学习爬虫之网页解析_beautifulsoup和xpath文档学习(five day)
1.BeautifulSoup
**BeautifulSoup 是一个可以从HTML或XML文件中提取数据的Python库,**它的使用方式相对于正则来说更加的简单方便,常常能够节省我们大量的时间。(cmd命令pipinstall beautifulsoup4即可)
官方中文文档的:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
注意:使用BeautifulSoup需要指定解析器
BeautifulSoup解析网页需要指定一个可用的解析器,以下是主要几种解析器:
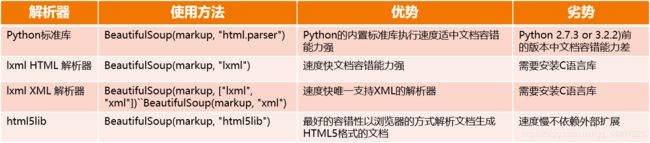 由于这个解析的过程在大规模的爬取中是会影响到整个爬虫系统的速度的,所以推荐使用的是lxml,速度会快很多,而lxml需要单独安装:
由于这个解析的过程在大规模的爬取中是会影响到整个爬虫系统的速度的,所以推荐使用的是lxml,速度会快很多,而lxml需要单独安装:
pip install lxml
soup = BeautifulSoup(html_doc, 'lxml') # 指定
提示:如果一段HTML或XML文档格式不正确的话,那么在不同的解析器中返回的结果可能是不一样的,所以要指定某一个解析器。
(1)代码演示使用:
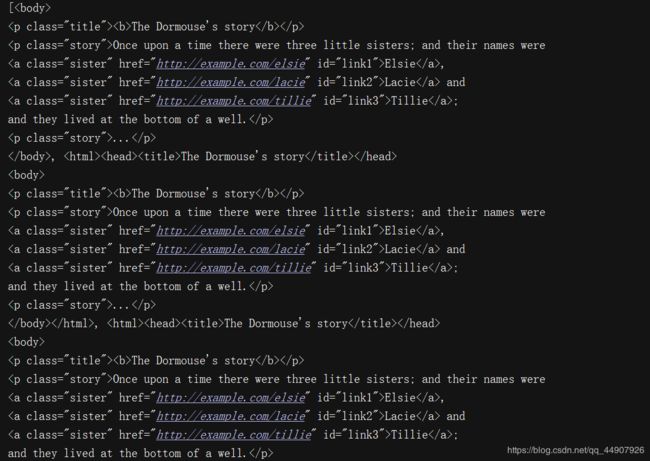
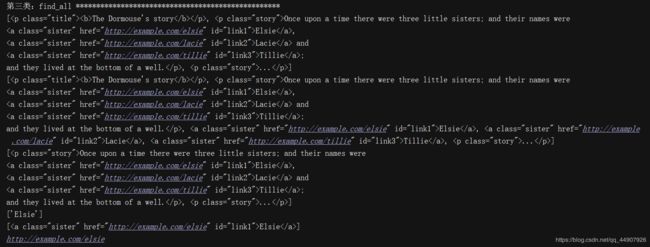
html_doc = """
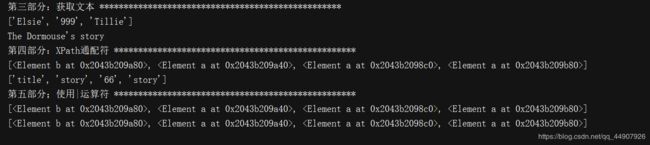
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
from bs4 import BeautifulSoup
# 使用BeautifulSoup解析上述代码,能够得到一个 BeautifulSoup 的对象
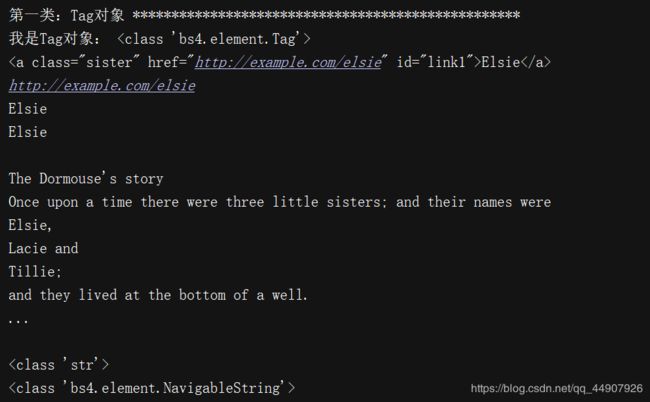
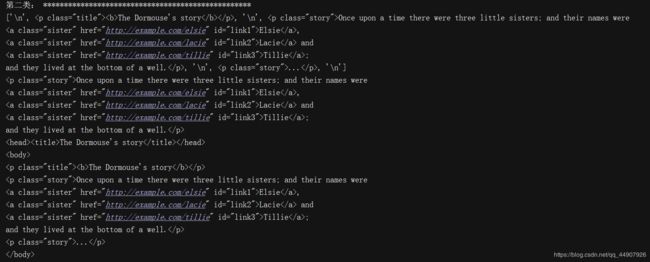
soup = BeautifulSoup(html_doc,"lxml") #将html转化为可操作的对象
# print(type(soup)) #输出:(2)代码输出:



2.XPath(路径表达式)
简介:
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。
相比于BeautifulSoup,Xpath在提取数据时会更有效率。
安装:
在python中很多库都提供XPath的功能,但是最流行的还是lxml这个库,效率最高。(直接pip install lxml 即可)
(1)代码演示简单使用:
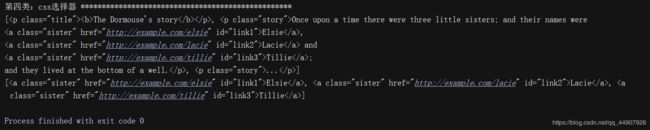
html_doc = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
999 and
Tillie;
and they lived at the bottom of a well.
...
"""
from lxml import etree #原理和beautiful一样,都是将html字符串转换为我们易于处理的标签对象
page = etree.HTML(html_doc) #返回了html节点
print(type(page)) #输出为:(2)代码输出: