克服bilibili登录反爬虫障碍
克服bilibili登录反爬虫障碍
- 目标网站分析
- 开发工具
- 操作过程
目标网站分析
1、网站名称:哔哩哔哩官网 (URL:https://www.bilibili.com/)
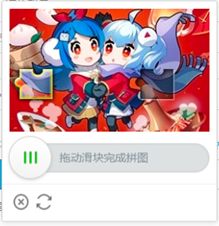
2、反爬虫技术:滑动验证码
开发工具
1、开发语言:
- python
2、使用的模块,工具
-
模块:Selenium、lxml、PIL、time、re、requests、urllib、bs4、json、pandas
-
工具:chromedriver.exe、chrome浏览器、jupyter notebook、Anaconda
操作过程
1、爬取目标
- 模拟登录B站,即完成输入用户名、密码、破解滑动滑块三个操作 URL:
https://passport.bilibili.com/login
2、工作思路
(1)实例化webdriver.Chrome对象,用于自动化操作电脑里的谷歌浏览器;
(2)输入用户名密码点击登陆;
(3)获取验证码的原始图片与有缺口的图片;
(4)找出两张图片的缺口起始处的距离之差;
(5)模拟滑块运动轨迹并拖动滑块;
3、操作步骤以及源码分析
(1)安装实验相关模板
-
python命令
pip install +模板名称 -
模板
Selenium、lxml、PIL、time、re、requests、urllib、bs4、json、pandas
(2)安装并配置Chromedriver
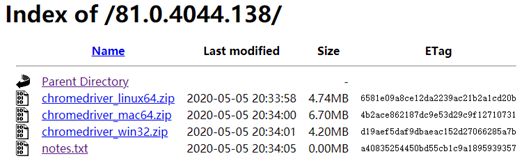
a) 查看Chrome浏览器的版本:为81.0.4044.138
在谷歌浏览器右上角的,设置->关于 Chrome中

b) 下载和Chrome浏览器版本对应的Chromedriver,驱动器不分32位还是64位,所以下载win32即可。
下载地址为http://chromedriver.storage.googleapis.com/index.html
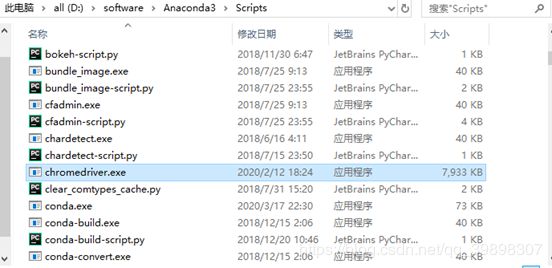
c) 解压压缩包,找到chromedriver.exe复制到Anaconda\Scripts的安装目录下
d) 将chromedriver.exe文件的路径并加入到电脑的环境变量中去
(3)自动登录B站,破解反爬技术
a) 初始化一些信息
包括滑块的起始位置、B站的登录网址、实例化一个webdriver.Chrome对象、让Chrome浏览器窗口最大化显示(保证截图可以时是100%显示,精确计算缺口位置)、设置等待时间(等待页面加载完全)、设置B站的登录账号和密码。
def __init__(self): # 初始化一些信息
self.left = 60 # 定义一个左边的起点 缺口一般离图片左侧有一定的距离 有一个滑块
self.url = 'https://passport.bilibili.com/login'
self.driver = webdriver.Chrome('chromedriver')
self.driver.maximize_window()
self.wait = WebDriverWait(self.driver, 20) # 设置等待
self.username = "****"
self.password = "****"
b) Selenium模拟人操作,输入用户名和密码
自动访问一下B站的登录界面,自动填充一下用户名和密码,其中用户名和密码的输入框都直接用ID来定位,通过查看网页源码,找到账号,密码输入框的id分别为login-username、login-passwd。填写账号、密码信息时,直接调用send_keys方法就可以。
登陆界面:
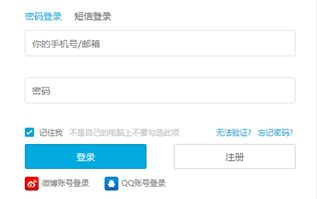
右键单击,检查,查看网页源码

这个步骤对应的源码如下:
def input_name_password(self): # 输入用户名和密码
self.driver.get(self.url)
self.user = self.wait.until(EC.presence_of_element_located((By.ID, 'login-username')))
self.passwd = self.wait.until(EC.presence_of_element_located((By.ID, 'login-passwd')))
self.user.send_keys(self.username)
self.passwd.send_keys(self.password)
c) 点击登录按钮
填写完信息,点击登录按钮,此处使用class_name来定位登录按钮,查看网页源码,类名是:btn-login,调用click()函数点击按钮,并等待验证码弹出,此处之所以sleep,是为了保证验证码可以顺利弹出。
登录按钮对应源码:
![]()
源码如下:
def click_login_button(self): # 点击登录按钮,出现验证码图片
login_button = self.wait.until(EC.element_to_be_clickable((By.CLASS_NAME, 'btn-login')))
login_button.click()
sleep(1)
self.wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'geetest_refresh_1'))).click()
sleep(1)
d) 获取图片验证码
通过截图的方式获取两张验证码图片,一张带缺口一张不带缺口,其中获取带缺口的图片,直接通过样式定位即可“geetest_canvas_bg”,并将截图保存
#获取带缺口的图片1 geetest_canvas_bg
gapimg = self.wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'geetest_canvas_bg')))
# sleep(2)
gapimg.screenshot(r'./captcha1.png') # 将class为geetest_canvas_bg的区域截屏保存
保存的截图如下:

通过js代码修改标签样式 显示验证码原图(不带缺口),并截图 geetest_canvas_fullbg保存。
# 通过js代码修改标签样式 显示图片2并截图 geetest_canvas_fullbg
js = 'var change = document.getElementsByClassName("geetest_canvas_fullbg");change[0].style = "display:block;"'
self.driver.execute_script(js)
# sleep(2)
fullimg = self.wait.until(
EC.presence_of_element_located((By.CLASS_NAME, 'geetest_canvas_fullbg')))
fullimg.screenshot(r'./captcha2.png') # 将class为geetest_canvas_fullbg的区域截屏保存

e) 获取缺口图起点
通过比较两张图的像素矩阵从而获得缺口坐标,像素不同的位置也就是缺口位置,判断两张截图的像素是否相同的代码如下:
def is_similar(self, image1, image2, x, y): #判断两张图片,各个位置的像素是否相同
'''判断两张图片 各个位置的像素是否相同
#image1:带缺口的图片
:param image2: 不带缺口的图片
:param x: 位置x
:param y: 位置y
:return: (x,y)位置的像素是否相同
'''
# 获取两张图片指定位置的像素点
pixel1 = image1.load()[x, y]
pixel2 = image2.load()[x, y]
# 设置一个阈值 允许有误差
threshold = 60
# 彩色图 每个位置的像素点有三个通道
if abs(pixel1[0] - pixel2[0]) < threshold and abs(pixel1[1] - pixel2[1]) < threshold and abs(
pixel1[2] - pixel2[2]) < threshold:
return True
else:
return False
如果通过循环,遍历像素矩阵,若不相同,就返回缺口的左侧边界的位置,也就是在x方向的位置。
def get_diff_location(self): # 获取缺口图起点,找到缺口的左侧边界 在x方向上的位置
captcha1 = Image.open('captcha1.png')
captcha2 = Image.open('captcha2.png')
for x in range(self.left, captcha1.size[0]): # 从左到右 x方向
for y in range(captcha1.size[1]): # 从上到下 y方向
if not self.is_similar(captcha1, captcha2, x, y):
return x # 找到缺口的左侧边界 在x方向上的位置
f) 移动滑块
使用样式定位滑块,调用click_and_hold()方法来滑动滑块,这里为了不让网站识别出是机器操作,因此需要休眠。
def move_slider(self, track):# 移动滑块完成登录
slider = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.geetest_slider_button')))
ActionChains(self.driver).click_and_hold(slider).perform()
sleep(0.5)
ActionChains(self.driver).move_by_offset(xoffset=0.70*track, yoffset=0).perform()
sleep(0.5)
ActionChains(self.driver).move_by_offset(xoffset=0.30*track, yoffset=0).perform()
sleep(0.5) #0.70和0.30可以是其他随意数值,也可以生成随机数
ActionChains(self.driver).release().perform() # 松开鼠标
g) 主函数
在计算出缺口位置后,还要间去滑块左侧距离图片的距离,即8,计算出来的才是滑块移动距离。
def main(self):
self.input_name_password()#输入用户名密码
self.click_login_button()#点击登录
self.get_geetest_image()# 通过截图的方式获取两张验证码图片,一张带缺口一张不带缺口
gap = self.get_diff_location() # 计算缺口左起点位置 , 获取缺口图起点,找到缺口的左侧边界 在x方向上的位置
gap = gap - 8 # 减去滑块左侧距离图片左侧在x方向上的距离 即为滑块实际要移动的距离
self.move_slider(gap)# 根据轨迹移动滑块完成登录
成功登录B站