【搜索那些事】细谈lucene(一)初识全文资源检索框架lucene
算算差不多有小半年没正儿八经的写博客了,从考完专升本考试就直接参加了工作,工作四个月之后又回来上本科,开学又在校内创办了CSDN高校俱乐部,制定学员学习方向,搞讲座,办公开课,反正一切事情很多。现在开学已经差不多一个月了吧,一切基本都走上了正轨,但发觉自己的未来发展之路却进入了一个迷茫期,专科阶段一直致力于web应用方面的学习,现在想提升一下自己的能力和平台,但一直找不到学习方向。还有一个问题是考研不考研的问题。所以一直很纠结。如果大家有什么好的建议,欢迎给予评论和建议。在迷茫中给自己选择了一个搜索和大数据方向,其实我对这个方向也没有很明确的见解,只是以前比较留意了一些。不知道这个方向是否适合自己,但我一直坚定,没有适合不适合,只有努力不努力。本“搜索那些事”系列博客主要以“lucene——》nutch——》hadoop”为路线,我不知道自己能不能坚持下来,也希望大家给予监督。
一:lucene历史和简介
Lucene 是apache软件基金会一个开放源代码的全文检索引擎工具包,是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。它不是一个完整的搜索应用程序,而是为你的应用程序提供索引和搜索功能。Lucene 目前是 Apache Jakarta 家族中的一个开源项目。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
Lucene最初是由Doug Cutting所撰写的,他是一位资深的全文索引及检索专家,曾经是V-Twin搜索引擎的主要开发者,后来在Excite担任高级系统架构设计师,目前从事于一些INTERNET底层架构的研究。他同时也是当前最火的大数据处理框架hadoop的创始人,其实,hadoop刚开始就是以Lucene的子项目Nutch的一部分正式引入的。我也打算在“搜索那些事”系列博客中可以从lucene——》nutch——hadoop的一点点的全部写出来。Doug Cutting贡献出Lucene的目标是为各种中小型应用程式加入全文检索功能。lucene 能够为文本类型的数据建立索引,所以你只要能把你要索引的数据格式转化的文本的,Lucene 就能对你的文档进行索引和搜索。比如你要对一些 HTML 文档,PDF 文档进行索引的话你就首先需要把 HTML 文档和 PDF 文档转化成文本格式的,然后将转化后的内容交给 Lucene 进行索引,然后把创建好的索引文件保存到磁盘或者内存中,最后根据用户输入的查询条件在索引文件上进行查询。不指定要索引的文档的格式也使 Lucene 能够几乎适用于所有的搜索应用程序。尽管当时lucene是由java编写的,不过由于它设计思想的先进和用于广泛,所以现在已有其他编程语言的版本(c/c++,c#,python等)。已经有很多Java项目都使用了Lucene作为其后台的全文索引引擎,比较著名的有:
- Jive:WEB论坛系统;
- Eyebrows:邮件列表HTML归档/浏览/查询系统,本文的主要参考文档“TheLucene search engine: Powerful, flexible, and free”作者就是EyeBrows系统的主要开发者之一,而EyeBrows已经成为目前APACHE项目的主要邮件列表归档系统。
- Cocoon:基于XML的web发布框架,全文检索部分使用了Lucene
- Eclipse:基于Java的开放开发平台,帮助部分的全文索引使用了Lucene
二:lucene特性简介
我们处在一个信息爆炸的时代,所以信息搜索对于当前社会发展是非常重要的。作为一个开放源代码项目,Lucene从问世之后,引发了开放源代码社群的巨大反响,程序员们不仅使用它构建具体的全文检索应用,而且将之集成到各种系统软件中去,以及构建Web应用,甚至某些商业软件也采用了Lucene作为其内部全文检索子系统的核心。apache软件基金会的网站使用了Lucene作为全文检索的引擎,IBM的开源软件eclipse的2.1版本中也采用了Lucene作为帮助子系统的全文索引引擎,相应的IBM的商业软件Web Sphere中也采用了Lucene。Lucene以其开放源代码的特性、优异的索引结构、良好的系统架构获得了越来越多的应用。
Lucene作为一个全文检索引擎,其具有如下突出的优点:
(1)索引文件格式独立于应用平台。Lucene定义了一套以8位字节为基础的索引文件格式,使得兼容系统或者不同平台的应用能够共享建立的索引文件。
(2)在传统全文检索引擎的倒排索引的基础上,实现了分块索引,能够针对新的文件建立小文件索引,提升索引速度。然后通过与原有索引的合并,达到优化的目的。
(3)优秀的面向对象的系统架构,使得对于Lucene扩展的学习难度降低,方便扩充新功能。
(4)设计了独立于语言和文件格式的文本分析接口,索引器通过接受Token流完成索引文件的创立,用户扩展新的语言和文件格式,只需要实现文本分析的接口。
(5)已经默认实现了一套强大的查询引擎,用户无需自己编写代码即使系统可获得强大的查询能力,Lucene的查询实现中默认实现了布尔操作、模糊查询(Fuzzy Search[11])、分组查询等等。
特性:
1.索引过程:
·在现在流行的硬件平台上每个小时可处理超过 150GB 的数据
·内存占用小,只需 1MB 的堆内存
·增量索引和批量索引速度一样快
·索引大小约为文本索引的 20-30% 大小
·静态索引修剪
2.搜索算法:
·范围搜索 - 优先返回最佳结果
·很多强大的查询类型:短语查询、通配符查询、近似查询、范围查询等
·可单独针对某个字段查询
·可单独根据某个字段排序
·多索引搜索并合并搜索结果
·允许同步更新索引和搜索
·灵活的门面搜索、高亮显示、结果集的联合和分组
·快速,低内存占用和容错
·可插入式排名模型,包括 VSM 和Okapi MB25
·可配置的存储引擎
3.跨平台解决方案
·100% 纯 Java
·其他语言提供索引兼容的实现
搜索应用程序和 Lucene 之间的关系,也反映了利用 Lucene 构建搜索应用程序的流程:
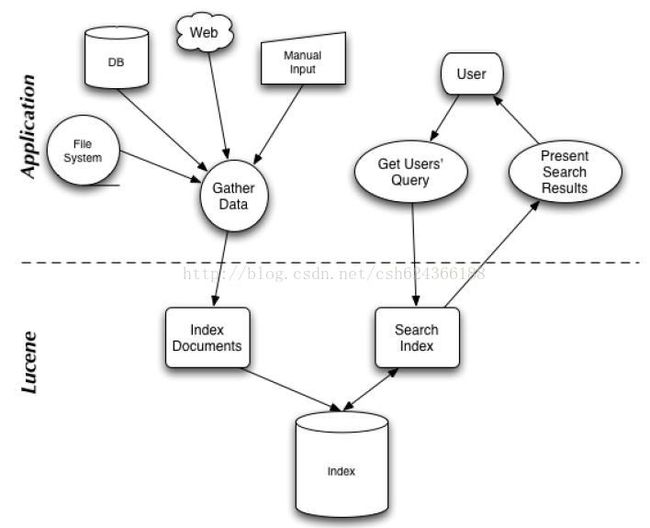
三:索引和搜索
索引是现代搜索引擎的核心,建立索引的过程就是把源数据处理成非常方便查询的索引文件的过程。为什么索引这么重要呢,试想你现在要在大量的文档中搜索含有某个关键词的文档,那么如果不建立索引的话你就需要把这些文档顺序的读入内存,然后检查这个文章中是不是含有要查找的关键词,这样的话就会耗费非常多的时间,想想搜索引擎可是在毫秒级的时间内查找出要搜索的结果的。这就是由于建立了索引的原因,你可以把索引想象成这样一种数据结构,他能够使你快速的随机访问存储在索引中的关键词,进而找到该关键词所关联的文档。Lucene 采用的是一种称为反向索引(inverted index)的机制。反向索引就是说我们维护了一个词 / 短语表,对于这个表中的每个词 / 短语,都有一个链表描述了有哪些文档包含了这个词 / 短语。这样在用户输入查询条件的时候,就能非常快的得到搜索结果。我们将在本系列文章的第二部分详细介绍 Lucene 的索引机制,由于 Lucene 提供了简单易用的 API,所以即使读者刚开始对全文本进行索引的机制并不太了解,也可以非常容易的使用Lucene 对你的文档实现索引。对文档建立好索引后,就可以在这些索引上面进行搜索了。搜索引擎首先会对搜索的关键词进行解析,然后再在建立好的索引上面进行查找,最终返回和用户输入的关键词相关联的文档。对于中文用户来说,最关心的问题是其是否支持中文的全文检索。由于Lucene良好架构设计,对中文的支持只需对其语言词法分析接口进行扩展就能实现对中文检索的支持。
推荐阅读:搜索那些事——细谈lucene(二)lucene搜索程序组件详解
参考资料:
lucene百度百科:http://baike.baidu.com/view/371811.htm
实战lucene:http://www.ibm.com/developerworks/cn/java/j-lo-lucene1/
七个搜索引擎:http://www.oschina.net/news/39289/7-search-engines-for-big-data