pytorch里的pack_padded_sequence和pad_packed_sequence解析
为什么要用pack_padded_sequence
在使用深度学习特别是LSTM进行文本分析时,经常会遇到文本长度不一样的情况,此时就需要对同一个batch中的不同文本使用padding的方式进行文本长度对齐,方便将训练数据输入到LSTM模型进行训练,同时为了保证模型训练的精度,应该同时告诉LSTM相关padding的情况,此时,pytorch中的pack_padded_sequence就有了用武之地。
直接从文本处理开始
假设我们有如下四段文字:
1.To the world you may be one person, but to one person you may be the world.
2.No man or woman is worth your tears, and the one who is, won’t make you cry.
3.Never frown, even when you are sad, because you never know who is falling in love with your smile.
4.We met at the wrong time, but separated at the right time. The most urgent is to take the most beautiful scenery; the deepest wound was the most real emotions.
将文本存储为test.txt,使用如下脚本转换成padding之后的矩阵:
import numpy as np
import wordfreq
vocab = {}
token_id = 1
lengths = []
with open('test.txt', 'r') as f:
for l in f:
tokens = wordfreq.tokenize(l.strip(), 'en')
lengths.append(len(tokens))
for t in tokens:
if t not in vocab:
vocab[t] = token_id
token_id += 1
x = np.zeros((len(lengths), max(lengths)))
l_no = 0
with open('test.txt', 'r') as f:
for l in f:
tokens = wordfreq.tokenize(l.strip(), 'en')
for i in range(len(tokens)):
x[l_no, i] = vocab[tokens[i]]
l_no += 1我们可以看到文本已经被转换成token_id矩阵,其中0为padding值。
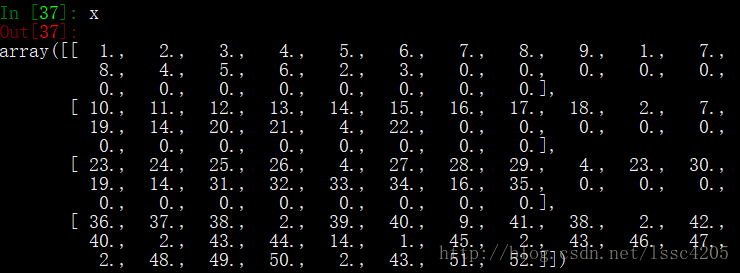
使用pack_padded_sequence
接下来就是需要用到pack_padded_sequence的地方:
import torch
import torch.nn as nn
from torch.autograd import Variable
x = Variable(x)
lengths = torch.Tensor(lengths)
_, idx_sort = torch.sort(torch.Tensor(lengths), dim=0, descending=True)
_, idx_unsort = torch.sort(idx_sort, dim=0)
x = x.index_select(0, idx_sort)
lengths = list(lengths[idx_sort])
x_packed = nn.utils.rnn.pack_padded_sequence(input=x, lengths=lengths, batch_first=True)需要注意的是,pack_padded_sequence函数的参数,lengths需要从大到小排序,x为已根据长度大小排好序,batch_first如果设置为true,则x的第一维为batch_size,第二维为seq_length,否则相反。
打印x_packed如下:

可以看到,x的前二维已被合并成一维,同时原来x中的padding值0已经被消除,多出的batch_sizes可以看成是原来x中第二维即seq_length在第一维即batch_size中不为padding值的个数。
使用pad_packed_sequence
那么问题来了,x_packed经后续的LSTM处理之后,如何转换回padding形式呢?没错,这就是pad_packed_sequence的用处。
假设x_packed经LSTM网络输出后仍为x_packed(注:一般情况下,经LSTM网络输出应该有第三维,但方便起见,x_packed的第三维的维度可看成是1),则相应转换如下:
x_padded = nn.utils.rnn.pad_packed_sequence(x_packed, batch_first=True)
output = x_padded[0].index_select(0, idx_unsort)需要注意的是,idx_unsort的作用在于将batch中的序列调整为原来的顺序。
打印output:
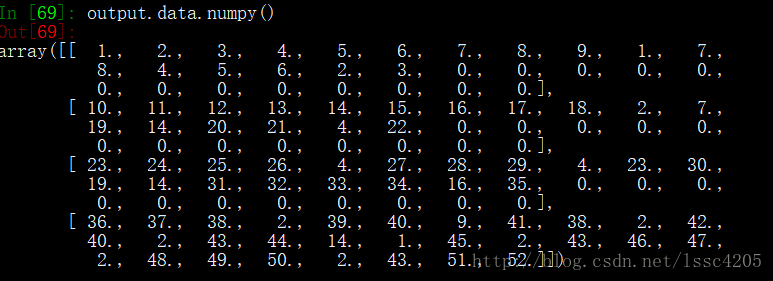
可以看出,与原来的x一样。
PackedSequence的用处
其实很简单,当之前的x_packed需要经过dropout等函数处理时,需要传入的是x_packed.data,是一个tensor,经过处理后,要将其重新封装成PackedSequence,再传入LSTM网络,示例如下:
dropout_output = nn.functional.dropout(x_packed.data, p=0.6, training=True)
x_dropout = nn.utils.rnn.PackedSequence(dropout_output, x_packed.batch_sizes)