NLP第18课:模型部署上线的几种服务发布方式
在前面所有的模型训练和预测中,我们训练好的模型都是直接通过控制台或者 Jupyter Notebook 来进行预测和交互的,在一个系统或者项目中使用这种方式显然不可能,那在 Web 应用中如何使用我们训练好的模型呢?本文将通过以下四个方面对该问题进行讲解:
- 微服务架构简介;
- 模型的持久化与加载方式;
- Flask 和 Bottle 微服务框架;
- Tensorflow Serving 模型部署和服务。
微服务架构简介
微服务是指开发一个单个小型的但有业务功能的服务,每个服务都有自己的处理和轻量通讯机制,可以部署在单个或多个服务器上。微服务也指一种松耦合的、有一定的有界上下文的面向服务架构。也就是说,如果每个服务都要同时修改,那么它们就不是微服务,因为它们紧耦合在一起;如果你需要掌握一个服务太多的上下文场景使用条件,那么它就是一个有上下文边界的服务,这个定义来自 DDD 领域驱动设计。
相对于单体架构和 SOA,它的主要特点是组件化、松耦合、自治、去中心化,体现在以下几个方面:
- 一组小的服务:服务粒度要小,而每个服务是针对一个单一职责的业务能力的封装,专注做好一件事情;
- 独立部署运行和扩展:每个服务能够独立被部署并运行在一个进程内。这种运行和部署方式能够赋予系统灵活的代码组织方式和发布节奏,使得快速交付和应对变化成为可能。
- 独立开发和演化:技术选型灵活,不受遗留系统技术约束。合适的业务问题选择合适的技术可以独立演化。服务与服务之间采取与语言无关的 API 进行集成。相对单体架构,微服务架构是更面向业务创新的一种架构模式。
- 独立团队和自治:团队对服务的整个生命周期负责,工作在独立的上下文中,自己决策自己治理,而不需要统一的指挥中心。团队和团队之间通过松散的社区部落进行衔接。
由此,我们可以看到整个微服务的思想,与我们现在面对信息爆炸、知识爆炸做事情的思路是相通的:通过解耦我们所做的事情,分而治之以减少不必要的损耗,使得整个复杂的系统和组织能够快速地应对变化。
我们为什么采用微服务呢?
“让我们的系统尽可能快地响应变化”
——Rebecca Parson
下面是一个简单的微服务模型架构设计:
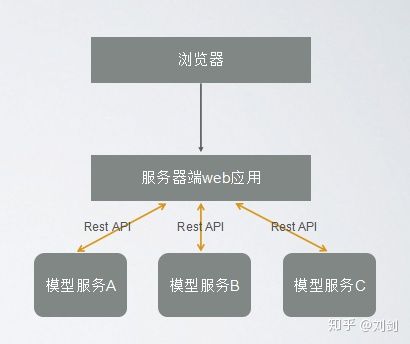
模型的持久化与加载方式
开发过 J2EE 应用的人应该对持久化的概念很清楚。通俗得讲,就是临时数据(比如内存中的数据,是不能永久保存的)持久化为持久数据(比如持久化至数据库中,能够长久保存)。
那我们训练好的模型一般都是存储在内存中,这个时候就需要用到持久化方式,在 Python 中,常用的模型持久化方式有三种,并且都是以文件的方式持久化。
1.JSON(JavaScript Object Notation)格式。
JSON 是一种轻量级的数据交换格式,易于人们阅读和编写。使用 JSON 函数需要导入 JSON 库:
import json
它拥有两个格式处理函数:
- json.dumps:将 Python 对象编码成 JSON 字符串;
- json.loads:将已编码的 JSON 字符串解码为 Python 对象。
下面看一个例子。
首先我们创建一个 List 对象 data,然后把 data 编码成 JSON 字符串保存在 data.json 文件中,之后再读取 data.json 文件中的字符串解码成 Python 对象,代码如下:
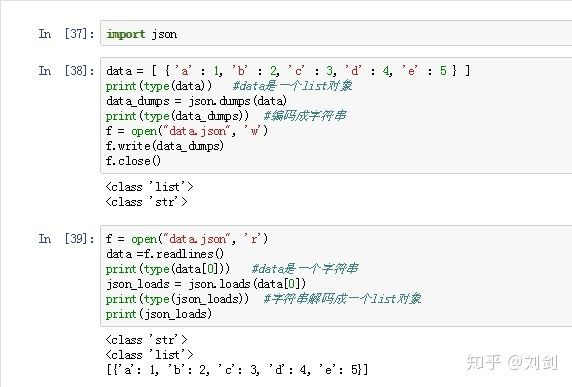
2. pickle 模块
pickle 提供了一个简单的持久化功能。可以将对象以文件的形式存放在磁盘上。pickle 模块只能在 Python 中使用,Python 中几乎所有的数据类型(列表、字典、集合、类等)都可以用 pickle 来序列化。pickle 序列化后的数据,可读性差,人一般无法识别。
使用的时候需要引入库:
import pickle
它有以下两个方法:
- pickle.dump(obj, file[, protocol]):序列化对象,并将结果数据流写入到文件对象中。参数 protocol 是序列化模式,默认值为0,表示以文本的形式序列化。protocol 的值还可以是1或2,表示以二进制的形式序列化。
- pickle.load(file):反序列化对象。将文件中的数据解析为一个 Python 对象。
我们继续延用上面的例子。实现的不同点在于,这次文件打开时用了 with...as... 语法,使用 pickle 保存结果,文件保存为 data.pkl,代码如下。
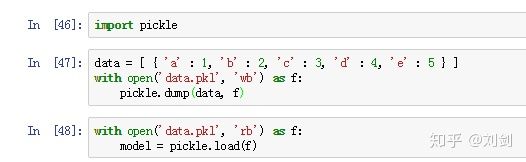
3. sklearn 中的 joblib 模块。
使用 joblib,首先需要引入包:
from sklearn.externals import joblib
使用方法如下,基本和 JSON、pickle一样,这里不再详细讲解。第17课中,进行模型保存时使用的就是这种方式,可以看代码,回顾一下。
joblib.dump(model, model_path) #模型保存
joblib.load(model_path) #模型加载
Flask 和 Bottle 微服务框架
通过上面,我们对微服务和 Python 中三种模型持久化和加载方式有了基本了解。下面我们看看,Python 中如何把模型发布成一个微服务的。
这里给出两个微服务框架 Bottle 和 Flask。
Bottle 是一个非常小巧但高效的微型 Python Web 框架,它被设计为仅仅只有一个文件的 Python 模块,并且除 Python 标准库外,它不依赖于任何第三方模块。
Bottle 本身主要包含以下四个模块,依靠它们便可快速开发微 Web 服务:
- 路由(Routing):将请求映射到函数,可以创建十分优雅的 URL;
- 模板(Templates):可以快速构建 Python 内置模板引擎,同时还支持 Mako、Jinja2、Cheetah 等第三方模板引擎;
- 工具集(Utilites):用于快速读取 form 数据,上传文件,访问 Cookies,Headers 或者其它 HTTP 相关的 metadata;
- 服务器(Server):内置 HTTP 开发服务器,并且支持 paste、fapws3、 bjoern、Google App Engine、Cherrypy 或者其它任何 WSGI HTTP 服务器。
Flask 也是一个 Python 编写的 Web 微框架,可以让我们使用 Python 语言快速实现一个网站或 Web 服务。并使用方式和 Bottle 相似,Flask 依赖 Jinja2 模板和 Werkzeug WSGI 服务。Werkzeug 本质是 Socket 服务端,其用于接收 HTTP 请求并对请求进行预处理,然后触发 Flask 框架,开发人员基于 Flask 框架提供的功能对请求进行相应的处理,并返回给用户,如果返回给用户的内容比较复杂时,需要借助 Jinja2 模板来实现对模板的处理,即将模板和数据进行渲染,将渲染后的字符串返回给用户浏览器。
Bottle 和 Flask 在使用上相似,而且 Flask 的文档资料更全,发布的服务更稳定,因此下面重点以 Flask 为例,来说明模型的微服务发布过程。
如果大家想进一步了解这两个框架,可以参考说明文档。
1.安装。
对 Bottle 和 Flask 进行安装,分别执行如下命令即可安装成功:
pip install bottle
pip install Flask
安装好之后,分别进入需要的包就可以写微服务程序了。这两个框架在使用时,用法、语法结构都差不多,网上 Flask 的中文资料相对多一些,所以这里用 Flask 来举例。
- 第一个最小的 Flask 应用。
第一个最小的 Flask 应用看起来会是这样:
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello World!'
if __name__ == '__main__':
app.run()
把它保存为 hello.py(或是类似的),然后用 Python 解释器来运行:
python hello.py
或者直接在 Jupyter Notebook 里面执行,都没有问题。服务启动将在控制台打印如下消息:
Running on http:// 127.0.0.1:5000/
意思就是,可以通过 localhost 和 5000 端口,在浏览器访问:
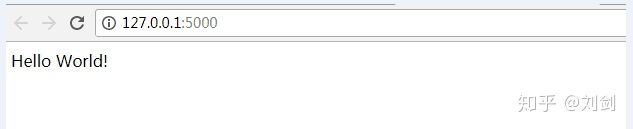
这时我们就得到了服务在浏览器上的返回结果,于是也成功构建了与浏览器交互的服务。
如果要修改服务对应的 IP 地址和端口怎么办?只需要修改这行代码,即可修改 IP 地址和端口:
app.run(host='192.168.31.19',port=8088)
- Flask 发布一个预测模型。
首先,我们这里使用第17课保存的模型“model.pkl”。如果不使用浏览器,常规的控制台交互,我们这样就可以实现:
from sklearn.externals import joblib
model_path = "D://达人课//中文自然语言处理入门实战课程//ch18//model.pkl"
model = joblib.load(model_path)
sen =[[['坚决', 'a', 'ad', '1_v'],
['惩治', 'v', 'v', '0_Root'],
['贪污', 'v', 'v', '1_v'],
['贿赂', 'n', 'n', '-1_v'],
['等', 'u', 'udeng', '-1_v'],
['经济', 'n', 'n', '1_v'],
['犯罪', 'v', 'vn', '-2_v']]]
print(model.predict(sen))
如果你现在有个需求,要求你的模型和浏览器进行交互,那 Flask 就可以实现。
在第一个最小的 Flask 应用基础上,我们增加模型预测接口,这里注意:启动之前把 IP 地址修改为自己本机的地址或者服务器工作站所在的 IP 地址。
完整的代码如下,首先在启动之前先把模型预加载到内存中,然后重新定义 predict 函数,接受一个参数 sen:
from sklearn.externals import joblib
from flask import Flask,request
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello World!'
@app.route('/predict/')
def predict(sen):
result = model.predict(sen)
return str(result)
if __name__ == '__main__':
model_path = "D://ch18//model.pkl"
model = joblib.load(model_path)
app.run(host='192.168.31.19')
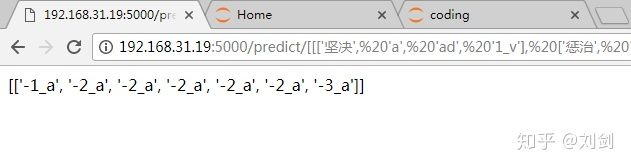
启动 Flask 服务之后,在浏览器地址中输入:
http:// 192.168.31.19:5000/pred ict/ [[['坚决', 'a', 'ad', '1 v'], ['惩治', 'v', 'v', '0Root'], ['贪污', 'v', 'v', '1 v'], ['贿赂', 'n', 'n', '-1v'], ['等', 'u', 'udeng', '-1 v'], ['经济', 'n', 'n', '1v'], ['犯罪', 'v', 'vn', '-2_v']]]
得到预测结果,这样就完成了微服务的发布,并实现了模型和前端浏览器的交互。
Tensorflow Serving 模型部署和服务
TensorFlow Serving 是一个用于机器学习模型 Serving 的高性能开源库。它可以将训练好的机器学习模型部署到线上,使用 gRPC 作为接口接受外部调用。更加让人眼前一亮的是,它支持模型热更新与自动模型版本管理。这意味着一旦部署 TensorFlow Serving 后,你再也不需要为线上服务操心,只需要关心你的线下模型训练。
同样,TensorFlow Serving 可以将模型部署在移动端,如安卓或者 iOS 系统的 App 应用上。关于 Tensorflow Serving 模型部署和服务,这里不在列举示例,直接参考文末的推荐阅读。
总结
本节对微服务架构做了简单介绍,并介绍了三种机器学习模型持久化和加载的方式,接着介绍了 Python 的两个轻量级微服务框架 Bottle 和 Flask。随后,我们通过 Flask 制作了一个简单的微服务预测接口,实现模型的预测和浏览器交互功能,最后简单介绍了 TensorFlow Servin 模型的部署和服务功能。
学完上述内容,读者可轻易实现自己训练的模型和 Web 应用的结合,提供微服务接口,实现模型上线应用。
参考文献以及推荐阅读
- Bottle 文档
- Flask 文档
- 面向机器智能的 TensorFlow 实践:产品环境中模型的部署
- Tensorflow Serving 服务部署与访问(Python + Java)