大数据课程笔记4:摘要结构,streaming algorithm
这是大数据课程第四节的笔记,笔者自己的理解使用斜体注明,正确性有待验证。
This is the note of lecture 4 in Big Data Algorithm class. The use of italics indicates the author’s own understanding, whose correctness needs to be verified.
1. Synopsis Structure
Most contents of the synopsis structure are collected from the lecture note in http://www.cohenwang.com/edith/bigdataclass2013 .
1.1. Definition
A small summary of a large data set that (approximately) captures some statistics/properties we are interested in.
Example: random samples, sketches/projections, histograms,…
1.2. Functionality
Some operations, such as insertion, deletion, query and merging databases, may be required.
1.3. Motivation/ Why?
Data can be too large to
- Keep for long or even short term
- Transmit across the network
- Process queries over in reasonable time/computation
1.4. Limitation
The size of working cpu/memory can be limited compared with the size of data.
Only one or two passes of data in cpu are affordable.
1.5. Applications:
network traffic management
I/O Efficiency
Real Time Data
2. Frequent Elements: Misra Gries Algorithm
2.1. Purpose
In brief, the system reads the data in one pass and outputs the frequencies of the top-k most frequent elements.
2.2. Motivation/Application
zipf law: Typical frequency distributions are highly skewed: with few very frequent elements. Say top 10% of elements have 90% of total occurrences. We are interested in finding the heaviest elements.
According to the zipf law, the most frequent elements are significant to represent the data.
Some applications:
- Networking: Find “elephant” flows
- Search: Find the most frequent queries
2.3. A simple algorithm
Simply create a counter for each distinct element and count it in its following occurrence.
However, this algorithm requires about nlogm bits, where n is the number of distinct elements, and m denotes the total number of elements. Sometimes, n counters are too large and only k counters are affordable.
2.4. Misra Gries Algorithm
2.4.1. Insert, Query
1. Place a counter on the first k distinct elements.
2. On the (k + 1)-st elements, reduce each counter by 1 and remove counters of value zero.
3. Report counter value on any query.2.4.2. One simple example for Insertion and Query
The input stream is “abccbcbae” (simply chosen randomly), and the maximum counter number k is 2.
| step number | current element | counter1’s element | counter1’s value | counter2’s element | counter2’s value |
|---|---|---|---|---|---|
| 0 | a | a | 1 | - | - |
| 1 | b | a | 1 | b | 1 |
| 2 | c | - | - | - | - |
| 3 | c | c | 1 | - | - |
| 4 | b | c | 1 | b | 1 |
| 5 | c | c | 2 | b | 1 |
| 6 | b | c | 2 | b | 2 |
| 7 | a | c | 1 | b | 1 |
| 8 | e | - | - | - | - |
2.4.3. Analyze the output
As illustrated in the previous example, the output is obviously an underestimate. However the maximum error is limited. When zipf law / power law property of data holds, the error is acceptable.
m is the total number of elements in the input, and m′ is the sum of the output. For example, m is 9 and m′ is 0 in step 2 and 4 in step 6 in the previous example. If n≤k , m=m′ , since if there is no (k + 1)-st elements, there is no reduction or removement. If n>k , the difference between m and m′ is caused by the reduction operations. And for each reduction operation, k+1 is reduced from the current output. Then there are at most m−m′k+1 reduction operations. Moreover, for each counter, the number is reduced by at most 1 for each reduction operation. Then the number is reduced by at most m−m′k+1 .
The error is proportional to the inverse of k . So the error is small when memory is large enough. Furthermore, when k is fixed, it’s proportional to m−m′ . Notice that m is the total number of input elements, m′ is the estimate of the total number of the top k most frequent elements. So the output is more accurate, if zipf law holds and m is large enough. This conclusion also explains the poor estimate in the example.
2.4.4. Merge
The merge operation is similar to insertion, as following:
1. Merge the common element counter, keep distinct counters.
2. Remove small counters to keep k largest (by reducing counter then remove counters of value zero.The estimate error is also at most m−m′k+1 . More details can be found in the lecture note in http://www.cohenwang.com/edith/bigdataclass2013 .
3. Stream Counting
3.1. Purpose
The system reads the data in one pass and output the total number of elements. It’s simply a counter.
3.2. A simple algorithm
One simple way is to keep one number as the counter, which increases by one for each element read.
The required space O(logN) , where N is the total number of input.
3.3. Morris’s idea
Instead of counting store N in logN bits, it will store logN in loglogN bits. It may take advantage of the idea that when N is large, the exact number of N is not important compared with the size of N . For example, when N=100000000 , it doesn’t matter whether N=100000010 or N=100000000 . However, that the left most 1 is in the 9 th position is important.
It also uses the powerful tool: randomization, and guarantee that the expectation of the output is the same as the correct output, while saving space.
The algorithm is as follows:
- Keep a counter x of value “ logn ”.
- Increase the counter with probability p=2−x .
- On a query, return 2x−1 .
3.4. One example
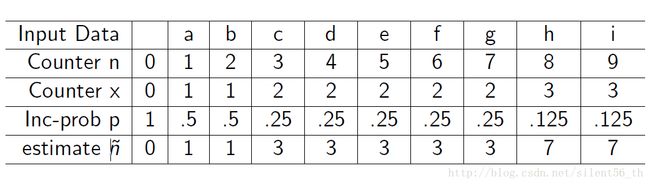
3.5. Analyze: the expected return value
The claim: Expected value after reading n input data is n .
Proof: Using the inductive principle, the proof is simple.
- Base case: n=0 , x=0 , n^=2x−1=0=n . Base case approved.
- Assume the claim is true for all n≤k , which means EX[n^]=n .
- When n=k+1 , we have
According to the principle of induction, the claim is true for all n≥0 .
4. Count Distinct Items
4.1. Some definitions
Input sequence A={a1,a2,⋯,am} , where m is the number of elements. ai∈N={1,2,⋯,n} . Therefore, there are no more than n distince elements in A .
Define mi={j:aj=i} , which is a set containing the index of all elements whose value is equal to i .
Then Fk=∑ni=1mki,k=0,1,2,⋯ .
- F0 is the number of distince elements in list, since ∅0=0,S0=1 iff. S≠∅ 。
- F1 is the length of sequnce, m .
- F2 is called Ginis index of homogeneity.
- F∗∞=max1≤i≤nmi
4.2. Purpose
The system reads the data in one pass and outputs F0 , which is the number of distinct items in the input sequence.
4.3. General Theorem

4.4. Improved Performance
The memory size is O(logn) bits.
The property of output: P(Y/F0<1/c)+P(Y/F0>c)≤3/c , where c is a fixed constant bigger than 2 , Y is the estimated output.
4.5. Algorithm
The basic idea is firstly using the finite field to hash elements to reduce size and make the item randomized, and then using the property of F0 random elements to estimate the size.
4.5.1. Basic Knowledge: Finite Field and Probability
Here, we only introduce some basic idea and calculation of finite field and probability. More details are available on the Internet.
4.5.1.1. Finite Field
Two websites, which explain the idea of finite field in detail, are found: http://mathworld.wolfram.com/FiniteField.html, http://blog.csdn.net/luotuo44/article/details/41645597
4.5.1.2. Probability Inequalities
Markov Inequality
P[X≥d]≤EX[X]d for X≥0 .
since EX[X]=∫xf(x)dx≥∫x=dxf(x)dx≥d∫x=df(x)dx , where f(x) is PDF (probability density function) of X .
Chebyshev Inequality
P[|X−μ|≥kδ]≤1k2 ,
since P[|X−μ|≥kδ]=P[(X−μ)2≥k2δ2]≤EX[(x−μ)2]k2δ2=δ2/(k2δ2)=1/k2 , where μ=EX[X] , δ=Var[X] , k is a fixed constant.
4.5.2. The algorithm
- Construct the finite field F=GF(2d) , where n<2d .
- hash the input element
- a,b randomly chosen from F .
- ∀ai∈A (in the order of the input sequence), hash ai to zi=a×ai+b(mod F) represented by a d -vector in F .
- Estimate F0 using properties of F0 random values
- De fine ri=r(zi)=max{i:2i|zi} , such that ri is right most 1 ’s position. For example r(1010000)=4 and r(1010010)=1 . ri should be less than d , which is roughly logn .
- Define R to be the largest ri over all elements of A, which means R=max(r1,r2,⋯,rm)
- Output Y=2R .
4.5.3. Some analysis of the algorithm
The use of the finite field is to hash input elements ai into a fixed size output zi , which is uniformly distributed among 0 and 2d−1 . The fixed size output guarantees that the system requires a fixed size of space. Moreover, the randomized property guaranteed that R can represent F0 .
Now let’s focus on the property of the output Y . Firstly, we need derive the probability distribution of ri based on F0 different randomized elements. Since the elements are randomized, p(ri≥j)=2−j . ( ri≥j means the last j bits of the i th elements are all zero. The probability for each bit to be zero is 1/2 since the the elements are randomized.) Furthermore, we define a new variable Zr=∑x∈F0I[r(ax+b)≥r] , which is the number of elements with r(ax+b) greater than r . According to the definition, we have ZR≥1 and ZR+1=0 , where R=max(r1,r2,⋯,rm) . The distribution of Zr is simply a bernoulli distribution of N=F0 and p=p(ri≥r)=2−r . Then E(Zr)=F02−r and Var(Zr)=F02−r(1−2−r)<E(Zr) .
As discussed above, Y is related to R by Y=2R , and R is related to Z by ZR≥1 and ZR+1=0 . When furthermore should discuss the probability of P(Zr≥1) and P(Zr=0) .
P(Zr≥1)≤EX(Zr)1=F0/2r
P(Zr=0)≤P(|Zr−E(Zr)|≥E(Zr))≤1E(Zr)2/Var(Zr)≤1E(Zr)=2r/F0
If 2r>cF0 , then P(Zr≥1)≤1/c . Then P(F0/Y<1/c)=P(2R>cF0 and ZR≥1 and ZR+1=0)≤P(ZR≥1|2R>cF0)≤1/c
If c∗2r<F0 , then P(Zr=0)≤1/c . Then