文本分类 之 基于BertForSequenceClassification模型的金融知道 最佳答案推荐
目录
- 金融知道 最佳答案推荐
- 1. BERT 中文预训练模型和数据集可以从百度云盘下载
- 2. 数据分析和预处理
- 3. 模型结果分析:
- 4. 模型预测和网页版Flask部署
- 5. 模型训练源码如下:
- 6. 模型网页部署源码
金融知道 最佳答案推荐
本项目是基于 hunggingface transformer 中BertForSequenceClassification, 利用BERT中文预训练模型,进行金融知道 最佳问答的 模型训练.
该模型可应用场景: 金融问答系统/论坛等 根据已有的答复, 推荐与问题最匹配的答案.
1. BERT 中文预训练模型和数据集可以从百度云盘下载
链接: 预训练模型和数据提取码: um2g
如果你想跳过训练直接做预测可以用我训练好的模型 在网盘中 checkpoint-18000文件夹中.
注意 : pytorch_model.bin是bert-base-chinese-pytorch_model.bin 重命名后的,因为transformers 从本地加载bert 预训练模型时,模型的名字必须时pytorch_model.bin,这个是由’file_utils.py’里面的 WEIGHTS_NAME=‘pytorch_model.bin’, 并且在modeling_utils.py中是寻找 path/pytorch_model.py 来加载预训练模型的.
2. 数据分析和预处理
原始数据结构: Title/Question/Reply/Is_best, 其中question 可以为空. 处理方式请见 data_clean.ipynb
- 数据集中question的分布:
question 为空的有: 599681
question 与 title 内容相同的有: 105422
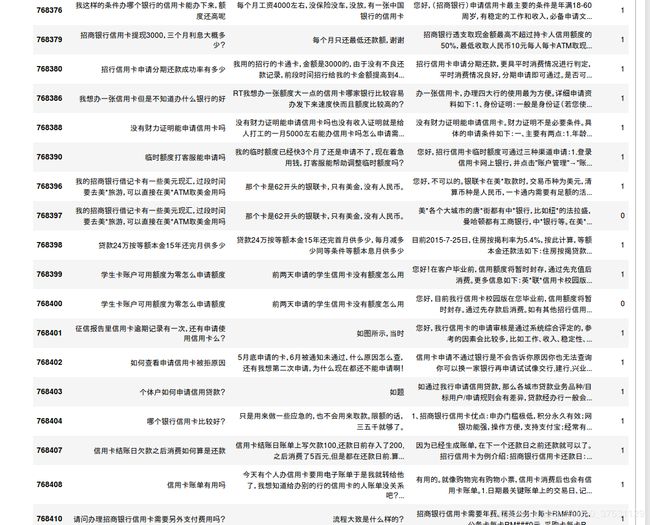
question 不为空,且与title 内容不相同的有: 63324 - 查看quesiton不为空且与title不相同的内容
第一列 title,第二列 question, 第三列 reply, 第四列 is_best
- 对于question不为空,且越title内容不一致的数据处理
1)) 计算question 和title的长度. 2)) 计算question和title的文本相似度.
于文本相似度高的,取长度较长的作为best_title, 对于文本相似度较低的 将title和question拼接到一起作为best_title
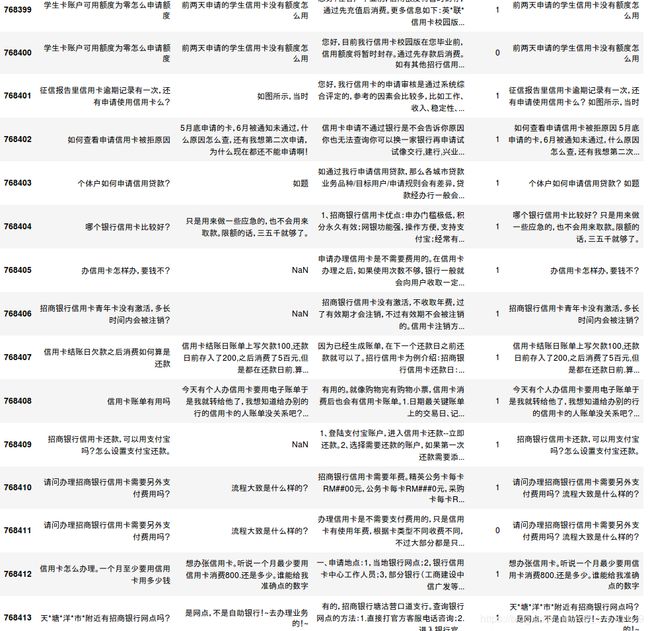
 best_title 处理结果如下图, columns顺序: title, question, reply, is_best, best_title(最后一列是通过前面的处理得到的).
best_title 处理结果如下图, columns顺序: title, question, reply, is_best, best_title(最后一列是通过前面的处理得到的).
我们可以看到:
对于question NaN 的行, best-title 直接是 title.
对于question和title不一致的行, 分两种情况:
- 内容不相似, 如768403 行, title是 ‘哪个银行信用卡比较好?’, question是 ‘只是用来做一些应急的,也不会用来取款,限额的话,三五千就够了’, best_title 是把两句话拼接起来的,因为title 和question 文本相似度不高,说明两部分内容表达的意思不一样,需要结合起来看.
2)内容相似, 如768412行, title是’信用卡怎么办理,一个月至少要用信用卡多少钱?’ question是’想办张信用卡,听说一个月最少要用信用卡消费800还是多少,谁能给我准确点的数字’, best_title 是选择question作为best_title,因为title和question内容相似度高,说明表达意思比较一致,选取较长的作为best_title.
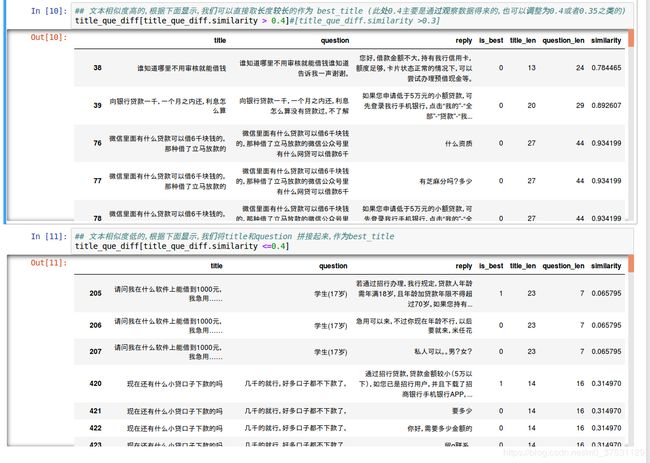
处理步骤:
-
第一: 获取best_title.
对于question 为空的,直接取title作为best_title
对于quesiton 与 title相同的,直接取title作为best_title
对于question 不为空,且与title不同的,按照上述方法,计算question和title的问题相似度,若相似度大于0.4直接取长度较长的作为best_title, 若相似度小于0.4,则将title与quesiton 拼接起来作为best_title. -
第二: 对new_data [‘best_title’, ‘reply’, ‘is_best’]进行分析和处理
查看is_best 0,1 数据量。
查看有多少问题含有best答案,有多少问题没有best答案。此处去掉没有best answer的问题,保证每个问题都有一个正确的answer。
整理wrong answer, 查看一个问题有多少个wrong answers。此处希望每个问题的wrong answers 数量是一致的。比如可以设为1个或者多个wrong. -
第三: 根据Reply 和is_best 保证每个问题都有一个最佳答复, 同时也有一个wrong 答复. 对于wrong 答复有3种方式:
方法1
如果该问题有对应wrong answer 则直接返回wrong answer
如果该问题没有对应的wrong answer 则从所有wrong answer中随机选择一个wrong answer 作为该问题的wrong answer (此处wrong answer 有些会很离谱)
方法2
如果该问题有对应wrong answer 则直接返回wrong answer
如果该问题没有对应的wrong answer 则从所有right+wrong answer中 随机选择一个非该问题的answer 作为该问题的wrong answer (这里可以说明wrong answer有些是有意义的,只是不是该问题的答案,但是有些也可可能是很离谱的)
方法3
如果该问题有对应wrong answer 则直接返回wrong answer
如果该问题没有对应的wrong answer 则从所有right answer中 随机选择一个非该问题的answer 作为该问题的wrong answer (这里至少可以说明答案是有意义的,只是不是该问题的答案)本许次训练时,首先用了第一种Negative 答复提取方法. predict时 用的是 第3种 Negative 提取方法构造的predict 文件. 我们看看效果. (最好是用第3中方法获取训练集和测试集, 百度网盘中的method-3是通过第3种方法获取的train/test/predict)
3. 模型结果分析:
训练命令:
python -u bert_update.py --data_dir data_1026_new --output_dir data_1026_new/output3 --max_seq_length 512 --do_train --do_eval --train_batch_size 4 --eval_batch_size 64 --gradient_accumulation_steps 32 --num_train_epochs 6 --eval_all_checkpoints >>data_1026_new/output3_log.txt 2>&1
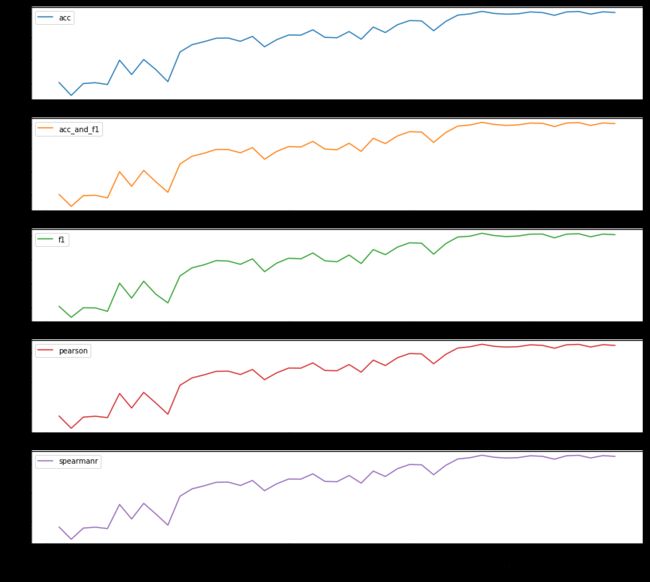
验证集上的结果:
| acc | acc_and_f1 | f1 | pearson | spearmanr |
|---|---|---|---|---|
| 0.97822 | 0.978229 | 0.978238 | 0.956442 | 0.956442 |
该模型训练的比较久~4天, 每个500个checkpoint 保存一次模型, 训练结束总共保存了47次(最后一个checkpoint: 23500), 模型在第18000个checkpoint acc达到最高 97.8%.(这个是用方法1构造的Negative reply, 可以再尝试方法3,我想相比方法1 应该会稍微难一些)
4. 模型预测和网页版Flask部署
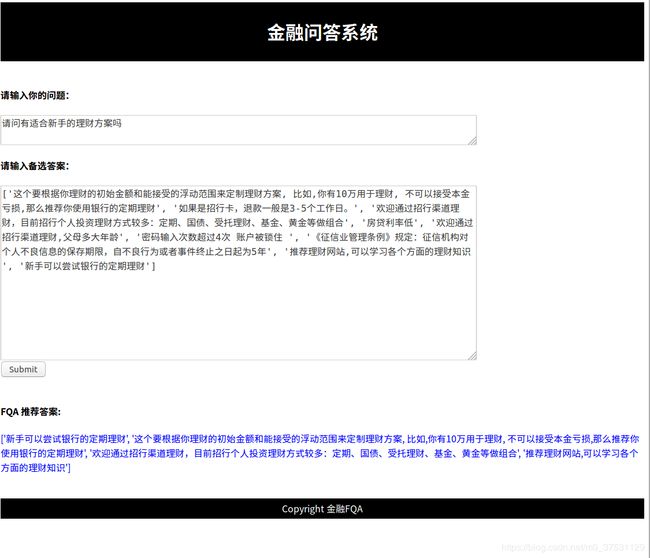
模型预测可以使用terminal 直接预测也可以通过Flask部署的网页输入问题和候选答案(可以为空).
网页版模型部署的代码在第6步会提供给大家. 网页部署需要在同目录下创建一个templates文件夹里面放一个FQA.html文件, 关于html如果创建,推荐参考w3schoolhtml的教程,我也是第一次做flask,根据这个教程半天的时间完成网页部署的.
terminal 运行命令如下:
python bert_update.py --data_dir data_1026_new --output_dir data_1026_new/output3 --max_seq_length 512 --do_predict --checkpoint checkpoint-18000
预测形式有两种:
- 如果有备选答案,则从备选答案中选择合适的答案推荐给用户.
- 如果没有备选答案,则通过TFIDF计算用户输入的问题 与训练集和测试集中,所有问题的相似度,找到相似度高的问题 对应的正确答案作为 备选答案. 然后通过模型从候选答案中选择最合适的答案推荐给用户.
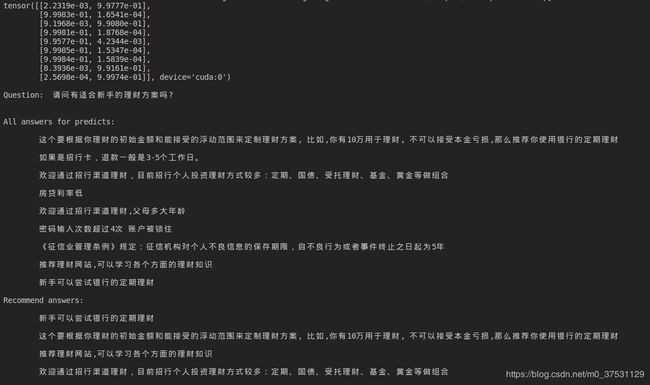
case-1: 输入问题和多个候选答案, 系统返回得分较高的答案推荐给用户.
下面是一个简单的预测结果如下, 下图中第一个tensor是 每个答案得到的[错误,正确] 的概率, 这里我只打印正确的概率大于0.9的答案, 该问题 在该模型下有4条答复满足要求(分别是第1,3,9,10),作为recommend answers 返回给用户.
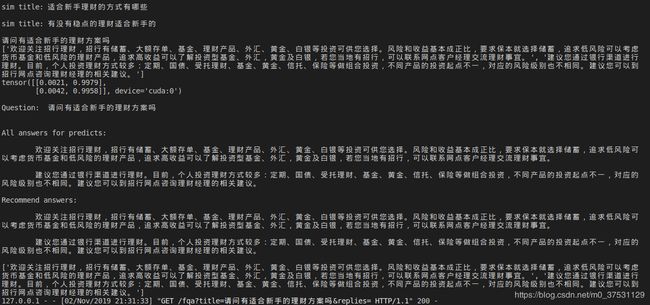
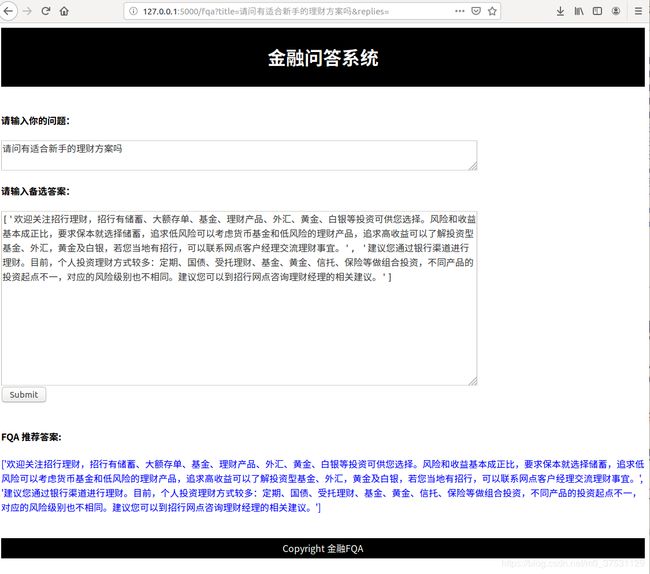
 case-2: 当用户只输入问题,没有备选答案时, 系统会通过TF-IDF从训练集和测试集 title中选择和 用户问题相似的问题, 然后获取这些问题的最佳答案作为候选答案, 通过模型推荐给用户更好的答案.(下图显示了 用户输入问题: ‘请问有适合新手的理财方案吗?’, 系统找到的相似title: ‘适合新手理财的方式有哪些’, ‘有没有稳点的理财适合新手的’, 对应这些问题的最佳答案 作为后选答案. 通过模型计算,这两个答案都比较适合推荐给用户)
case-2: 当用户只输入问题,没有备选答案时, 系统会通过TF-IDF从训练集和测试集 title中选择和 用户问题相似的问题, 然后获取这些问题的最佳答案作为候选答案, 通过模型推荐给用户更好的答案.(下图显示了 用户输入问题: ‘请问有适合新手的理财方案吗?’, 系统找到的相似title: ‘适合新手理财的方式有哪些’, ‘有没有稳点的理财适合新手的’, 对应这些问题的最佳答案 作为后选答案. 通过模型计算,这两个答案都比较适合推荐给用户)
5. 模型训练源码如下:
# coding=utf-8
from __future__ import absolute_import, division, print_function
import argparse
import glob
import logging
import os
import random
import numpy as np
import torch
from torch.utils.data import (DataLoader, RandomSampler, SequentialSampler,
TensorDataset)
from torch.utils.data.distributed import DistributedSampler
from tensorboardX import SummaryWriter
from tqdm import tqdm, trange
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler, TensorDataset
from transformers import AdamW, WarmupLinearSchedule
from transformers import WEIGHTS_NAME, BertConfig, BertForSequenceClassification,BertTokenizer
from transformers.data.processors.utils import DataProcessor, InputExample,InputFeatures
import pandas as pd
import torch.nn.functional as F
from scipy.stats import pearsonr, spearmanr
from sklearn.metrics import matthews_corrcoef, f1_score
logger = logging.getLogger(__name__)
def convert_one_example_to_features(examples, tokenizer, max_length=512, pad_token=0, pad_token_segment_id=0, mask_padding_with_zero=True):
features = []
for (ex_index, example) in enumerate(examples):
inputs = tokenizer.encode_plus(
example.text_a,
example.text_b,
add_special_tokens=True,
max_length=max_length,
truncate_first_sequence=False # We're truncating the first sequence in priority
)
input_ids, token_type_ids = inputs["input_ids"], inputs["token_type_ids"]
attention_mask = [1 if mask_padding_with_zero else 0] * len(input_ids)
padding_length = max_length - len(input_ids)
input_ids = input_ids + ([pad_token] * padding_length)
attention_mask = attention_mask + ([0 if mask_padding_with_zero else 1] * padding_length)
token_type_ids = token_type_ids + ([pad_token_segment_id] * padding_length)
assert len(input_ids) == max_length, "Error with input length {} vs {}".format(len(input_ids), max_length)
assert len(attention_mask) == max_length, "Error with input length {} vs {}".format(len(attention_mask), max_length)
assert len(token_type_ids) == max_length, "Error with input length {} vs {}".format(len(token_type_ids), max_length)
features.append(
InputFeatures(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
label=None))
return features
def convert_examples_to_features(examples, tokenizer,
max_length=512,
task=None,
label_list=None,
output_mode=None,
pad_on_left=False,
pad_token=0,
pad_token_segment_id=0,
mask_padding_with_zero=True):
label_map = {label: i for i, label in enumerate(label_list)}
features = []
for (ex_index, example) in enumerate(examples):
if ex_index % 10000 == 0:
logger.info("Writing example %d" % (ex_index))
inputs = tokenizer.encode_plus(
example.text_a,
example.text_b,
add_special_tokens=True,
max_length=max_length,
truncate_first_sequence=False # We're truncating the first sequence in priority
)
# import code
# code.interact(local=locals())
input_ids, token_type_ids = inputs["input_ids"], inputs["token_type_ids"]
# The mask has 1 for real tokens and 0 for padding tokens. Only real
# tokens are attended to.
attention_mask = [1 if mask_padding_with_zero else 0] * len(input_ids)
# Zero-pad up to the sequence length.
padding_length = max_length - len(input_ids)
if pad_on_left:
input_ids = ([pad_token] * padding_length) + input_ids
attention_mask = ([0 if mask_padding_with_zero else 1] * padding_length) + attention_mask
token_type_ids = ([pad_token_segment_id] * padding_length) + token_type_ids
else:
input_ids = input_ids + ([pad_token] * padding_length)
attention_mask = attention_mask + ([0 if mask_padding_with_zero else 1] * padding_length)
token_type_ids = token_type_ids + ([pad_token_segment_id] * padding_length)
# import code
# code.interact(local=locals())
# print()
assert len(input_ids) == max_length, "Error with input length {} vs {}".format(len(input_ids), max_length)
assert len(attention_mask) == max_length, "Error with input length {} vs {}".format(len(attention_mask), max_length)
assert len(token_type_ids) == max_length, "Error with input length {} vs {}".format(len(token_type_ids), max_length)
if output_mode == "classification":
label = label_map[example.label]
elif output_mode == "regression":
label = float(example.label)
else:
raise KeyError(output_mode)
if ex_index < 5:
logger.info("*** Example ***")
logger.info("guid: %s" % (example.guid))
logger.info("input_ids: %s" % " ".join([str(x) for x in input_ids]))
logger.info("attention_mask: %s" % " ".join([str(x) for x in attention_mask]))
logger.info("token_type_ids: %s" % " ".join([str(x) for x in token_type_ids]))
logger.info("label: %s (id = %d)" % (example.label, label))
features.append(
InputFeatures(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
label=label))
return features
class FaqProcessor(DataProcessor):
def get_train_examples(self, data_dir):
return self._create_examples(os.path.join(data_dir, 'train.csv'))
def get_dev_examples(self, data_dir):
return self._create_examples(os.path.join(data_dir, 'test.csv'))
def get_labels(self):
return [0, 1]
def _create_examples(self, path):
df = pd.read_csv(path, encoding='utf-8-sig',sep='\t')
# df.
examples = []
titles = [str(t) for t in df['best_title'].tolist()]
replies = [str(t) for t in df['reply'].tolist()]
labels = df['is_best'].astype('int').tolist()
for i in range(len(labels)):
examples.append(
InputExample(guid=i, text_a=titles[i], text_b=replies[i], label=labels[i]))
return examples
def _create_one_example(self, title, replies):
examples = []
num_examples = len(replies)
for i in range(num_examples):
examples.append(InputExample(guid=i, text_a=str(title), text_b=str(replies[i]), label=None))
return examples
def prepare_replies(self, path):
df = pd.read_csv(path)
df = df.fillna(0)
replies = [str(t) for t in df['reply'].tolist()]
return replies
def simple_accuracy(preds, labels):
return (preds == labels).mean()
def acc_and_f1(preds, labels):
acc = simple_accuracy(preds, labels)
f1 = f1_score(y_true=labels, y_pred=preds)
return {
"acc": acc,
"f1": f1,
"acc_and_f1": (acc + f1) / 2,
}
def pearson_and_spearman(preds, labels):
pearson_corr = pearsonr(preds, labels)[0]
spearman_corr = spearmanr(preds, labels)[0]
return {
"pearson": pearson_corr,
"spearmanr": spearman_corr,
"corr": (pearson_corr + spearman_corr) / 2,
}
def acc_f1_pea_spea(preds, labels):
acc_f1 = acc_and_f1(preds, labels)
pea_spea = pearson_and_spearman(preds,labels)
return {**acc_f1, **pea_spea}
def set_seed(args):
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
def train(args, processor, model, tokenizer):
""" Train the model """
tb_writer = SummaryWriter()
train_dataset = load_and_cache_examples(args, processor, tokenizer, evaluate=False)
train_sampler = RandomSampler(train_dataset)
train_dataloader = DataLoader(train_dataset, sampler=train_sampler, batch_size=args.train_batch_size)
if args.max_steps > 0:
t_total = args.max_steps
args.num_train_epochs = args.max_steps // (len(train_dataloader) // args.gradient_accumulation_steps) + 1
else:
t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs
# Prepare optimizer and schedule (linear warmup and decay)
no_decay = ['bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)], 'weight_decay': args.weight_decay},
{'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
scheduler = WarmupLinearSchedule(optimizer, warmup_steps=args.warmup_steps, t_total=t_total)
# Train!
logger.info("***** Running training *****")
logger.info(" Num examples = %d", len(train_dataset))
logger.info(" Num Epochs = %d", args.num_train_epochs)
logger.info(" Instantaneous batch size per GPU = %d", args.train_batch_size)
logger.info(" Total train batch size (w. parallel, distributed & accumulation) = %d",
args.train_batch_size * args.gradient_accumulation_steps)
logger.info(" Gradient Accumulation steps = %d", args.gradient_accumulation_steps)
logger.info(" Total optimization steps = %d", t_total)
global_step = 0
tr_loss, logging_loss = 0.0, 0.0
model.zero_grad()
train_iterator = trange(int(args.num_train_epochs), desc="Epoch")
set_seed(args) # Added here for reproductibility (even between python 2 and 3)
for _ in train_iterator:
epoch_iterator = tqdm(train_dataloader, desc="Iteration")
for step, batch in enumerate(epoch_iterator):
model.train()
batch = tuple(t.to(args.device) for t in batch)
inputs = {'input_ids': batch[0],
'attention_mask': batch[1],
'token_type_ids': batch[2],
'labels': batch[3]}
outputs = model(**inputs)
loss = outputs[0] # model outputs are always tuple in transformers (see doc)
if args.gradient_accumulation_steps > 1:
loss = loss / args.gradient_accumulation_steps
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
tr_loss += loss.item()
if (step + 1) % args.gradient_accumulation_steps == 0:
optimizer.step()
scheduler.step() # Update learning rate schedule
model.zero_grad()
global_step += 1
if args.logging_steps > 0 and global_step % args.logging_steps == 0:
# Log metrics
if args.evaluate_during_training: # Only evaluate when single GPU otherwise metrics may not average well
results = evaluate(args, processor, model, tokenizer)
for key, value in results.items():
tb_writer.add_scalar('eval_{}'.format(key), value, global_step)
tb_writer.add_scalar('lr', scheduler.get_lr()[0], global_step)
tb_writer.add_scalar('loss', (tr_loss - logging_loss)/args.logging_steps, global_step)
logging_loss = tr_loss
if args.save_steps > 0 and global_step % args.save_steps == 0:
# Save model checkpoint
output_dir = os.path.join(args.output_dir, 'checkpoint-{}'.format(global_step))
if not os.path.exists(output_dir):
os.makedirs(output_dir)
model_to_save = model.module if hasattr(model, 'module') else model # Take care of distributed/parallel training
model_to_save.save_pretrained(output_dir)
torch.save(args, os.path.join(output_dir, 'training_args.bin'))
logger.info("Saving model checkpoint to %s", output_dir)
if args.max_steps > 0 and global_step > args.max_steps:
epoch_iterator.close()
break
if args.max_steps > 0 and global_step > args.max_steps:
train_iterator.close()
break
tb_writer.close()
return global_step, tr_loss / global_step
def evaluate(args, processor, model, tokenizer, prefix=""):
# Loop to handle MNLI double evaluation (matched, mis-matched)
# eval_outputs_dirs = (args.output_dir, args.output_dir + '-MM') if args.task_name == "mnli" else (args.output_dir,)
eval_output_dir = args.output_dir
results = {}
# for eval_output_dir in zip(eval_task_names, eval_outputs_dirs):
eval_dataset = load_and_cache_examples(args, processor, tokenizer, evaluate=True)
if not os.path.exists(eval_output_dir) :
os.makedirs(eval_output_dir)
# Note that DistributedSampler samples randomly
eval_sampler = SequentialSampler(eval_dataset)
eval_dataloader = DataLoader(eval_dataset, sampler=eval_sampler, batch_size=args.eval_batch_size)
# Eval!
logger.info("***** Running evaluation {}*****".format(prefix))
logger.info(" Num examples = %d", len(eval_dataset))
logger.info(" Batch size = %d", args.eval_batch_size)
eval_loss = 0.0
nb_eval_steps = 0
preds = None
out_label_ids = None
for batch in tqdm(eval_dataloader, desc="Evaluating"):
model.eval()
batch = tuple(t.to(args.device) for t in batch)
with torch.no_grad():
inputs = {'input_ids': batch[0],
'attention_mask': batch[1],
'token_type_ids': batch[2],
'labels': batch[3]}
outputs = model(**inputs)
tmp_eval_loss, logits = outputs[:2]
eval_loss += tmp_eval_loss.mean().item()
nb_eval_steps += 1
if preds is None:
preds = logits.detach().cpu().numpy()
out_label_ids = inputs['labels'].detach().cpu().numpy()
else:
preds = np.append(preds, logits.detach().cpu().numpy(), axis=0)
out_label_ids = np.append(out_label_ids, inputs['labels'].detach().cpu().numpy(), axis=0)
eval_loss = eval_loss / nb_eval_steps
preds = np.argmax(preds, axis=1)
result = acc_f1_pea_spea(preds, out_label_ids)
results.update(result)
output_eval_file = os.path.join(eval_output_dir, "eval_results.txt")
with open(output_eval_file, "w") as writer:
logger.info("***** Eval results {} *****".format(prefix))
for key in sorted(result.keys()):
logger.info(" %s = %s", key, str(result[key]))
writer.write("%s = %s\n" % (key, str(result[key])))
return results
def load_and_cache_examples(args, processor, tokenizer, evaluate=False):
# Load data features from cache or dataset file
cached_features_file = os.path.join(args.data_dir, 'cached_{}_{}'.format(
'dev' if evaluate else 'train',
str(args.max_seq_length)))
if os.path.exists(cached_features_file):
logger.info("Loading features from cached file %s", cached_features_file)
features = torch.load(cached_features_file)
else:
logger.info("Creating features from dataset file at %s", args.data_dir)
label_list = processor.get_labels()
examples = processor.get_dev_examples(args.data_dir) if evaluate else processor.get_train_examples(args.data_dir)
features = convert_examples_to_features(
examples=examples,
tokenizer=tokenizer,
max_length=args.max_seq_length,
label_list=label_list,
output_mode='classification',
pad_on_left=False,
pad_token=tokenizer.convert_tokens_to_ids([tokenizer.pad_token])[0],
pad_token_segment_id=0)
logger.info("Saving features into cached file %s", cached_features_file)
torch.save(features, cached_features_file)
# Convert to Tensors and build dataset
all_input_ids = torch.tensor([f.input_ids for f in features], dtype=torch.long)
all_attention_mask = torch.tensor([f.attention_mask for f in features], dtype=torch.long)
all_token_type_ids = torch.tensor([f.token_type_ids for f in features], dtype=torch.long)
all_labels = torch.tensor([f.label for f in features], dtype=torch.long)
dataset = TensorDataset(all_input_ids, all_attention_mask, all_token_type_ids, all_labels)
return dataset
def main():
parser = argparse.ArgumentParser()
## Required parameters
parser.add_argument("--data_dir", default=None, type=str, required=True,
help="The input data dir. Should contain the .tsv files (or other data files) for the task.")
# parser.add_argument("--model_name_or_path", default=None, type=str, required=True,
# help="Path to pre-trained model or shortcut name selected in the list: " + ", ".join(ALL_MODELS))
parser.add_argument("--output_dir", default=None, type=str, required=True,
help="The output directory where the model predictions and checkpoints will be written.")
## Other parameters
parser.add_argument("--config_name", default="", type=str,
help="Pretrained config name or path if not the same as model_name")
parser.add_argument("--tokenizer_name", default="", type=str,
help="Pretrained tokenizer name or path if not the same as model_name")
parser.add_argument("--cache_dir", default="", type=str,
help="Where do you want to store the pre-trained models downloaded from s3")
parser.add_argument("--max_seq_length", default=128, type=int,
help="The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded.")
parser.add_argument("--do_train", action='store_true',
help="Whether to run training.")
parser.add_argument("--do_eval", action='store_true',
help="Whether to run eval on the dev set.")
parser.add_argument("--evaluate_during_training", action='store_true',
help="Rul evaluation during training at each logging step.")
parser.add_argument("--do_lower_case", action='store_true',
help="Set this flag if you are using an uncased model.")
parser.add_argument("--train_batch_size", default=8, type=int,
help="Batch size per GPU/CPU for training.")
parser.add_argument("--eval_batch_size", default=8, type=int,
help="Batch size per GPU/CPU for evaluation.")
parser.add_argument('--gradient_accumulation_steps', type=int, default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.")
parser.add_argument("--learning_rate", default=5e-5, type=float,
help="The initial learning rate for Adam.")
parser.add_argument("--weight_decay", default=0.0, type=float,
help="Weight deay if we apply some.")
parser.add_argument("--adam_epsilon", default=1e-8, type=float,
help="Epsilon for Adam optimizer.")
parser.add_argument("--max_grad_norm", default=1.0, type=float,
help="Max gradient norm.")
parser.add_argument("--num_train_epochs", default=3.0, type=float,
help="Total number of training epochs to perform.")
parser.add_argument("--max_steps", default=-1, type=int,
help="If > 0: set total number of training steps to perform. Override num_train_epochs.")
parser.add_argument("--warmup_steps", default=0, type=int,
help="Linear warmup over warmup_steps.")
parser.add_argument('--logging_steps', type=int, default=500,
help="Log every X updates steps.")
parser.add_argument('--save_steps', type=int, default=500,
help="Save checkpoint every X updates steps.")
parser.add_argument("--eval_all_checkpoints", action='store_true',
help="Evaluate all checkpoints starting with the same prefix as model_name ending and ending with step number")
parser.add_argument('--overwrite_output_dir', action='store_true',
help="Overwrite the content of the output directory")
parser.add_argument('--overwrite_cache', action='store_true',
help="Overwrite the cached training and evaluation sets")
parser.add_argument('--seed', type=int, default=42,
help="random seed for initialization")
parser.add_argument('--do_predict', action='store_true')
parser.add_argument('--checkpoint', type=str, default='checkpoint-1000')
args = parser.parse_args()
if os.path.exists(args.output_dir) and os.listdir(args.output_dir) and args.do_train and not args.overwrite_output_dir:
raise ValueError("Output directory ({}) already exists and is not empty. Use --overwrite_output_dir to overcome.".format(args.output_dir))
args.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Setup logging
logging.basicConfig(format = '%(asctime)s - %(levelname)s - %(name)s - %(message)s',
datefmt = '%m/%d/%Y %H:%M:%S',
level = logging.INFO)
# Set seed
set_seed(args)
# Prepare GLUE task
processor = FaqProcessor()
# Training
if args.do_train:
label_list = processor.get_labels()
num_labels = len(label_list)
config = BertConfig.from_pretrained('bert-base-chinese', cache_dir='./cache_down', num_labels=num_labels)
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese', cache_dir='./cache_down')
#model = BertForSequenceClassification.from_pretrained("./cache_down/pytorch_model.bin", config=config)
model = BertForSequenceClassification.from_pretrained("data_1026_new/output/checkpoint-5000/pytorch_model.bin", config=config)
model.to(args.device)
logger.info("Training/evaluation parameters %s", args)
global_step, tr_loss = train(args, processor, model, tokenizer)
logger.info(" global_step = %s, average loss = %s", global_step, tr_loss)
# Saving best-practices: if you use defaults names for the model, you can reload it using from_pretrained()
if args.do_train :
# Create output directory if needed
if not os.path.exists(args.output_dir) :
os.makedirs(args.output_dir)
logger.info("Saving model checkpoint to %s", args.output_dir)
# Save a trained model, configuration and tokenizer using `save_pretrained()`.
# They can then be reloaded using `from_pretrained()`
model_to_save = model.module if hasattr(model, 'module') else model # Take care of distributed/parallel training
model_to_save.save_pretrained(args.output_dir)
tokenizer.save_pretrained(args.output_dir)
# Good practice: save your training arguments together with the trained model
torch.save(args, os.path.join(args.output_dir, 'training_args.bin'))
# Load a trained model and vocabulary that you have fine-tuned
model = BertForSequenceClassification.from_pretrained(args.output_dir)
tokenizer = BertTokenizer.from_pretrained(args.output_dir, do_lower_case=args.do_lower_case)
model.to(args.device)
# Evaluation
results = {}
if args.do_eval :
# tokenizer = BertTokenizer.from_pretrained(args.output_dir, do_lower_case=args.do_lower_case)
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese', cache_dir='./cache_down')
checkpoints = [args.output_dir]
if args.eval_all_checkpoints:
checkpoints = list(os.path.dirname(c) for c in sorted(glob.glob(args.output_dir + '/**/pytorch_model.bin', recursive=True)))
logging.getLogger("transformers.modeling_utils").setLevel(logging.WARN) # Reduce logging
logger.info("Evaluate the following checkpoints: %s", checkpoints)
print(checkpoints)
for checkpoint in checkpoints:
print(checkpoint)
global_step = checkpoint.split('-')[-1] if len(checkpoints) > 1 else ""
model = BertForSequenceClassification.from_pretrained(checkpoint)#, config=checkpoint+'/config.json')
model.to(args.device)
result = evaluate(args,processor, model, tokenizer, prefix=global_step)
result = dict((k + '_{}'.format(global_step), v) for k, v in result.items())
results.update(result)
if args.do_predict:
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese', cache_dir='./cache_down')
model = BertForSequenceClassification.from_pretrained(os.path.join(args.output_dir, args.checkpoint))
model.to(args.device)
tilte = ['请问有适合新手的理财方案吗?']
# replies = processor.prepare_replies(os.path.join(args.data_dir, 'train.csv'))
replies = ['这个要根据你理财的初始金额和能接受的浮动范围来定制理财方案, 比如,你有10万用于理财, 不可以接受本金亏损,那么推荐你使用银行的定期理财',
'如果是招行卡,退款一般是3-5个工作日。',
'欢迎通过招行渠道理财,目前招行个人投资理财方式较多:定期、国债、受托理财、基金、黄金等做组合', '房贷利率低',
'欢迎通过招行渠道理财,父母多大年龄',
'密码输入次数超过4次 账户被锁住',
'《征信业管理条例》规定:征信机构对个人不良信息的保存期限,自不良行为或者事件终止之日起为5年',
'推荐理财网站,可以学习各个方面的理财知识',
'新手可以尝试银行的定期理财']
examples = processor._create_one_example(tilte, replies)
features = convert_one_example_to_features(examples, tokenizer)
# Convert to Tensors and build dataset
all_input_ids = torch.tensor([f.input_ids for f in features], dtype=torch.long)
all_attention_mask = torch.tensor([f.attention_mask for f in features], dtype=torch.long)
all_token_type_ids = torch.tensor([f.token_type_ids for f in features], dtype=torch.long)
with torch.no_grad():
inputs = {'input_ids': all_input_ids.to(args.device),
'attention_mask': all_attention_mask.to(args.device),
'token_type_ids': all_token_type_ids.to(args.device)}
outputs = model(**inputs)
logits = outputs[0]
score = F.softmax(logits,dim=1)
print(score)
values,index = score.sort(0,descending=True)
recommend_answers = []
for i in range(values.shape[0]):
if values[i][1] > 0.9 and len(recommend_answers) < 5:
recommend_answers.append(replies[index[i][1]])
print('\nQuestion: ', tilte[0] + '\n')
print('\nAll answers for predicts: \n')
for rep in replies:
print('\t'+ rep + '\n')
# print('Recommend answer:', replies[index[0][1]], '\n')
if len(recommend_answers) == 0:
print('No recommend answers!')
else:
print('Recommend_answers: \n')
for i in recommend_answers:
print('\t' + i + '\n')
def train_test_split(datafile, test_size=None, random_seed=None):
if test_size==None:
test_size = 0.3
if random_seed==None:
random_seed = 7
## 读取数据
df = pd.read_csv(datafile)
df = df.fillna(0)
np.random.seed(random_seed)
indices = np.random.permutation(len(df))
cut = int(len(df) * (1-test_size))
train = df.iloc[indices[:cut]]
test = df.iloc[indices[cut:]]
return train, test
def train_test_read(train, test):
train_df = pd.read_csv(train,encoding='UTF-8-SIG')
test_df = pd.read_csv(test,encoding='UTF-8-SIG')
train_df.to_csv('data_fin_new/train.csv',index=False)
test_df.to_csv('data_fin_new/test.csv',index=False)
if __name__ == "__main__":
main()
6. 模型网页部署源码
import flask
from flask import Flask, render_template, session, request, redirect, url_for,jsonify
# from app import app
import argparse
import glob
import logging
import os
import random
import numpy as np
import torch
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler,TensorDataset
from torch.utils.data.distributed import DistributedSampler
from tensorboardX import SummaryWriter
from tqdm import tqdm, trange
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler, TensorDataset
from transformers import AdamW, WarmupLinearSchedule
from transformers import WEIGHTS_NAME, BertConfig, BertForSequenceClassification, BertTokenizer
from transformers.data.processors.utils import DataProcessor, InputExample,InputFeatures
import pandas as pd
import torch.nn.functional as F
from scipy.stats import pearsonr, spearmanr
from sklearn.metrics import matthews_corrcoef, f1_score
from sklearn.feature_extraction.text import TfidfVectorizer
import numpy as np
from scipy.linalg import norm
logger = logging.getLogger(__name__)
def convert_one_example_to_features(examples, tokenizer, max_length=512, pad_token=0, pad_token_segment_id=0, mask_padding_with_zero=True):
features = []
for (ex_index, example) in enumerate(examples):
inputs = tokenizer.encode_plus(
example.text_a,
example.text_b,
add_special_tokens=True,
max_length=max_length,
truncate_first_sequence=False # We're truncating the first sequence in priority
)
input_ids, token_type_ids = inputs["input_ids"], inputs["token_type_ids"]
attention_mask = [1 if mask_padding_with_zero else 0] * len(input_ids)
padding_length = max_length - len(input_ids)
input_ids = input_ids + ([pad_token] * padding_length)
attention_mask = attention_mask + ([0 if mask_padding_with_zero else 1] * padding_length)
token_type_ids = token_type_ids + ([pad_token_segment_id] * padding_length)
assert len(input_ids) == max_length, "Error with input length {} vs {}".format(len(input_ids), max_length)
assert len(attention_mask) == max_length, "Error with input length {} vs {}".format(len(attention_mask), max_length)
assert len(token_type_ids) == max_length, "Error with input length {} vs {}".format(len(token_type_ids), max_length)
features.append(
InputFeatures(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
label=None))
return features
class FaqProcessor(DataProcessor):
def _create_one_example(self, title, replies):
examples = []
num_examples = len(replies)
for i in range(num_examples):
examples.append(InputExample(guid=i, text_a=str(title), text_b=str(replies[i]), label=None))
return examples
def prepare_replies(self, path):
df = pd.read_csv(path)
df = df.fillna(0)
replies = [str(t) for t in df['reply'].tolist()]
return replies
def getSimiTitleAnswers(new_title, all_title, total_df):
def tfidf_similarity(s1, s2):
def add_space(s):
return ' '.join(list(s))
# 将字中间加入空格
s1, s2 = add_space(s1), add_space(s2)
# 转化为TF矩阵
cv = TfidfVectorizer(tokenizer=lambda s: s.split())
corpus = [s1, s2]
vectors = cv.fit_transform(corpus).toarray()
# 计算TF系数
return np.dot(vectors[0], vectors[1]) / (norm(vectors[0]) * norm(vectors[1]))
sim_reply = []
for tt in all_title:
if tfidf_similarity(tt, new_title) > 0.5:
print('sim title:', tt + '\n')
tt_replies = total_df[total_df.best_title==tt].reply.tolist()
if len(tt_replies) > 1:
for i in tt_replies:
if i not in sim_reply:
sim_reply.append(i)
else:
if tt_replies not in sim_reply:
sim_reply.extend(tt_replies)
return sim_reply
def predict(title, replies, tokenizer, model, device):
processor = FaqProcessor()
examples = processor._create_one_example(title, replies)
features = convert_one_example_to_features(examples, tokenizer)
# Convert to Tensors and build dataset
all_input_ids = torch.tensor([f.input_ids for f in features], dtype=torch.long)
all_attention_mask = torch.tensor([f.attention_mask for f in features], dtype=torch.long)
all_token_type_ids = torch.tensor([f.token_type_ids for f in features], dtype=torch.long)
with torch.no_grad():
inputs = {'input_ids': all_input_ids.to(device),
'attention_mask': all_attention_mask.to(device),
'token_type_ids': all_token_type_ids.to(device)}
outputs = model(**inputs)
logits = outputs[0]
score = F.softmax(logits,dim=1)
print(score)
values,index = score.sort(0,descending=True)
recommend_answers = []
for i in range(values.shape[0]):
if values[i][1] > 0.9 and len(recommend_answers) < 5:
recommend_answers.append(replies[index[i][1]])
print('\nQuestion: ', title + '\n')
print('\nAll answers for predicts: \n')
for rep in replies:
print('\t'+ rep + '\n')
if len(recommend_answers) == 0:
print('No recommend answers!')
else:
print('Recommend_answers: \n')
for i in recommend_answers:
print('\t' + i + '\n')
#ret_str = '
'.join(recommend_answers)
return recommend_answers
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = BertForSequenceClassification.from_pretrained(os.path.join('data_1026_new','output3', 'checkpoint-18000'))
model.eval()
model.to(device)
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese', cache_dir='./cache_down')
train_df = pd.read_csv('data_1026_new/train.csv', encoding='utf-8-sig',sep='\t')[['best_title','is_best','reply']]
test_df = pd.read_csv('data_1026_new/test.csv', encoding='utf-8-sig',sep='\t')[['best_title','is_best','reply']]
total_df = pd.concat([train_df[train_df.is_best == 1], test_df[test_df.is_best==1]], axis=0)[['best_title','is_best','reply']]
print(total_df.iloc[-2:-1,:])
all_title = total_df.best_title.drop_duplicates().tolist()
app = Flask(__name__)
app.secret_key = 'F12Zr47j\3yX R~X@H!jLwf/T'
@app.route("/")
def hello_world():
return render_template('FQA.html')
@app.route('/fqa', methods=['GET'])
def fqa():
while request.args.get('title'):
title = str(request.args.get('title'))
if request.args.get('replies'): ## 如果有备选答案 则进行切分
replies = request.args.get('replies').split('\r\n')
else:## 如果没有备选答案,则根据问题文本相似度查找与title相似的问题,找到这些问题对应的正确答案.
replies = getSimiTitleAnswers(title, all_title, total_df)
print(title)
print(replies)
if len(replies) == 0:
return render_template('FQA.html', message='No answers recommend!')
ret = predict(title, replies, tokenizer, model, device)
print(ret)
return render_template('FQA.html', message=ret, title=title, replies=replies)
else:
return render_template('FQA.html')
if __name__ == '__main__':
app.run(port=5000, debug=True)
FQA.html 源码
<!DOCTYPE html>
<html>
<head>
<style>
#header {
background-color:black;
color:white;
text-align:center;
padding:5px;
}
#nav {
line-height:30px;
background-color:#eeeeee;
height:300px;
width:100px;
float:left;
padding:5px;
}
#section {
width:350px;
float:left;
padding:10px;
}
#footer {
background-color:black;
color:white;
clear:both;
text-align:center;
padding:5px;
}
</style>
</head>
<body>
<div id="header">
<h1>金融问答系统</h1>
</div>
<br />
<form>
<h4>请输入你的问题:</h4>
{% if title %}
<textarea type="text" name="title" style="height:50px;width:820px;">{{title}}</textarea>
{% else %}
<textarea type="text" name="title" style="height:50px;width:820px;"></textarea>
{% endif %}
<br />
<h4>请输入备选答案:</h4>
{% if replies %}
<textarea type="text" name="replies" style="height:300px;width:820px;" >{{replies}}</textarea>
{% else %}
<textarea type="text" name="replies" style="height:300px;width:820px;" ></textarea>
{% endif %}
<br />
<input type="submit" value="Submit" />
</form>
{% if message %}
<br />
<h4>FQA 推荐答案:</h4>
<p style="color:blue">{{ message }}</p>
{% endif %}
<br />
<div id="footer">
Copyright 金融FQA
</div>
</body>
</html>