吴恩达深度学习 | (6) 神经网络与深度学习专项课程第四周学习笔记
课程视频
课程PPT
吴恩达深度学习专项课程共分为五个部分,本篇博客将介绍第一部分神经网络和深度学习专项的第四周课程:深层神经网络,深层指的是多隐藏层神经网络。截止目前我们已经学习了单隐层神经网络和逻辑回归的前向/反向传播,向量化以及随机初始化参数的重要性等内容。本周我们会把之前学的内容组合起来,构建深层神经网络。
目录
1.深层神经网络
2.深层网络中的前向传播
3.核对矩阵的维数
4.为什么使用深层表示
5.搭建深层神经网络块
6.前向和反向传播
7.参数 VS 超参数
8.这和大脑有什么关系
1.深层神经网络
- 什么是深层神经网络
首先回顾一下之前学习的逻辑回归模型和单隐层神经网络:

这两个模型都属于浅层模型,逻辑回归可以看作是一个单层神经网络,单隐层神经网络是一个双层神经网络。注意我们在计算神经网络层数时只考虑隐层和输出层。
所谓深层神经网络指的是多隐层神经网络(隐层数>=2):

上图中的两个例子都属于深层神经网络,分别有两个和五个隐层。
深层神经网络的引入可以使我们学到更多复杂有趣的函数或特征,但是也增加了一个需要设置的超参数:隐层的数量。在实际使用中,可以先从浅层模型做起,不断调整隐层的数量,在预留的交叉验证集上观察效果,以选择最优的隐层数量。
- 深层神经网络的符号表示
| 符号 | 含义 |
 |
神经网络层数(不包括输入层,输入层是第0层) |
![n^{[l]}](http://img.e-com-net.com/image/info8/65a4e4299ef245928a1c2daf2b0ca52c.gif) |
第l层的单元数 |
![z^{[l]}](http://img.e-com-net.com/image/info8/c386d828fe624bc9ba863d3fa68f7392.gif) |
单个样本第l层的中间结果(线性组合) (,1) |
![a^{[l]}](http://img.e-com-net.com/image/info8/e01bd3307ef24324a923be9ac0f160b7.gif) |
单个样本第l层的激活输出. ,1) |
|
|
单个样本的输入特征向量(列向量) |
 |
单个样本输出层的预测值 =![a^{[L]}](http://img.e-com-net.com/image/info8/7a5f951053ab4edd80d59cfc582a3edd.gif) . . |
 |
输入特征向量的维数 |
![Z^{[l]}](http://img.e-com-net.com/image/info8/2d5b1db694a04c49a9a4f2e77c56437e.gif) |
m个样本第l层的中间结果(线性组合) (,m) 每一列是 |
![A^{[l]}](http://img.e-com-net.com/image/info8/f86f1b6b129b46758e7c96e86b678e0f.gif) |
m个样本第l层的激活输出 (,m) 每一列是 |
| m个样本输出层的预测值 |
|
 |
m个样本的输入特征矩阵 ( |
![W^{[l]}](http://img.e-com-net.com/image/info8/82ca4e1ef2614230a656d20222e27352.gif) |
第l-1层和第l层之间的权重参数。![(n^{[l]},n^{[l-1]})](http://img.e-com-net.com/image/info8/e0aa087b8bdc439cad8f09b7df8717d6.gif) |
![b^{[l]}](http://img.e-com-net.com/image/info8/acaeef77a1a6493b973c2c7a79fb6b23.gif) |
第l-1层和第l层之间的偏置参数。 |
| 第l层的激活函数 |

输入层:单元数量由输入样本特征向量维数决定
隐层:单元数量可以任意设置
输出层:单元数量取决于目的,如果进行2分类则一个单元,多分类(>2)就多个单元.
如下图所示的深层神经网络:

神经网络有4层,L=4,输入层是第0层;

2.深层网络中的前向传播
- 单个样本的前向传播(向量化)

对于上图的神经网络结构:
对于一般神经网络结构:

- m个样本前向传播(向量化)
对单个样本前向传播的向量进行堆叠,形成相应的矩阵。
对于上图的神经网络结构:

对于一般的神经网络结构:

上述过程在编码中可以表示为一个for循环:

注意:虽然之前讲过在代码中应尽可能避免显式for循环,不过上述情况可以使用显式for循环,因为它无法用向量化代替。
3.核对矩阵的维数
在实现神经网络前向/反向传播时,可以记录每一个步运算前后矩阵或向量的维度,使维度对应起来,确保正确性。
以下图的神经网络结构(L=5)为例进行演示:

- 单个样本的前向传播(向量化)

其他前向传播的公式也可以按上述方法进行矩阵/向量的维度核对,![]() 同维。
同维。
反向传播也有类似的维度核对,因为![]() ,
, ![]() 是同维的,如:
是同维的,如:

- m个样本的前向传播(向量化)

注意在加偏置参数时,要用到Python 中的广播,先把从![]() 扩展为
扩展为![(n^{[l]},m)](http://img.e-com-net.com/image/info8/eca2fa9ecd544ea7a8a23df086c18386.gif) 再运算,相当于为每一列都加上。其他前向传播的公式也可以按上述方法进行矩阵/向量的维度核对,
再运算,相当于为每一列都加上。其他前向传播的公式也可以按上述方法进行矩阵/向量的维度核对,![]() 同维。
同维。
反向传播也有类似的维度核对,因为![]() ,
, ![]() 是同维的,如:
是同维的,如:

4.为什么使用深层表示
为什么深层网络(多隐层神经网络)会有效?本小节给出一些直观解释:
- Intuition about deep representation
首先看一个人脸检测的例子:
输入层是人脸图片的特征,第一个隐层可能做的工作是检测图像的边缘特征(边缘像素点);第二个隐层对第一个隐层检测的边缘特征进行组合,得到一些局部特征,如眼,鼻子等;第三个隐层再对第二个隐层检测的局部特征进行组合,得到全局特征,如人脸。由此,通过深层网络一步步实现从检测简单特征到复杂特征。
这种从简单到复杂的金字塔形的结构也可以用于其他方面,如语音识别:

对于一段原始的语音,第一个隐层可能检测的是一些简单的特征如音调的高低等,第2个隐层检测一些噪声或音位特征,第3个隐层对上一层检测特征进行组合,检测单词特征,接下来的隐层再组合之前检测的特征,得到语段和句子层面的特征。利用深层网络从简单特征到复杂特征,直到可视化语音片段。
- 电路理论和深度学习
另一种为什么使用深层表示的解释是电路理论:
如果你可以用一个“小”(指的是各个隐层的单元数相对较少)的L层的深层神经网络完成一个函数的计算的话,此时也可以用一个单隐层神经网络实现,不过该隐层的单元数相对之前是指数级的。
比如:计算![]()
使用“小”的L层的深层网络:

此时网络的深度是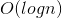 级的,而且每一个隐层的单元数都不算多。
级的,而且每一个隐层的单元数都不算多。
使用单隐层神经网络:

此时,隐层单元数是 级的。
级的。
5.搭建深层神经网络块
- 前向/反向函数
对于一个深层网络,任意取出其中的某一层,得到其前向/反向传播的通式(对于单个样本):

流程图:

- 深层网络前向/反向传播流程图(单个样本)

先前向传播得到![]() ,计算损失函数
,计算损失函数![]() ;再反向传播,先计算出
;再反向传播,先计算出![]() ,在继续利用链式法(以及前向传播中缓存的中间结果
,在继续利用链式法(以及前向传播中缓存的中间结果![]() ,和参数
,和参数![]() )则逐步计算出
)则逐步计算出![]() ,其他层依次进行。
,其他层依次进行。
计算出参数的梯度就可以用梯度下降法更新参数了。
注意在运算过程中缓存每一层中间结果和模型参数,可以使前向/反向传播共享参数,非常方便。
6.前向和反向传播
- 第l层的前向传播

- 第l层的反向传播

- 深层神经网络的前向/反向传播过程
前向传播:
反向传播:

有了初始项和通项,就可以不断循环,实现前向传播计算代价,反向传播计算每层参数的梯度,完成梯度下降,更新参数。
7.参数 VS 超参数
- 什么是超参数
参数:

超参数:
学习率 ; 梯度下降迭代次数;隐层的数量;每个隐层单元的数量;激活函数的选择(ReLU、tanh等)
; 梯度下降迭代次数;隐层的数量;每个隐层单元的数量;激活函数的选择(ReLU、tanh等)
Mometum;mini-batch大小;正则化等(下一专项课程会讲)
超参数就是控制实际参数的参数,超参数的不同取值可以影响模型的实际参数。比如,取不同的学习率,模型最后的学到的参数是不同的。
- 如何选择超参数
应用深度学习的迭代过程:

可以系统的在一定范围内尝试不同的超参数取值,然后训练模型,在预留的(交叉)验证集上查看模型效果(准确率等指标,对于学习率的选择,也可以绘制代价随梯度下降迭代次数的变化曲线进行选择)。重复这个过程直到找到一组合适的超参数取值(在该组超参数的配置下,模型在验证集上的效果最好,然后把预留的验证集和训练集组成一个大训练集,在该组最优的超参数下训练模型,最后在测试集上跑一遍,测试一下效果,作为最后的性能指标。注意深度学习由于数据量比较大, 我们一般不采用交叉验证(即将训练集分为m份,每次取其中m-1份训练,剩下一份验证,对于一组超参数配置,需要训练m次模型,取m次验证的平均效果,作为该组超参数的效果,这样做计算成本太高,在深度学习中我们一般将训练集划分为两部分,一大部分训练,一小部分作为验证集验证))。
在实践过程中,要经常并敢于尝试,时间长了就可以形成一种选择超参数的直觉。
随着深度学习的发展,不存在不变的超参数经验法则,任何一种经验法有可能在一段时间后就不再适用,还是得不断的尝试。
面临许多不同的超参数选择是深度学习的一个难点和不足,相信随着深度学习的发展,这个问题会有改观。
8.这和大脑有什么关系
深度学习和大脑实际上关联不大。

深度学习的出现或许是受大脑的启发,早期会把深度学习和大脑作类比,比如可以把逻辑回归和大脑的单个神经元作类比。但是大脑神经元究竟是怎么学习,怎么优化,是否也会使用梯度下降,反向传播等算法还是使用一种完全不同的原理和算法,这是不得而知的。所以,现在很少把深度学习和大脑作类比。
不过深度学习的出现,确实带来了巨大的改变,在监督学习问题中,他可以学习到一个从![]() 的复杂灵活的函数,在各个领域都有很大作用和影响。
的复杂灵活的函数,在各个领域都有很大作用和影响。
也许未来如果能真的发现大脑的学习算法,那么真正的人工智能就会诞生了。