吴恩达深度学习第二课-第一周笔记及课后编程题
笔记
训练_开发_测试集
小数据时代
训练集/测试集的分配比例大致遵循70% / 30%
或训练集/开发集(或cross validation set)/测试集的分配比例大致遵循60% / 20% / 20%
大数据时代
只要开发集能够确定哪一个算法/模型有更好的表现,测试集能够无偏评估模型的性能,就称赋予了开发集、测试集足够的数据量了;训练集将被赋予更大比重的数据量。如:训练集/开发集/测试集的比率为98% / 2% / 2%
注:
训练集和测试集可以来自不同分布的数据,但开发集和测试集必须要用相同分布的数据。
如果不需要无偏评估模型性能,我们可以只分配训练集和开发集。
偏差与方差 VS 过拟合与欠拟合
偏差(bias)和方差(variance);过拟合(over-fitting)和欠拟合(under-fitting)
情况一:training error大 => high bias,即under-fitting
情况二:training error小且developing error大 => high variance,即over-fitting
注:
以上两种情况均建立在贝叶斯误差(Bayes error)小且训练集和开发集来自相同分布的大前提下才成立。
high bias和high variance可能同时出现
正则化
过拟合出现的原因:
模型太复杂,即隐藏单元过多或层数太多
参数值过大
正则化是避免模型出现high variance即过拟合的有效方法,吴恩达老师的课中主要介绍了以下两种正则化方法。
L2正则化
概述
将原来的损失函数
 , 添加一个Frobenius norm =>
, 添加一个Frobenius norm =>
 ,其中
,其中  表示矩阵W中所有元素的平方和。
表示矩阵W中所有元素的平方和。
注:在添加了Frobenius norm之后,损失函数对W的偏导数也要有相应的变动,即
 原
原
为什么L2正则化可以减少过拟合?
在损失函数中有正则项,当 λ 设置的比较大时,为减小损失,w会相对小甚至近似于零,直观上看是减少了网络中的一些隐藏单元,其实是近似于零的隐藏单元对网络的影响变得很小。
缺点
当 λ 设置过大时,会使模型出现欠拟合的情况,当 λ 设置过小时,减少过拟合的效果又很差。
BUT每个模型都会存在一个中间值(即适当的 λ),使得当前模型既不会过拟合也不会欠拟合。
Dropout正则化
一般只在计算机视觉领域使用。
此知识点要是不懂可以参照课后编程题相关部分进行理解。
General Process
将神经网络完整拷贝,然后对拷贝逐层遍历,并设置消除网络中单元的概率,对每一个单元进行类似抛硬币的操作,当满足消除概率时,将该单元和它的进出线去掉,如此往复,就得到了一个单元数更少即规模更小的更简单的神经网络。
每一个样本随机消除的单元都跟其他样本有所区别,即每一个样本的训练网络是不一样的。
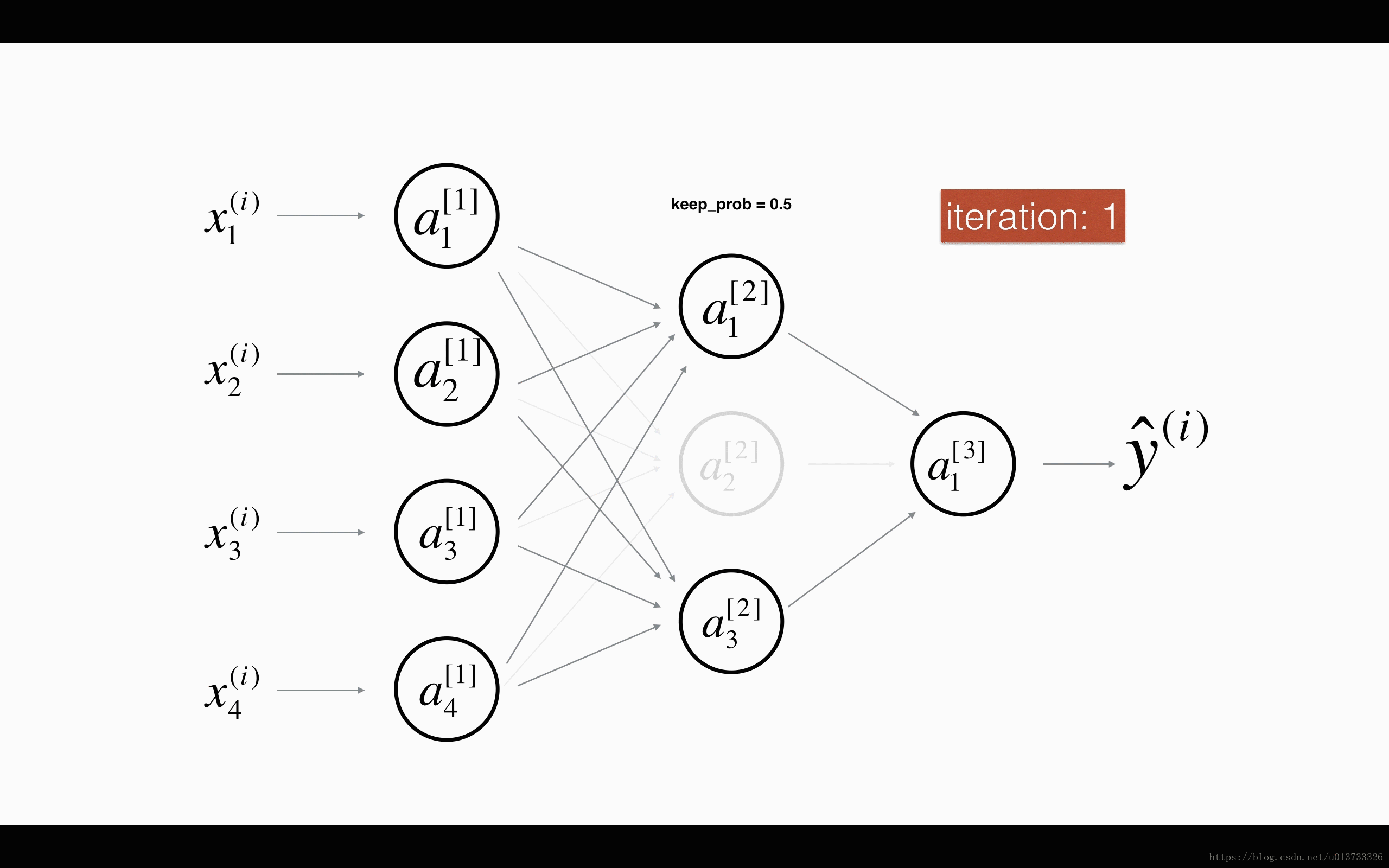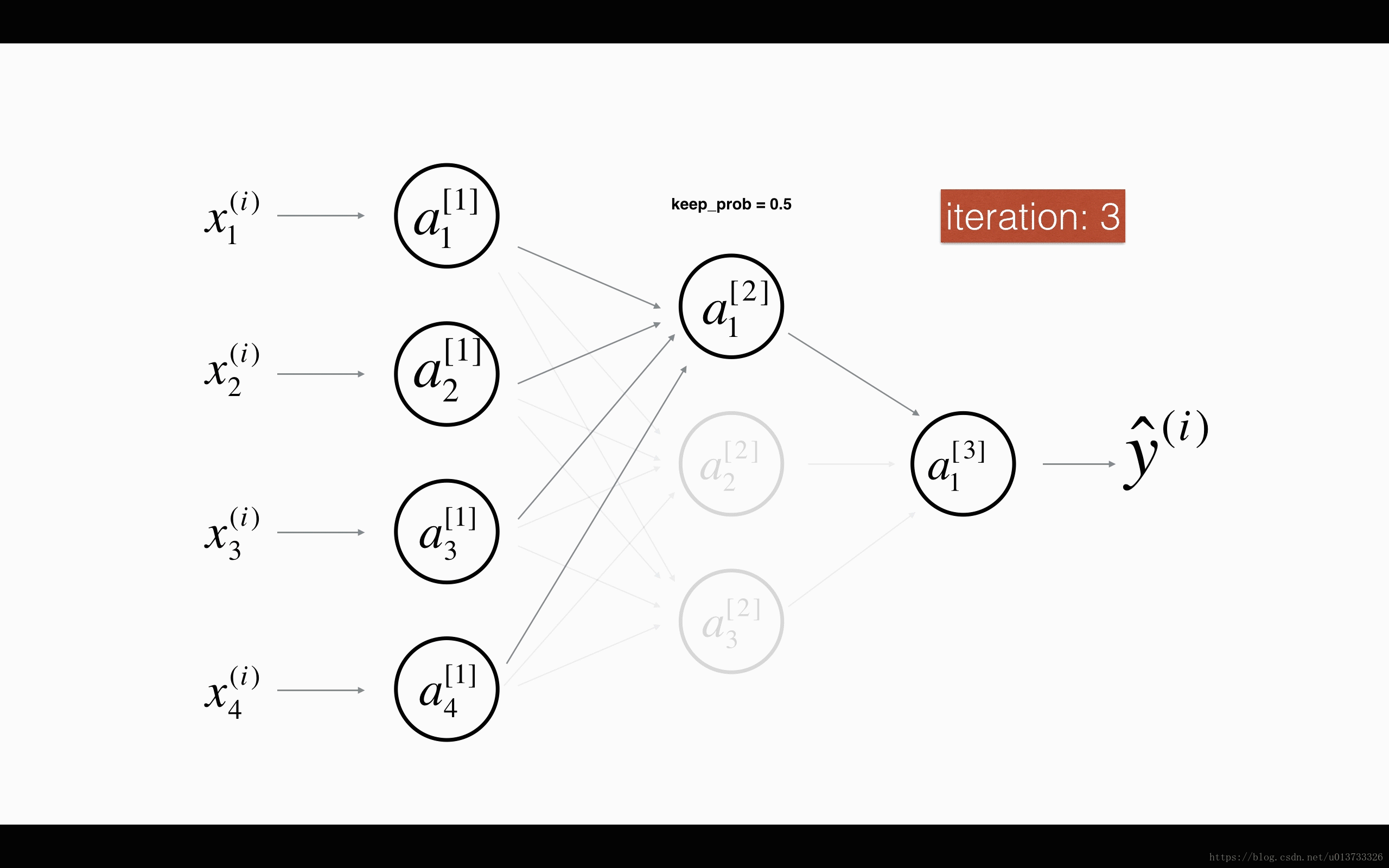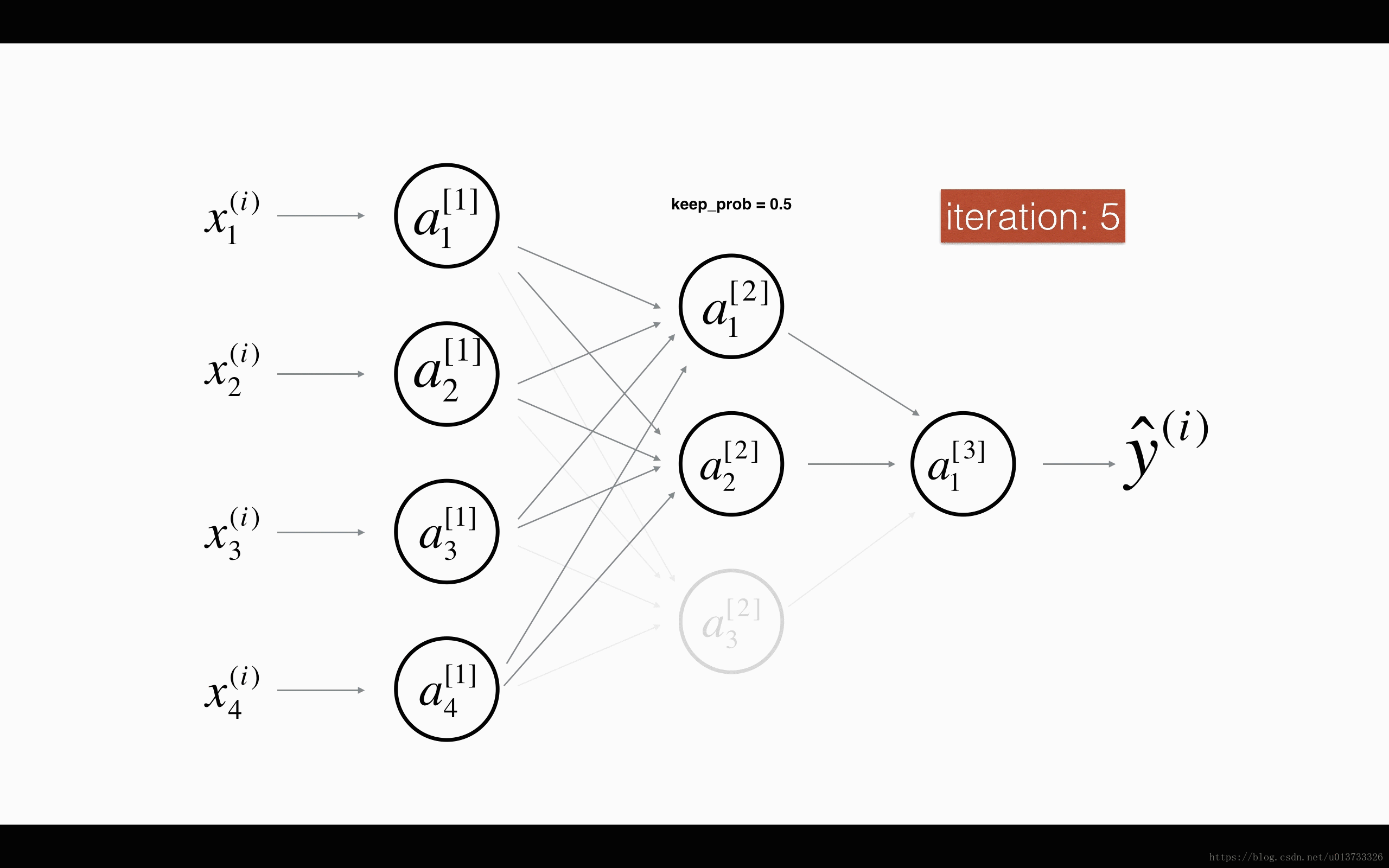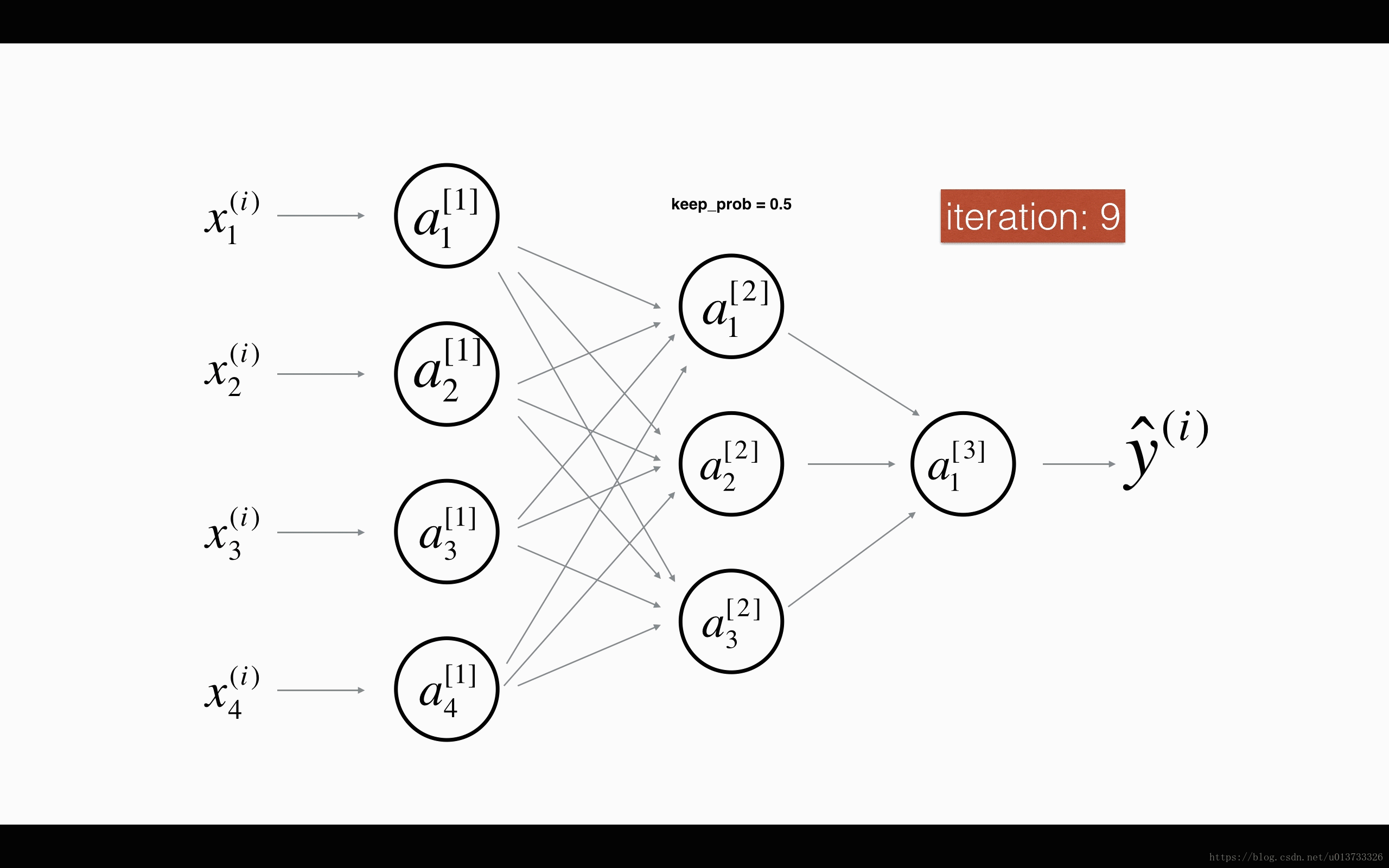
图1 对第二层进行随机消除,保留概率为50%
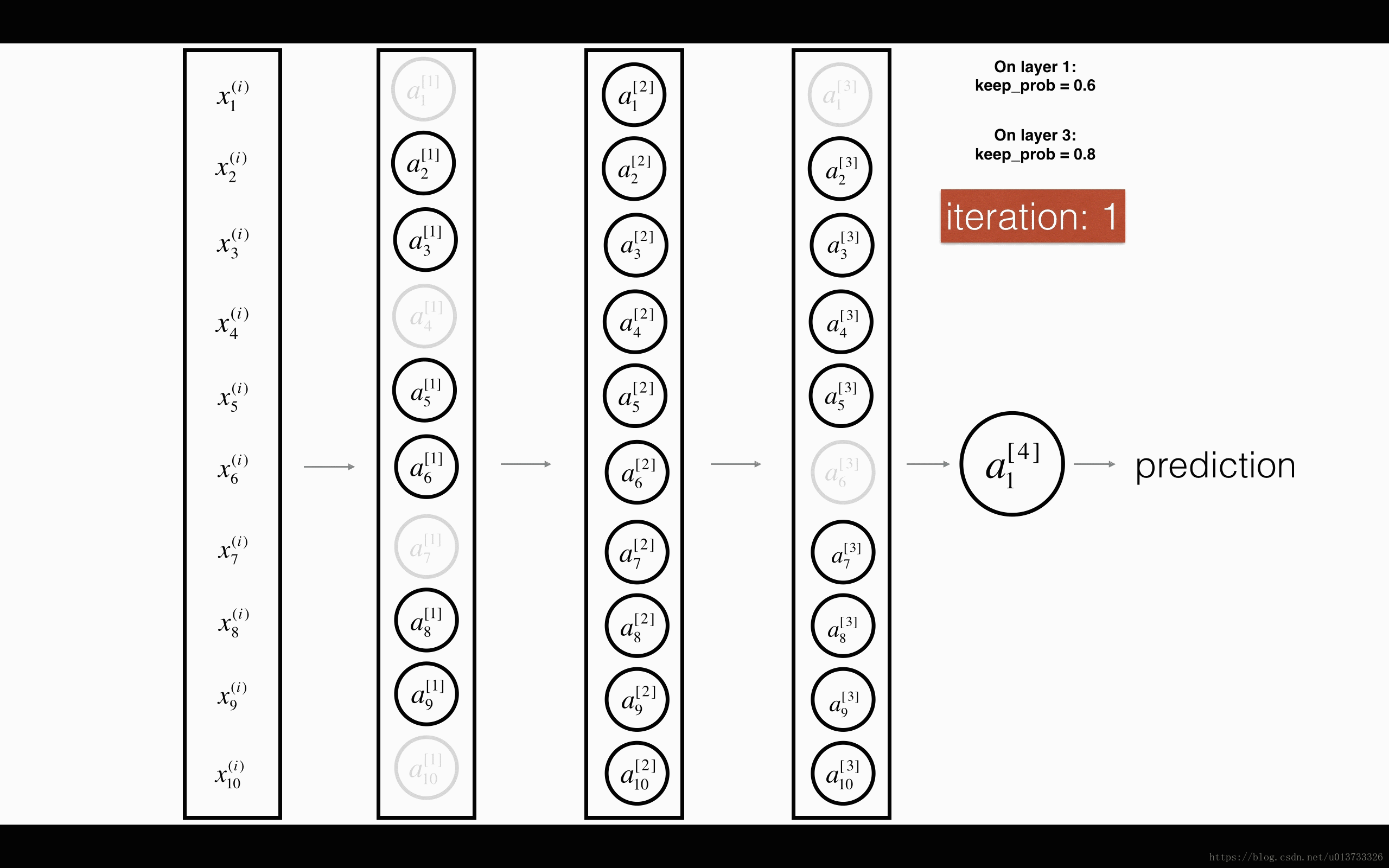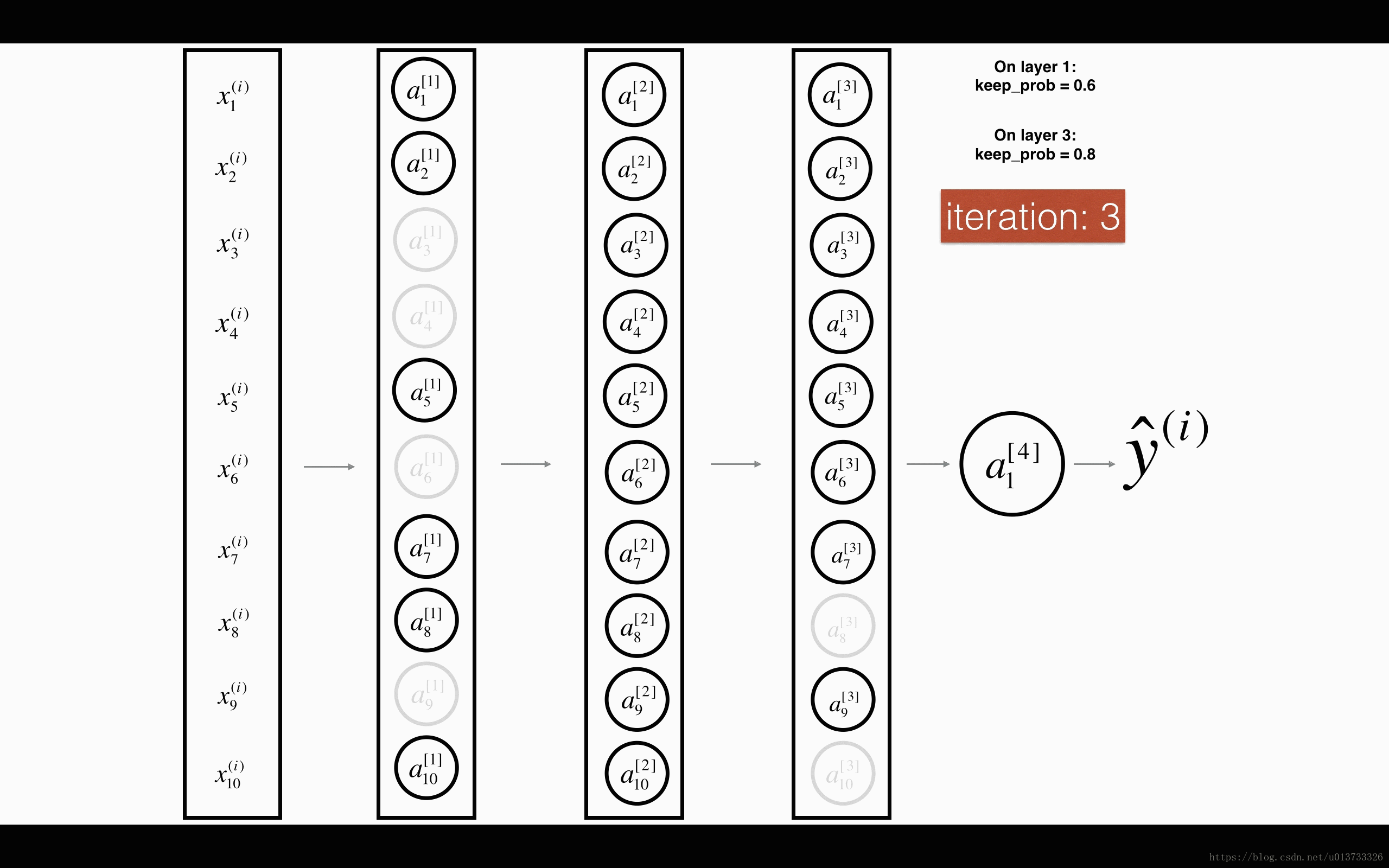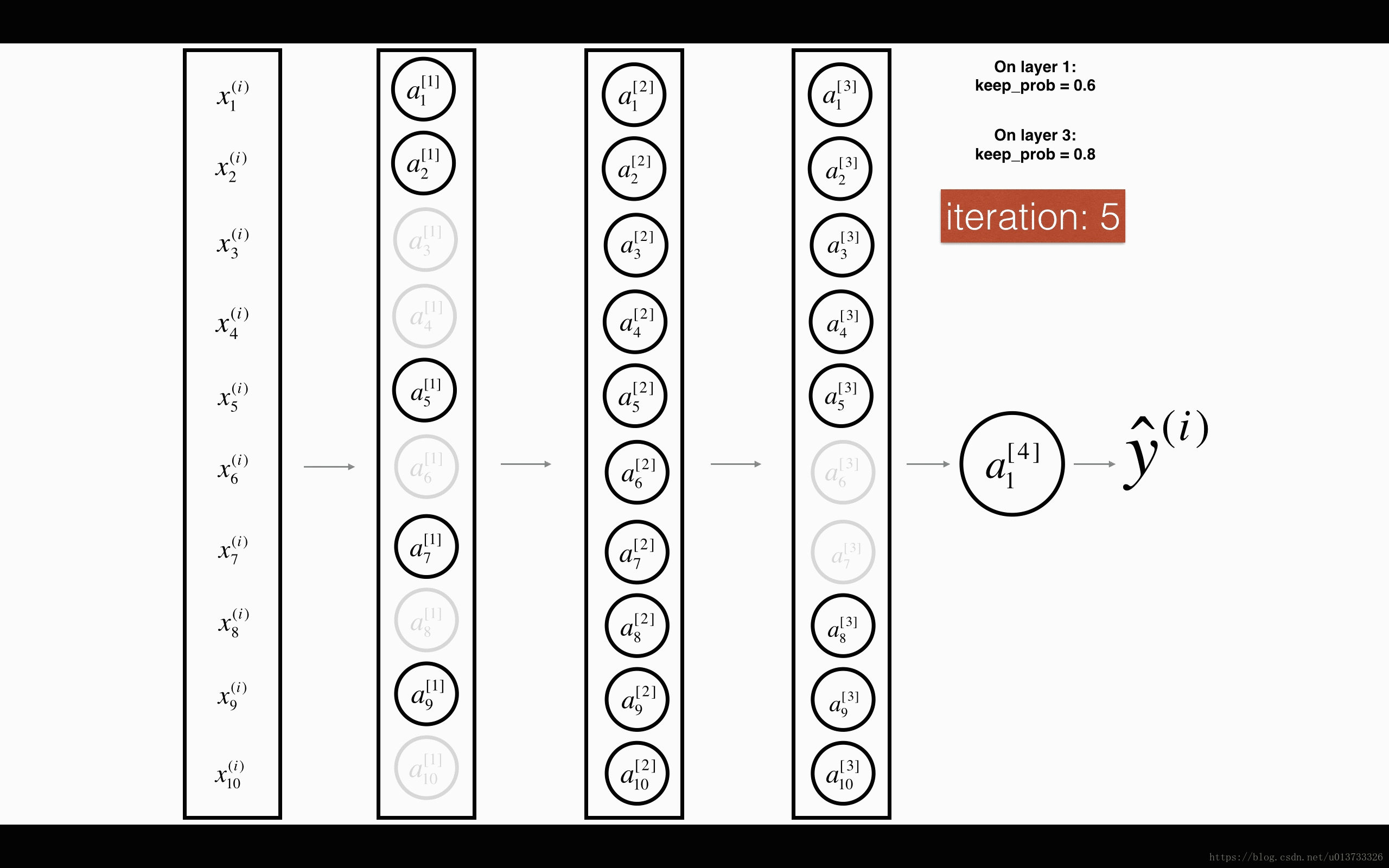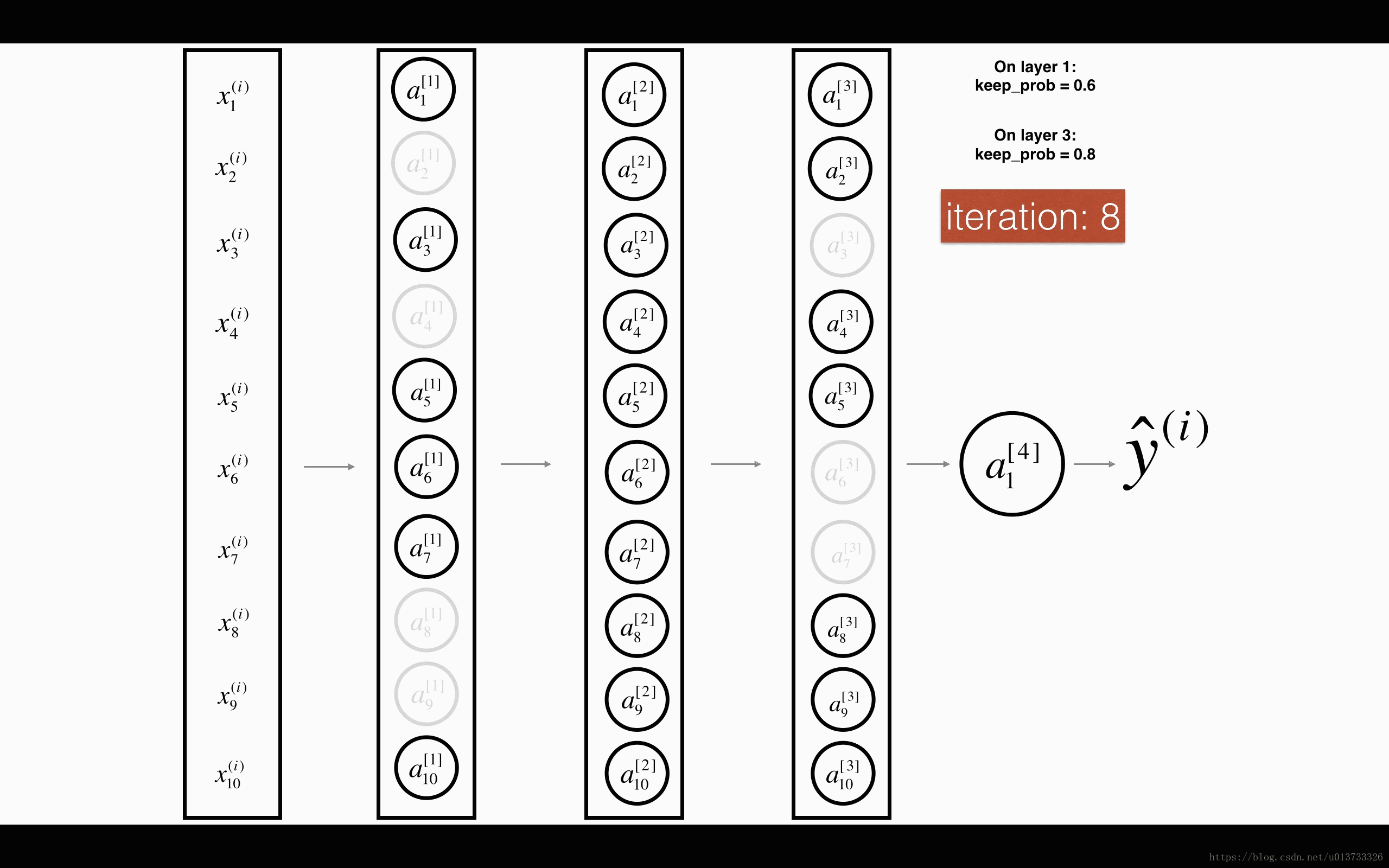
图2 对第一、第三层分别进行随机消除,保留概率分别为60%、80%
Inverted Dropout
假设对网络中的第三隐藏层,即l=3设置一个保留概率keep_prob
设矩阵d3=np.random.rand(a3.shape[0], a3.shape[1]) < keep_prob
(即:矩阵中元素小于keep_prob的被赋值为1,其余元素被赋值为0)
a3 = np.multiply(a3, d3)
(即:对a3进行消除,对应d3位置为0的元素被消除)
a3 = a3 / keep_prob
(关键步骤,保证a3在消除某些单元后仍保持与消除前a3的期望值相同)
为什么Dropout是有效的正则化
每一层中的各个单元,他们被删除的可能性是相同的,所以不能对某一个单元加上过多的权重。
因此对每一个单元都只加少量的权重,这样就可以起到压缩权重的作用。对每一层的keep_prob值也是需要斟酌的,如果觉得某一层更有可能造成过拟合(比如单元数较多的层),我们可以将keep_prob的值设置的小一点,即消除的单元数会更多。
如果不随机消除,在某些局部特征的影响下,前后单元容易产生依赖,这种依赖会随着学习过程逐渐加深,这样就会导致过拟合的发生。
缺点
损失函数不再被明确的定义,因为每次迭代都会消除一些单元,很难检查梯度下降的性能。
减少过拟合的其他方法
数据扩增(Data Augmentation)
增加训练数据是减小过拟合的有效方法。
如在图片识别领域,我们可以人工地对图片进行旋转、放大、缩小,这样就可以得到更多的数据样本。
Early Stopping
在对网络的训练效果进行衡量时,我们通常只会画出iteration-training error曲线图,但是当training error降到很低时,是有极大的概率出现过拟合的,因此我们可以在图中加一条iteration-dev set error曲线,如课程中下图所示:
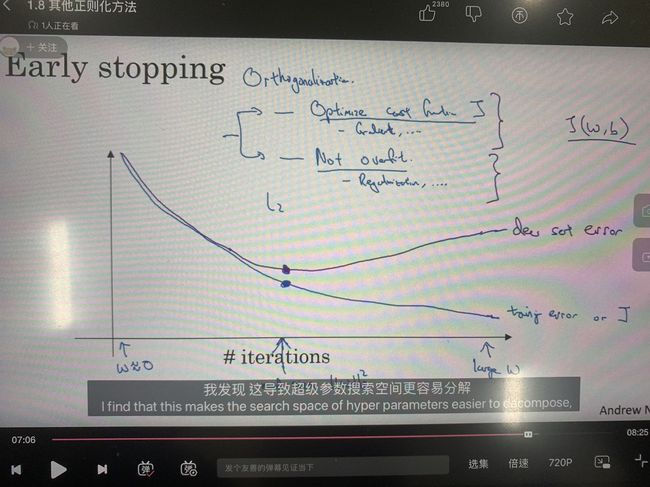
当dev set error的转折点处停止训练,取此时的参数作为最后结果。
Early Stopping可以在一定程度上避免过拟合的发生。
缺点
对机器学习而言,我们要:
优化损失,即减少损失(如使用梯度下降法)
避免过拟合(如使用正则化)
通常两个步骤要用独立的方法分别完成,而Early Stopping是使用一个方法完成两个步骤,即需要进行一个平衡或者说是博弈,这在一定程度上会影响模型的性能。
归一化输入(Normalization)
归一化输入是加速神经网络训练的其中一个方法,步骤如下:
减均值:
 ,
, 
归一化方差:
 ,
, 
经过上述两步后,输入的均值变为0,方差变为1
注:对训练集和测试集要使用相同的 μ 和 σ ,使每个输入特征都在相似的范围内。
梯度消失/爆炸
梯度消失是指梯度以很快的速度(指数级)下降到0
梯度爆炸是指梯度以很快的速度(指数级)上升
为了避免出现以上两种情况,恰当地对权重矩阵(Weights matrix)进行初始化很重要——
当l层的激活函数为ReLU时,通常使用:
Wl = np.random.randn(Al.shape[0], Al.shape[1])*np.sqrt(2/n[l-1]) # 其中n[l-1]指的是上一层的单元数当l层的激活函数为tanh时,通常使用:
Wl = np.random.randn(Al.shape[0], Al.shape[1])*np.sqrt(1/n[l-1]) 这也被成为Xavier initialization.
梯度检验(Grad Check)
基本步骤如下:
for each i:
 (其中,每一个 θ 值是对应下标的W,b压缩组合后的一个向量)
(其中,每一个 θ 值是对应下标的W,b压缩组合后的一个向量)
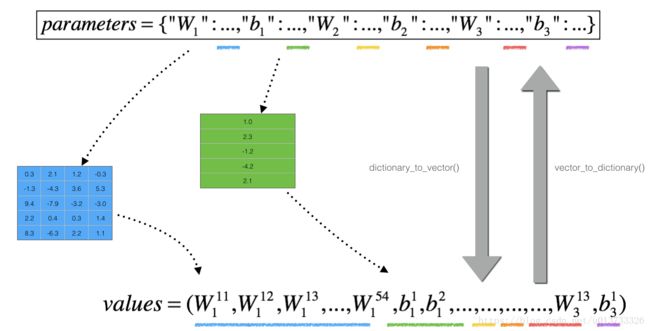
然后:
 与 ε 进行比较,如果小于等于 ε ,则梯度是正确的,反之则需要检查反向传播是否出现了bug
与 ε 进行比较,如果小于等于 ε ,则梯度是正确的,反之则需要检查反向传播是否出现了bug
Note:
不需要在每一次训练迭代中都使用梯度检验,只需要在特定迭代次数后使用进行debug,否则会严重影响训练速度;
如果当前算法/模型在梯度检验中效果不理想,则需要检查梯度算法是否出现了错误;
如果在损失函数中添加了L2正则项,不要忘记;
梯度检验不能跟Dropout同时使用,在梯度检验成功的情况下,再添加dropout。
课后编程题
本次课后编程题分为三部分,需要的文件如下:
第一周课后编程题资料, 提取码:4xy7
Part 1:Initialization
"""
Part 1: Initialization
A well-chosen weights initialization can:
- Speed up the convergence of gradient descent
- Increase the odds of gradient descent converging to a lower training(and generalization) error
"""
import numpy as np
import matplotlib.pyplot as plt
import sklearn
import sklearn.datasets
from init_utils import sigmoid, relu, compute_loss, forward_propagation, backward_propagation
from init_utils import update_parameters, predict, load_dataset, plot_decision_boundary, predict_dec
plt.rcParams['figure.figsize'] = (7.0, 4.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
# load image dataset: blue/red dots in circles
train_X, train_Y, test_X, test_Y = load_dataset()
"""
You will use a 3-layer neural network (already implemented for you). Here are the initialization methods you will
experiment with:
- Zeros initialization -- setting initialization = "zeros" in the input argument.
- Random initialization -- setting initialization = "random" in the input argument. This initializes the weights to
large random values.
- He initialization -- setting initialization = "he" in the input argument. This initializes the weights to random
values scaled according to a paper by He et al., 2015.
"""
# Neural Network model
def model(X, Y, learning_rate=0.01, num_iterations=15000, print_cost=True, initialization="he"):
"""
Implements a three-layer neural network: LINEAR->RELU->LINEAR->RELU->LINEAR->SIGMOID.
Arguments:
X -- input data, of shape (2, number of examples)
Y -- true "label" vector (containing 0 for red dots; 1 for blue dots), of shape (1, number of examples)
learning_rate -- learning rate for gradient descent
num_iterations -- number of iterations to run gradient descent
print_cost -- if True, print the cost every 1000 iterations
initialization -- flag to choose which initialization to use ("zeros","random" or "he")
Returns:
parameters -- parameters learnt by the model
"""
grads = {}
costs = [] # to keep track of the loss
m = X.shape[1] # number of examples
layers_dims = [X.shape[0], 10, 5, 1]
# Initialize parameters dictionary.
if initialization == "zeros":
parameters = initialize_parameters_zeros(layers_dims)
elif initialization == "random":
parameters = initialize_parameters_random(layers_dims)
elif initialization == "he":
parameters = initialize_parameters_he(layers_dims)
# Loop (gradient descent)
for i in range(0, num_iterations):
# Forward propagation: LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID.
a3, cache = forward_propagation(X, parameters)
# Loss
cost = compute_loss(a3, Y)
# Backward propagation.
grads = backward_propagation(X, Y, cache)
# Update parameters.
parameters = update_parameters(parameters, grads, learning_rate)
# Print the loss every 1000 iterations
if print_cost and i % 1000 == 0:
print("Cost after iteration {}: {}".format(i, cost))
costs.append(cost)
# plot the loss
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('iterations (per hundreds)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
return parameters
# Exercise 1: Implement the following function to initialize all parameters to zeros. You'll see later that this does
# not work well since it fails to "break symmetry", but let's try it anyway and see what happens. Use np.zeros((..,..))
# with the correct shapes.
def initialize_parameters_zeros(layers_dims):
"""
Arguments:
layer_dims -- python array (list) containing the size of each layer.
Returns:
parameters -- python dictionary containing your parameters "W1", "b1", ..., "WL", "bL":
W1 -- weight matrix of shape (layers_dims[1], layers_dims[0])
b1 -- bias vector of shape (layers_dims[1], 1)
...
WL -- weight matrix of shape (layers_dims[L], layers_dims[L-1])
bL -- bias vector of shape (layers_dims[L], 1)
"""
parameters = {}
L = len(layers_dims) # number of layers in the network
for l in range(1, L):
# START CODE HERE #
parameters['W' + str(l)] = np.zeros((layers_dims[l], layers_dims[l-1]))
parameters['b' + str(l)] = np.zeros((layers_dims[l], 1))
# END CODE HERE #
return parameters
# test for initialize_parameters_zeros
print("========== test for initialize_parameters_zeros ==========")
parameters = initialize_parameters_zeros([3, 2, 1])
print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))
# Run the following code to train your model on 15,000 iterations using zeros initialization.
parameters = model(train_X, train_Y, initialization="zeros")
print("On the train set:")
predictions_train = predict(train_X, train_Y, parameters)
print("On the test set:")
predictions_test = predict(test_X, test_Y, parameters)
# The performance is awful, and the cost does not really decrease, and the algorithm performs no better than
# random guessing. Why? Let's look at the details of the predictions and the decision boundary:
print("predictions_train = " + str(predictions_train))
print("predictions_test = " + str(predictions_test))
plt.title("Model with Zeros initialization")
axes = plt.gca()
axes.set_xlim([-1.5, 1.5])
axes.set_ylim([-1.5, 1.5])
plot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y)
# In general, initializing all the weights to zero results in the network failing to break symmetry. This means that
# every neuron in each layer will learn the same thing, and you might as well be training a neural network with n^[l]=1
# for every layer, and the network is no more powerful than a linear classifier such as logistic regression.
# Exercise 2: Implement the following function to initialize your weights to large random values (scaled by *10) and
# your biases to zeros
def initialize_parameters_random(layers_dims):
"""
Arguments:
layer_dims -- python array (list) containing the size of each layer.
Returns:
parameters -- python dictionary containing your parameters "W1", "b1", ..., "WL", "bL":
W1 -- weight matrix of shape (layers_dims[1], layers_dims[0])
b1 -- bias vector of shape (layers_dims[1], 1)
...
WL -- weight matrix of shape (layers_dims[L], layers_dims[L-1])
bL -- bias vector of shape (layers_dims[L], 1)
"""
np.random.seed(3) # This seed makes sure your "random" numbers will be the same as ours
parameters = {}
L = len(layers_dims) # integer representing the number of layers
for l in range(1, L):
# START CODE HERE #
parameters['W' + str(l)] = np.random.randn(layers_dims[l], layers_dims[l-1]) * 10
parameters['b' + str(l)] = np.zeros((layers_dims[l], 1))
# END CODE HERE #
return parameters
# test for initialize_parameters_random
print("========== test for initialize_parameters_random ==========")
parameters = initialize_parameters_random([3, 2, 1])
print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))
# Run the following code to train your model on 15,000 iterations using random initialization.
parameters = model(train_X, train_Y, initialization="random")
print("On the train set:")
predictions_train = predict(train_X, train_Y, parameters)
print("On the test set:")
predictions_test = predict(test_X, test_Y, parameters)
print(predictions_train)
print(predictions_test)
plt.title("Model with large random initialization")
axes = plt.gca()
axes.set_xlim([-1.5, 1.5])
axes.set_ylim([-1.5, 1.5])
plot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y)
# The cost starts very high. This is because with large random-valued weights, the last activation (sigmoid) outputs
# results that are very close to 0 or 1 for some examples, and when it gets that example wrong it incurs a very high
# loss for that example. Indeed, when log(a^[3])=log(0), the loss goes to infinity. Poor initialization can lead to
# vanishing/exploding gradients, which also slows down the optimization algorithm. If you train this network longer you
# will see better results, but initializing with overly large random numbers slows down the optimization.
# Exercise 3: Implement the following function to initialize your parameters with He initialization.
def initialize_parameters_he(layers_dims):
"""
Arguments:
layer_dims -- python array (list) containing the size of each layer.
Returns:
parameters -- python dictionary containing your parameters "W1", "b1", ..., "WL", "bL":
W1 -- weight matrix of shape (layers_dims[1], layers_dims[0])
b1 -- bias vector of shape (layers_dims[1], 1)
...
WL -- weight matrix of shape (layers_dims[L], layers_dims[L-1])
bL -- bias vector of shape (layers_dims[L], 1)
"""
np.random.seed(3)
parameters = {}
L = len(layers_dims) # integer representing the number of layers
for l in range(1, L):
# START CODE HERE #
parameters['W' + str(l)] = np.random.randn(layers_dims[l], layers_dims[l-1]) * np.sqrt(2 / layers_dims[l-1])
parameters['b' + str(l)] = np.zeros((layers_dims[l], 1))
# START CODE HERE #
return parameters
# test for initialize_parameters_he
print("========== test for initialize_parameters_random ==========")
parameters = initialize_parameters_he([2, 4, 1])
print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))
# Run the following code to train your model on 15,000 iterations using He initialization.
parameters = model(train_X, train_Y, initialization="he")
print("On the train set:")
predictions_train = predict(train_X, train_Y, parameters)
print("On the test set:")
predictions_test = predict(test_X, test_Y, parameters)
plt.title("Model with He initialization")
axes = plt.gca()
axes.set_xlim([-1.5, 1.5])
axes.set_ylim([-1.5, 1.5])
plot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y)
# The model with He initialization separates the blue and the red dots very well in a small number of iterations.
"""
Conclusion:
- Different initializations lead to different results
- Random initialization is used to break symmetry and make sure different hidden units can learn different things
- Don't intialize to values that are too large
- He initialization works well for networks with ReLU activations
"""
Part 2:Regularization
"""
Part 2: Regularization
Deep Learning models have so much flexibility and capacity that overfitting can be a serious problem, if the training
dataset is not big enough. Sure it does well on the training set, but the learned network doesn't generalize to new
examples that it has never seen.
In order to prevent over-fitting, we may use regularization
"""
# import packages
import numpy as np
import matplotlib.pyplot as plt
from reg_utils import sigmoid, relu, plot_decision_boundary, initialize_parameters, load_2D_dataset, predict_dec
from reg_utils import compute_cost, predict, forward_propagation, backward_propagation, update_parameters
import sklearn
import sklearn.datasets
import scipy.io
plt.rcParams['figure.figsize'] = (7.0, 4.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
"""
Problem Statement: You have just been hired as an AI expert by the French Football Corporation. They would like you to
recommend positions where France’s goal keeper should kick the ball so that the French team’s players can then hit it
with their head.
"""
train_X, train_Y, test_X, test_Y = load_2D_dataset()
"""
Each dot corresponds to a position on the football field where a football player has hit the ball with his/her head after
the French goal keeper has shot the ball from the left side of the football field.
- If the dot is blue, it means the French player managed to hit the ball with his/her head
- If the dot is red, it means the other team's player hit the ball with their head
Your goal: Use a deep learning model to find the positions on the field where the goalkeeper should kick the ball
"""
# Neural Network model
def model(X, Y, learning_rate=0.3, num_iterations=30000, print_cost=True, lambd=0, keep_prob=1):
"""
Implements a three-layer neural network: LINEAR->RELU->LINEAR->RELU->LINEAR->SIGMOID.
Arguments:
X -- input data, of shape (input size, number of examples)
Y -- true "label" vector (1 for blue dot / 0 for red dot), of shape (output size, number of examples)
learning_rate -- learning rate of the optimization
num_iterations -- number of iterations of the optimization loop
print_cost -- If True, print the cost every 10000 iterations
lambd -- regularization hyperparameter, scalar
keep_prob - probability of keeping a neuron active during drop-out, scalar.
Returns:
parameters -- parameters learned by the model. They can then be used to predict.
"""
grads = {}
costs = [] # to keep track of the cost
m = X.shape[1] # number of examples
layers_dims = [X.shape[0], 20, 3, 1]
# Initialize parameters dictionary.
parameters = initialize_parameters(layers_dims)
# Loop (gradient descent)
for i in range(0, num_iterations):
# Forward propagation: LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID.
if keep_prob == 1:
a3, cache = forward_propagation(X, parameters)
elif keep_prob < 1:
a3, cache = forward_propagation_with_dropout(X, parameters, keep_prob)
# Cost function
if lambd == 0:
cost = compute_cost(a3, Y)
else:
cost = compute_cost_with_regularization(a3, Y, parameters, lambd)
# Backward propagation.
assert (lambd == 0 or keep_prob == 1) # it is possible to use both L2 regularization and dropout,
# but this assignment will only explore one at a time
if lambd == 0 and keep_prob == 1:
grads = backward_propagation(X, Y, cache)
elif lambd != 0:
grads = backward_propagation_with_regularization(X, Y, cache, lambd)
elif keep_prob < 1:
grads = backward_propagation_with_dropout(X, Y, cache, keep_prob)
# Update parameters.
parameters = update_parameters(parameters, grads, learning_rate)
# Print the loss every 10000 iterations
if print_cost and i % 10000 == 0:
print("Cost after iteration {}: {}".format(i, cost))
if print_cost and i % 1000 == 0:
costs.append(cost)
# plot the cost
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('iterations (x1,000)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
return parameters
# First train the model without any regularization, and observe the accuracy on the train/test sets
parameters = model(train_X, train_Y)
print("On the training set:")
predictions_train = predict(train_X, train_Y, parameters)
print("On the test set:")
predictions_test = predict(test_X, test_Y, parameters)
plt.title("Model without regularization")
axes = plt.gca()
axes.set_xlim([-0.75, 0.40])
axes.set_ylim([-0.75, 0.65])
plot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y)
# The non-regularized model is obviously over-fitting the training set. It is fitting the noisy points!
# Lets now look at two techniques to reduce over-fitting.
# Exercise 1: Implement compute_cost_with_regularization() which computes the cost with L2 regularization
def compute_cost_with_regularization(A3, Y, parameters, lambd):
"""
Implement the cost function with L2 regularization. See formula (2) above.
Arguments:
A3 -- post-activation, output of forward propagation, of shape (output size, number of examples)
Y -- "true" labels vector, of shape (output size, number of examples)
parameters -- python dictionary containing parameters of the model
Returns:
cost - value of the regularized loss function (formula (2))
"""
m = Y.shape[1]
W1 = parameters["W1"]
W2 = parameters["W2"]
W3 = parameters["W3"]
cross_entropy_cost = compute_cost(A3, Y) # This gives you the cross-entropy part of the cost
# START CODE HERE # (approx. 1 line)
L2_regularization_cost = lambd * (np.sum(np.square(W1)) + np.sum(np.square(W2)) + np.sum(np.square(W3))) / (2 * m)
# END CODER HERE #
cost = cross_entropy_cost + L2_regularization_cost
return cost
# Of course, because you changed the cost, you have to change backward propagation as well
# Exercise 2
def backward_propagation_with_regularization(X, Y, cache, lambd):
"""
Implements the backward propagation of our baseline model to which we added an L2 regularization.
Arguments:
X -- input dataset, of shape (input size, number of examples)
Y -- "true" labels vector, of shape (output size, number of examples)
cache -- cache output from forward_propagation()
lambd -- regularization hyperparameter, scalar
Returns:
gradients -- A dictionary with the gradients with respect to each parameter, activation and pre-activation variables
"""
m = X.shape[1]
(Z1, A1, W1, b1, Z2, A2, W2, b2, Z3, A3, W3, b3) = cache
dZ3 = A3 - Y
# START CODE HERE #
dW3 = 1. / m * np.dot(dZ3, A2.T) + lambd * W3 / m
# END CODE HERE #
db3 = 1. / m * np.sum(dZ3, axis=1, keepdims=True)
dA2 = np.dot(W3.T, dZ3)
dZ2 = np.multiply(dA2, np.int64(A2 > 0))
# START CODE HERE #
dW2 = 1. / m *np.dot(dZ2, A1.T) + (lambd * W2) / m
# END CODE HERE #
db2 = 1. / m * np.sum(dZ2, axis=1, keepdims=True)
dA1 = np.dot(W2.T, dZ2)
dZ1 = np.multiply(dA1, np.int64(A1 > 0))
# START CODE HERE #
dW1 = 1. / m * np.dot(dZ1, X.T) + (lambd * W1) / m
# END CODE HERE #
db1 = 1. / m * np.sum(dZ1, axis=1, keepdims=True)
gradients = {"dZ3": dZ3, "dW3": dW3, "db3": db3,
"dZ2": dZ2, "dW2": dW2, "db2": db2,
"dZ1": dZ1, "dW1": dW1, "db1": db1}
return gradients
# Let's now run the model with L2 regularization(λ=0.7)
parameters = model(train_X, train_Y, lambd=0.7)
print("On the train set:")
predictions_train = predict(train_X, train_Y, parameters)
print("On the test set:")
predictions_test = predict(test_X, test_Y, parameters)
plt.title("Model with L2-regularization")
axes = plt.gca()
axes.set_xlim([-0.75, 0.40])
axes.set_ylim([-0.75, 0.65])
plot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y)
"""
Observations:
- The value of λ is a hyperparameter that you can tune using a dev set.
- L2 regularization makes your decision boundary smoother. If λ is too large, it is also possible to "over-smooth",
resulting in a model with high bias.
L2-regularization relies on the assumption that a model with small weights is simpler than a model with large weights.
Thus, by penalizing the square values of the weights in the cost function you drive all the weights to smaller values.
It becomes too costly for the cost to have large weights! This leads to a smoother model in which the output changes
more slowly as the input changes.
"""
# Exercise 3: Implement the forward propagation with dropout. You are using a 3 layer neural network, and will add
# dropout to the first and second hidden layers. We will not apply dropout to the input layer or output layer.
"""
Instruction:
1. In lecture, we dicussed creating a variable d^[l] with the same shape as a^[l] using np.random.rand() to randomly
get numbers between 0 and 1. Here, you will use a vectorized implementation, so create a random matrix:
D^[l] = [d^[l](1) d^[l](2) ... d^[l](m)] of the same dimension as A^[l]
2. Set each entry of D^[l] to be 0 with probability greater than or equal to keep_prob or 1 with probability less
than keep_prob), by thresholding values in D^[l] appropriately. Hint: to set all the entries of a matrix X to 0(if
entry is less than 0.5) or 1(if entry is more than 0.5) you would do: X = (X < 0.5). Note that 0 and 1 are
respectively equivalent to False and True.
3. Set A^[l] to A^[l]*D^[l].(You are shutting down some neurons). You can think of D^[l] as a mask, so that when it
is multiplied with another matrix, it shuts down some of the values.
4. Divide A^[l] by keep_prob. By doing this you are assuring that the result of the cost will still have the same
expected value as without drop-out.(Inverted dropout)
"""
def forward_propagation_with_dropout(X, parameters, keep_prob=0.5):
"""
Implements the forward propagation: LINEAR -> RELU + DROPOUT -> LINEAR -> RELU + DROPOUT -> LINEAR -> SIGMOID.
Arguments:
X -- input dataset, of shape (2, number of examples)
parameters -- python dictionary containing your parameters "W1", "b1", "W2", "b2", "W3", "b3":
W1 -- weight matrix of shape (20, 2)
b1 -- bias vector of shape (20, 1)
W2 -- weight matrix of shape (3, 20)
b2 -- bias vector of shape (3, 1)
W3 -- weight matrix of shape (1, 3)
b3 -- bias vector of shape (1, 1)
keep_prob - probability of keeping a neuron active during drop-out, scalar
Returns:
A3 -- last activation value, output of the forward propagation, of shape (1,1)
cache -- tuple, information stored for computing the backward propagation
"""
np.random.seed(1)
# retrieve parameters
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
W3 = parameters["W3"]
b3 = parameters["b3"]
# LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID
Z1 = np.dot(W1, X) + b1
A1 = relu(Z1)
# START CODE HERE # # Steps 1-4 below correspond to the Steps 1-4 described above.
D1 = np.random.rand(A1.shape[0], A1.shape[1])
D1 = D1 < keep_prob
A1 = A1 * D1
A1 = A1 / keep_prob
# END CODE HERE #
Z2 = np.dot(W2, A1) + b2
A2 = relu(Z2)
# START CODE HERE #
D2 = np.random.rand(A2.shape[0], A2.shape[1])
D2 = D2 < keep_prob
A2 = A2 * D2
A2 = A2 / keep_prob
# END CODE HERE #
Z3 = np.dot(W3, A2) + b3
A3 = sigmoid(Z3)
cache = (Z1, D1, A1, W1, b1, Z2, D2, A2, W2, b2, Z3, A3, W3, b3)
return A3, cache
# Exercise 4: Implement the backward propagation with dropout. As before, you are training a 3 layer network. Add
# dropout to the first and second hidden layers, using the masks D^[1] and D^[2] stored in the cache.
"""
Instruction: Backpropagation with dropout is actually quite easy. You will have to carry out 2 Steps:
- You had previously shut down some neurons during forward propagation, by applying a mask D^[l] to Al. In
backpropagation, you will have to shut down the same neurons, by reapplying the same mask D^[l] to dAl.
- During forward propagation, you had divided Al by keep_prob. In backpropagation, you'll therefore have to divide
dA1 by keep_prob again (the calculus interpretation is that if A^[l] is scaled by keep_prob, then its derivative
dA^[l] is also scaled by the same keep_prob).
"""
def backward_propagation_with_dropout(X, Y, cache, keep_prob):
"""
Implements the backward propagation of our baseline model to which we added dropout.
Arguments:
X -- input dataset, of shape (2, number of examples)
Y -- "true" labels vector, of shape (output size, number of examples)
cache -- cache output from forward_propagation_with_dropout()
keep_prob - probability of keeping a neuron active during drop-out, scalar
Returns:
gradients -- A dictionary with the gradients with respect to each parameter, activation and pre-activation variables
"""
m = X.shape[1]
(Z1, D1, A1, W1, b1, Z2, D2, A2, W2, b2, Z3, A3, W3, b3) = cache
dZ3 = A3 - Y
dW3 = 1. / m * np.dot(dZ3, A2.T)
db3 = 1. / m * np.sum(dZ3, axis=1, keepdims=True)
dA2 = np.dot(W3.T, dZ3)
# START CODE HERE #
dA2 = dA2 * D2 # Apply mask D2 to shut down the same neurons as in forward propagation
dA2 = dA2 / keep_prob # Scale the value of neurons that haven't been shut down
# END CODE HERE #
dZ2 = np.multiply(dA2, np.int64(A2 > 0))
dW2 = 1. / m * np.dot(dZ2, A1.T)
db2 = 1. / m * np.sum(dZ2, axis=1, keepdims=True)
dA1 = np.dot(W2.T, dZ2)
# START CODE HERE #
dA1 = dA1 * D1
dA1 = dA1 / keep_prob
# END CODE HERE #
dZ1 = np.multiply(dA1, np.int64(A1 > 0))
dW1 = 1. / m * np.dot(dZ1, X.T)
db1 = 1. / m * np.sum(dZ1, axis=1, keepdims=True)
gradients = {"dZ3": dZ3, "dW3": dW3, "db3": db3,
"dA2": dA2, "dZ2": dZ2, "dW2": dW2, "db2": db2,
"dA1": dA1, "dZ1": dZ1, "dW1": dW1, "db1": db1}
return gradients
# Let's now run the model with dropout (keep_prob = 0.86). It means at every iteration you shut down each neurons of
# layer 1 and 2 with 24% probability.
parameters = model(train_X, train_Y, keep_prob=0.86, learning_rate=0.3)
print("On the train set:")
predictions_train = predict(train_X, train_Y, parameters)
print("On the test set:")
predictions_test = predict(test_X, test_Y, parameters)
plt.title("Model with dropout")
axes = plt.gca()
axes.set_xlim([-0.75, 0.40])
axes.set_ylim([-0.75, 0.65])
plot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y)
"""
Note that regularization hurts training set performance! This is because it limits the ability of the network to overfit
to the training set. But since it ultimately gives better test accuracy, it is helping your system.
"""
Part 3:Gradient Checking
"""
Background:
You are part of a team working to make mobile payments available globally, and are asked to build a deep learning model
to detect fraud--whenever someone makes a payment, you want to see if the payment might be fraudulent, such as if the
user's account has been taken over by a hacker.
But backpropagation is quite challenging to implement, and sometimes has bugs. Because this is a mission-critical
application, your company's CEO wants to be really certain that your implementation of backpropagation is correct. Your
CEO says, "Give me a proof that your backpropagation is actually working!" To give this reassurance, you are going to
use "gradient checking".
"""
import numpy as np
from gc_utils import sigmoid, relu, dictionary_to_vector, vector_to_dictionary, gradients_to_vector
from testCases import *
# 1-dimensional gradient checking
# Exercise: implement "forward propagation" and "backward propagation" for this simple function(J = θx). I.e., compute
# both J(.) ("forward propagation") and its derivative with respect to θ ("backward propagation"), in two separate
# functions.
def forward_propagation(x, theta):
"""
Implement the linear forward propagation (compute J) presented in Figure 1 (J(theta) = theta * x)
Arguments:
x -- a real-valued input
theta -- our parameter, a real number as well
Returns:
J -- the value of function J, computed using the formula J(theta) = theta * x
"""
# START CODE HERE # (approx. 1 line)
J = np.dot(theta, x)
# END CODE HERE #
return J
# test for forward_propagation
print("========= test for forward_propagation ==========")
x, theta = 2, 4
J = forward_propagation(x, theta)
print("J = " + str(J))
# Exercise: Now, implement the backward propagation step (derivative computation)
def backward_propagation(x, theta):
"""
Computes the derivative of J with respect to theta (see Figure 1).
Arguments:
x -- a real-valued input
theta -- our parameter, a real number as well
Returns:
dtheta -- the gradient of the cost with respect to theta
"""
# START CODE HERE # (approx. 1 line)
dtheta = x
# END CODE HERE #
return dtheta
# test for backward_propagation
print("========= test for backward_propagation ==========")
x, theta = 2, 4
dtheta = backward_propagation(x, theta)
print("dtheta = " + str(dtheta))
# Exercise: To show that the backward_propagation() function is correctly computing the gradient, let's implement grad check
def gradient_check(x, theta, epsilon=1e-7):
"""
Implement the backward propagation presented in Figure 1.
Arguments:
x -- a real-valued input
theta -- our parameter, a real number as well
epsilon -- tiny shift to the input to compute approximated gradient with formula(1)
Returns:
difference -- difference (2) between the approximated gradient and the backward propagation gradient
"""
# Compute gradapprox using left side of formula (1). epsilon is small enough, you don't need to worry about the limit.
# START CODE HERE # (approx. 5 lines)
theta_plus = theta + epsilon
theta_minus = theta - epsilon
J_plus = forward_propagation(x, theta_plus)
J_minus = forward_propagation(x, theta_minus)
gradapprox = (J_plus - J_minus) / (2 * epsilon)
# END CODE HERE #
# Check if gradapprox is close enough to the output of backward_propagation()
# START CODE HERE # (approx. 1 line)
grad = backward_propagation(x, theta)
# END CODE HERE #
# START CODE HERE # (approx. 3 line)
numerator = np.linalg.norm(grad - gradapprox)
denominator = np.linalg.norm(grad) + np.linalg.norm(gradapprox)
difference = numerator / denominator
# END CODE HERE #
if difference < 1e-7:
print("The gradient is correct!")
else:
print("The gradient is wrong!")
return difference
# test for gradient_check
print("========= test for gradient_check ==========")
x, theta = 2, 4
difference = gradient_check(x, theta)
print("difference = " + str(difference))
# N-dimensional gradient checking
# forward propagation
def forward_propagation_n(X, Y, parameters):
"""
Implements the forward propagation (and computes the cost) presented in Figure 3.
Arguments:
X -- training set for m examples
Y -- labels for m examples
parameters -- python dictionary containing your parameters "W1", "b1", "W2", "b2", "W3", "b3":
W1 -- weight matrix of shape (5, 4)
b1 -- bias vector of shape (5, 1)
W2 -- weight matrix of shape (3, 5)
b2 -- bias vector of shape (3, 1)
W3 -- weight matrix of shape (1, 3)
b3 -- bias vector of shape (1, 1)
Returns:
cost -- the cost function (logistic cost for one example)
"""
# retrieve parameters
m = X.shape[1]
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
W3 = parameters["W3"]
b3 = parameters["b3"]
# LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID
Z1 = np.dot(W1, X) + b1
A1 = relu(Z1)
Z2 = np.dot(W2, A1) + b2
A2 = relu(Z2)
Z3 = np.dot(W3, A2) + b3
A3 = sigmoid(Z3)
# Cost
logprobs = np.multiply(-np.log(A3), Y) + np.multiply(-np.log(1 - A3), 1 - Y)
cost = 1. / m * np.sum(logprobs)
cache = (Z1, A1, W1, b1, Z2, A2, W2, b2, Z3, A3, W3, b3)
return cost, cache
# backward propagation
# There are some incorrect code inside which is for grad check
def backward_propagation_n(X, Y, cache):
"""
Implement the backward propagation presented in figure 2.
Arguments:
X -- input datapoint, of shape (input size, 1)
Y -- true "label"
cache -- cache output from forward_propagation_n()
Returns:
gradients -- A dictionary with the gradients of the cost with respect to each parameter, activation and pre-activation variables.
"""
m = X.shape[1]
(Z1, A1, W1, b1, Z2, A2, W2, b2, Z3, A3, W3, b3) = cache
dZ3 = A3 - Y
dW3 = 1. / m * np.dot(dZ3, A2.T)
db3 = 1. / m * np.sum(dZ3, axis=1, keepdims=True)
dA2 = np.dot(W3.T, dZ3)
dZ2 = np.multiply(dA2, np.int64(A2 > 0))
dW2 = 1. / m * np.dot(dZ2, A1.T) * 2 # Should not multiply by 2
db2 = 1. / m * np.sum(dZ2, axis=1, keepdims=True)
dA1 = np.dot(W2.T, dZ2)
dZ1 = np.multiply(dA1, np.int64(A1 > 0))
dW1 = 1. / m * np.dot(dZ1, X.T)
db1 = 4. / m * np.sum(dZ1, axis=1, keepdims=True) # Should not multiply by 4
gradients = {"dZ3": dZ3, "dW3": dW3, "db3": db3,
"dA2": dA2, "dZ2": dZ2, "dW2": dW2, "db2": db2,
"dA1": dA1, "dZ1": dZ1, "dW1": dW1, "db1": db1}
return gradients
# Exercise: Implement gradient_check_n()
def gradient_check_n(parameters, gradients, X, Y, epsilon=1e-7):
"""
Checks if backward_propagation_n computes correctly the gradient of the cost output by forward_propagation_n
Arguments:
parameters -- python dictionary containing your parameters "W1", "b1", "W2", "b2", "W3", "b3":
grad -- output of backward_propagation_n, contains gradients of the cost with respect to the parameters.
x -- input datapoint, of shape (input size, 1)
y -- true "label"
epsilon -- tiny shift to the input to compute approximated gradient with formula(1)
Returns:
difference -- difference (2) between the approximated gradient and the backward propagation gradient
"""
# Set-up variables
parameters_values, _ = dictionary_to_vector(parameters)
grad = gradients_to_vector(gradients)
num_parameters = parameters_values.shape[0]
J_plus = np.zeros((num_parameters, 1))
J_minus = np.zeros((num_parameters, 1))
gradapprox = np.zeros((num_parameters, 1))
# Compute gradapprox
for i in range(num_parameters):
# Compute J_plus[i]. Inputs: "parameters_values, epsilon". Output = "J_plus[i]".
# "_" is used because the function you have to outputs two parameters but we only care about the first one
# START CODE HERE # (approx. 3 lines)
theta_plus = np.copy(parameters_values)
theta_plus[i][0] = theta_plus[i][0] + epsilon
J_plus[i], _ = forward_propagation_n(X, Y, vector_to_dictionary(theta_plus))
# END CODE HERE #
# Compute J_minus[i]. Inputs: "parameters_values, epsilon". Output = "J_minus[i]".
# START CODE HERE # (approx. 3 lines)
theta_minus = np.copy(parameters_values)
theta_minus[i][0] = theta_minus[i][0] - epsilon
J_minus[i], _ = forward_propagation_n(X, Y, vector_to_dictionary(theta_minus))
# END CODE HERE #
# Compare gradapprox to backward propagation gradients by computing difference.
# START CODE HERE # (approx. 1 line)
numerator = np.linalg.norm(grad - gradapprox)
denominator = np.linalg.norm(grad) + np.linalg.norm(gradapprox)
difference = numerator / denominator
# END CODE HERE
if difference > 1e-7:
print(
"\033[93m" + "There is a mistake in the backward propagation! difference = " + str(difference) + "\033[0m")
else:
print(
"\033[92m" + "Your backward propagation works perfectly fine! difference = " + str(difference) + "\033[0m")
return difference
# test for gradient_check_n
print("========== test for gradient_check_n ==========")
X, Y, parameters = gradient_check_n_test_case()
cost, cache = forward_propagation_n(X, Y, parameters)
gradients = backward_propagation_n(X, Y, cache)
difference = gradient_check_n(parameters, gradients, X, Y)
参考
何宽【中文】【吴恩达课后编程作业】Course 2 - 改善深层神经网络 - 第一周作业(1&2&3)
Kulbear Initialization, Regularization, Gradient Checking