
"""
if cell_type == 'gru':
c = GRUCell
else:
c = LSTMCell
cell = c(hidden_size)
cell = DropoutWrapper(
cell,
dtype=tf.float32,
output_keep_prob=self.keep_prob,
)
cell = ResidualWrapper(cell)
return cell
def build_encoder_cell(self, hidden_size, cell_type, layer_size):
"""
构建编码器所有层
:param hidden_size:
:param cell_type:
:param layer_size:
:return:
"""
cells = [self.one_cell(hidden_size, cell_type) for _ in range(layer_size)]
return MultiRNNCell(cells)
def build_encoder(self):
"""
构建完整编码器
:return:
"""
with tf.variable_scope('encoder'):
encoder_cell = self.build_encoder_cell(self.hidden_size, self.cell_type, self.layer_size)
encoder_inputs_embedded = tf.nn.embedding_lookup(self.encoder_embeddings, self.encoder_inputs) #tf.nn.embedding_lookup(params, ids)函数的用法主要是选取一个张量里面索引对应的元素;params可以是张量也可以是数组等,id就是对应的索引。
encoder_inputs_embedded = layers.dense(encoder_inputs_embedded, # 全连接层 相当于添加一个层
self.hidden_size,
use_bias=False,
name='encoder_residual_projection')
initial_state = encoder_cell.zero_state(self.batch_size, dtype=tf.float32) # 初始化值
if self.bidirection: # 双向RNN
encoder_cell_bw = self.build_encoder_cell(self.hidden_size, self.cell_type, self.layer_size)
(
(encoder_fw_outputs, encoder_bw_outputs),
(encoder_fw_state, encoder_bw_state)
) = tf.nn.bidirectional_dynamic_rnn(
cell_bw=encoder_cell_bw,
cell_fw=encoder_cell,
inputs=encoder_inputs_embedded,
sequence_length=self.encoder_inputs_length,
dtype=tf.float32,
swap_memory=True)
encoder_outputs = tf.concat(
(encoder_bw_outputs, encoder_fw_outputs), 2) # 在第二个维度拼接
encoder_final_state = []
for i in range(self.layer_size):
c_fw, h_fw = encoder_fw_state[i]
c_bw, h_bw = encoder_bw_state[i]
c = tf.concat((c_fw, c_bw), axis=-1) # 在最高的维度进行拼接
h = tf.concat((h_fw, h_bw), axis=-1)
encoder_final_state.append(LSTMStateTuple(c=c, h=h))
encoder_final_state = tuple(encoder_final_state)
else:
encoder_outputs, encoder_final_state = tf.nn.dynamic_rnn(
cell=encoder_cell,
inputs=encoder_inputs_embedded,
sequence_length=self.encoder_inputs_length,
dtype=tf.float32,
initial_state=initial_state,
swap_memory=True)
return encoder_outputs, encoder_final_state
- 解码器
def build_decoder_cell(self, encoder_outputs, encoder_final_state,
hidden_size, cell_type, layer_size):
"""
构建解码器所有层
:param encoder_outputs:
:param encoder_state:
:param hidden_size:
:param cell_type:
:param layer_size:
:return:
"""
sequence_length = self.encoder_inputs_length
if self.mode == 'decode':
encoder_outputs = tf.contrib.seq2seq.tile_batch( # 将encoder_outputs内的每个样本复制self.beam_width次
encoder_outputs, multiplier=self.beam_width)
encoder_final_state = tf.contrib.seq2seq.tile_batch(
encoder_final_state, multiplier=self.beam_width)
sequence_length = tf.contrib.seq2seq.tile_batch(
sequence_length, multiplier=self.beam_width)
if self.bidirection: # 编码器是否使用双向rnn
cell = MultiRNNCell([self.one_cell(hidden_size * 2, cell_type) for _ in range(layer_size)])
else:
cell = MultiRNNCell([self.one_cell(hidden_size, cell_type) for _ in range(layer_size)])
# 使用attention机制
self.attention_mechanism = BahdanauAttention(
num_units=self.hidden_size,
memory=encoder_outputs,
memory_sequence_length=sequence_length
)
def cell_input_fn(inputs, attention):
mul = 2 if self.bidirection else 1
attn_projection = layers.Dense(self.hidden_size * mul,
dtype=tf.float32,
use_bias=False,
name='attention_cell_input_fn')
return attn_projection(array_ops.concat([inputs, attention], -1))
cell = AttentionWrapper(
cell=cell,
attention_mechanism=self.attention_mechanism,
attention_layer_size=self.hidden_size,
cell_input_fn=cell_input_fn,
name='Attention_Wrapper'
)
if self.mode == 'decode':
decoder_initial_state = cell.zero_state(batch_size=self.batch_size * self.beam_width,
dtype=tf.float32).clone(
cell_state=encoder_final_state)
else:
decoder_initial_state = cell.zero_state(batch_size=self.batch_size,
dtype=tf.float32).clone(
cell_state=encoder_final_state)
return cell, decoder_initial_state
def build_decoder(self, encoder_outputs, encoder_final_state):
"""
构建完整解码器
:return:
"""
with tf.variable_scope("decode"):
decoder_cell, decoder_initial_state = self.build_decoder_cell(encoder_outputs, encoder_final_state,
self.hidden_size, self.cell_type,
self.layer_size)
# 输出层投影
decoder_output_projection = layers.Dense(self.decoder_vocab_size, dtype=tf.float32,
use_bias=False,
kernel_initializer=tf.truncated_normal_initializer(mean=0.0,
stddev=0.1),
name='decoder_output_projection')
if self.mode == 'train':
# 训练模式
decoder_inputs_embdedded = tf.nn.embedding_lookup(self.decoder_embeddings, self.decoder_inputs_train)
training_helper = TrainingHelper(
inputs=decoder_inputs_embdedded,
sequence_length=self.decoder_inputs_length,
name='training_helper'
)
training_decoder = BasicDecoder(decoder_cell, training_helper,
decoder_initial_state, decoder_output_projection)
max_decoder_length = tf.reduce_max(self.decoder_inputs_length)
training_decoder_output, _, _ = tf.contrib.seq2seq.dynamic_decode(training_decoder,
maximum_iterations=max_decoder_length)
self.masks = tf.sequence_mask(self.decoder_inputs_length, maxlen=max_decoder_length, dtype=tf.float32,
name='masks')
self.loss = tf.contrib.seq2seq.sequence_loss(logits=training_decoder_output.rnn_output,
targets=self.decoder_inputs,
weights=self.masks,
average_across_timesteps=True,
average_across_batch=True
)
else:
# 预测模式
start_token = [DataUnit.START_INDEX] * self.batch_size
end_token = DataUnit.END_INDEX
inference_decoder = BeamSearchDecoder(
cell=decoder_cell,
embedding=lambda x: tf.nn.embedding_lookup(self.decoder_embeddings, x),
start_tokens=start_token,
end_token=end_token,
initial_state=decoder_initial_state,
beam_width=self.beam_width,
output_layer=decoder_output_projection
)
inference_decoder_output, _, _ = tf.contrib.seq2seq.dynamic_decode(inference_decoder,
maximum_iterations=self.max_decode_step)
self.decoder_pred_decode = inference_decoder_output.predicted_ids
self.decoder_pred_decode = tf.transpose(
self.decoder_pred_decode,
perm=[0, 2, 1]
)
- 优化器
def build_optimizer(self):
"""
构建优化器
:return:
"""
learning_rate = tf.train.polynomial_decay(self.learning_rate, self.global_step,
self.decay_step, self.min_learning_rate, power=0.5)
self.current_learning_rate = learning_rate
trainable_params = tf.trainable_variables()
gradients = tf.gradients(self.loss, trainable_params)
# 优化器
self.opt = tf.train.AdamOptimizer(
learning_rate=learning_rate
)
# 梯度裁剪
clip_gradients, _ = tf.clip_by_global_norm(
gradients, self.max_gradient_norm
)
# 更新梯度
self.update = self.opt.apply_gradients(
zip(clip_gradients, trainable_params),
global_step=self.global_step
)
- 训练
def train(self, sess, encoder_inputs, encoder_inputs_length,
decoder_inputs, decoder_inputs_length, keep_prob):
"""
训练模型
:param sess:
:return:
"""
input_feed = self.check_feeds(encoder_inputs, encoder_inputs_length,
decoder_inputs, decoder_inputs_length, keep_prob,
False)
output_feed = [
self.update, self.loss,
self.current_learning_rate
]
_, cost, lr = sess.run(output_feed, input_feed)
return cost, lr
- 预测
def predict(self, sess, encoder_inputs, encoder_inputs_length):
"""
预测
:return:
"""
input_feed = self.check_feeds(encoder_inputs, encoder_inputs_length,
None, None, 1, True)
pred = sess.run(self.decoder_pred_decode, input_feed)
return pred[0]
参考来源:
(1)Seq2Seq模型概述