tensorflow基础概念
1,tensorflow基础(一):tensor 和 operation
尽管有一定的python基础。
1,能够熟练的使用Tensors,Graphs,Operations,Varibles,placeholders,Sessions和name scopes来构建并运行简单的TensorFlow graphs
2,能够在TensorBoard中查看构建好的graphs
简介
TensorFlow,顾名思义就是流动着的Tensor。
Tensor实际上就是一个多维数组(multidimensional array),是TF的主要数据结构。它们在一个或多个由节点(nodes)和边(edges)组成的图(graphs)中流动。边代表的是tensors,节点代表的是对tensors的操作(operations,or Ops for short)。tensors在图中从一个节点流向另一个节点,每次经过一个节点都会接受一次操作。
创建tensor的方法可以分为2种,一种是TF自带的一些函数直接创建:
import tensorflow as tf
# create a zero filled tensor
tf.zeros([row_dim, col_dim])
# create a one filled tensor
tf.ones([row_dim, col_dim])
# create a constant filled tensor
tf.fill([row_dim, col_dim], 42)
# create a tensor out of an existing constant
tf.constant([1, 2, 3])
# generate random numbers from a uniform distribution
tf.random_uniform([row_dim, col_dim], minval=0, maxval=1)
# generate random numbers from a normal distribution
tf.random_normal([row_dim, col_dim], mean=0.0, stddev=1.0)
另一种是将Python对象(Numpy arrays, Python lists,Python scalars)转成tensor,例如:
import numpy as np
x_data = np.array([[1., 2., 3.], [3., 2., 6.]])
tf.convert_to_tensor(x_data, dtype=tf.float32)Tensor对象有3个属性:
- rank:number of dimensions
- shape: number of rows and columns
- type: data type of tensor's elements
Operation
下面举一个简单的例子来说明tensor是如何在graph中流动的:
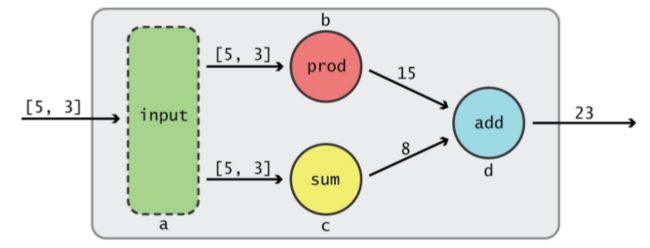
example1.png
节点a接收了一个1-D tensor,该tensor从节点a流出后,分别流向了节点b和c,节点b执行的是prod操作(5*3),节点c执行的是sum操作(5+3)。当tensor从节点b流出时变成了15,从节点c流出时变成了8。此时,2个tensor又同时流入节点d,接受的是add操作(15+8),最后从节点d流出的tensor就是23。
用TF代码来创建上面的graph:
import tensorflow as tf
a = tf.constant([5, 3], name='input_a')
b = tf.reduce_prod(a, name='prod_b')
c = tf.reduce_sum(a, name='sum_c')
d = tf.add(b, c, name='add_d')
在上面的代码中,我们用不同的构造函数(constructor)定义了四个操作(对应图上4个节点)。例如,tf.constant()创建的操作实际上就是一个“二传手”:接受一个tensor(或者一个list对象,自动将其转换成tensor对象),然后传给与它直接相连的下一个node。tf.reduce_prod()和tf.reduce_sum()操作可以把input tensor对象中的所有值相乘或相加,然后传递给下一个直接相连的node。
=====================================
===========================================================
=============================================================================
tensorflow基础:session,placeholder and variable

尽管我创建了一个input tensor([5,3])以及一系列操作(tf.reduce_prod, tf.reduce_sum, tf.add),可是并不能马上看到结果,这是我第一次接触TF时最不习惯的地方。
Session
一个完整的TF代码主要可以分成2个部分:定义(definition)和运行(run)。而此时我们仅仅是完成了graph的定义,不会立刻执行。为了运行这个图,让tensor真正流动起来,我们需要创建一个Session对象,然后调用它的run方法。当执行完毕后,最好调用close方法将Session关闭:

code2.png
当我们把图中的一个节点(node)传递给Session.run( )的时候,实际上就是在对TF说:“Hi,我想要这个node的输出,请帮我运行相应的操作来得到它,谢谢!” 这时,Session会找到这个node所依赖的所有操作,然后按照从前到后的顺序依次进行计算,直到得出你所需要的结果。
写到这里,我突然想到这和linux中的软件包管理器十分类似,当你install一个软件包的时候,它会自动帮你把所有依赖包都装好,而这背后的安装过程对用户来说都是透明的。虽然我不知道软件包管理器是怎么实现的,但我猜测其内部也有一个graph。
Session.run方法有2个参数,分别是fetches和feed_dict。参数名有时候可以省略,比如sess.run(fetches=d)和前面的sess.run(d)是一样的。传递给fetches参数的既可以是Tensor也可以是Operation。如果传给fetches的是一个list,run返回的结果也是一个与之对应的list:

feed_dict参数的作用是替换图中的某个tensor的值
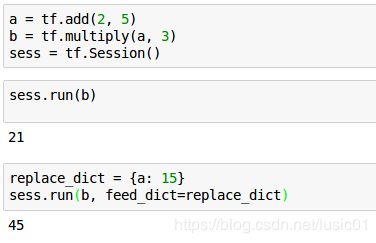
当我们利用feed_dict直接提供某个tensor值(a=15)的时候,就不需要再去执行为计算这个tensor所需的所有操作(2+5=7)。这样做的好处是在某些情况下可以避免一些不必要的计算。除此之外,feed_dict还可以用来设置graph的输入值,这就引入了placeholder的概念。
placeholder
我们将文章开头部分的代码做了一点修改

此时的a不是一个tensor,而是一个placeholder。我们定义了它的type和shape,但是并没有具体的值。在后面定义graph的代码中,placeholder看上去和普通的tensor对象一样。在运行程序的时候我们用feed_dict的方式把具体的值提供给placeholder,达到了给graph提供input的目的。
placeholder有点像在定义函数的时候用到的参数。我们在写函数内部代码的时候,虽然用到了参数,但并不知道参数所代表的值。只有在调用函数的时候,我们才把具体的值传递给参数。
Variable
前面介绍的Tensor对象是不可改变的(immutable),可以认为它们是常量(constant)。程序中还需要一类可以改变自身值的变量(variables),下面我们就来创建Variable对象:
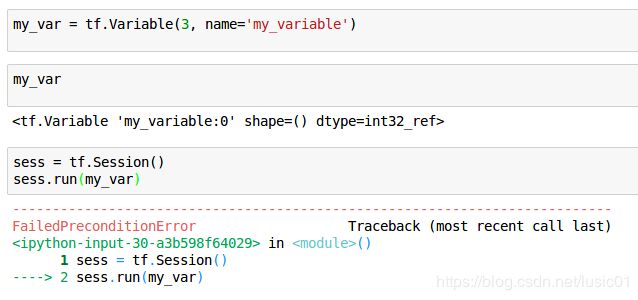
Oops!报错了?为什么看不到变量的值呢?
Variable对象的状态是由Session来管理的,所以我们必须在Session中对Variable对象进行初始化操作:

也可以对部分Variable对象进行初始化操作:
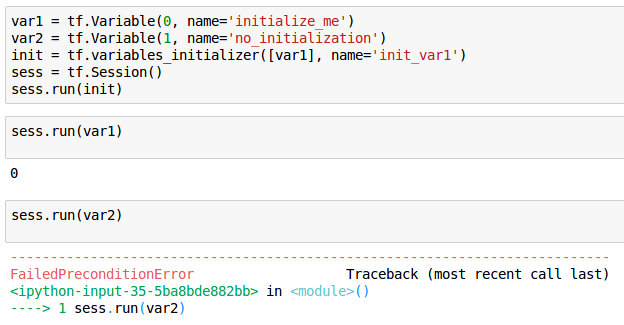
既然变量的值是可以改变的,那么我们该如何操作呢?我们可以用Variable对象的assign方法Variable.assign()来给Variable一个新的值。Variable.assign()返回的是一个操作(Op), 必须在Session中运行才会起作用:
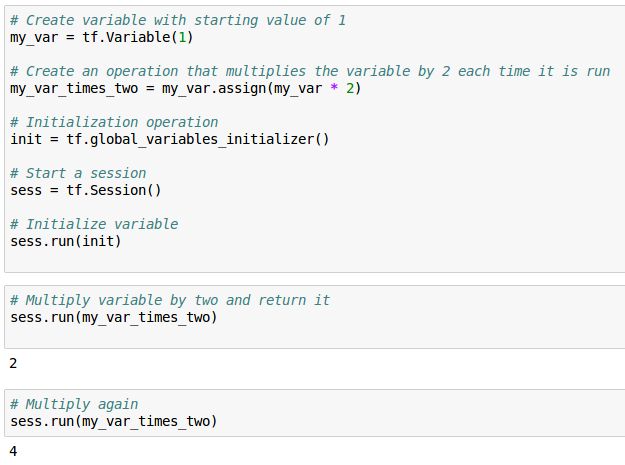
code9.png
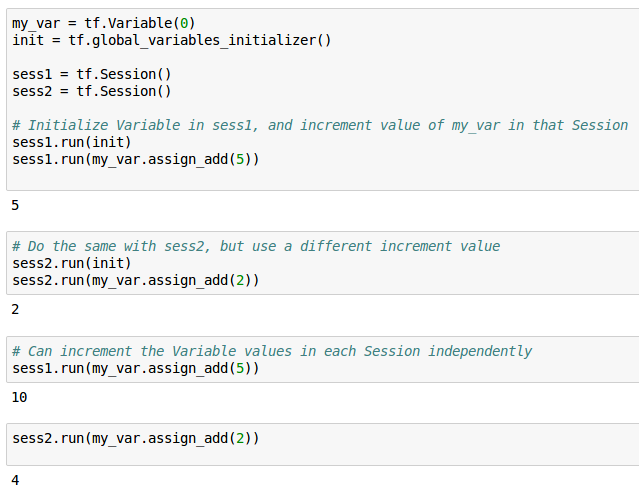
每个Session对Variable的管理是独立的,所以同一个Variable在不同的Session中可以有不同的值:
【深度学习-4】TensorFlow基础(三):Graph,name scopes, TensorBoard

Rapp
2017.05.05 12:56* 字数 626 阅读 699评论 0喜欢 3
Graph
在前面的文章中,我们学会了如何在TensorFlow(TF)中创建Tensor,Variable和Operation来组成一个graph,以及如何利用Session运行一个graph。但是这个graph对象究竟是在什么时候创建的?我们能否同时创建多个graph呢?
要回答这个问题,我们首先要了解在默认的情况下,TF是如何创建graph的。TF在library加载以后,会自动创建一个Graph对象,并把它作为default graph,我们创建的操作会自动放在这个default graph里。我们也可以不使用TF自动创建的graph,而是创建自己的graph对象并设置为default,然后添加各种操作,例如:
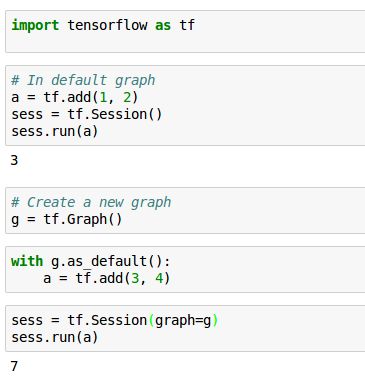
code1.png
注意,如果打算运行自己创建的graph,一定要把它传递给tf.Session的graph参数。
我们也可以自己创建多个Graph对象,将它设为default graph后,添加各种操作:

code2.png
name scopes and TensorBoard
到目前为止,我们学习了创建TF graph所需的所有原材料。前面的例子都很简单,一个graph中只有几个节点,然而在实际工作中,我们需要创建包含成百上千个节点的graph。如何有效的组织和查看graph就显得尤为重要。在TF中,我们可以通过name scope的方式来组织节点,并利用TensorBoard来可视化。
name scopes的作用就是把相关的操作组织在一起,形成一个大的block。在TensorBoard中查看graph的时候,会发现所有的节点都被封装在一个个block中。
我们先来利用name scope创建一个简单的graph,并保存在文件中:
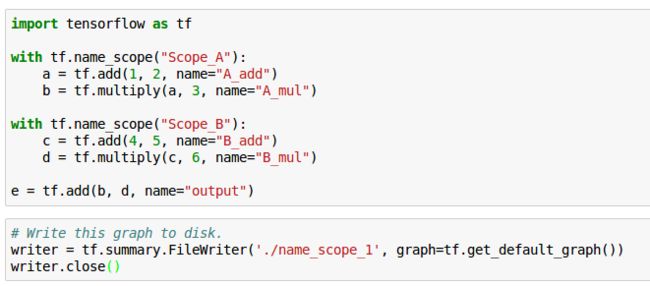
code3.png
接着在终端中启动TensorBoard:
$ tensorboard --logdir='./name_scope_1'
打开浏览器,在地址栏中输入http://127.0.1.1:6006,点击GRAPH标签,就可以看到下面的结果:
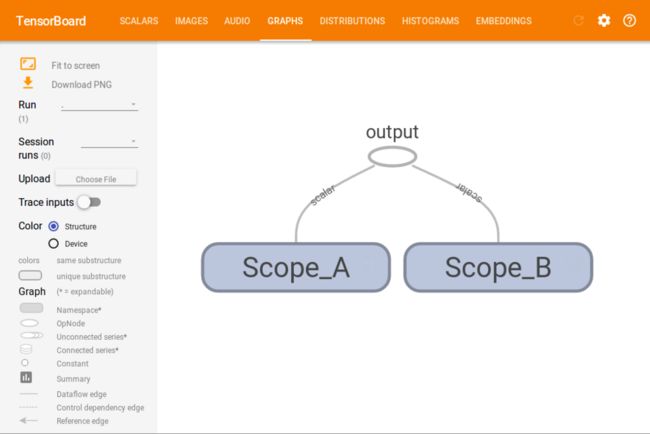
tensorboard_1.png
此时我们只能看到两个box,分别代表的是我们定义的两个name scope,我们点击box右上角的+号,就可以展开box,看到里面的节点:
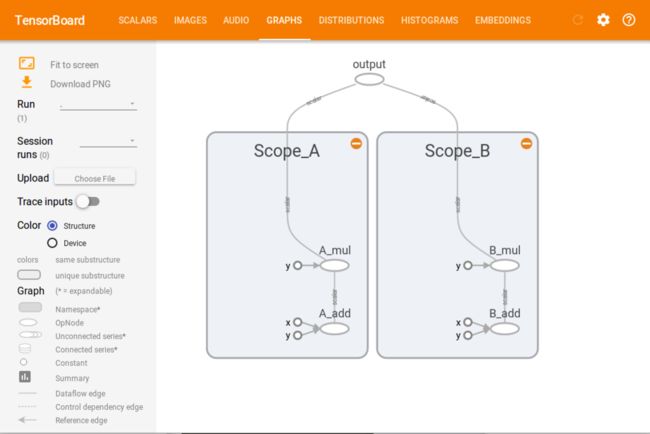
tensorboard_2.png
接下来我们创建一个更复杂一些的graph:

code4.png
在TensorBoard中我们可以清楚的看到:Transformation scope包含了4个scope,这4个scope又分成了2层(用不同的颜色表示),第一层的A和B把它们的output传给了第二层的C和D,然后C和D把它们的output传给了最后一个节点。
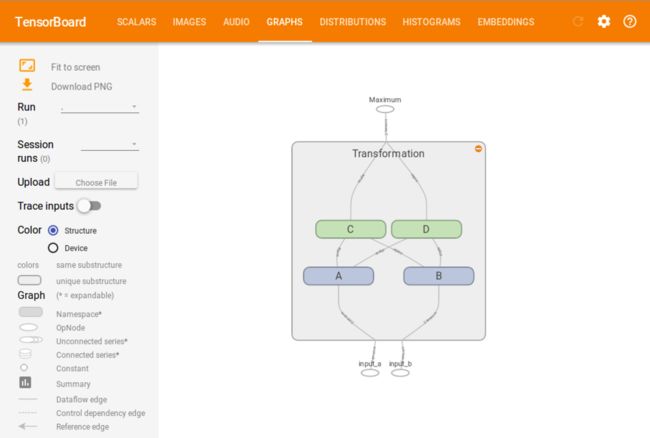
tensorboard_3.png
我们可以进一步查看4个scope内部的结构:
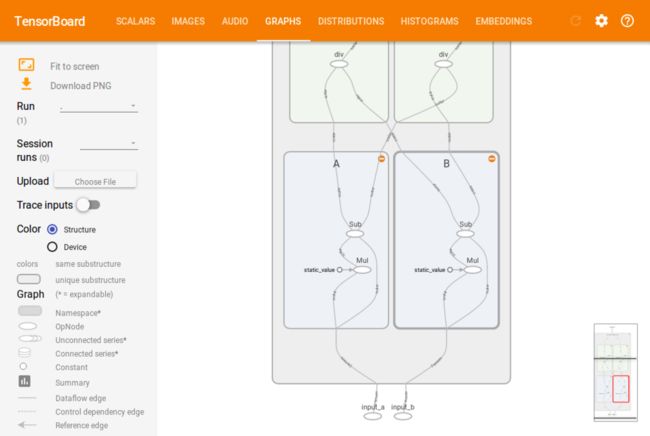
tensorboard_4.png

tensorboard_5.png
从这个例子可以看到,将复杂的网络分解成各个block和layer,可以让我们快速地理解网络的结构。
我们通过简单的例子学习了TensorFlow中的一些最基本的概念。这是我们看懂TF代码的前提条件,也是向构建复杂神经网络迈出的坚实一步。预知后事如何,且听下回分解